示例#
这是展示如何使用scikit-learn的示例库。一些示例演示了 API 一般来说,有些以教程形式演示特定的应用程序。另请查看我们的 user guide 了解更详细的插图。
发布亮点#
这些示例说明了scikit-learn版本的主要功能。

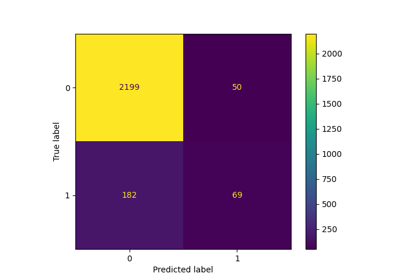
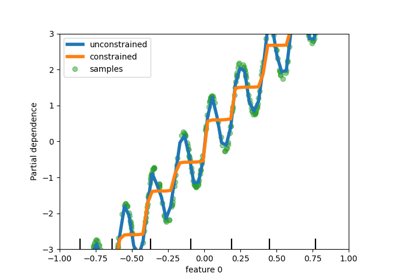
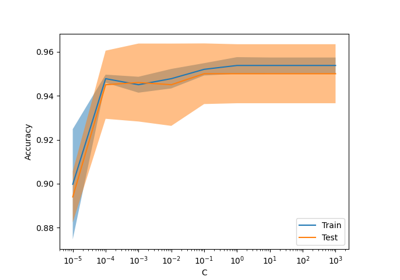


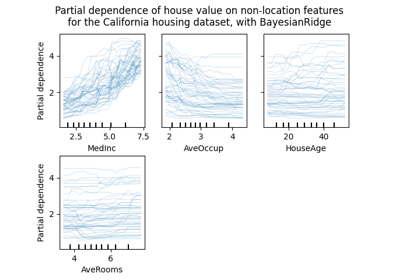
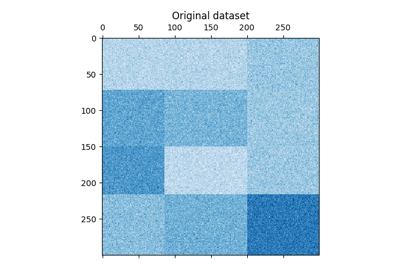
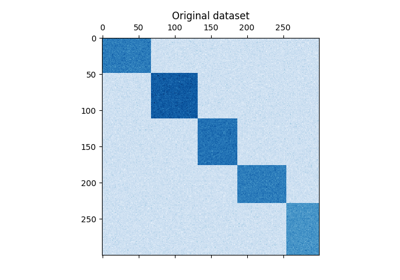
双聚类#
有关双集群技术的示例。

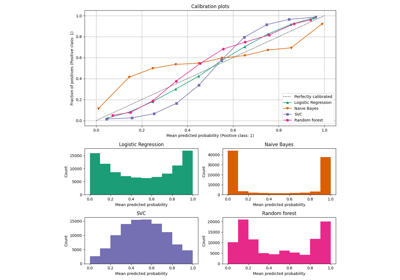
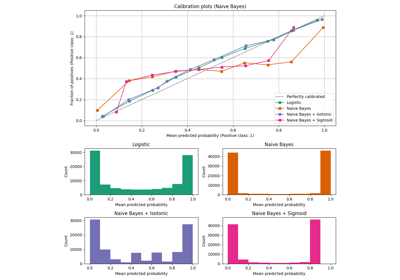
校准#
示例说明分类器预测概率的校准。
分类#
有关分类算法的一般示例。



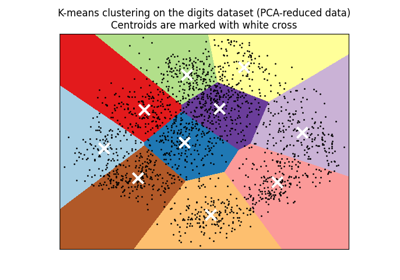
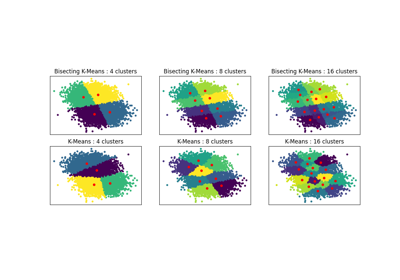
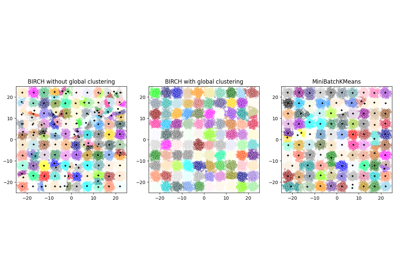
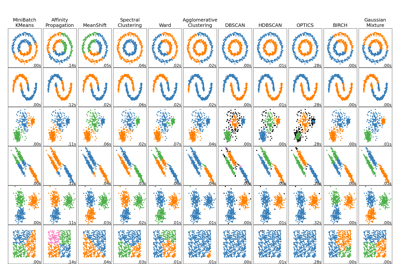
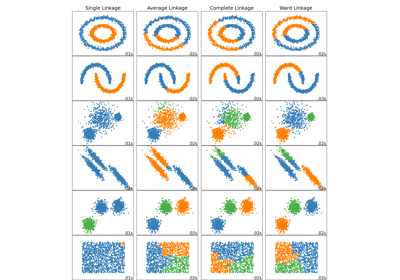
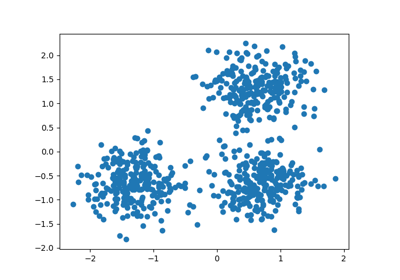
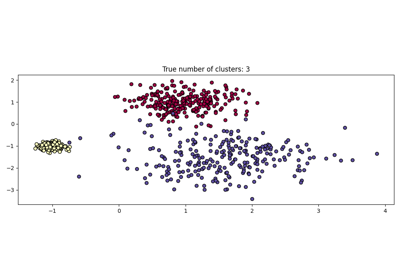
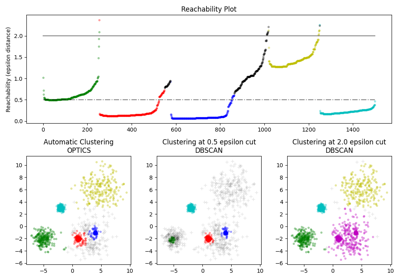
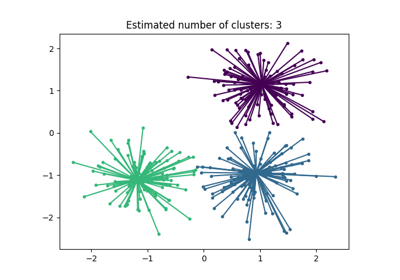
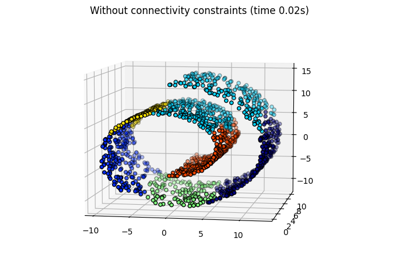
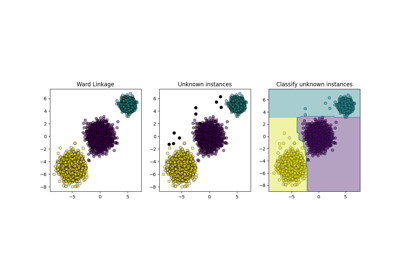
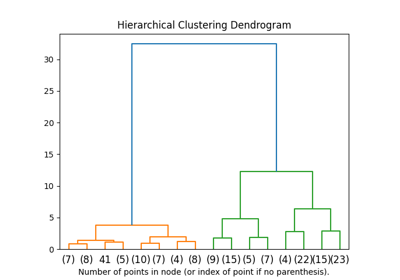
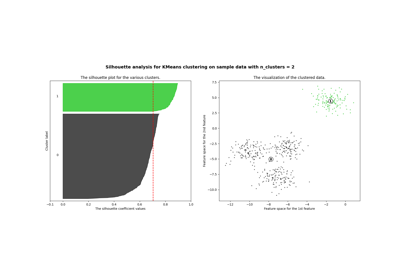
聚类#
有关的例子 sklearn.cluster module.



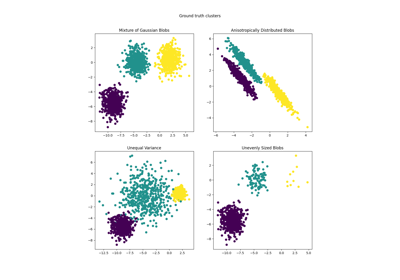
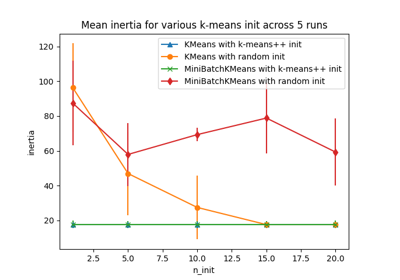
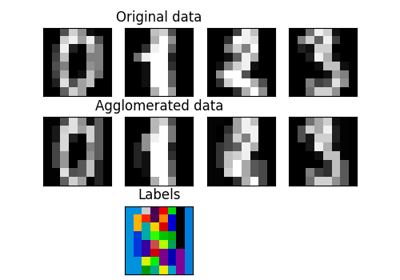
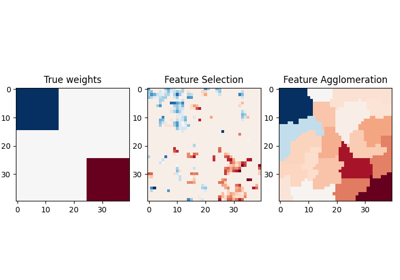


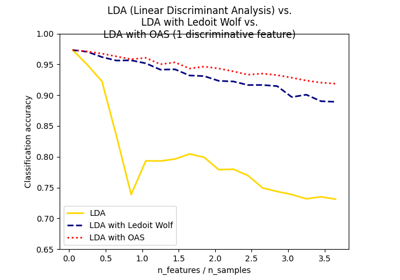
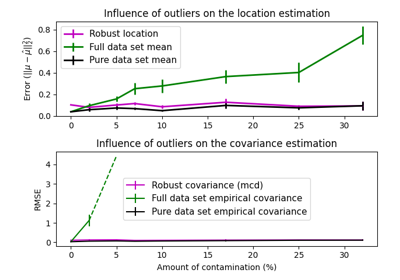
协方差估计#
有关的例子 sklearn.covariance module.

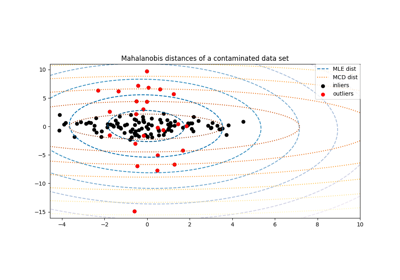
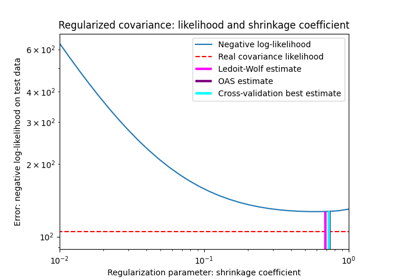
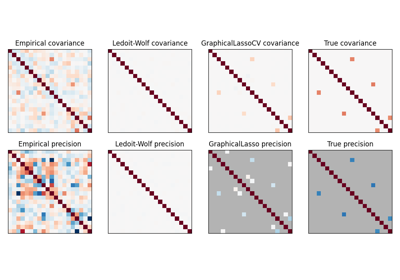
收缩协方差估计:LedoitWolf vs OAS和最大似然
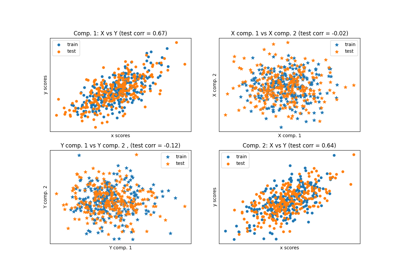
交叉分解#
有关的例子 sklearn.cross_decomposition module.
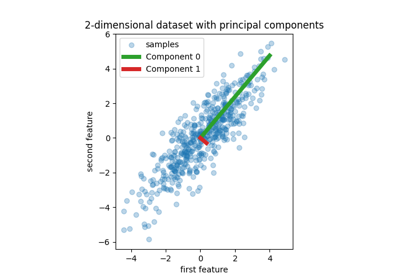
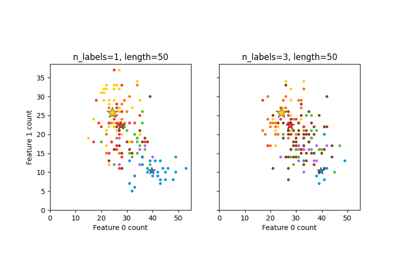
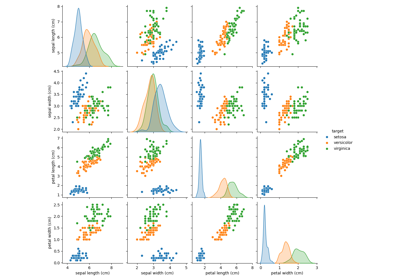
数据集示例#
有关的例子 sklearn.datasets module.
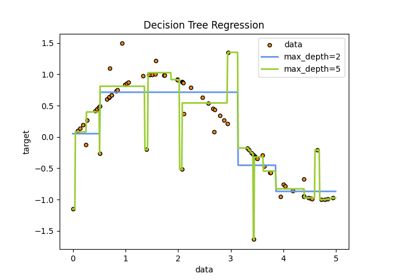
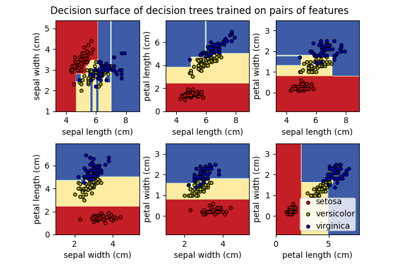
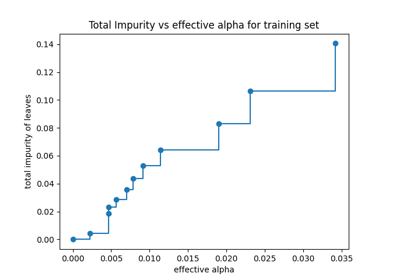
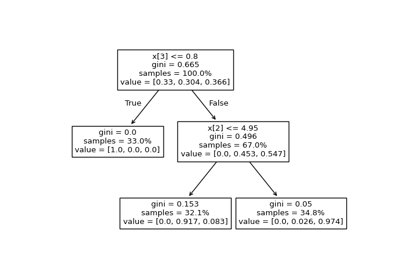
决策树#
有关的例子 sklearn.tree module.
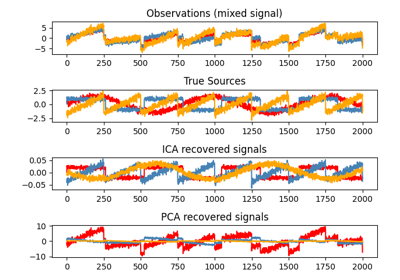
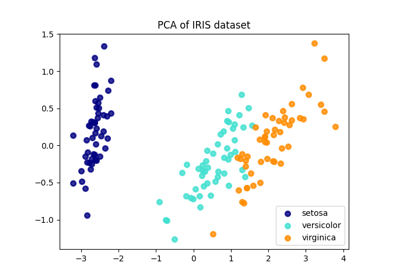
分解#
有关的例子 sklearn.decomposition module.

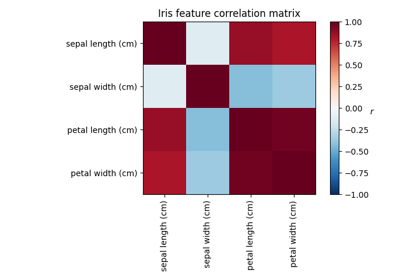
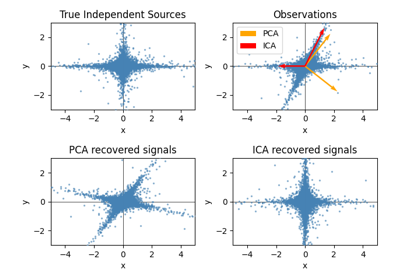

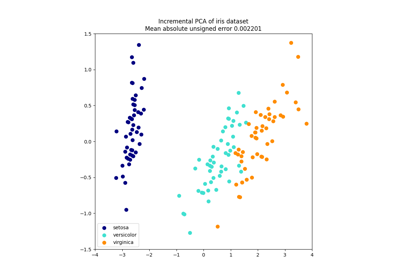
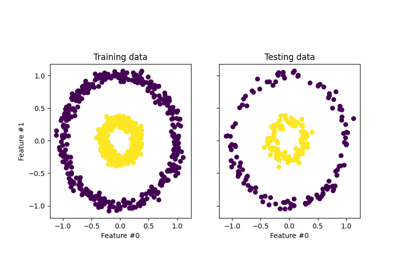
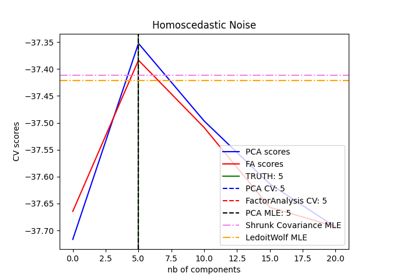
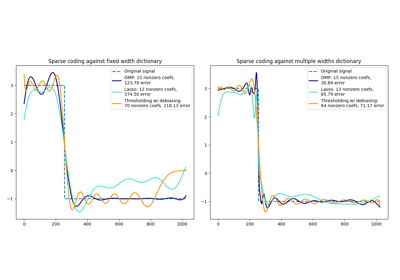
开发估算器#
有关自定义估算器开发的示例。

集成方法#
有关的例子 sklearn.ensemble module.
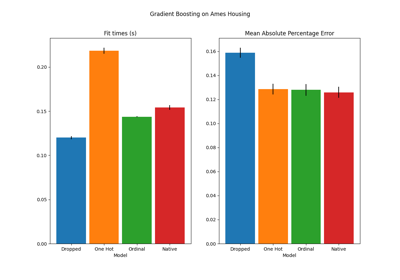
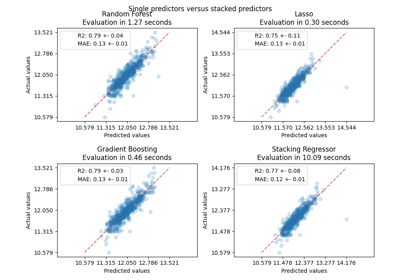

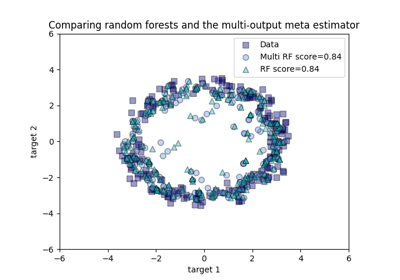
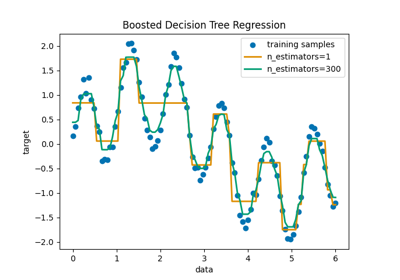
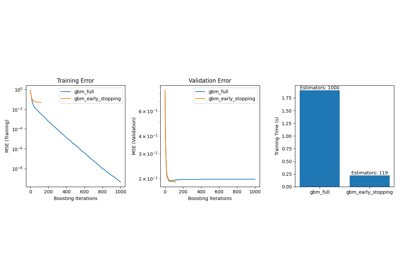
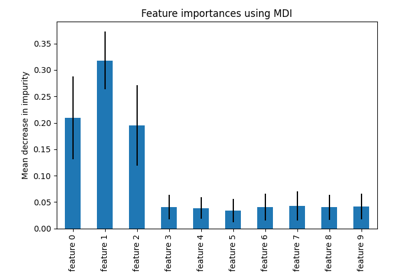
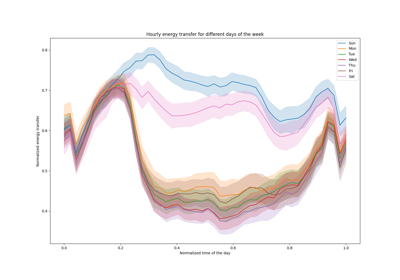

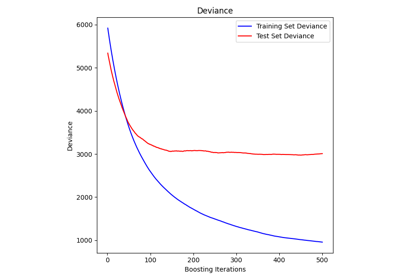
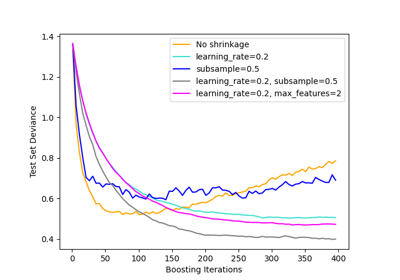


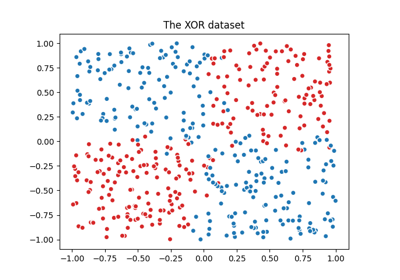
基于现实世界数据集的示例#
应用于具有一些中等大小数据集或交互式用户界面的现实世界问题。

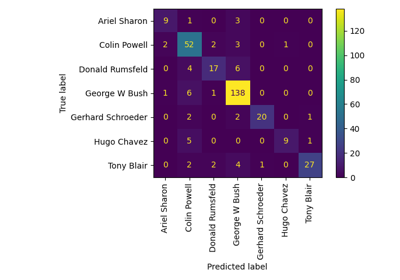

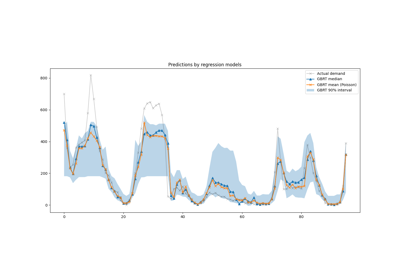
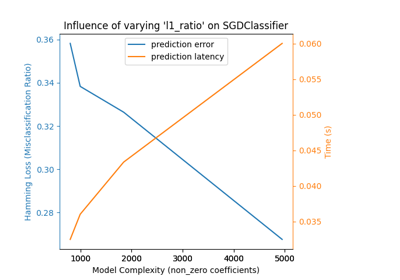
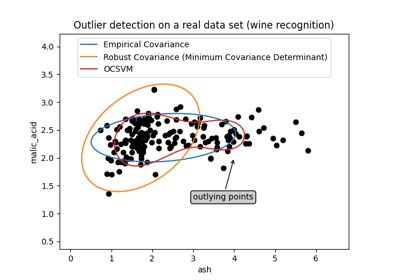
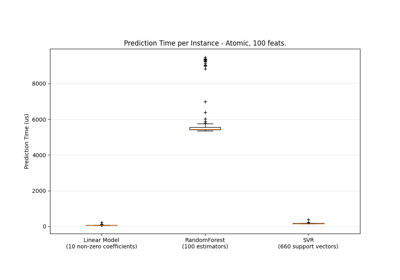
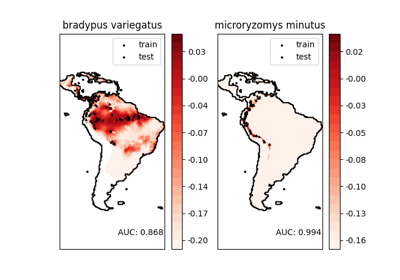
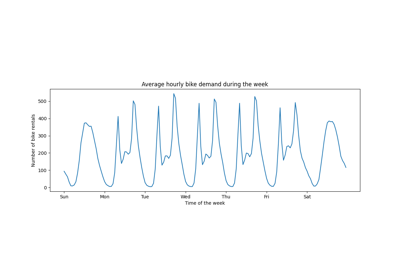
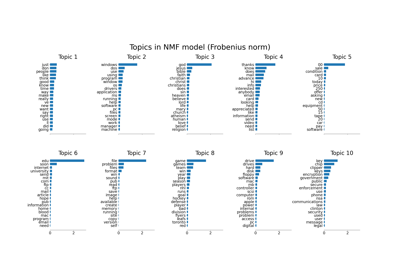

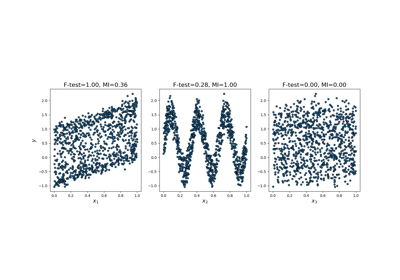
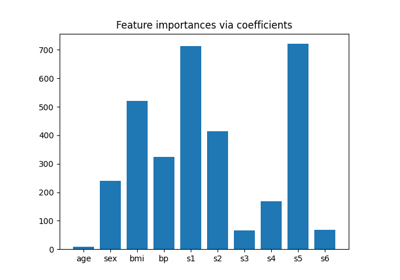
特征选择#
有关的例子 sklearn.feature_selection module.


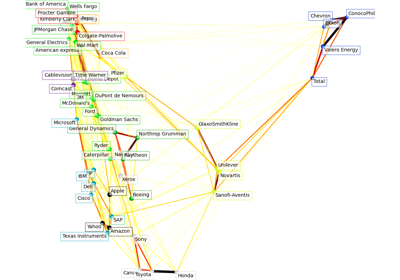
冻结的估计者#
有关的例子 sklearn.frozen module.

高斯混合模型#
有关的例子 sklearn.mixture module.

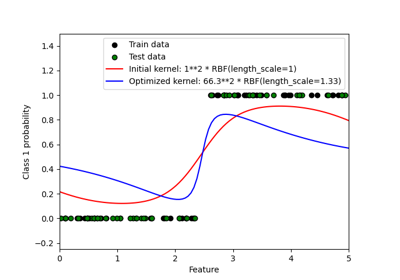
机器学习的高斯过程#
有关的例子 sklearn.gaussian_process module.
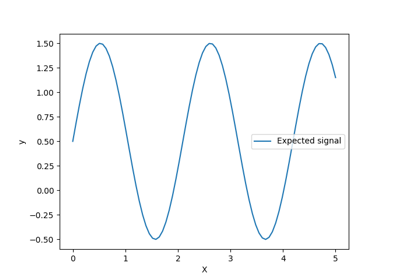
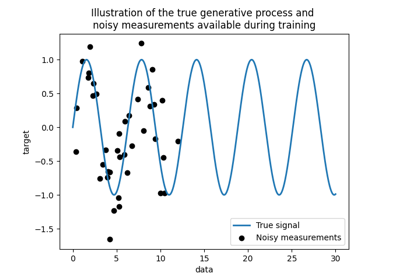
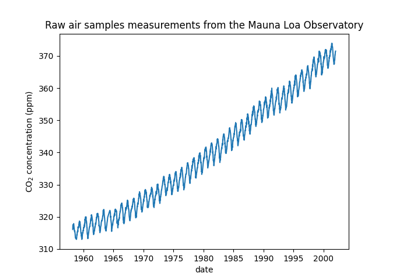
使用高斯过程回归(GPT)预测Mona Loa数据集的二氧化碳水平
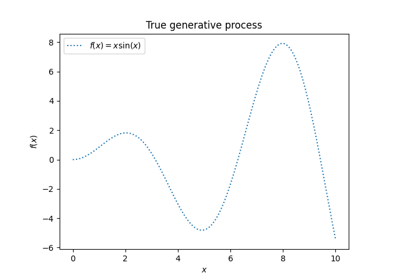
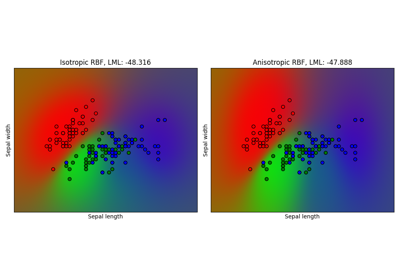
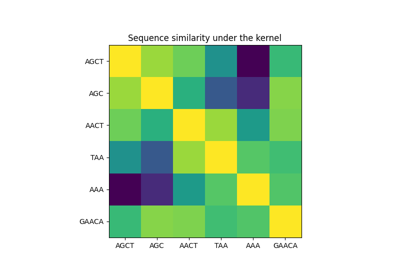
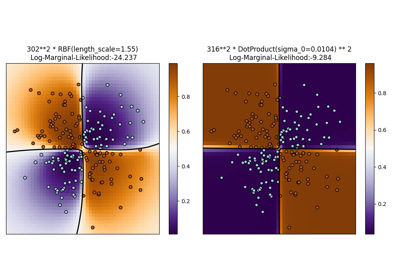
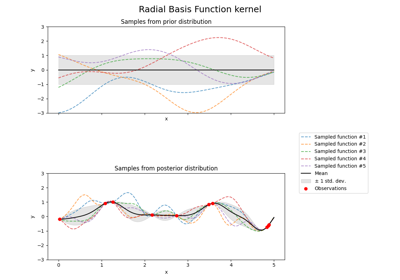
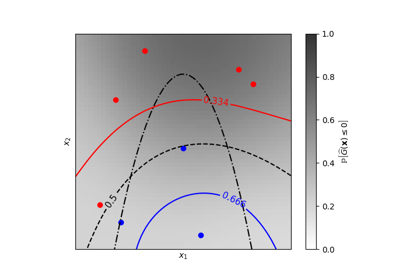
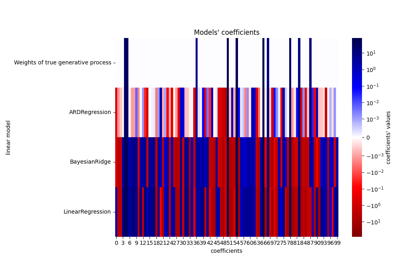
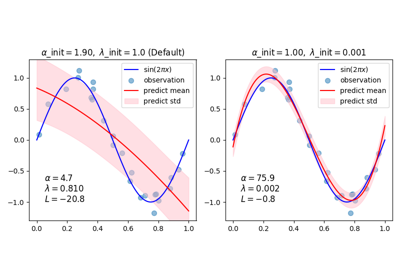
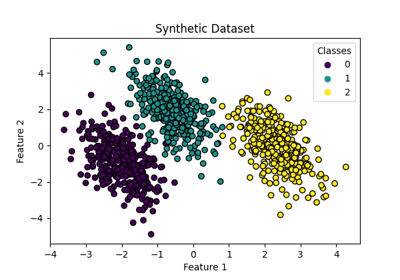
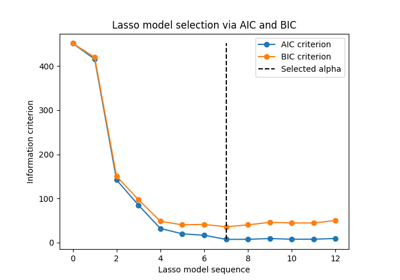
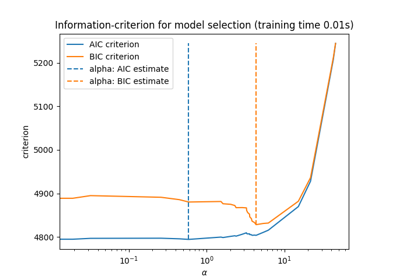
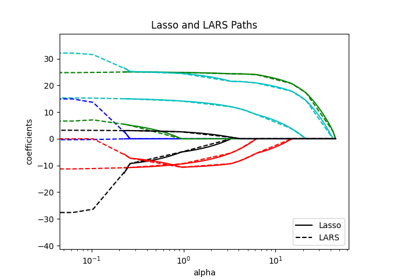
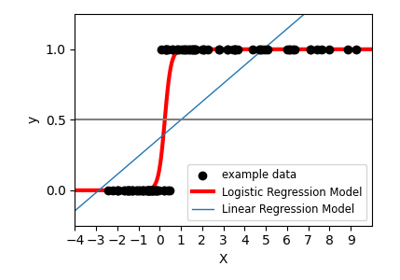
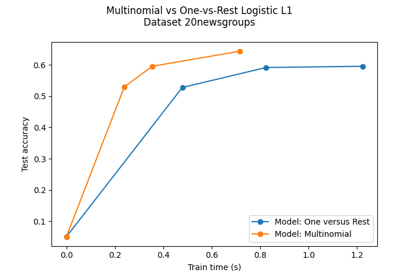
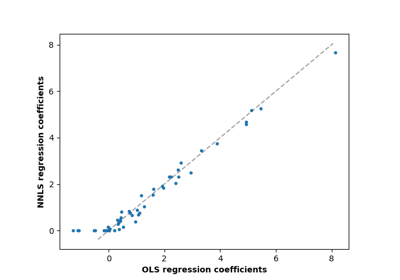
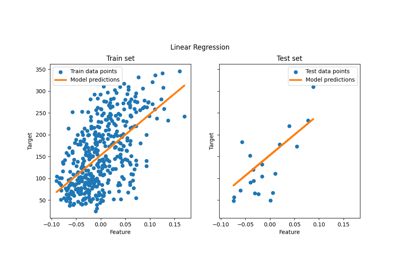
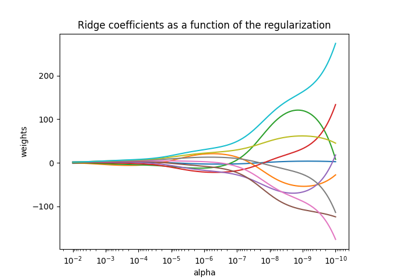
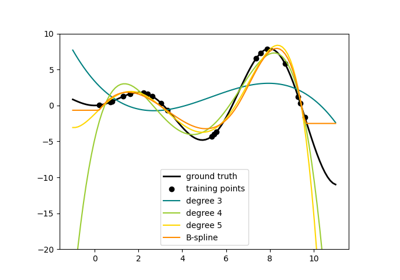
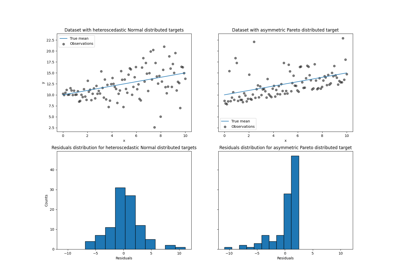
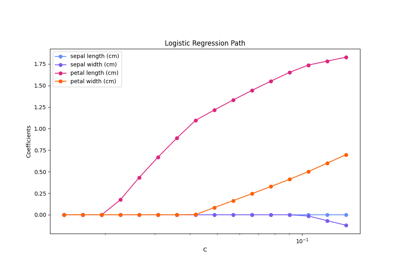
广义线性模型#
有关的例子 sklearn.linear_model module.






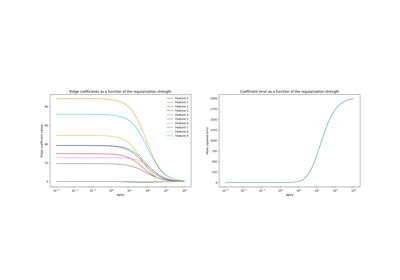
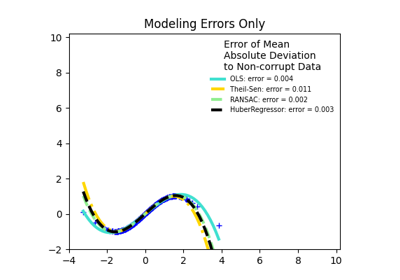
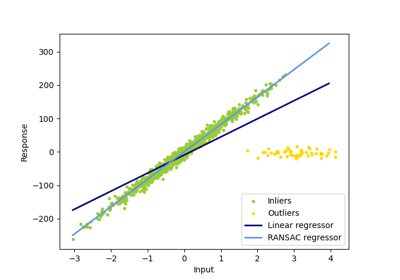
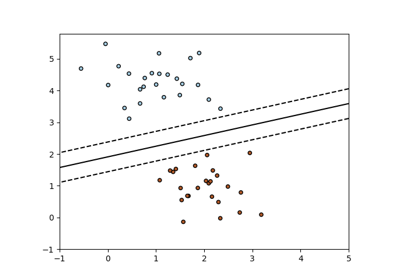
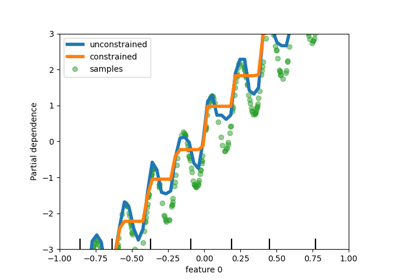
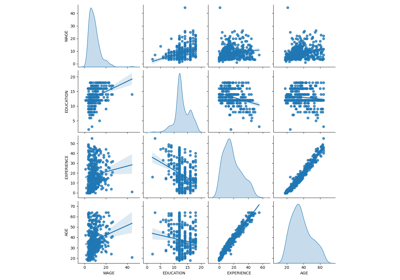
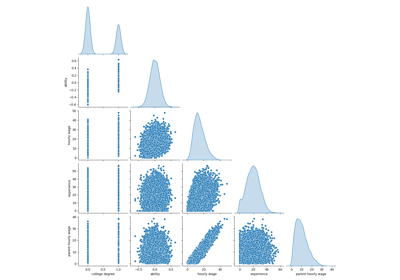
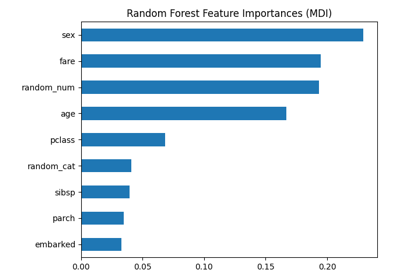
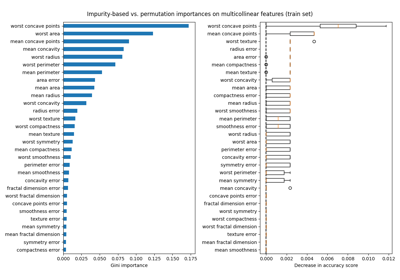
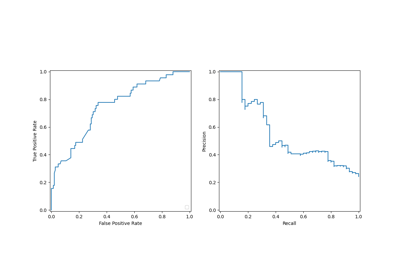
检查#
与 sklearn.inspection module.
核近似#
有关的例子 sklearn.kernel_approximation module.
流形学习#
有关的例子 sklearn.manifold module.


杂项#
scikit-learn的其他和介绍性示例。



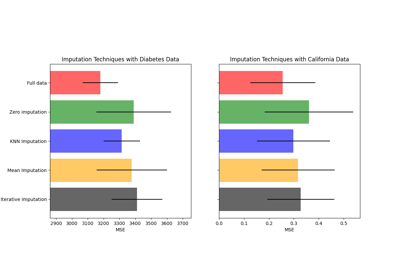
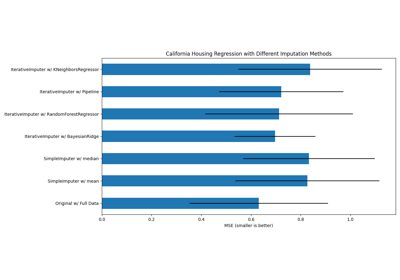
缺失值插补#
有关的例子 sklearn.impute module.
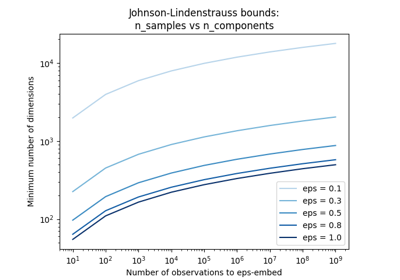
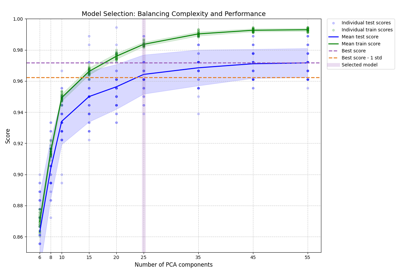
模型选择#
与 sklearn.model_selection module.

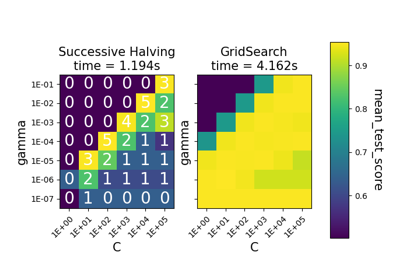

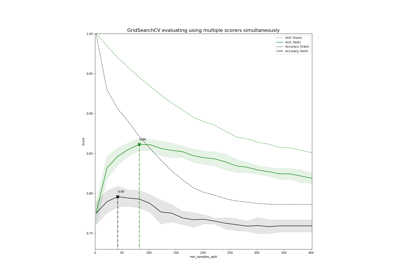
基于cross_val_score和GridSearchCV的多度量评估演示
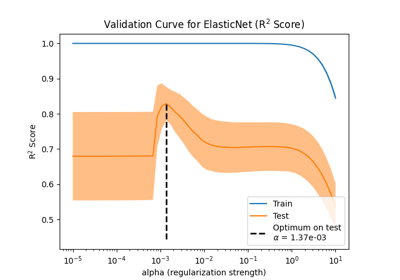
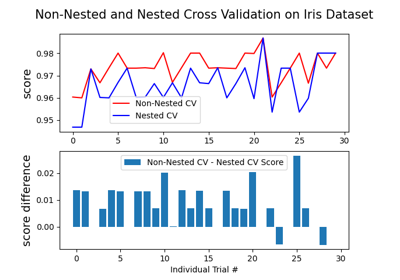
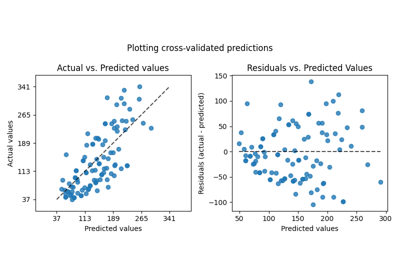



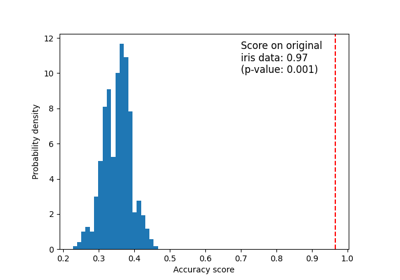
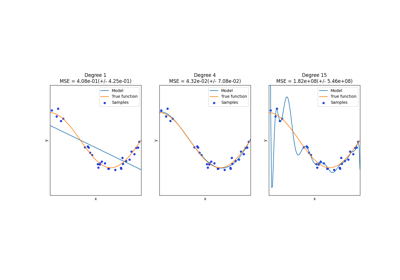
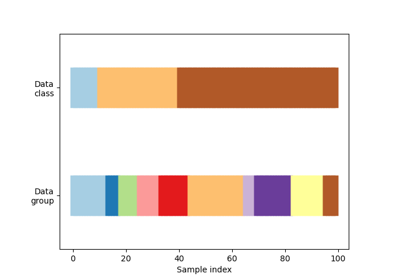
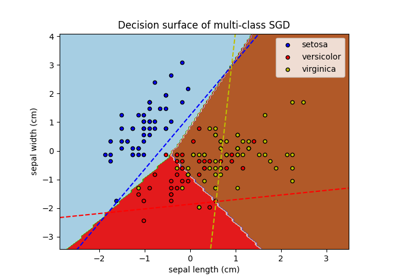
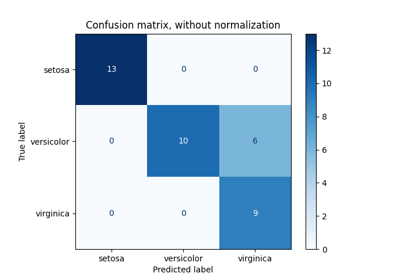
多类方法#
有关的例子 sklearn.multiclass module.
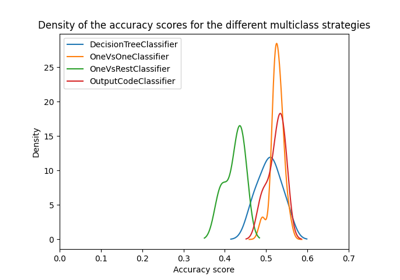
多输出方法#
有关的例子 sklearn.multioutput module.
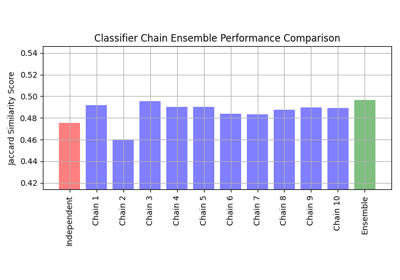
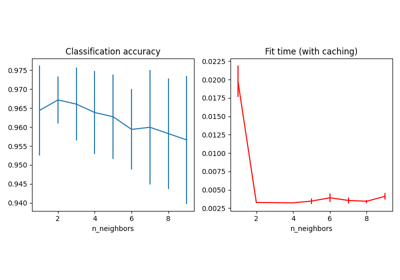
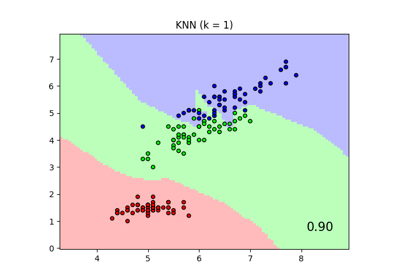
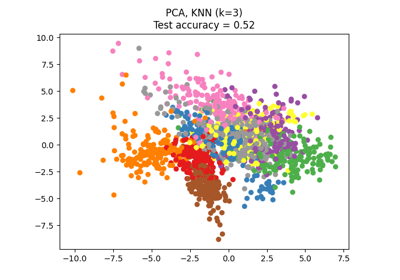
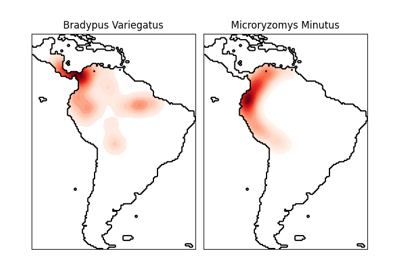
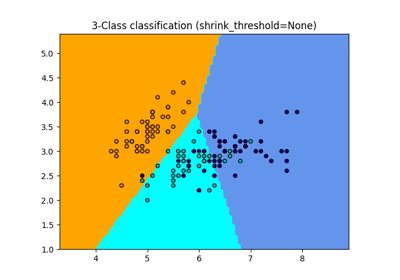
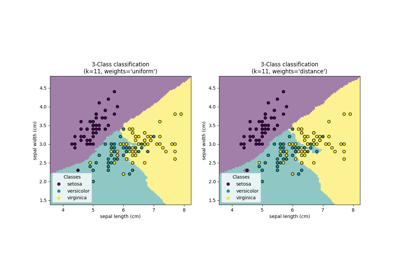
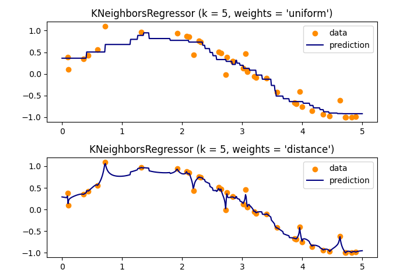
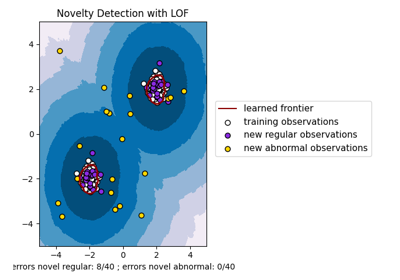
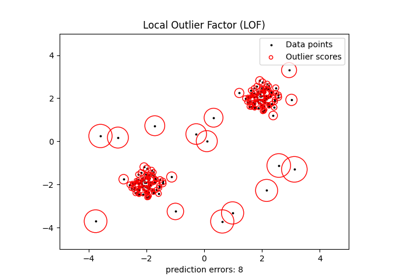
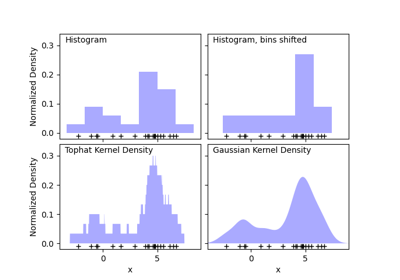
最近邻居#
有关的例子 sklearn.neighbors module.


神经网络#
有关的例子 sklearn.neural_network module.


管道和复合估计量#
如何从其他估计器组成变压器和管道的示例。看到 User Guide .

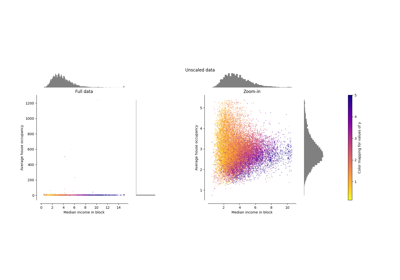
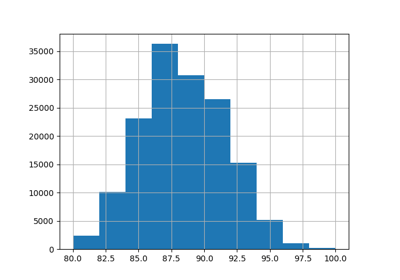
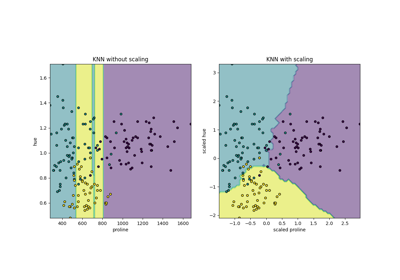
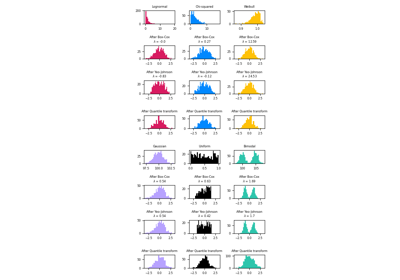
预处理#
有关的例子 sklearn.preprocessing module.
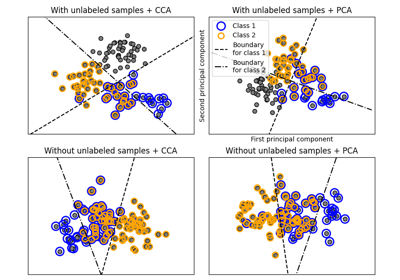
半监督分类#
有关的例子 sklearn.semi_supervised module.


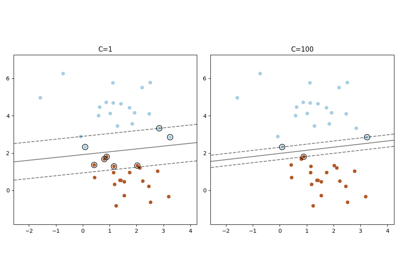
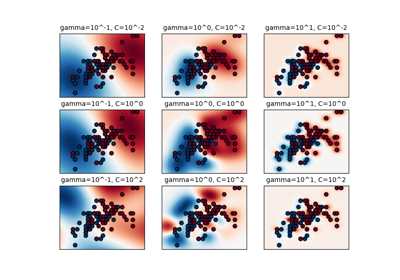
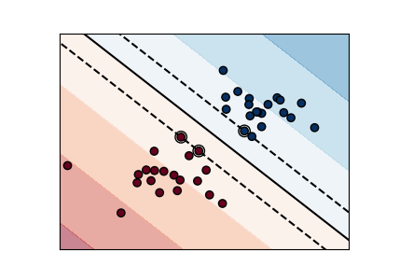
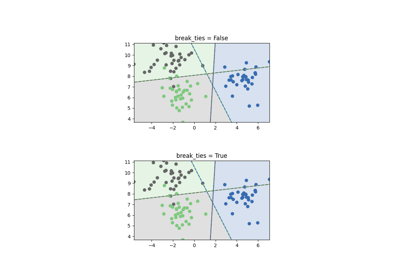
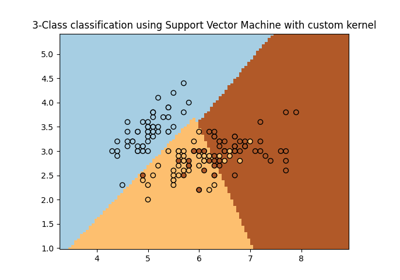
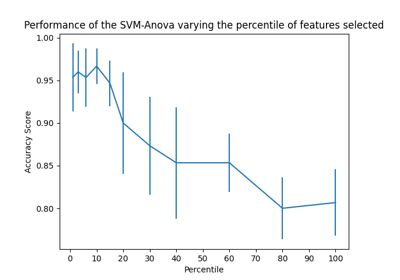
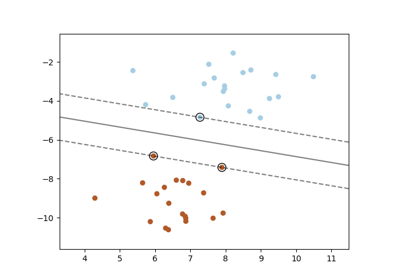
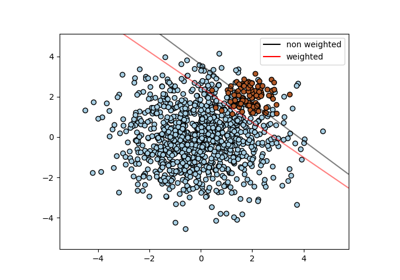
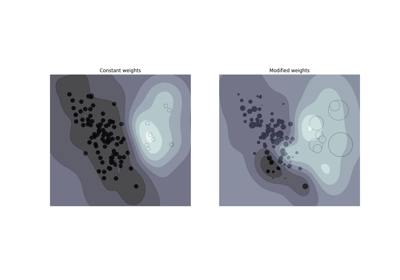
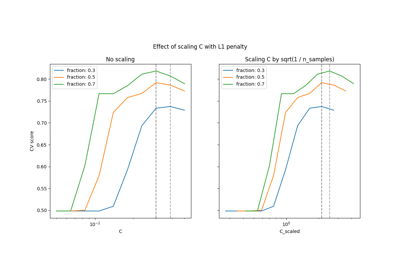
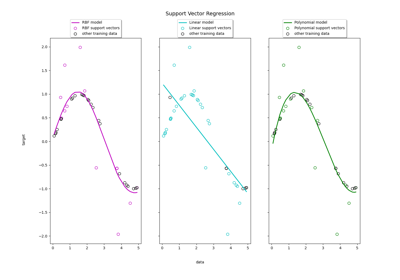
支持向量机#
有关的例子 sklearn.svm module.
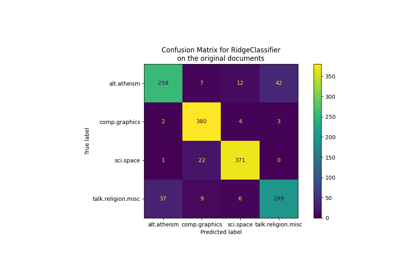
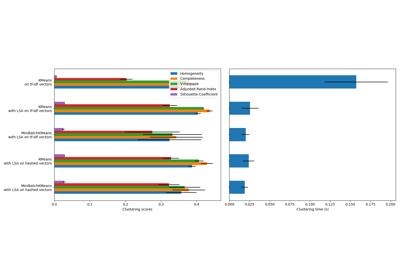
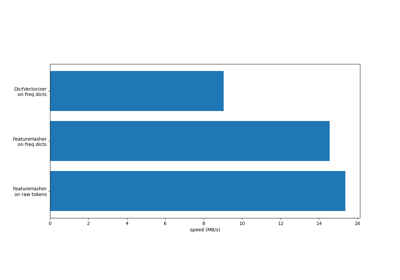
使用文本文档#
有关的例子 sklearn.feature_extraction.text module.
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _