备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
pr曲线#
评估分类器输出质量的精确召回指标示例。
当类别非常不平衡时,精确召回是预测成功的一个有用的度量。在信息检索中,查准率是指实际返回的项目中相关项目所占的比例,而查全率是指所有应该返回的项目中返回的项目所占的比例。这里的“相关性”是指被正面标记的项目,即,真阳性和假阴性。
精度 (\(P\) )定义为真阳性的数量 (\(T_p\) )超过真阳性数量加上假阳性数量 (\(F_p\) ).
召回 (\(R\) )定义为真阳性的数量 (\(T_p\) )超过真阳性数量加上假阴性数量 (\(F_n\) ).
准确率-召回率曲线显示了不同阈值下准确率和召回率之间的权衡。曲线下的高区域代表高召回率和高精度。通过返回的结果中几乎没有假阳性来实现高精度,通过相关结果中几乎没有假阴性来实现高召回。两者的高分表明分类器返回准确的结果(高精度),以及返回所有相关结果的大部分(高召回率)。
召回率高但精确度低的系统会返回大部分相关项目,但返回的结果被错误标记的比例很高。精确度高但召回率低的系统恰恰相反,返回的相关项目很少,但与实际标签相比,其大多数预测标签都是正确的。具有高精度和高召回率的理想系统将返回大多数相关项目,并且大多数结果都被正确标记。
精确度的定义 (\(\frac{T_p}{T_p + F_p}\) )表明降低分类器的阈值可能会通过增加返回的结果数量来增加分母。如果之前阈值设置得太高,新结果可能都是真阳性,这将提高精确度。如果之前的阈值大约正确或太低,进一步降低阈值将引入假阳性,从而降低精确度。
召回的定义是 \(\frac{T_p}{T_p+F_n}\) ,在哪里 \(T_p+F_n\) 不取决于分类器阈值。改变分类器阈值只能改变分子, \(T_p\) .降低分类器阈值可以通过增加真阳性结果的数量来提高召回率。也有可能降低阈值可能会使召回率保持不变,而精确度会波动。因此,准确性不一定会随着召回而下降。
在情节的阶梯区域可以观察到召回率和精确度之间的关系--在这些步骤的边缘,阈值的微小变化会大大降低精确度,而召回率只有微小的增加。
Average precision (AP)总结了这样的图,即每个阈值下达到的准确度的加权平均值,将召回率较前一阈值的增加用作权重:
\(\text{AP} = \sum_n (R_n - R_{n-1}) P_n\)
哪里 \(P_n\) 和 \(R_n\) 是第n个阈值处的准确率和召回率。一对 \((R_k, P_k)\) 被称为 operating point .
AP和操作点下方的梯状区域 (sklearn.metrics.auc )是总结准确率-召回曲线的常见方法,会导致不同的结果。阅读更多的 User Guide .
精确召回曲线通常用于二进制分类中来研究分类器的输出。为了将准确率-召回曲线和平均准确率扩展到多类别或多标签分类,有必要对输出进行二进制化。每个标签可以绘制一条曲线,但也可以通过将标签指示符矩阵的每个元素视为二元预测来绘制精确召回曲线 (micro-averaging ).
备注
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
在二进制分类设置中#
数据集和模型#
我们将使用线性SRC分类器来区分两种类型的虹膜。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
# Add noisy features
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.concatenate([X, random_state.randn(n_samples, 200 * n_features)], axis=1)
# Limit to the two first classes, and split into training and test
X_train, X_test, y_train, y_test = train_test_split(
X[y < 2], y[y < 2], test_size=0.5, random_state=random_state
)
线性SRC期望每个功能具有相似的值范围。因此,我们将首先使用 StandardScaler .
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
classifier = make_pipeline(StandardScaler(), LinearSVC(random_state=random_state))
classifier.fit(X_train, y_train)
绘制精确-召回曲线#
要绘制准确率-召回曲线,您应该使用 PrecisionRecallDisplay .事实上,有两种方法可用,具体取决于您是否已经计算了分类器的预测。
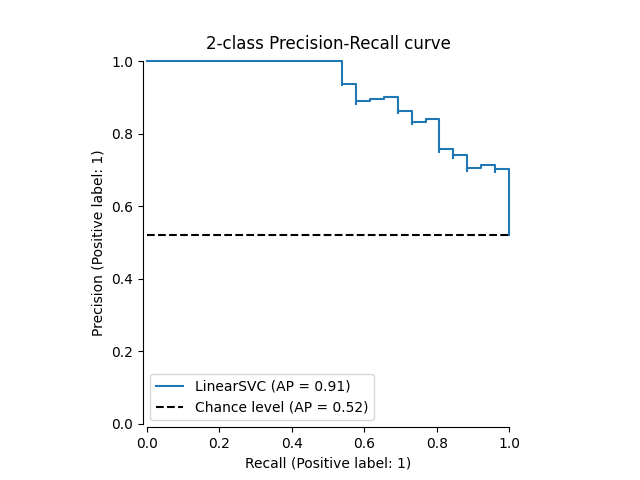
让我们首先绘制没有分类器预测的准确率-召回率曲线。我们使用 from_estimator 它在绘制曲线之前为我们计算预测。
from sklearn.metrics import PrecisionRecallDisplay
display = PrecisionRecallDisplay.from_estimator(
classifier, X_test, y_test, name="LinearSVC", plot_chance_level=True, despine=True
)
_ = display.ax_.set_title("2-class Precision-Recall curve")
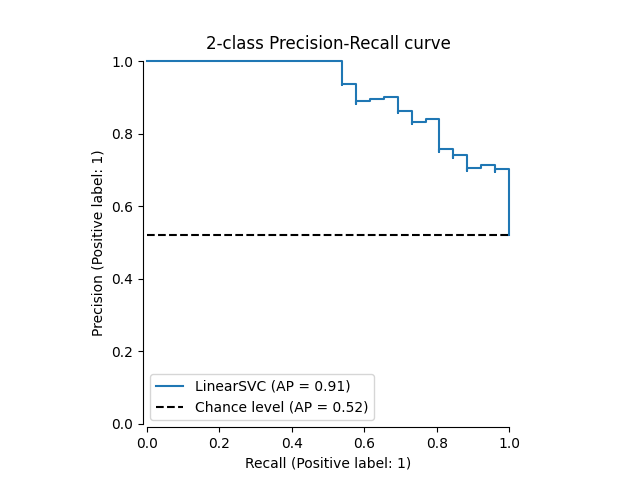
如果我们已经获得了模型的估计概率或分数,那么我们可以使用 from_predictions .
y_score = classifier.decision_function(X_test)
display = PrecisionRecallDisplay.from_predictions(
y_test, y_score, name="LinearSVC", plot_chance_level=True, despine=True
)
_ = display.ax_.set_title("2-class Precision-Recall curve")
在多标签设置中#
精确度-召回率曲线不支持多标签设置。但是,人们可以决定如何处理这个案件。我们在下面展示这样一个例子。
创建多标签数据、匹配和预测#
我们创建一个多标签数据集,以说明多标签设置中的精确召回。
from sklearn.preprocessing import label_binarize
# Use label_binarize to be multi-label like settings
Y = label_binarize(y, classes=[0, 1, 2])
n_classes = Y.shape[1]
# Split into training and test
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.5, random_state=random_state
)
我们使用 OneVsRestClassifier 用于多标签预测。
from sklearn.multiclass import OneVsRestClassifier
classifier = OneVsRestClassifier(
make_pipeline(StandardScaler(), LinearSVC(random_state=random_state))
)
classifier.fit(X_train, Y_train)
y_score = classifier.decision_function(X_test)
多标签设置中的平均精度分数#
from sklearn.metrics import average_precision_score, precision_recall_curve
# For each class
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(Y_test[:, i], y_score[:, i])
average_precision[i] = average_precision_score(Y_test[:, i], y_score[:, i])
# A "micro-average": quantifying score on all classes jointly
precision["micro"], recall["micro"], _ = precision_recall_curve(
Y_test.ravel(), y_score.ravel()
)
average_precision["micro"] = average_precision_score(Y_test, y_score, average="micro")
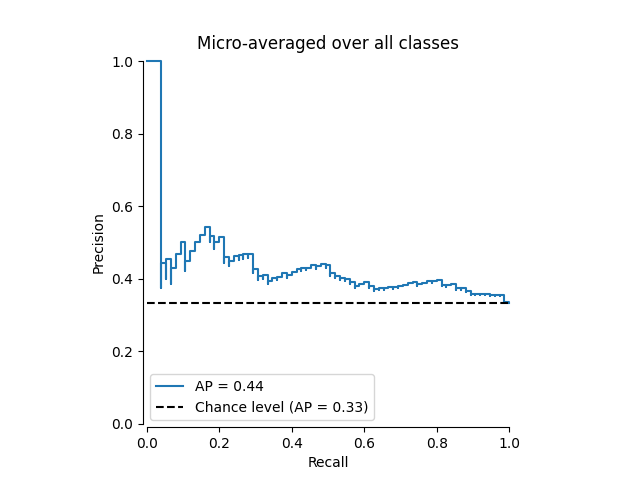
绘制微平均精度-召回曲线#
from collections import Counter
display = PrecisionRecallDisplay(
recall=recall["micro"],
precision=precision["micro"],
average_precision=average_precision["micro"],
prevalence_pos_label=Counter(Y_test.ravel())[1] / Y_test.size,
)
display.plot(plot_chance_level=True, despine=True)
_ = display.ax_.set_title("Micro-averaged over all classes")
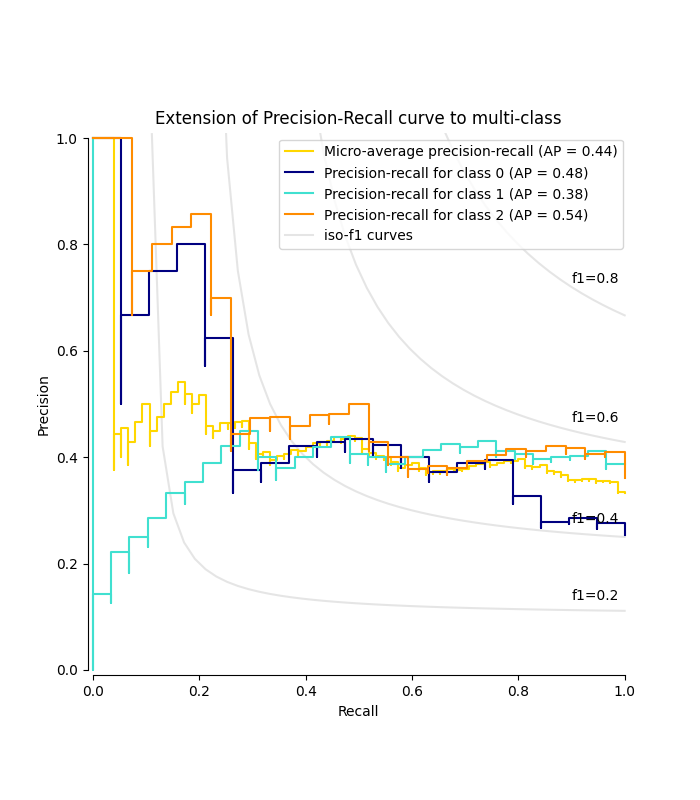
绘制每个类别的精确召回曲线和iso-f1曲线#
from itertools import cycle
import matplotlib.pyplot as plt
# setup plot details
colors = cycle(["navy", "turquoise", "darkorange", "cornflowerblue", "teal"])
_, ax = plt.subplots(figsize=(7, 8))
f_scores = np.linspace(0.2, 0.8, num=4)
lines, labels = [], []
for f_score in f_scores:
x = np.linspace(0.01, 1)
y = f_score * x / (2 * x - f_score)
(l,) = plt.plot(x[y >= 0], y[y >= 0], color="gray", alpha=0.2)
plt.annotate("f1={0:0.1f}".format(f_score), xy=(0.9, y[45] + 0.02))
display = PrecisionRecallDisplay(
recall=recall["micro"],
precision=precision["micro"],
average_precision=average_precision["micro"],
)
display.plot(ax=ax, name="Micro-average precision-recall", color="gold")
for i, color in zip(range(n_classes), colors):
display = PrecisionRecallDisplay(
recall=recall[i],
precision=precision[i],
average_precision=average_precision[i],
)
display.plot(
ax=ax, name=f"Precision-recall for class {i}", color=color, despine=True
)
# add the legend for the iso-f1 curves
handles, labels = display.ax_.get_legend_handles_labels()
handles.extend([l])
labels.extend(["iso-f1 curves"])
# set the legend and the axes
ax.legend(handles=handles, labels=labels, loc="best")
ax.set_title("Extension of Precision-Recall curve to multi-class")
plt.show()
Total running time of the script: (0分0.432秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _