备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
归纳集群#
Clustering can be expensive, especially when our dataset contains millions of datapoints. Many clustering algorithms are not inductive and so cannot be directly applied to new data samples without recomputing the clustering, which may be intractable. Instead, we can use clustering to then learn an inductive model with a classifier, which has several benefits:
它允许集群扩展并应用于新数据
与将集群重新适应新样本不同,它确保标签程序随着时间的推移保持一致
它允许我们使用分类器的推理能力来描述或解释集群
这个例子说明了元估计器的通用实现,它通过从集群标签中引入分类器来扩展集群。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.base import BaseEstimator, clone
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.utils.metaestimators import available_if
from sklearn.utils.validation import check_is_fitted
N_SAMPLES = 5000
RANDOM_STATE = 42
def _classifier_has(attr):
"""Check if we can delegate a method to the underlying classifier.
First, we check the first fitted classifier if available, otherwise we
check the unfitted classifier.
"""
return lambda estimator: (
hasattr(estimator.classifier_, attr)
if hasattr(estimator, "classifier_")
else hasattr(estimator.classifier, attr)
)
class InductiveClusterer(BaseEstimator):
def __init__(self, clusterer, classifier):
self.clusterer = clusterer
self.classifier = classifier
def fit(self, X, y=None):
self.clusterer_ = clone(self.clusterer)
self.classifier_ = clone(self.classifier)
y = self.clusterer_.fit_predict(X)
self.classifier_.fit(X, y)
return self
@available_if(_classifier_has("predict"))
def predict(self, X):
check_is_fitted(self)
return self.classifier_.predict(X)
@available_if(_classifier_has("decision_function"))
def decision_function(self, X):
check_is_fitted(self)
return self.classifier_.decision_function(X)
def plot_scatter(X, color, alpha=0.5):
return plt.scatter(X[:, 0], X[:, 1], c=color, alpha=alpha, edgecolor="k")
# Generate some training data from clustering
X, y = make_blobs(
n_samples=N_SAMPLES,
cluster_std=[1.0, 1.0, 0.5],
centers=[(-5, -5), (0, 0), (5, 5)],
random_state=RANDOM_STATE,
)
# Train a clustering algorithm on the training data and get the cluster labels
clusterer = AgglomerativeClustering(n_clusters=3)
cluster_labels = clusterer.fit_predict(X)
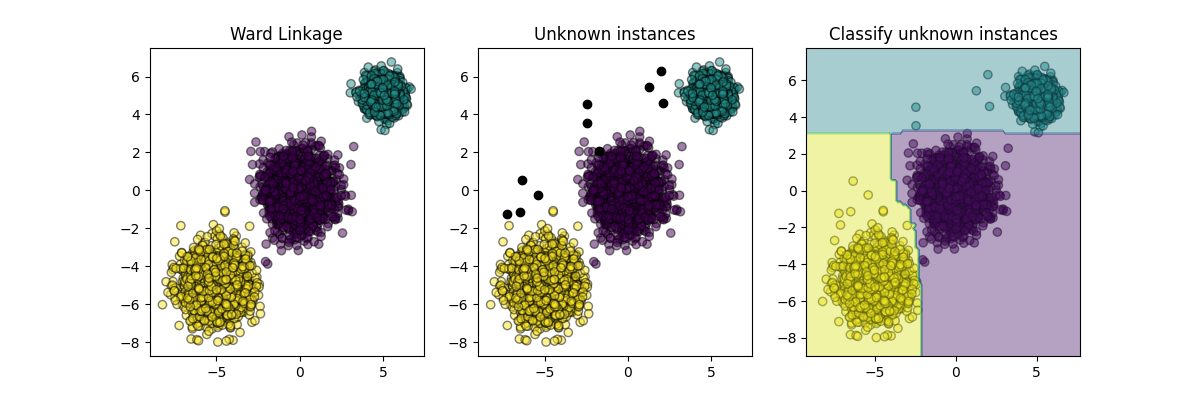
plt.figure(figsize=(12, 4))
plt.subplot(131)
plot_scatter(X, cluster_labels)
plt.title("Ward Linkage")
# Generate new samples and plot them along with the original dataset
X_new, y_new = make_blobs(
n_samples=10, centers=[(-7, -1), (-2, 4), (3, 6)], random_state=RANDOM_STATE
)
plt.subplot(132)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, "black", 1)
plt.title("Unknown instances")
# Declare the inductive learning model that it will be used to
# predict cluster membership for unknown instances
classifier = RandomForestClassifier(random_state=RANDOM_STATE)
inductive_learner = InductiveClusterer(clusterer, classifier).fit(X)
probable_clusters = inductive_learner.predict(X_new)
ax = plt.subplot(133)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, probable_clusters)
# Plotting decision regions
DecisionBoundaryDisplay.from_estimator(
inductive_learner, X, response_method="predict", alpha=0.4, ax=ax
)
plt.title("Classify unknown instances")
plt.show()
Total running time of the script: (0分1.268秒)
相关实例


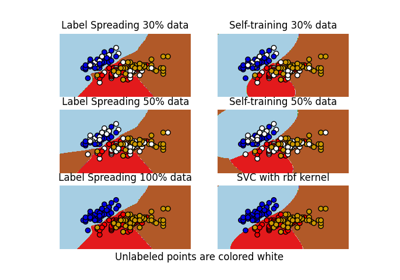
Decision boundary of semi-supervised classifiers versus SVM on the Iris dataset
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _