备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
非负矩阵分解和潜在Dirichlet分配的主题提取#
这是一个应用的例子 NMF 和 LatentDirichletAllocation 在文档库上提取该文档库的主题结构的添加模型。 输出是主题图,每个主题都用基于权重的前几个单词表示为条形图。
非负矩阵分解应用于两个不同的目标函数:Frobenius模和广义Kullback-Leibler分歧。后者相当于概率潜在语义索引。
默认参数(n_samples / n_features / n_components)应该使示例在几十秒内即可运行。您可以尝试增加问题的维度,但请注意,NMF中的时间复杂性是多项的。在LDA中,时间复杂度与(n_samples * 迭代)成正比。

Loading dataset...
done in 0.770s.
Extracting tf-idf features for NMF...
done in 0.163s.
Extracting tf features for LDA...
done in 0.160s.
Fitting the NMF model (Frobenius norm) with tf-idf features, n_samples=2000 and n_features=1000...
done in 0.098s.
Fitting the NMF model (generalized Kullback-Leibler divergence) with tf-idf features, n_samples=2000 and n_features=1000...
done in 1.609s.
Fitting the MiniBatchNMF model (Frobenius norm) with tf-idf features, n_samples=2000 and n_features=1000, batch_size=128...
done in 0.095s.
Fitting the MiniBatchNMF model (generalized Kullback-Leibler divergence) with tf-idf features, n_samples=2000 and n_features=1000, batch_size=128...
done in 0.214s.
Fitting LDA models with tf features, n_samples=2000 and n_features=1000...
done in 1.921s.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from time import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_20newsgroups
from sklearn.decomposition import NMF, LatentDirichletAllocation, MiniBatchNMF
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
n_samples = 2000
n_features = 1000
n_components = 10
n_top_words = 20
batch_size = 128
init = "nndsvda"
def plot_top_words(model, feature_names, n_top_words, title):
fig, axes = plt.subplots(2, 5, figsize=(30, 15), sharex=True)
axes = axes.flatten()
for topic_idx, topic in enumerate(model.components_):
top_features_ind = topic.argsort()[-n_top_words:]
top_features = feature_names[top_features_ind]
weights = topic[top_features_ind]
ax = axes[topic_idx]
ax.barh(top_features, weights, height=0.7)
ax.set_title(f"Topic {topic_idx + 1}", fontdict={"fontsize": 30})
ax.tick_params(axis="both", which="major", labelsize=20)
for i in "top right left".split():
ax.spines[i].set_visible(False)
fig.suptitle(title, fontsize=40)
plt.subplots_adjust(top=0.90, bottom=0.05, wspace=0.90, hspace=0.3)
plt.show()
# Load the 20 newsgroups dataset and vectorize it. We use a few heuristics
# to filter out useless terms early on: the posts are stripped of headers,
# footers and quoted replies, and common English words, words occurring in
# only one document or in at least 95% of the documents are removed.
print("Loading dataset...")
t0 = time()
data, _ = fetch_20newsgroups(
shuffle=True,
random_state=1,
remove=("headers", "footers", "quotes"),
return_X_y=True,
)
data_samples = data[:n_samples]
print("done in %0.3fs." % (time() - t0))
# Use tf-idf features for NMF.
print("Extracting tf-idf features for NMF...")
tfidf_vectorizer = TfidfVectorizer(
max_df=0.95, min_df=2, max_features=n_features, stop_words="english"
)
t0 = time()
tfidf = tfidf_vectorizer.fit_transform(data_samples)
print("done in %0.3fs." % (time() - t0))
# Use tf (raw term count) features for LDA.
print("Extracting tf features for LDA...")
tf_vectorizer = CountVectorizer(
max_df=0.95, min_df=2, max_features=n_features, stop_words="english"
)
t0 = time()
tf = tf_vectorizer.fit_transform(data_samples)
print("done in %0.3fs." % (time() - t0))
print()
# Fit the NMF model
print(
"Fitting the NMF model (Frobenius norm) with tf-idf features, "
"n_samples=%d and n_features=%d..." % (n_samples, n_features)
)
t0 = time()
nmf = NMF(
n_components=n_components,
random_state=1,
init=init,
beta_loss="frobenius",
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=1,
).fit(tfidf)
print("done in %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
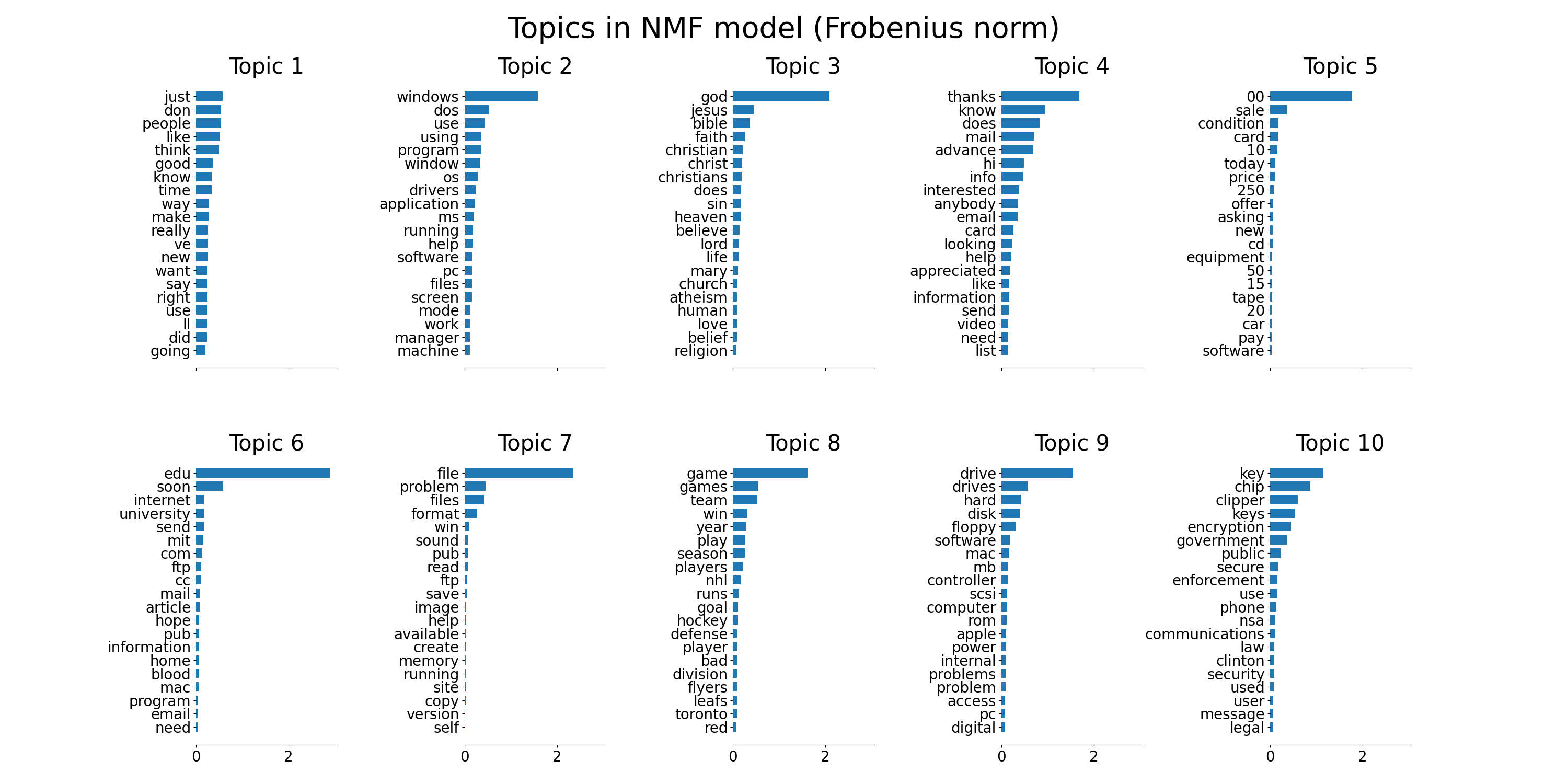
plot_top_words(
nmf, tfidf_feature_names, n_top_words, "Topics in NMF model (Frobenius norm)"
)
# Fit the NMF model
print(
"\n" * 2,
"Fitting the NMF model (generalized Kullback-Leibler "
"divergence) with tf-idf features, n_samples=%d and n_features=%d..."
% (n_samples, n_features),
)
t0 = time()
nmf = NMF(
n_components=n_components,
random_state=1,
init=init,
beta_loss="kullback-leibler",
solver="mu",
max_iter=1000,
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=0.5,
).fit(tfidf)
print("done in %0.3fs." % (time() - t0))
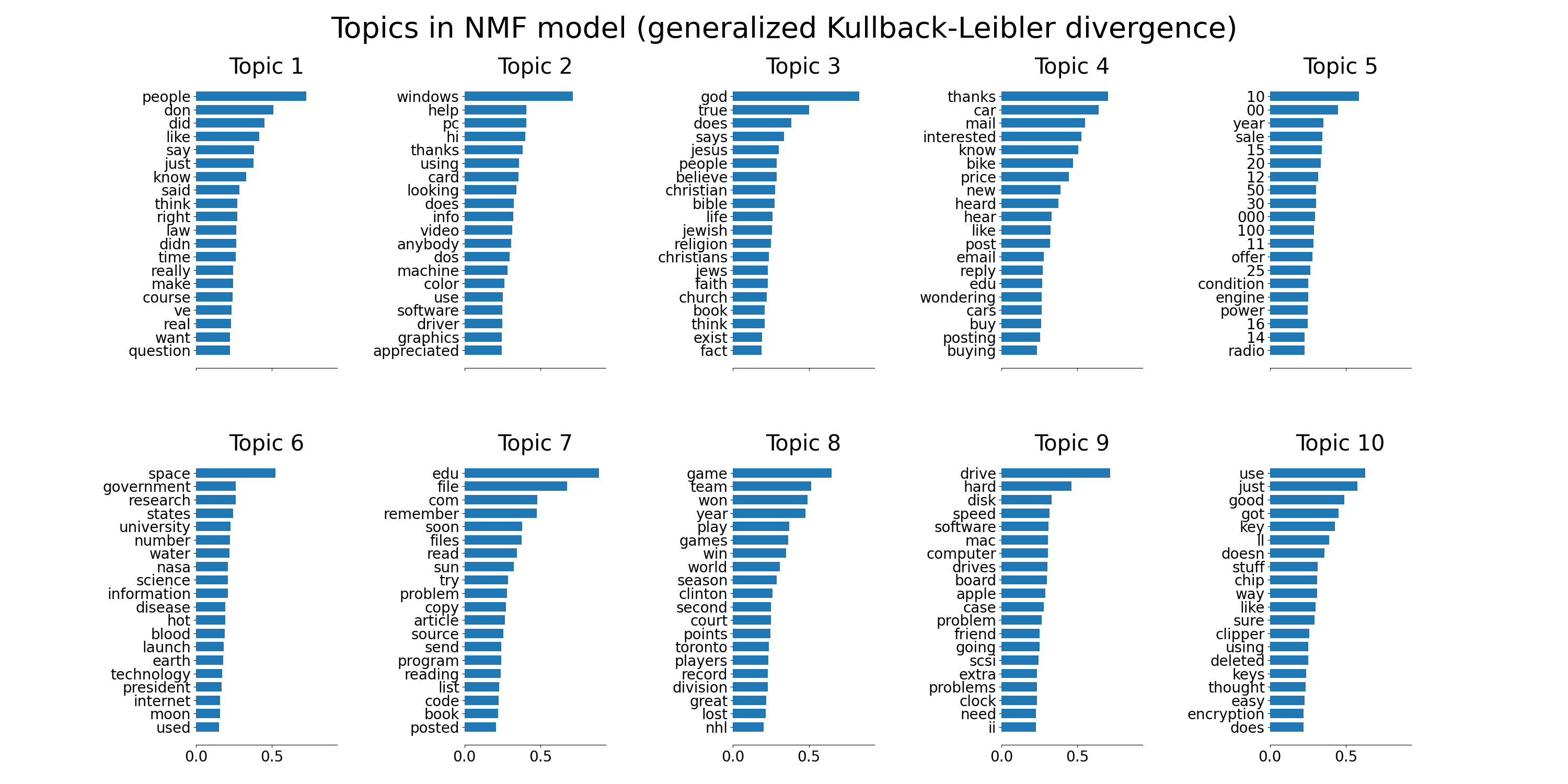
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
plot_top_words(
nmf,
tfidf_feature_names,
n_top_words,
"Topics in NMF model (generalized Kullback-Leibler divergence)",
)
# Fit the MiniBatchNMF model
print(
"\n" * 2,
"Fitting the MiniBatchNMF model (Frobenius norm) with tf-idf "
"features, n_samples=%d and n_features=%d, batch_size=%d..."
% (n_samples, n_features, batch_size),
)
t0 = time()
mbnmf = MiniBatchNMF(
n_components=n_components,
random_state=1,
batch_size=batch_size,
init=init,
beta_loss="frobenius",
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=0.5,
).fit(tfidf)
print("done in %0.3fs." % (time() - t0))
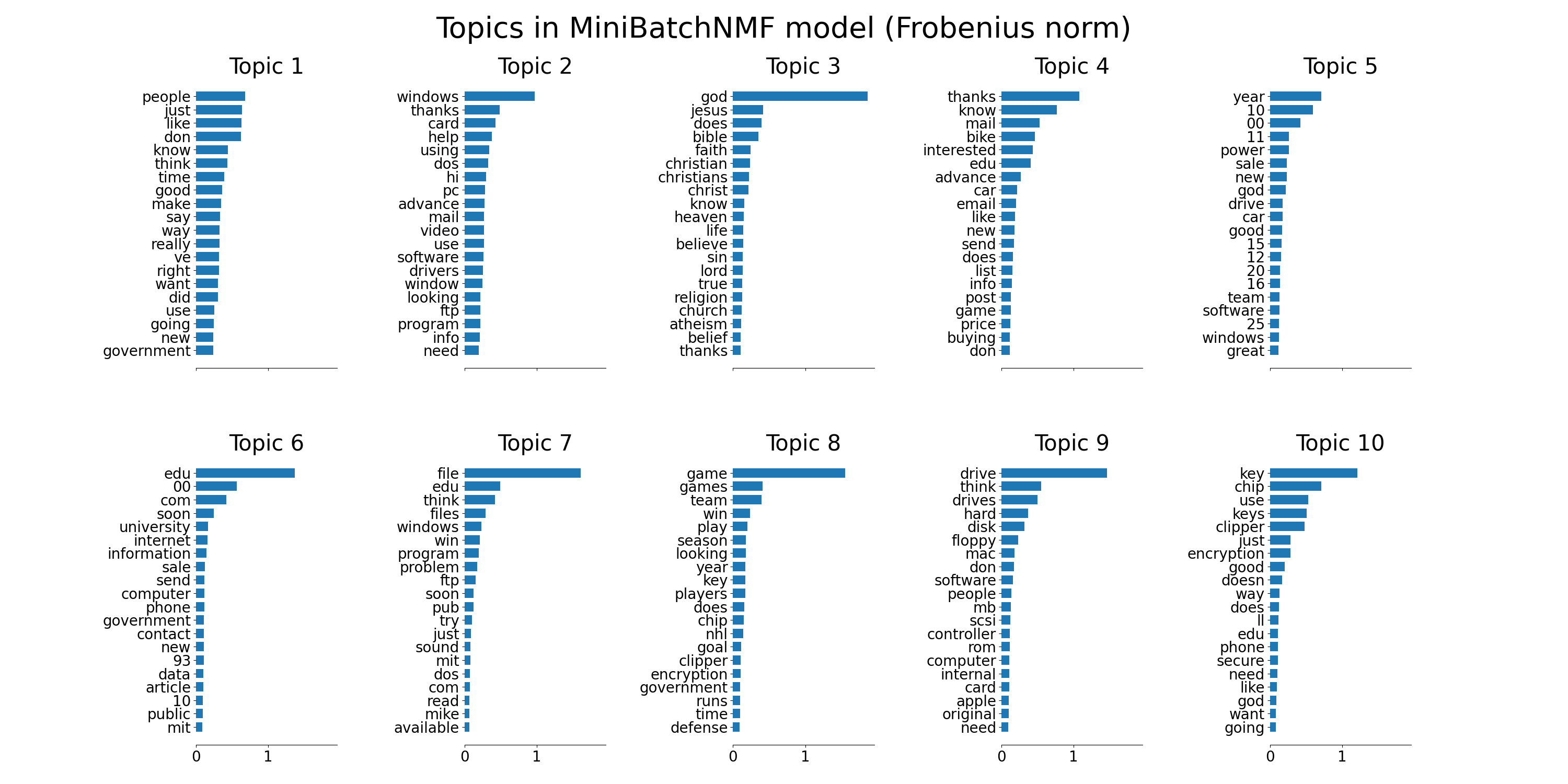
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
plot_top_words(
mbnmf,
tfidf_feature_names,
n_top_words,
"Topics in MiniBatchNMF model (Frobenius norm)",
)
# Fit the MiniBatchNMF model
print(
"\n" * 2,
"Fitting the MiniBatchNMF model (generalized Kullback-Leibler "
"divergence) with tf-idf features, n_samples=%d and n_features=%d, "
"batch_size=%d..." % (n_samples, n_features, batch_size),
)
t0 = time()
mbnmf = MiniBatchNMF(
n_components=n_components,
random_state=1,
batch_size=batch_size,
init=init,
beta_loss="kullback-leibler",
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=0.5,
).fit(tfidf)
print("done in %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
plot_top_words(
mbnmf,
tfidf_feature_names,
n_top_words,
"Topics in MiniBatchNMF model (generalized Kullback-Leibler divergence)",
)
print(
"\n" * 2,
"Fitting LDA models with tf features, n_samples=%d and n_features=%d..."
% (n_samples, n_features),
)
lda = LatentDirichletAllocation(
n_components=n_components,
max_iter=5,
learning_method="online",
learning_offset=50.0,
random_state=0,
)
t0 = time()
lda.fit(tf)
print("done in %0.3fs." % (time() - t0))
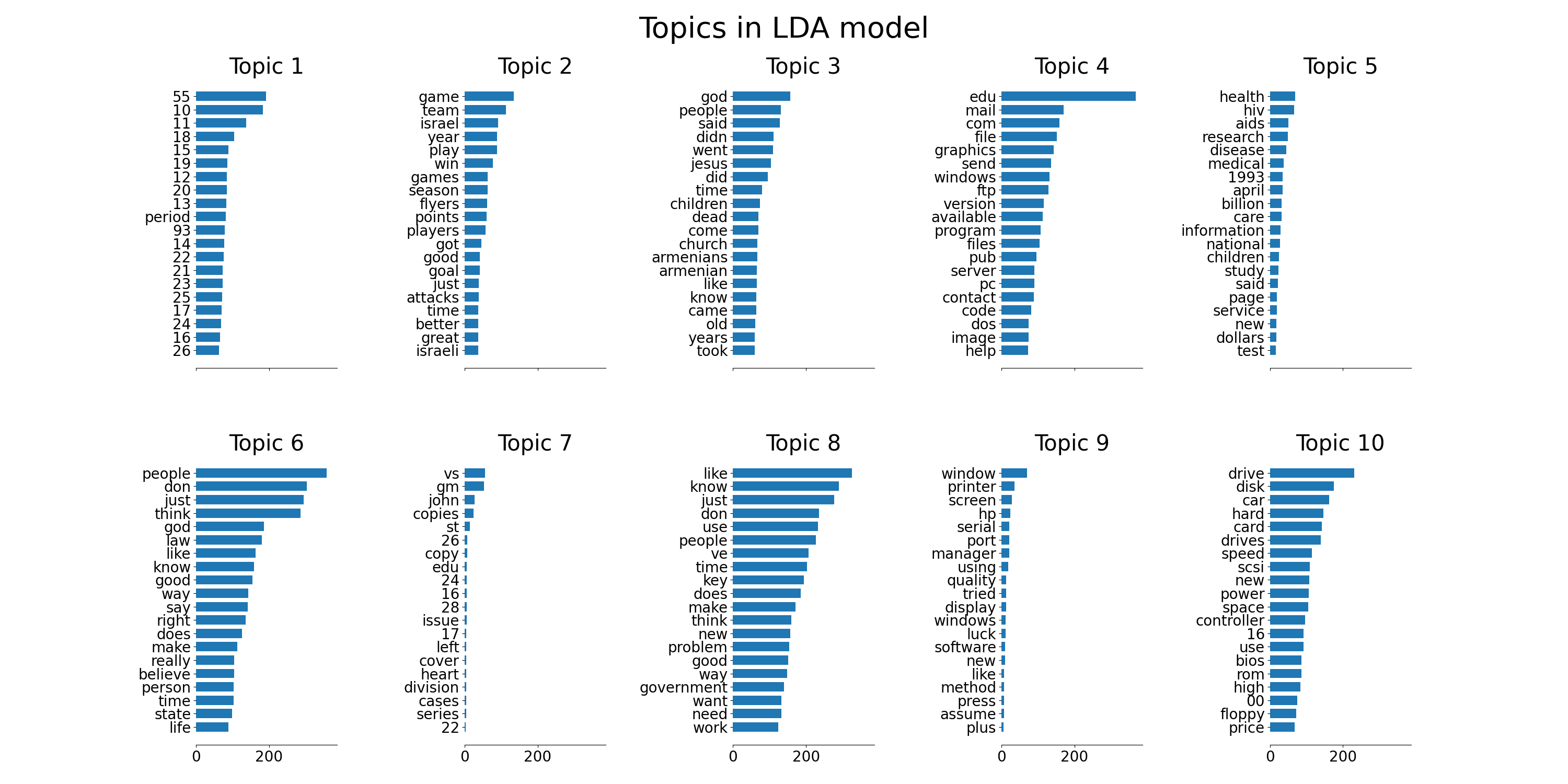
tf_feature_names = tf_vectorizer.get_feature_names_out()
plot_top_words(lda, tf_feature_names, n_top_words, "Topics in LDA model")
Total running time of the script: (0分8.895秒)
相关实例

Normal, Ledoit-Wolf and OAS Linear Discriminant Analysis for classification
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _