备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
树木森林的重要性#
此示例展示了使用树木森林来评估特征对人工分类任务的重要性。蓝色条是森林的特征重要性,以及由误差条代表的树间变异性。
正如预期的那样,该情节表明3个特征具有信息性,而其余的则不然。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
数据生成和模型匹配#
我们生成一个仅包含3个信息特征的合成数据集。我们将明确不对数据集进行洗牌,以确保信息特征将与X的前三列相对应。此外,我们将将数据集拆分为训练和测试子集。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False,
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
将采用随机森林分类器来计算特征重要性。
from sklearn.ensemble import RandomForestClassifier
feature_names = [f"feature {i}" for i in range(X.shape[1])]
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
基于杂质平均减少的特征重要性#
特征重要性由匹配属性提供 feature_importances_ 并计算为每棵树内杂质积累减少的平均值和标准差。
警告
基于杂质的特征重要性可能会产生误导 high cardinality 特性(许多独特的值)。看到 排列特征重要性 作为下面的替代。
import time
import numpy as np
start_time = time.time()
importances = forest.feature_importances_
std = np.std([tree.feature_importances_ for tree in forest.estimators_], axis=0)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
Elapsed time to compute the importances: 0.007 seconds
让我们描绘基于杂质的重要性。
import pandas as pd
forest_importances = pd.Series(importances, index=feature_names)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
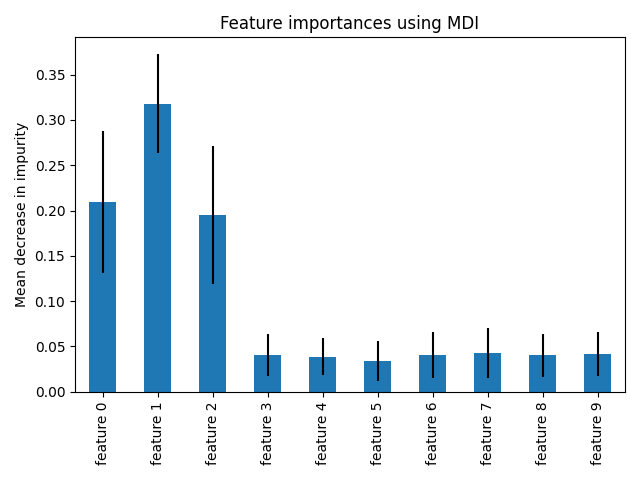
我们观察到,正如预期的那样,前三个特征被发现是重要的。
基于特征排列的特征重要性#
排列特征重要性克服了基于杂质的特征重要性的局限性:它们对高基数特征没有偏见,并且可以在遗漏的测试集上计算。
from sklearn.inspection import permutation_importance
start_time = time.time()
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
Elapsed time to compute the importances: 0.626 seconds
全排列重要性的计算成本更高。特征被洗牌n次,并重新调整模型以估计其重要性。请参阅 排列特征重要性 了解更多详细信息。我们现在可以绘制重要性排名。
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()

使用两种方法都会检测到相同的特征为最重要的。尽管相对重要性各不相同。正如图中所示,与排列重要性相比,Millennium不太可能完全省略某个特征。
Total running time of the script: (0分1.055秒)
相关实例
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _