备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
使用网格搜索进行模型统计比较#
此示例说明如何统计比较使用 GridSearchCV .
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
我们将从模拟月亮形状的数据(其中类之间的理想分离是非线性的)开始,向其添加适度的噪声。数据点将属于由两个特征预测的两个可能类别之一。我们将为每个类模拟50个样本:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_moons
X, y = make_moons(noise=0.352, random_state=1, n_samples=100)
sns.scatterplot(
x=X[:, 0], y=X[:, 1], hue=y, marker="o", s=25, edgecolor="k", legend=False
).set_title("Data")
plt.show()
我们将比较 SVC 其估计值各不相同 kernel 参数,以决定这个超参数中的哪一个选择最能预测我们的模拟数据。我们将使用以下方法评估模型的性能 RepeatedStratifiedKFold ,在每次重复中使用不同的数据随机化,重复10次10重分层交叉验证。性能将通过使用评估 roc_auc_score .
from sklearn.model_selection import GridSearchCV, RepeatedStratifiedKFold
from sklearn.svm import SVC
param_grid = [
{"kernel": ["linear"]},
{"kernel": ["poly"], "degree": [2, 3]},
{"kernel": ["rbf"]},
]
svc = SVC(random_state=0)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=10, random_state=0)
search = GridSearchCV(estimator=svc, param_grid=param_grid, scoring="roc_auc", cv=cv)
search.fit(X, y)
我们现在可以检查搜索结果,按他们的排序 mean_test_score :
import pandas as pd
results_df = pd.DataFrame(search.cv_results_)
results_df = results_df.sort_values(by=["rank_test_score"])
results_df = results_df.set_index(
results_df["params"].apply(lambda x: "_".join(str(val) for val in x.values()))
).rename_axis("kernel")
results_df[["params", "rank_test_score", "mean_test_score", "std_test_score"]]
我们可以看到,使用 'rbf' 内核表现最好,紧随其后 'linear' .两个估计器均为a 'poly' 内核的性能更差,使用二次方程的内核的性能比所有其他模型低得多。
通常,分析就在这里结束,但故事的一半却不见了。的输出 GridSearchCV 不提供有关模型之间差异的确定性的信息。我们不知道这些是否是 statistically 显著为了评估这一点,我们需要进行统计测试。具体来说,为了比较两个模型的性能,我们应该从统计上比较它们的UC分数。每个模型有100个样本(AUC评分),因为我们重复了10次10次10次交叉验证。
然而,模型的分数并不独立:所有模型都在 same 100个分区,增加了模型性能之间的相关性。由于数据的某些分区可能会使所有模型的类别区分变得特别容易或难以找到,因此模型分数将协变。
让我们通过绘制每个折叠中所有模型的性能并计算跨折叠模型之间的相关性来检查这种分区效应:
# create df of model scores ordered by performance
model_scores = results_df.filter(regex=r"split\d*_test_score")
# plot 30 examples of dependency between cv fold and AUC scores
fig, ax = plt.subplots()
sns.lineplot(
data=model_scores.transpose().iloc[:30],
dashes=False,
palette="Set1",
marker="o",
alpha=0.5,
ax=ax,
)
ax.set_xlabel("CV test fold", size=12, labelpad=10)
ax.set_ylabel("Model AUC", size=12)
ax.tick_params(bottom=True, labelbottom=False)
plt.show()
# print correlation of AUC scores across folds
print(f"Correlation of models:\n {model_scores.transpose().corr()}")
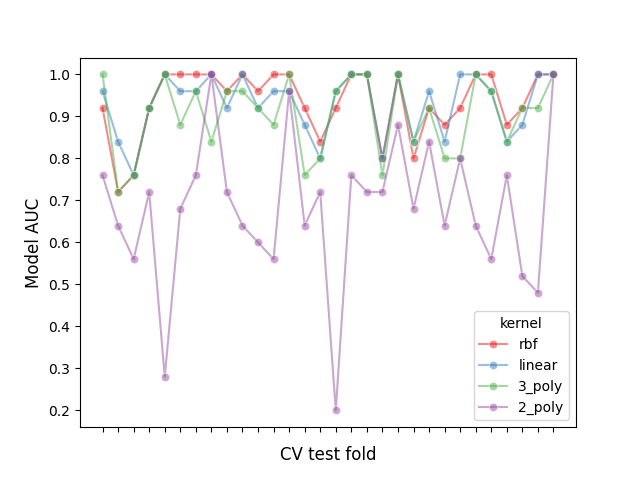
Correlation of models:
kernel rbf linear 3_poly 2_poly
kernel
rbf 1.000000 0.882561 0.783392 0.351390
linear 0.882561 1.000000 0.746492 0.298688
3_poly 0.783392 0.746492 1.000000 0.355440
2_poly 0.351390 0.298688 0.355440 1.000000
我们可以观察到模型的性能高度取决于折叠率。
因此,如果我们假设样本之间的独立性,我们将低估统计测试中计算的方差,从而增加假阳性错误的数量(即在模型之间不存在显着差异时检测到显着差异) [1].
针对这些情况开发了几种方差修正统计测试。在这个例子中,我们将展示如何在两个不同的统计框架下实现其中之一(所谓的纳多和Bengio的修正t检验):频率论和Bayesian。
比较两种模型:频率论方法#
我们可以首先问:“第一个模型是否明显优于第二个模型(按 mean_test_score )? "
为了使用频率论方法回答这个问题,我们可以运行配对t检验并计算p值。这在预测文献中也被称为迪博尔德-马里亚诺测试 [5]. 已经开发了此类t检验的许多变体来解决上一节描述的“样本的非独立性问题”。我们将使用被证明可以获得最高可复制性分数的分数(在同一数据集的不同随机分区上评估模型时,评估模型的性能的相似程度),同时保持较低的假阳性和假阴性率:Nadeau和Bengio的修正t检验 [2] 使用10次重复10倍交叉验证 [3].
该修正的配对t检验计算为:
哪里 \(k\) 是折痕的数量, \(r\) 交叉验证中的重复次数, \(x\) 是模型性能的差异, \(n_{test}\) 是用于测试的样本数量, \(n_{train}\) 是用于训练的样本数,并且 \(\hat{\sigma}^2\) 代表观察到的差异的方差。
让我们实现一个修正的右尾配对t检验,以评估第一个模型的性能是否显着优于第二个模型的性能。我们的零假设是,第二个模型的表现至少与第一个模型一样好。
import numpy as np
from scipy.stats import t
def corrected_std(differences, n_train, n_test):
"""Corrects standard deviation using Nadeau and Bengio's approach.
Parameters
----------
differences : ndarray of shape (n_samples,)
Vector containing the differences in the score metrics of two models.
n_train : int
Number of samples in the training set.
n_test : int
Number of samples in the testing set.
Returns
-------
corrected_std : float
Variance-corrected standard deviation of the set of differences.
"""
# kr = k times r, r times repeated k-fold crossvalidation,
# kr equals the number of times the model was evaluated
kr = len(differences)
corrected_var = np.var(differences, ddof=1) * (1 / kr + n_test / n_train)
corrected_std = np.sqrt(corrected_var)
return corrected_std
def compute_corrected_ttest(differences, df, n_train, n_test):
"""Computes right-tailed paired t-test with corrected variance.
Parameters
----------
differences : array-like of shape (n_samples,)
Vector containing the differences in the score metrics of two models.
df : int
Degrees of freedom.
n_train : int
Number of samples in the training set.
n_test : int
Number of samples in the testing set.
Returns
-------
t_stat : float
Variance-corrected t-statistic.
p_val : float
Variance-corrected p-value.
"""
mean = np.mean(differences)
std = corrected_std(differences, n_train, n_test)
t_stat = mean / std
p_val = t.sf(np.abs(t_stat), df) # right-tailed t-test
return t_stat, p_val
model_1_scores = model_scores.iloc[0].values # scores of the best model
model_2_scores = model_scores.iloc[1].values # scores of the second-best model
differences = model_1_scores - model_2_scores
n = differences.shape[0] # number of test sets
df = n - 1
n_train = len(next(iter(cv.split(X, y)))[0])
n_test = len(next(iter(cv.split(X, y)))[1])
t_stat, p_val = compute_corrected_ttest(differences, df, n_train, n_test)
print(f"Corrected t-value: {t_stat:.3f}\nCorrected p-value: {p_val:.3f}")
Corrected t-value: 0.750
Corrected p-value: 0.227
我们可以将修正后的t和p值与未修正的t和p值进行比较:
t_stat_uncorrected = np.mean(differences) / np.sqrt(np.var(differences, ddof=1) / n)
p_val_uncorrected = t.sf(np.abs(t_stat_uncorrected), df)
print(
f"Uncorrected t-value: {t_stat_uncorrected:.3f}\n"
f"Uncorrected p-value: {p_val_uncorrected:.3f}"
)
Uncorrected t-value: 2.611
Uncorrected p-value: 0.005
使用传统的显著性α水平, p=0.05 ,我们观察到未经修正的t检验得出的结论是,第一个模型明显优于第二个模型。
相比之下,使用正确的方法,我们无法检测到这种差异。
然而,在后一种情况下,频率论方法并不能让我们得出第一和第二模型具有等效性能的结论。如果我们想做出这一断言,我们需要使用Bayesian方法。
比较两个模型:Bayesian方法#
我们可以使用贝叶斯估计来计算第一个模型优于第二个模型的概率。贝叶斯估计将输出一个分布,然后是平均值 \(\mu\) 两种型号的性能差异。
为了获得后验分布,我们需要定义一个先验,该先验模型在查看数据之前对我们对平均值分布的信念进行建模,并将其乘以一个似然函数,该函数计算我们观察到的差异的可能性,给定差异的平均值可以取的值。
Bayesian估计可以以多种形式进行来回答我们的问题,但在这个例子中,我们将实现Benavoli及其同事建议的方法 [4].
使用封闭形式的公式定义后验的一种方法是选择似然函数的先验共乘。贝纳沃利和同事 [4] 表明,当比较两个分类器的性能时,我们可以将先验建模为与正态似然性相结合的正态-伽玛分布(均值和方差均未知),从而将后验表示为正态分布。将方差从这个正态后验边缘化,我们可以将均值参数的后验定义为Student t分布。具体而言:
哪里 \(n\) 是样本总数, \(\overline{x}\) 代表分数的平均差异, \(n_{test}\) 是用于测试的样本数量, \(n_{train}\) 是用于训练的样本数,并且 \(\hat{\sigma}^2\) 代表观察到的差异的方差。
请注意,我们在贝叶斯方法中也使用了纳多和本吉奥的校正方差。
让我们计算并绘制后验:
# initialize random variable
t_post = t(
df, loc=np.mean(differences), scale=corrected_std(differences, n_train, n_test)
)
让我们绘制后验分布:
x = np.linspace(t_post.ppf(0.001), t_post.ppf(0.999), 100)
plt.plot(x, t_post.pdf(x))
plt.xticks(np.arange(-0.04, 0.06, 0.01))
plt.fill_between(x, t_post.pdf(x), 0, facecolor="blue", alpha=0.2)
plt.ylabel("Probability density")
plt.xlabel(r"Mean difference ($\mu$)")
plt.title("Posterior distribution")
plt.show()
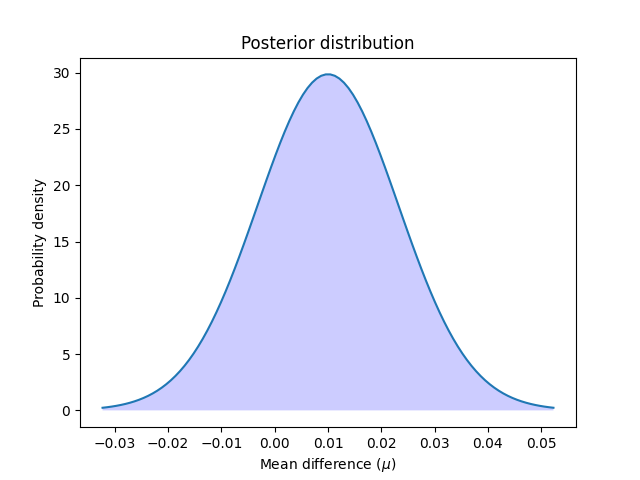
我们可以通过计算从零到无穷大的后验分布曲线下面积来计算第一个模型优于第二个模型的概率。反之亦然:我们可以通过计算从负无限到零的曲线下面积来计算第二个模型比第一个模型更好的概率。
better_prob = 1 - t_post.cdf(0)
print(
f"Probability of {model_scores.index[0]} being more accurate than "
f"{model_scores.index[1]}: {better_prob:.3f}"
)
print(
f"Probability of {model_scores.index[1]} being more accurate than "
f"{model_scores.index[0]}: {1 - better_prob:.3f}"
)
Probability of rbf being more accurate than linear: 0.773
Probability of linear being more accurate than rbf: 0.227
与频率论方法相比,我们可以计算一个模型比另一个更好的概率。
请注意,我们获得了与频率论方法类似的结果。考虑到我们对先验的选择,我们本质上正在执行相同的计算,但我们被允许做出不同的断言。
实践等效领域#
有时,我们有兴趣确定我们的模型具有等效性能的概率,其中“等效”是以实用的方式定义的。天真的做法 [4] 将被定义为实际等效的估计量时,他们的差异小于1%的准确性。但我们也可以在考虑到我们试图解决的问题的情况下定义这种实际等价。例如,5%的准确性差异意味着销售额增加1000美元,我们认为任何高于此的数量都与我们的业务相关。
在本例中,我们将定义实际等效区域(ROPE)为 \([-0.01, 0.01]\) .也就是说,如果两个模型的性能差异小于1%,我们将认为它们实际上是等效的。
为了计算分类器实际等效的概率,我们计算ROPE区间内后验曲线下的面积:
rope_interval = [-0.01, 0.01]
rope_prob = t_post.cdf(rope_interval[1]) - t_post.cdf(rope_interval[0])
print(
f"Probability of {model_scores.index[0]} and {model_scores.index[1]} "
f"being practically equivalent: {rope_prob:.3f}"
)
Probability of rbf and linear being practically equivalent: 0.432
我们可以绘制后验分布在ROPE区间上的分布:
x_rope = np.linspace(rope_interval[0], rope_interval[1], 100)
plt.plot(x, t_post.pdf(x))
plt.xticks(np.arange(-0.04, 0.06, 0.01))
plt.vlines([-0.01, 0.01], ymin=0, ymax=(np.max(t_post.pdf(x)) + 1))
plt.fill_between(x_rope, t_post.pdf(x_rope), 0, facecolor="blue", alpha=0.2)
plt.ylabel("Probability density")
plt.xlabel(r"Mean difference ($\mu$)")
plt.title("Posterior distribution under the ROPE")
plt.show()
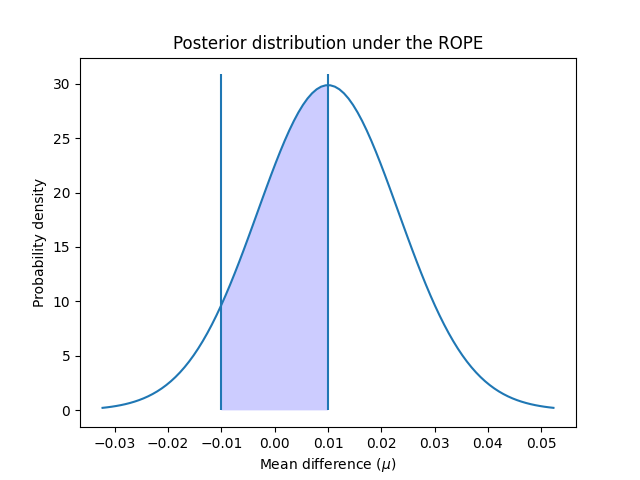
中建议的 [4], 我们可以使用与频率论方法相同的标准进一步解释这些可能性:落入ROPE内的可能性是否大于95%(阿尔法值为5%)? 在这种情况下,我们可以得出结论,两种模型实际上是等效的。
Bayesian估计方法还允许我们计算我们对差异估计的不确定性有多大。这可以使用可信的间隔来计算。对于给定的概率,它们显示了估计数量(在我们的情况下是性能的平均差异)可以采用的值范围。例如,50%的可信区间 [x, y] 告诉我们,模型之间的真实(平均)性能差异在x和y之间的概率为50%。
让我们使用50%、75%和95%来确定数据的可信区间:
cred_intervals = []
intervals = [0.5, 0.75, 0.95]
for interval in intervals:
cred_interval = list(t_post.interval(interval))
cred_intervals.append([interval, cred_interval[0], cred_interval[1]])
cred_int_df = pd.DataFrame(
cred_intervals, columns=["interval", "lower value", "upper value"]
).set_index("interval")
cred_int_df
如表中所示,模型之间的真实平均差异在0.000977和0.019023之间的可能性为50%,在-0.005422和0.025422之间的可能性为70%,在-0.016445和0.036445之间的可能性为95%。
所有模型的成对比较:频率论方法#
我们还可能有兴趣将我们评估的所有模型的性能与 GridSearchCV .在这种情况下,我们将多次运行统计测试,这将导致 multiple comparisons problem .
有很多可能的方法可以解决这个问题,但标准方法是应用 Bonferroni correction . Bonferroni可以通过将p值乘以我们正在测试的比较数量来计算。
让我们使用修正的t检验来比较模型的性能:
from itertools import combinations
from math import factorial
n_comparisons = factorial(len(model_scores)) / (
factorial(2) * factorial(len(model_scores) - 2)
)
pairwise_t_test = []
for model_i, model_k in combinations(range(len(model_scores)), 2):
model_i_scores = model_scores.iloc[model_i].values
model_k_scores = model_scores.iloc[model_k].values
differences = model_i_scores - model_k_scores
t_stat, p_val = compute_corrected_ttest(differences, df, n_train, n_test)
p_val *= n_comparisons # implement Bonferroni correction
# Bonferroni can output p-values higher than 1
p_val = 1 if p_val > 1 else p_val
pairwise_t_test.append(
[model_scores.index[model_i], model_scores.index[model_k], t_stat, p_val]
)
pairwise_comp_df = pd.DataFrame(
pairwise_t_test, columns=["model_1", "model_2", "t_stat", "p_val"]
).round(3)
pairwise_comp_df
我们观察到,在纠正多次比较后,唯一与其他模型显着不同的模型是 '2_poly' . 'rbf' ,该模型排名第一 GridSearchCV ,与 'linear' 或 '3_poly' .
所有模型的成对比较:Bayesian方法#
当使用Bayesian估计来比较多个模型时,我们不需要纠正多次比较(原因请参阅 [4]) .
我们可以按照与第一部分相同的方式进行成对比较:
pairwise_bayesian = []
for model_i, model_k in combinations(range(len(model_scores)), 2):
model_i_scores = model_scores.iloc[model_i].values
model_k_scores = model_scores.iloc[model_k].values
differences = model_i_scores - model_k_scores
t_post = t(
df, loc=np.mean(differences), scale=corrected_std(differences, n_train, n_test)
)
worse_prob = t_post.cdf(rope_interval[0])
better_prob = 1 - t_post.cdf(rope_interval[1])
rope_prob = t_post.cdf(rope_interval[1]) - t_post.cdf(rope_interval[0])
pairwise_bayesian.append([worse_prob, better_prob, rope_prob])
pairwise_bayesian_df = pd.DataFrame(
pairwise_bayesian, columns=["worse_prob", "better_prob", "rope_prob"]
).round(3)
pairwise_comp_df = pairwise_comp_df.join(pairwise_bayesian_df)
pairwise_comp_df
使用Bayesian方法,我们可以计算一个模型表现得更好、更差或实际上与另一个模型相当的概率。
结果表明,该模型排名第一 GridSearchCV 'rbf' ,大约有6.8%的机会比 'linear' ,比 '3_poly' . 'rbf' 和 'linear' 实际等效的可能性为43%,而 'rbf' 和 '3_poly' 有10%的可能性。
与使用频率论方法获得的结论类似,所有模型都有100%的可能性优于 '2_poly' ,并且没有一个具有与后者几乎相当的性能。
带回家的消息#
绩效指标中的微小差异很容易被证明只是偶然的,而不是因为一个模型比另一个模型系统性地预测得更好。如本例所示,统计数据可以告诉您这种情况的可能性有多大。
当对GridSearchCV中评估的两个模型的性能进行统计比较时,有必要纠正计算出的方差,因为模型的分数并不相互独立,因此可能会被低估。
使用(方差修正)配对t检验的频率论方法可以告诉我们一个模型的性能是否比另一个更好,并且确定性高于偶然性。
贝叶斯方法可以提供一个模型比另一个模型更好、更差或实际等同的概率。它还可以告诉我们,我们有多大的信心知道我们的模型的真正差异落在一定的值范围内。
如果对多个模型进行统计比较,则在使用频率论方法时需要进行多重比较修正。
引用
Total running time of the script: (0分1.271秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _