备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
真实数据集上的离群值检测#
这个例子说明了对真实数据集进行稳健协方差估计的需要。它对于异常值检测和更好地理解数据结构都很有用。
我们从Wine数据集中选择了两组由两个变量组成的两组,以说明可以使用多种异常值检测工具进行什么样的分析。出于可视化的目的,我们正在使用二维示例,但人们应该意识到,正如我们将要指出的那样,在多维中,事情并不那么微不足道。
在下面的两个例子中,主要结果是,经验协方差估计作为非稳健估计,受到观察的异类结构的高度影响。尽管稳健的协方差估计能够专注于数据分布的主要模式,但它坚持数据应该是高斯分布的假设,从而产生了对数据结构的一些有偏差的估计,但在某种程度上是准确的。单类支持机不假设数据分布的任何参数形式,因此可以更好地对数据的复杂形状进行建模。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
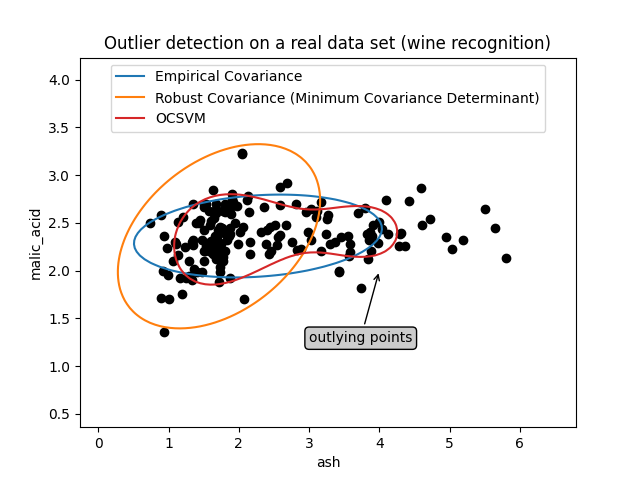
第一示例#
第一个例子说明了当存在离群点时,最小协方差决定性稳健估计器如何帮助集中在相关集群上。这里,经验协方差估计因主集群之外的点而倾斜。当然,一些筛选工具会指出两个集群的存在(支持载体机、高斯混合模型、单变量异常值检测.)。但如果这是一个多维的例子,那么这些都不可能那么容易应用。
from sklearn.covariance import EllipticEnvelope
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.svm import OneClassSVM
estimators = {
"Empirical Covariance": EllipticEnvelope(support_fraction=1.0, contamination=0.25),
"Robust Covariance (Minimum Covariance Determinant)": EllipticEnvelope(
contamination=0.25
),
"OCSVM": OneClassSVM(nu=0.25, gamma=0.35),
}
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
X = load_wine()["data"][:, [1, 2]] # two clusters
fig, ax = plt.subplots()
colors = ["tab:blue", "tab:orange", "tab:red"]
# Learn a frontier for outlier detection with several classifiers
legend_lines = []
for color, (name, estimator) in zip(colors, estimators.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
bbox_args = dict(boxstyle="round", fc="0.8")
arrow_args = dict(arrowstyle="->")
ax.annotate(
"outlying points",
xy=(4, 2),
xycoords="data",
textcoords="data",
xytext=(3, 1.25),
bbox=bbox_args,
arrowprops=arrow_args,
)
ax.legend(handles=legend_lines, loc="upper center")
_ = ax.set(
xlabel="ash",
ylabel="malic_acid",
title="Outlier detection on a real data set (wine recognition)",
)
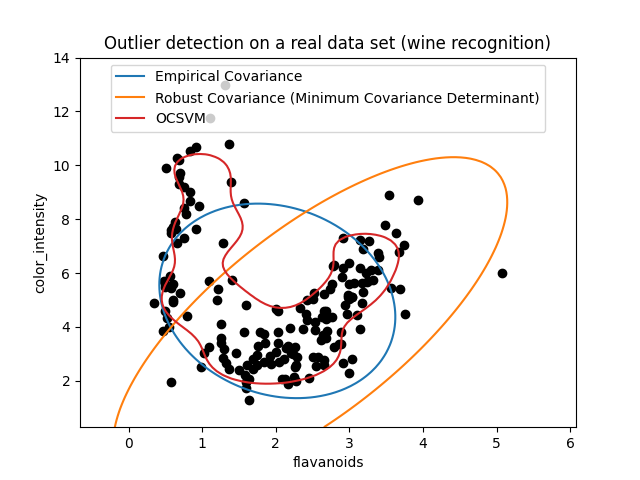
二示例#
第二个例子显示了最小协方差决定性协方差稳健估计器专注于数据分布主要模式的能力:位置似乎得到了很好的估计,尽管由于香蕉形分布,协方差很难估计。无论如何,我们可以消除一些离经叛道的观察。单类支持机能够捕获真实的数据结构,但困难在于调整其核带宽参数,以便在数据散布矩阵的形状和数据过拟合的风险之间获得良好的折衷。
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
fig, ax = plt.subplots()
colors = ["tab:blue", "tab:orange", "tab:red"]
# Learn a frontier for outlier detection with several classifiers
legend_lines = []
for color, (name, estimator) in zip(colors, estimators.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Outlier detection on a real data set (wine recognition)",
)
plt.show()
Total running time of the script: (0分0.255秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _