备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
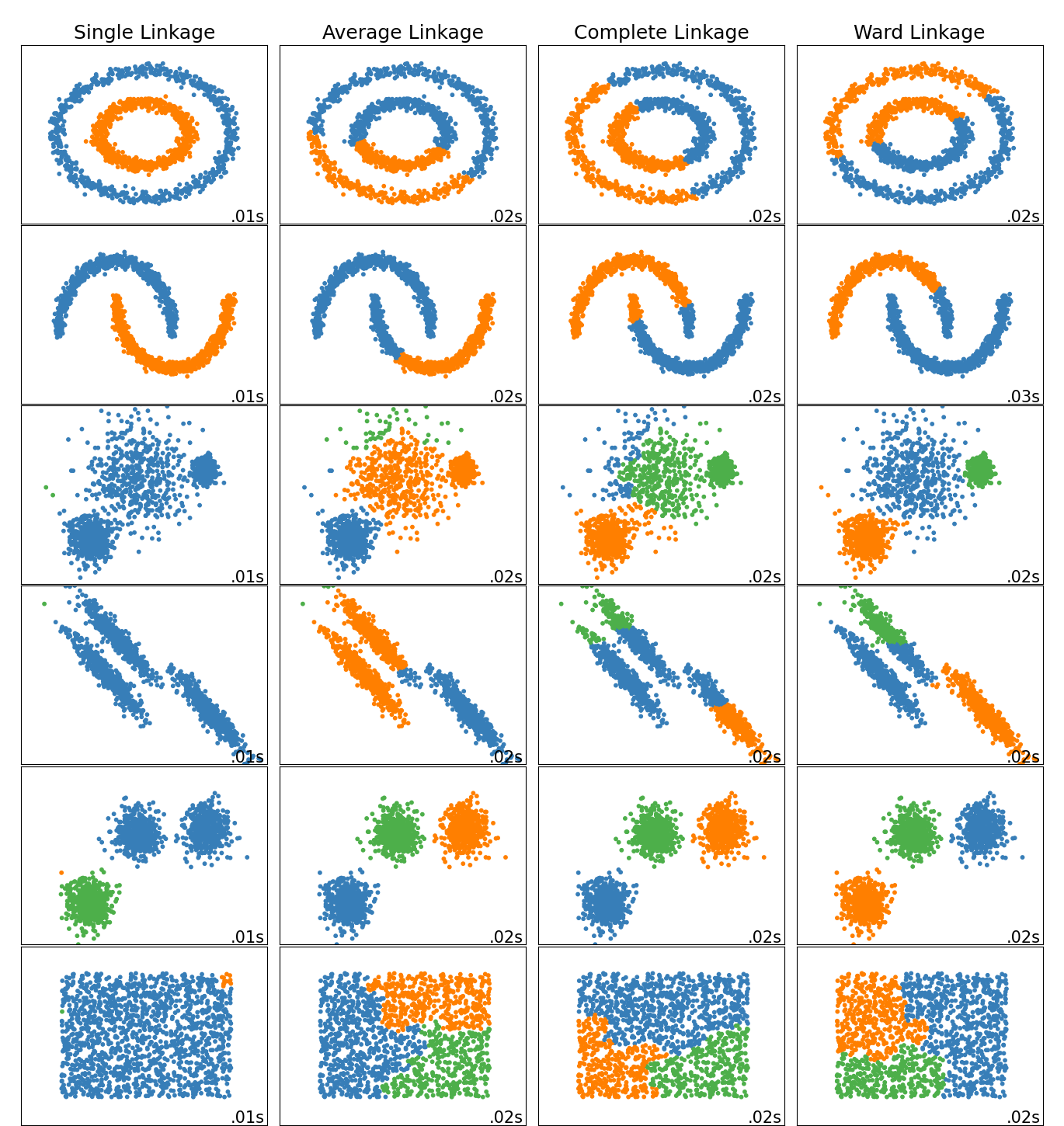
在玩具数据集上比较不同的分层链接方法#
此示例展示了对“有趣”但仍然是2D的数据集进行分层集群的不同链接方法的特征。
要做的主要观察是:
单一链接速度很快,并且可以在非球状数据上表现良好,但在存在噪音的情况下表现不佳。
平均和完全连锁在完全分离的球状集群上表现良好,但在其他方面结果好坏参半。
Ward是处理有噪数据最有效的方法。
虽然这些例子提供了一些关于算法的直觉,但这种直觉可能不适用于非常高维度的数据。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import time
import warnings
from itertools import cycle, islice
import matplotlib.pyplot as plt
import numpy as np
from sklearn import cluster, datasets
from sklearn.preprocessing import StandardScaler
生成数据集。我们选择足够大的大小来查看算法的可扩展性,但又不能太大,以免运行时间过长
n_samples = 1500
noisy_circles = datasets.make_circles(
n_samples=n_samples, factor=0.5, noise=0.05, random_state=170
)
noisy_moons = datasets.make_moons(n_samples=n_samples, noise=0.05, random_state=170)
blobs = datasets.make_blobs(n_samples=n_samples, random_state=170)
rng = np.random.RandomState(170)
no_structure = rng.rand(n_samples, 2), None
# Anisotropicly distributed data
X, y = datasets.make_blobs(n_samples=n_samples, random_state=170)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X, transformation)
aniso = (X_aniso, y)
# blobs with varied variances
varied = datasets.make_blobs(
n_samples=n_samples, cluster_std=[1.0, 2.5, 0.5], random_state=170
)
运行集群并绘制
# Set up cluster parameters
plt.figure(figsize=(9 * 1.3 + 2, 14.5))
plt.subplots_adjust(
left=0.02, right=0.98, bottom=0.001, top=0.96, wspace=0.05, hspace=0.01
)
plot_num = 1
default_base = {"n_neighbors": 10, "n_clusters": 3}
datasets = [
(noisy_circles, {"n_clusters": 2}),
(noisy_moons, {"n_clusters": 2}),
(varied, {"n_neighbors": 2}),
(aniso, {"n_neighbors": 2}),
(blobs, {}),
(no_structure, {}),
]
for i_dataset, (dataset, algo_params) in enumerate(datasets):
# update parameters with dataset-specific values
params = default_base.copy()
params.update(algo_params)
X, y = dataset
# normalize dataset for easier parameter selection
X = StandardScaler().fit_transform(X)
# ============
# Create cluster objects
# ============
ward = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="ward"
)
complete = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="complete"
)
average = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="average"
)
single = cluster.AgglomerativeClustering(
n_clusters=params["n_clusters"], linkage="single"
)
clustering_algorithms = (
("Single Linkage", single),
("Average Linkage", average),
("Complete Linkage", complete),
("Ward Linkage", ward),
)
for name, algorithm in clustering_algorithms:
t0 = time.time()
# catch warnings related to kneighbors_graph
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message="the number of connected components of the "
"connectivity matrix is [0-9]{1,2}"
" > 1. Completing it to avoid stopping the tree early.",
category=UserWarning,
)
algorithm.fit(X)
t1 = time.time()
if hasattr(algorithm, "labels_"):
y_pred = algorithm.labels_.astype(int)
else:
y_pred = algorithm.predict(X)
plt.subplot(len(datasets), len(clustering_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
colors = np.array(
list(
islice(
cycle(
[
"#377eb8",
"#ff7f00",
"#4daf4a",
"#f781bf",
"#a65628",
"#984ea3",
"#999999",
"#e41a1c",
"#dede00",
]
),
int(max(y_pred) + 1),
)
)
)
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.text(
0.99,
0.01,
("%.2fs" % (t1 - t0)).lstrip("0"),
transform=plt.gca().transAxes,
size=15,
horizontalalignment="right",
)
plot_num += 1
plt.show()
Total running time of the script: (0分1.273秒)
相关实例


Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _