备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
识别手写数字#
此示例展示了如何使用scikit-learn来识别手写数字(0-9)的图像。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
# Standard scientific Python imports
import matplotlib.pyplot as plt
# Import datasets, classifiers and performance metrics
from sklearn import datasets, metrics, svm
from sklearn.model_selection import train_test_split
数字数据集#
数字数据集由8 x 8像素的数字图像组成。的 images 数据集的属性存储每个图像的8 x 8灰度值数组。我们将使用这些阵列来可视化前4张图像。的 target 数据集的属性存储每个图像代表的数字,这包含在下面4个图的标题中。
注意:如果我们正在使用图像文件(例如,“png”文件),我们会使用加载它们 matplotlib.pyplot.imread .
digits = datasets.load_digits()
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title("Training: %i" % label)

分类#
为了对该数据应用分类器,我们需要拉平图像,将每个2-D灰度值阵列从形状转变 (8, 8) 成形 (64,) .随后,整个数据集就会成型 (n_samples, n_features) ,在哪里 n_samples 是图像的数量和 n_features 是每个图像中的像素总数。
然后,我们可以将数据拆分为训练和测试子集,并在训练样本上适应支持载体分类器。随后,可以使用匹配的分类器来预测测试子集中样本的数字值。
# flatten the images
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Create a classifier: a support vector classifier
clf = svm.SVC(gamma=0.001)
# Split data into 50% train and 50% test subsets
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False
)
# Learn the digits on the train subset
clf.fit(X_train, y_train)
# Predict the value of the digit on the test subset
predicted = clf.predict(X_test)
下面我们可视化前4个测试样本,并在标题中显示其预测数字值。
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, prediction in zip(axes, X_test, predicted):
ax.set_axis_off()
image = image.reshape(8, 8)
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title(f"Prediction: {prediction}")

classification_report 构建一个文本报告,显示主要的分类指标。
print(
f"Classification report for classifier {clf}:\n"
f"{metrics.classification_report(y_test, predicted)}\n"
)
Classification report for classifier SVC(gamma=0.001):
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
我们还可以绘制一个 confusion matrix 真实数字值和预测数字值的。
disp = metrics.ConfusionMatrixDisplay.from_predictions(y_test, predicted)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
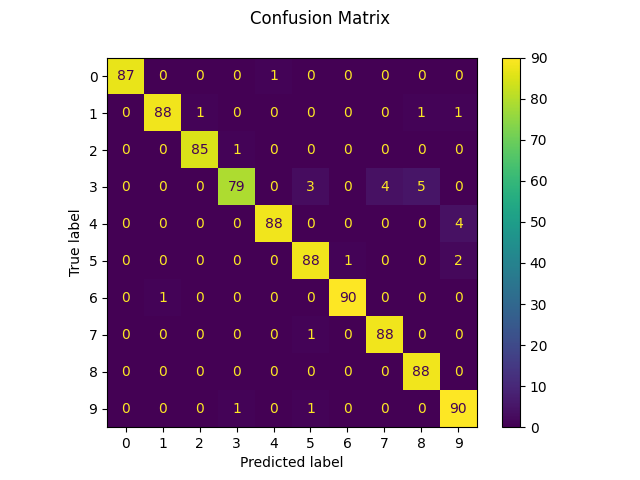
Confusion matrix:
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]
如果评估分类器的结果以形式存储 confusion matrix 而不是就 y_true 和 y_pred ,仍然可以建造一个 classification_report 具体如下:
# The ground truth and predicted lists
y_true = []
y_pred = []
cm = disp.confusion_matrix
# For each cell in the confusion matrix, add the corresponding ground truths
# and predictions to the lists
for gt in range(len(cm)):
for pred in range(len(cm)):
y_true += [gt] * cm[gt][pred]
y_pred += [pred] * cm[gt][pred]
print(
"Classification report rebuilt from confusion matrix:\n"
f"{metrics.classification_report(y_true, y_pred)}\n"
)
Classification report rebuilt from confusion matrix:
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
Total running time of the script: (0分0.292秒)
相关实例


Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _