备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
分位数回归#
这个例子说明了分位数回归如何预测非平凡条件分位数。
左图显示了误差分布为正态分布,但具有非常数方差的情况,即具有异方差性。
右图显示了非对称误差分布的示例,即帕累托分布。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集生成#
为了说明分位数回归的行为,我们将生成两个合成数据集。两个数据集的真正生成随机过程将由相同的预期值组成,与单个要素呈线性关系 x .
import numpy as np
rng = np.random.RandomState(42)
x = np.linspace(start=0, stop=10, num=100)
X = x[:, np.newaxis]
y_true_mean = 10 + 0.5 * x
我们将通过改变目标的分布来产生两个后续问题 y 同时保持相同的期望值:
在第一种情况下,添加异方差正态噪音;
在第二种情况下,添加了非对称帕累托噪音。
y_normal = y_true_mean + rng.normal(loc=0, scale=0.5 + 0.5 * x, size=x.shape[0])
a = 5
y_pareto = y_true_mean + 10 * (rng.pareto(a, size=x.shape[0]) - 1 / (a - 1))
让我们首先可视化数据集以及残余的分布 y - mean(y) .
import matplotlib.pyplot as plt
_, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 11), sharex="row", sharey="row")
axs[0, 0].plot(x, y_true_mean, label="True mean")
axs[0, 0].scatter(x, y_normal, color="black", alpha=0.5, label="Observations")
axs[1, 0].hist(y_true_mean - y_normal, edgecolor="black")
axs[0, 1].plot(x, y_true_mean, label="True mean")
axs[0, 1].scatter(x, y_pareto, color="black", alpha=0.5, label="Observations")
axs[1, 1].hist(y_true_mean - y_pareto, edgecolor="black")
axs[0, 0].set_title("Dataset with heteroscedastic Normal distributed targets")
axs[0, 1].set_title("Dataset with asymmetric Pareto distributed target")
axs[1, 0].set_title(
"Residuals distribution for heteroscedastic Normal distributed targets"
)
axs[1, 1].set_title("Residuals distribution for asymmetric Pareto distributed target")
axs[0, 0].legend()
axs[0, 1].legend()
axs[0, 0].set_ylabel("y")
axs[1, 0].set_ylabel("Counts")
axs[0, 1].set_xlabel("x")
axs[0, 0].set_xlabel("x")
axs[1, 0].set_xlabel("Residuals")
_ = axs[1, 1].set_xlabel("Residuals")
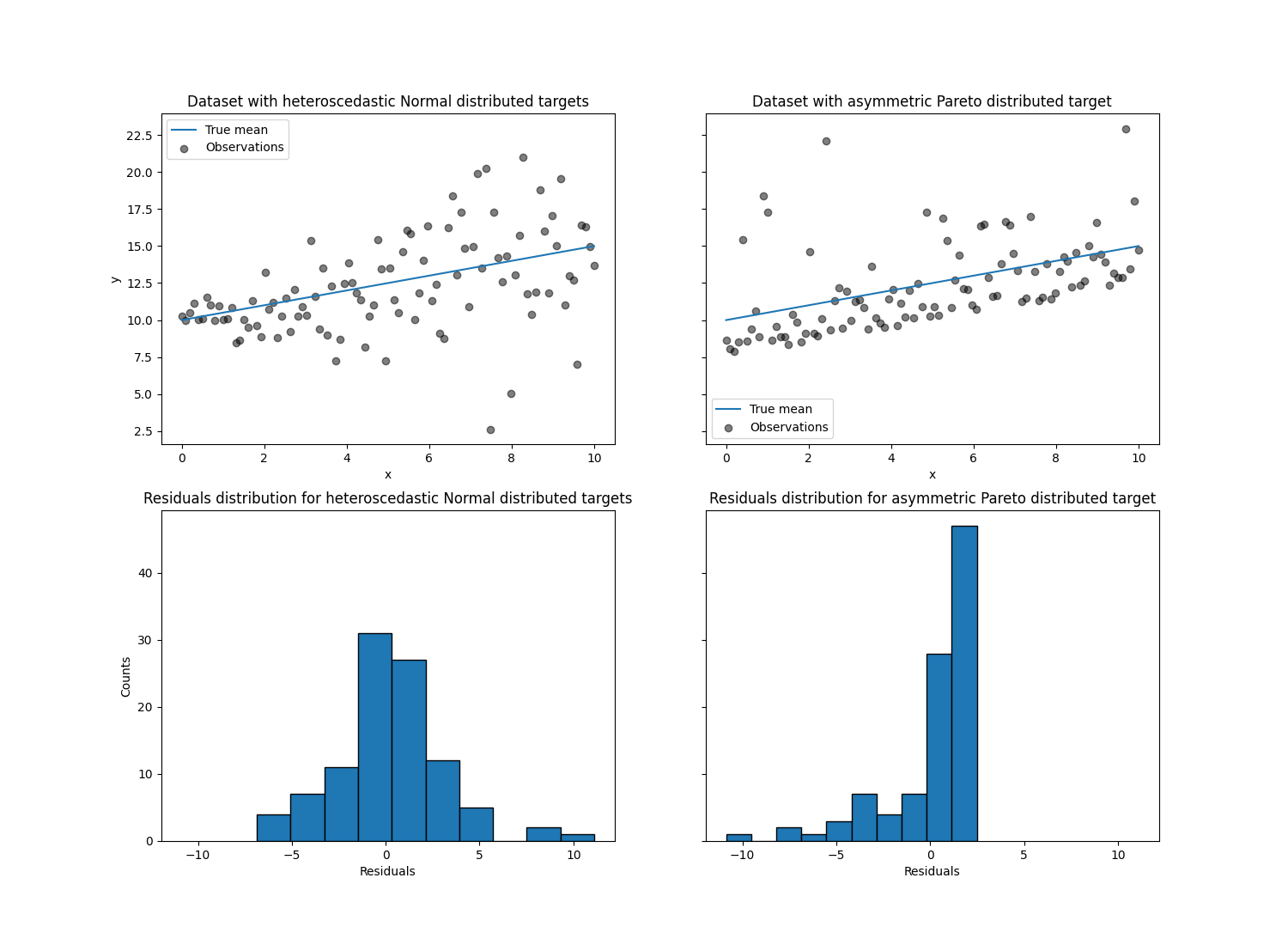
对于异方差正态分布目标,我们观察到当特征值时,噪音的方差正在增加 x 正在增加。
对于不对称帕累托分布目标,我们观察到正残数是有界的。
这些类型的有噪目标通过以下方式进行估计 LinearRegression 效率较低,即我们需要更多数据才能获得稳定的结果,此外,大的异常值可能会对匹配系数产生巨大影响。(换句话说:在方差不变的设置中,普通最小平方估计器收敛得快得多 true 随着样本量增加的系数。)
在这种不对称设置中,中位数或不同分位数提供了额外的见解。最重要的是,中位数估计对于异常值和重尾分布更稳健。但请注意,极端分位数是由很少的数据点估计的。95%分位数或多或少是由5%的最大值估计的,因此也有点敏感的异常值。
在本教程的其余部分中,我们将展示如何 QuantileRegressor 可以在实践中使用,并直观地了解所匹配模型的属性。最后,我们将比较两者 QuantileRegressor 和 LinearRegression .
拟合 QuantileRegressor#
在本节中,我们想要估计条件中位数以及分别固定为5%和95%的低分位数和高分位数。因此,我们将得到三个线性模型,每个分位数一个。
我们将使用5%和95%的分位数来查找训练样本中中心90%区间以外的异常值。
from sklearn.linear_model import QuantileRegressor
quantiles = [0.05, 0.5, 0.95]
predictions = {}
out_bounds_predictions = np.zeros_like(y_true_mean, dtype=np.bool_)
for quantile in quantiles:
qr = QuantileRegressor(quantile=quantile, alpha=0)
y_pred = qr.fit(X, y_normal).predict(X)
predictions[quantile] = y_pred
if quantile == min(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred >= y_normal
)
elif quantile == max(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred <= y_normal
)
现在,我们可以绘制三个线性模型以及中心90%区间内的样本与该区间外的样本的区分。
plt.plot(X, y_true_mean, color="black", linestyle="dashed", label="True mean")
for quantile, y_pred in predictions.items():
plt.plot(X, y_pred, label=f"Quantile: {quantile}")
plt.scatter(
x[out_bounds_predictions],
y_normal[out_bounds_predictions],
color="black",
marker="+",
alpha=0.5,
label="Outside interval",
)
plt.scatter(
x[~out_bounds_predictions],
y_normal[~out_bounds_predictions],
color="black",
alpha=0.5,
label="Inside interval",
)
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
_ = plt.title("Quantiles of heteroscedastic Normal distributed target")
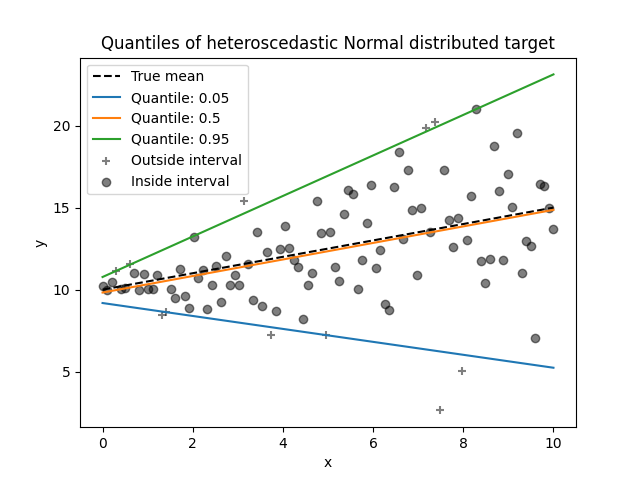
由于噪音仍然是正态分布的,特别是对称的,因此真实的条件均值和真实的条件中位数重合。事实上,我们看到估计的中位数几乎达到了真实平均值。我们观察到噪音方差增加对5%和95%分位数的影响:这些分位数的斜坡非常不同,并且它们之间的间隔随着增加而变得更宽 x .
为了获得有关5%和95%分位数估计数含义的额外直觉,考虑到我们总共有100个样本,可以计算高于和低于预测分位数(由上图上的十字表示)的样本数量。
我们可以使用不对称帕累托分布目标重复相同的实验。
quantiles = [0.05, 0.5, 0.95]
predictions = {}
out_bounds_predictions = np.zeros_like(y_true_mean, dtype=np.bool_)
for quantile in quantiles:
qr = QuantileRegressor(quantile=quantile, alpha=0)
y_pred = qr.fit(X, y_pareto).predict(X)
predictions[quantile] = y_pred
if quantile == min(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred >= y_pareto
)
elif quantile == max(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred <= y_pareto
)
plt.plot(X, y_true_mean, color="black", linestyle="dashed", label="True mean")
for quantile, y_pred in predictions.items():
plt.plot(X, y_pred, label=f"Quantile: {quantile}")
plt.scatter(
x[out_bounds_predictions],
y_pareto[out_bounds_predictions],
color="black",
marker="+",
alpha=0.5,
label="Outside interval",
)
plt.scatter(
x[~out_bounds_predictions],
y_pareto[~out_bounds_predictions],
color="black",
alpha=0.5,
label="Inside interval",
)
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
_ = plt.title("Quantiles of asymmetric Pareto distributed target")
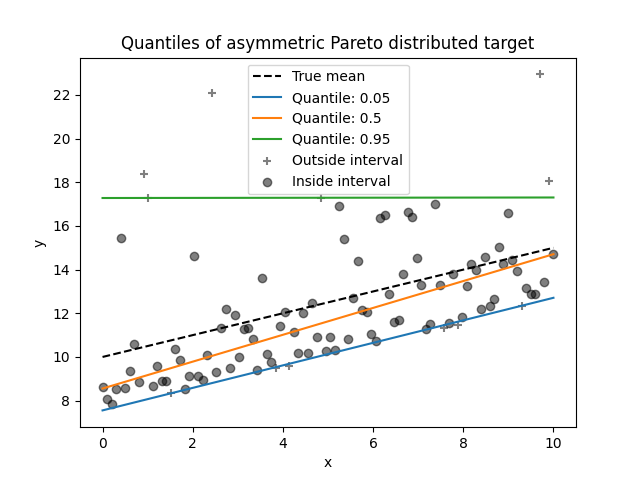
由于噪音分布的不对称性,我们观察到真实平均值和估计的条件中位数是不同的。我们还观察到每个分位数模型具有不同的参数,以更好地适应所需的分位数。请注意,理想情况下,在这种情况下,所有分位数都是平行的,随着数据点更多或极端分位数更少,这将变得更加明显,例如10%和90%。
比较 QuantileRegressor 和 LinearRegression#
在本节中,我们将详细讨论损失函数的差异, QuantileRegressor 和 LinearRegression 正在最小化。
事实上, LinearRegression 是一种最小化训练目标和预测目标之间的均方误差(SSE)的最小化方法。相反, QuantileRegressor 与 quantile=0.5 相反,最小化平均绝对误差(MAE)。
为什么这很重要?损失函数指定模型的确切目标是预测什么,请参阅 user guide on the choice of scoring function .简而言之,最小化SSE的模型预测平均值(期望),最小化MAE的模型预测中位数。
让我们根据均方误差和平均绝对误差来计算此类模型的训练误差。我们将使用非对称帕累托分布目标来使其更有趣,因为均值和中位数不相等。
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
linear_regression = LinearRegression()
quantile_regression = QuantileRegressor(quantile=0.5, alpha=0)
y_pred_lr = linear_regression.fit(X, y_pareto).predict(X)
y_pred_qr = quantile_regression.fit(X, y_pareto).predict(X)
print(
"Training error (in-sample performance)\n"
f"{'model':<20} MAE MSE\n"
f"{linear_regression.__class__.__name__:<20} "
f"{mean_absolute_error(y_pareto, y_pred_lr):5.3f} "
f"{mean_squared_error(y_pareto, y_pred_lr):5.3f}\n"
f"{quantile_regression.__class__.__name__:<20} "
f"{mean_absolute_error(y_pareto, y_pred_qr):5.3f} "
f"{mean_squared_error(y_pareto, y_pred_qr):5.3f}"
)
Training error (in-sample performance)
model MAE MSE
LinearRegression 1.805 6.486
QuantileRegressor 1.670 7.025
在训练集中,我们看到MAE较低 QuantileRegressor 比 LinearRegression .相比之下,SSE较低 LinearRegression 比 QuantileRegressor .这些结果证实MAE是通过以下方式最小化的损失 QuantileRegressor 而SSE则将损失最小化 LinearRegression .
我们可以通过查看交叉验证获得的测试误差来做出类似的评估。
from sklearn.model_selection import cross_validate
cv_results_lr = cross_validate(
linear_regression,
X,
y_pareto,
cv=3,
scoring=["neg_mean_absolute_error", "neg_mean_squared_error"],
)
cv_results_qr = cross_validate(
quantile_regression,
X,
y_pareto,
cv=3,
scoring=["neg_mean_absolute_error", "neg_mean_squared_error"],
)
print(
"Test error (cross-validated performance)\n"
f"{'model':<20} MAE MSE\n"
f"{linear_regression.__class__.__name__:<20} "
f"{-cv_results_lr['test_neg_mean_absolute_error'].mean():5.3f} "
f"{-cv_results_lr['test_neg_mean_squared_error'].mean():5.3f}\n"
f"{quantile_regression.__class__.__name__:<20} "
f"{-cv_results_qr['test_neg_mean_absolute_error'].mean():5.3f} "
f"{-cv_results_qr['test_neg_mean_squared_error'].mean():5.3f}"
)
Test error (cross-validated performance)
model MAE MSE
LinearRegression 1.732 6.690
QuantileRegressor 1.679 7.129
我们对样本外评估也得出了类似的结论。
Total running time of the script: (0分0.405秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _