备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
绘制交叉验证预测#
此示例说明如何使用 cross_val_predict 连同 PredictionErrorDisplay 以可视化预测错误。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
我们将加载糖尿病数据集并创建线性回归模型的实例。
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
X, y = load_diabetes(return_X_y=True)
lr = LinearRegression()
cross_val_predict 返回大小相同的数组 y 其中每个条目都是通过交叉验证获得的预测。
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(lr, X, y, cv=10)
以来 cv=10 这意味着我们训练了10个模型,每个模型用于预测10个折叠中的一个。我们现在可以使用 PredictionErrorDisplay 以可视化预测误差。
在左轴上,我们绘制了观察到的值 \(y\) 与预测值相比 \(\hat{y}\) 由模型给出。在右轴上,我们绘制了剩余值(即观察值和预测值之间的差)与预测值。
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="actual_vs_predicted",
subsample=100,
ax=axs[0],
random_state=0,
)
axs[0].set_title("Actual vs. Predicted values")
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="residual_vs_predicted",
subsample=100,
ax=axs[1],
random_state=0,
)
axs[1].set_title("Residuals vs. Predicted Values")
fig.suptitle("Plotting cross-validated predictions")
plt.tight_layout()
plt.show()
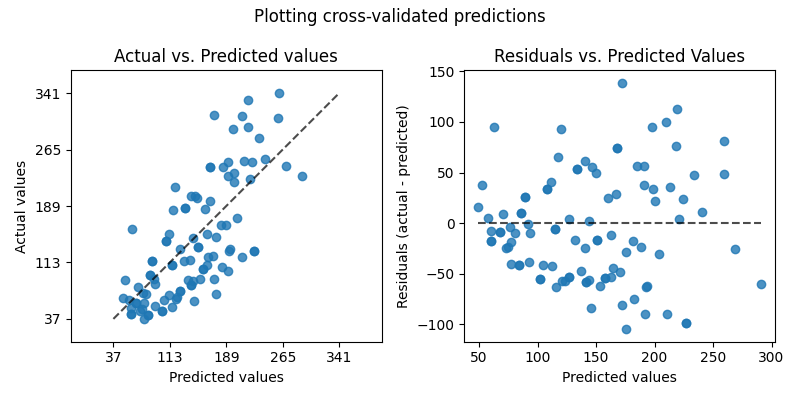
值得注意的是,我们使用了 cross_val_predict 在本示例中仅用于可视化目的。
通过根据返回的级联预测计算单个性能指标来量化评估模型性能是有问题的 cross_val_predict 当不同的CV褶皱因尺寸和分布而异时。
建议使用以下方法计算每层性能指标: cross_val_score 或 cross_validate 而不是.
Total running time of the script: (0分0.131秒)
相关实例
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _