备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
使用多项逻辑+ L1的MNIST分类#
在这里,我们对MNIST数字分类任务的子集进行了具有L1罚分的多项逻辑回归。我们为此使用SAGA算法:当样本数量明显大于特征数量时,这是一个快速求解器,并且能够精细优化非光滑目标函数,l1罚分就是这种情况。测试准确率达到> 0.8,而权重载体保持不变 sparse 因此更容易 interpretable .
请注意,该l1惩罚线性模型的准确性显着低于该数据集上的l2惩罚线性模型或非线性多层感知器模型所能达到的准确性。
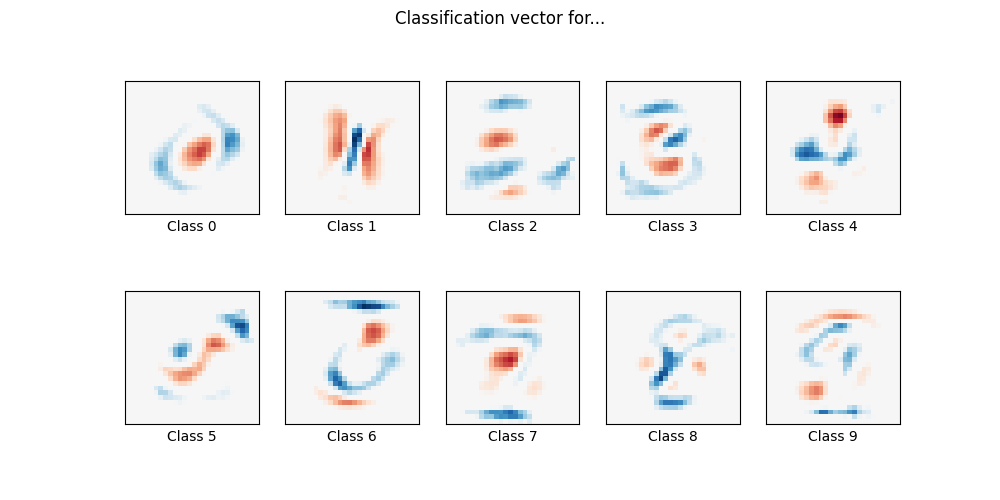
Sparsity with L1 penalty: 74.57%
Test score with L1 penalty: 0.8253
Example run in 5.386 s
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.utils import check_random_state
# Turn down for faster convergence
t0 = time.time()
train_samples = 5000
# Load data from https://www.openml.org/d/554
X, y = fetch_openml("mnist_784", version=1, return_X_y=True, as_frame=False)
random_state = check_random_state(0)
permutation = random_state.permutation(X.shape[0])
X = X[permutation]
y = y[permutation]
X = X.reshape((X.shape[0], -1))
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=train_samples, test_size=10000
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Turn up tolerance for faster convergence
clf = LogisticRegression(C=50.0 / train_samples, penalty="l1", solver="saga", tol=0.1)
clf.fit(X_train, y_train)
sparsity = np.mean(clf.coef_ == 0) * 100
score = clf.score(X_test, y_test)
# print('Best C % .4f' % clf.C_)
print("Sparsity with L1 penalty: %.2f%%" % sparsity)
print("Test score with L1 penalty: %.4f" % score)
coef = clf.coef_.copy()
plt.figure(figsize=(10, 5))
scale = np.abs(coef).max()
for i in range(10):
l1_plot = plt.subplot(2, 5, i + 1)
l1_plot.imshow(
coef[i].reshape(28, 28),
interpolation="nearest",
cmap=plt.cm.RdBu,
vmin=-scale,
vmax=scale,
)
l1_plot.set_xticks(())
l1_plot.set_yticks(())
l1_plot.set_xlabel(f"Class {i}")
plt.suptitle("Classification vector for...")
run_time = time.time() - t0
print("Example run in %.3f s" % run_time)
plt.show()
Total running time of the script: (0分5.436秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _