备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
单一估计量与装袋:偏差方差分解#
此示例说明并比较了单个估计器的预期均方误差与Bagging总体的偏差方差分解。
在回归中,估计器的预期均方误差可以按照偏差、方差和噪音来分解。平均而言,在回归问题的数据集上,偏差项测量估计器的预测与该问题的最佳可能估计器的预测相差的平均量(即,Bayes模型)。方差项衡量估计器在与同一问题的不同随机实例进行匹配时预测的变异性。下面将每个问题实例标记为“LS”,代表“Learning Sample”。最后,噪音测量了由于数据变异性而造成的误差中不可约的部分。
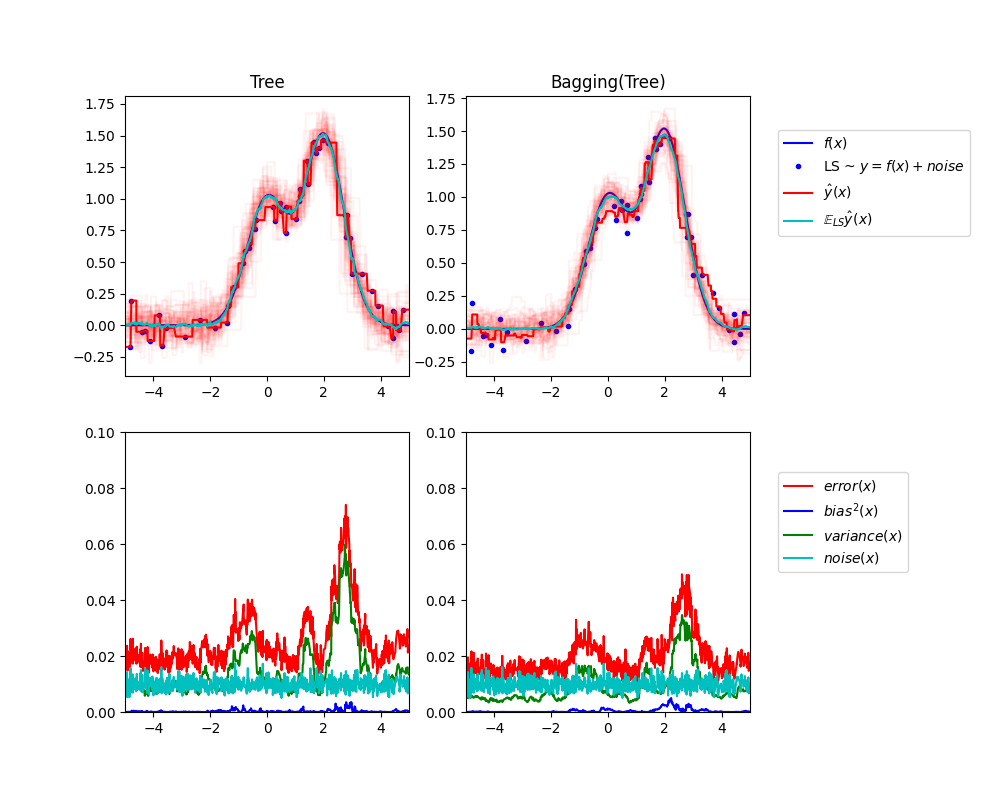
左上图说明了在玩具1d回归问题的随机数据集LS(蓝点)上训练的单个决策树的预测(深红色)。它还说明了在问题的其他(和不同)随机绘制的实例LS上训练的其他单个决策树的预测(以浅红色表示)。直观地说,这里的方差项对应于各个估计器的预测束(浅红色)的宽度。方差越大,预测越敏感 x 训练集的小变化。偏差项对应于估计器的平均预测(青色)和最佳可能模型(深蓝色)之间的差异。在这个问题上,我们可以观察到偏差相当低(青色和蓝色曲线都彼此接近),而方差很大(红色束相当宽)。
左下图绘制了单个决策树的预期均方误差的逐点分解。它证实了偏差项(蓝色)很低,而方差很大(绿色)。它还说明了误差的噪音部分,正如预期的那样,该部分似乎是恒定的并且在附近 0.01 .
正确的数字对应于相同的图,但使用了决策树的袋装集合。在这两个图中,我们可以观察到偏差项比之前的情况更大。在右上图中,平均预测(青色)和最佳可能模型之间的差异较大(例如,注意周围的偏差 x=2 ).在右下图中,偏差曲线也略高于左下图。然而,就方差而言,预测束更窄,这表明方差更低。事实上,正如右下图所证实的那样,方差项(绿色)低于单个决策树。总体而言,偏差方差分解因此不再相同。权衡对于Bagging来说更好:对数据集的引导副本上的几棵决策树进行平均会稍微增加偏差项,但允许更大程度地减少方差,从而导致较低的总体均方误差(比较较低数字中的红色曲线)。脚本输出也证实了这一直觉。Bagging集成的总误差低于单个决策树的总误差,这种差异确实主要源于方差的减少。
有关偏差方差分解的更多详细信息,请参阅的第7.3节 [1].
引用#
Tree: 0.0255 (error) = 0.0003 (bias^2) + 0.0152 (var) + 0.0098 (noise)
Bagging(Tree): 0.0196 (error) = 0.0004 (bias^2) + 0.0092 (var) + 0.0098 (noise)
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import BaggingRegressor
from sklearn.tree import DecisionTreeRegressor
# Settings
n_repeat = 50 # Number of iterations for computing expectations
n_train = 50 # Size of the training set
n_test = 1000 # Size of the test set
noise = 0.1 # Standard deviation of the noise
np.random.seed(0)
# Change this for exploring the bias-variance decomposition of other
# estimators. This should work well for estimators with high variance (e.g.,
# decision trees or KNN), but poorly for estimators with low variance (e.g.,
# linear models).
estimators = [
("Tree", DecisionTreeRegressor()),
("Bagging(Tree)", BaggingRegressor(DecisionTreeRegressor())),
]
n_estimators = len(estimators)
# Generate data
def f(x):
x = x.ravel()
return np.exp(-(x**2)) + 1.5 * np.exp(-((x - 2) ** 2))
def generate(n_samples, noise, n_repeat=1):
X = np.random.rand(n_samples) * 10 - 5
X = np.sort(X)
if n_repeat == 1:
y = f(X) + np.random.normal(0.0, noise, n_samples)
else:
y = np.zeros((n_samples, n_repeat))
for i in range(n_repeat):
y[:, i] = f(X) + np.random.normal(0.0, noise, n_samples)
X = X.reshape((n_samples, 1))
return X, y
X_train = []
y_train = []
for i in range(n_repeat):
X, y = generate(n_samples=n_train, noise=noise)
X_train.append(X)
y_train.append(y)
X_test, y_test = generate(n_samples=n_test, noise=noise, n_repeat=n_repeat)
plt.figure(figsize=(10, 8))
# Loop over estimators to compare
for n, (name, estimator) in enumerate(estimators):
# Compute predictions
y_predict = np.zeros((n_test, n_repeat))
for i in range(n_repeat):
estimator.fit(X_train[i], y_train[i])
y_predict[:, i] = estimator.predict(X_test)
# Bias^2 + Variance + Noise decomposition of the mean squared error
y_error = np.zeros(n_test)
for i in range(n_repeat):
for j in range(n_repeat):
y_error += (y_test[:, j] - y_predict[:, i]) ** 2
y_error /= n_repeat * n_repeat
y_noise = np.var(y_test, axis=1)
y_bias = (f(X_test) - np.mean(y_predict, axis=1)) ** 2
y_var = np.var(y_predict, axis=1)
print(
"{0}: {1:.4f} (error) = {2:.4f} (bias^2) "
" + {3:.4f} (var) + {4:.4f} (noise)".format(
name, np.mean(y_error), np.mean(y_bias), np.mean(y_var), np.mean(y_noise)
)
)
# Plot figures
plt.subplot(2, n_estimators, n + 1)
plt.plot(X_test, f(X_test), "b", label="$f(x)$")
plt.plot(X_train[0], y_train[0], ".b", label="LS ~ $y = f(x)+noise$")
for i in range(n_repeat):
if i == 0:
plt.plot(X_test, y_predict[:, i], "r", label=r"$\^y(x)$")
else:
plt.plot(X_test, y_predict[:, i], "r", alpha=0.05)
plt.plot(X_test, np.mean(y_predict, axis=1), "c", label=r"$\mathbb{E}_{LS} \^y(x)$")
plt.xlim([-5, 5])
plt.title(name)
if n == n_estimators - 1:
plt.legend(loc=(1.1, 0.5))
plt.subplot(2, n_estimators, n_estimators + n + 1)
plt.plot(X_test, y_error, "r", label="$error(x)$")
plt.plot(X_test, y_bias, "b", label="$bias^2(x)$")
plt.plot(X_test, y_var, "g", label="$variance(x)$")
plt.plot(X_test, y_noise, "c", label="$noise(x)$")
plt.xlim([-5, 5])
plt.ylim([0, 0.1])
if n == n_estimators - 1:
plt.legend(loc=(1.1, 0.5))
plt.subplots_adjust(right=0.75)
plt.show()
Total running time of the script: (0分0.892秒)
相关实例
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _