备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
基于k-means的文本聚类#
这是一个示例,展示了如何使用scikit-learn API按主题对文档进行聚集 Bag of Words approach .
演示了两种算法,即 KMeans 以及它更可扩展的变体, MiniBatchKMeans .此外,潜在语义分析用于降低维度并发现数据中的潜在模式。
此示例使用两个不同的文本载体:a TfidfVectorizer 和 HashingVectorizer .查看示例笔记本 收件箱Hasher和DictVectorizer比较 有关矢量化器的更多信息以及它们的处理时间比较。
有关通过监督学习方法进行的文档分析,请参见示例脚本 使用稀疏特征对文本文档进行分类 .
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
加载文本数据#
我们从 20个新闻组文本数据集 ,其中包含20个主题的约18,000条新闻组帖子。为了说明目的并降低计算成本,我们选择了4个主题的子集,仅占约3,400个文档。查看示例 使用稀疏特征对文本文档进行分类 以获得对此类主题重叠的直觉。
请注意,默认情况下,文本示例包含一些消息元数据,例如 "headers" , "footers" (签名)和 "quotes" 到其他职位。公司现采用国际 remove 参数从 fetch_20newsgroups 以去除这些特征并产生更合理的集群问题。
import numpy as np
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
"sci.space",
]
dataset = fetch_20newsgroups(
remove=("headers", "footers", "quotes"),
subset="all",
categories=categories,
shuffle=True,
random_state=42,
)
labels = dataset.target
unique_labels, category_sizes = np.unique(labels, return_counts=True)
true_k = unique_labels.shape[0]
print(f"{len(dataset.data)} documents - {true_k} categories")
3387 documents - 4 categories
量化集群结果的质量#
在本节中,我们定义了一个使用多种指标对不同的集群管道进行评分的函数。
聚类算法基本上是无监督的学习方法。然而,由于我们碰巧有这个特定数据集的类标签,因此可以使用利用这种“监督”地面真相信息的评估指标来量化结果集群的质量。这些指标的例子如下:
同质性,量化了有多少集群仅包含单个类别的成员;
完整性,量化给定类中有多少成员被分配到相同集群;
V-度量,完整性和齐性的调和平均值;
Rand-Index,用于测量根据聚类算法的结果和地面真值类分配对数据点进行一致分组的频率;
调整的随机指数,一个机会调整的随机指数,使得随机聚类分配的期望ARI为0.0。
如果基础事实标签未知,则只能使用模型结果本身执行评估。在这种情况下,剪影系数就派上了用场。看到 在KMeans聚类中使用轮廓分析选择聚类数 以获取如何做到这一点的示例。
有关更多参考,请参阅 集群绩效评估 .
from collections import defaultdict
from time import time
from sklearn import metrics
evaluations = []
evaluations_std = []
def fit_and_evaluate(km, X, name=None, n_runs=5):
name = km.__class__.__name__ if name is None else name
train_times = []
scores = defaultdict(list)
for seed in range(n_runs):
km.set_params(random_state=seed)
t0 = time()
km.fit(X)
train_times.append(time() - t0)
scores["Homogeneity"].append(metrics.homogeneity_score(labels, km.labels_))
scores["Completeness"].append(metrics.completeness_score(labels, km.labels_))
scores["V-measure"].append(metrics.v_measure_score(labels, km.labels_))
scores["Adjusted Rand-Index"].append(
metrics.adjusted_rand_score(labels, km.labels_)
)
scores["Silhouette Coefficient"].append(
metrics.silhouette_score(X, km.labels_, sample_size=2000)
)
train_times = np.asarray(train_times)
print(f"clustering done in {train_times.mean():.2f} ± {train_times.std():.2f} s ")
evaluation = {
"estimator": name,
"train_time": train_times.mean(),
}
evaluation_std = {
"estimator": name,
"train_time": train_times.std(),
}
for score_name, score_values in scores.items():
mean_score, std_score = np.mean(score_values), np.std(score_values)
print(f"{score_name}: {mean_score:.3f} ± {std_score:.3f}")
evaluation[score_name] = mean_score
evaluation_std[score_name] = std_score
evaluations.append(evaluation)
evaluations_std.append(evaluation_std)
文本特征上的K均值聚集#
在该示例中使用两种特征提取方法:
TfidfVectorizer使用内存词汇表(Python dict)将最频繁的单词映射到特征索引,从而计算单词出现频率(稀疏)矩阵。然后使用在整个数据库中按特征收集的逆文档频率(IDF)载体对词频进行重新加权。HashingVectorizer将单词出现的哈希到固定维度空间,可能存在冲突。然后,将字数计数载体规格化,使其l2-模等于1(投影到欧几里得单位球体),这对于k-均值在多维空间中工作似乎很重要。
此外,还可以使用降维对这些提取的特征进行后处理。我们将在下文中探讨这些选择对集群质量的影响。
使用TfidfVectorizer的特征提取#
我们首先使用字典向量器和IDF正规化来对估计器进行基准测试,如由 TfidfVectorizer .
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
max_df=0.5,
min_df=5,
stop_words="english",
)
t0 = time()
X_tfidf = vectorizer.fit_transform(dataset.data)
print(f"vectorization done in {time() - t0:.3f} s")
print(f"n_samples: {X_tfidf.shape[0]}, n_features: {X_tfidf.shape[1]}")
vectorization done in 0.253 s
n_samples: 3387, n_features: 7929
在忽略出现在超过50%的文档中的术语(由 max_df=0.5 )以及至少5个文档中不存在的术语(由 min_df=5 ),由此产生的唯一术语的数量 n_features 大约8,000人。我们还可以量化的稀疏性 X_tfidf 矩阵为非零项的分数除以元素总数。
print(f"{X_tfidf.nnz / np.prod(X_tfidf.shape):.3f}")
0.007
我们发现大约0.7%的条目 X_tfidf 矩阵不为零。
使用k均值对稀疏数据进行聚集#
既是 KMeans 和 MiniBatchKMeans 优化非凸目标函数时,它们的集群并不能保证对于给定的随机初始化是最优的。更进一步地,在稀疏的多维数据(例如使用Bag of Words方法进行了载体化的文本)上,k-means可以在极其孤立的数据点上初始化重心。这些数据点可以始终保持自己的重心。
下面的代码说明了前面的现象有时如何导致高度不平衡的集群,具体取决于随机初始化:
from sklearn.cluster import KMeans
for seed in range(5):
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=1,
random_state=seed,
).fit(X_tfidf)
cluster_ids, cluster_sizes = np.unique(kmeans.labels_, return_counts=True)
print(f"Number of elements assigned to each cluster: {cluster_sizes}")
print()
print(
"True number of documents in each category according to the class labels: "
f"{category_sizes}"
)
Number of elements assigned to each cluster: [ 481 675 1785 446]
Number of elements assigned to each cluster: [1689 638 480 580]
Number of elements assigned to each cluster: [ 1 1 1 3384]
Number of elements assigned to each cluster: [1887 311 332 857]
Number of elements assigned to each cluster: [ 291 673 1771 652]
True number of documents in each category according to the class labels: [799 973 987 628]
为了避免这个问题,一种可能性是增加具有独立随机初始化的运行数量 n_init .在这种情况下,选择具有最佳惯性(k均值目标函数)的集群。
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=5,
)
fit_and_evaluate(kmeans, X_tfidf, name="KMeans\non tf-idf vectors")
clustering done in 0.16 ± 0.04 s
Homogeneity: 0.349 ± 0.010
Completeness: 0.398 ± 0.009
V-measure: 0.372 ± 0.009
Adjusted Rand-Index: 0.203 ± 0.017
Silhouette Coefficient: 0.007 ± 0.000
所有这些集群评估指标的最大值都是1.0(对于完美的集群结果)。价值观越高越好。接近0.0的调整后Rand-Index值对应于随机标记。从上面的分数注意,集群分配确实远高于机会水平,但整体质量肯定可以提高。
请记住,类标签可能无法准确反映文档主题,因此使用标签的指标不一定是评估集群管道质量的最佳指标。
使用LSA执行降维#
A n_init=1 can still be used as long as the dimension of the vectorized space is reduced first to make k-means more stable. For such purpose we use TruncatedSVD, which works on term count/tf-idf matrices. Since SVD results are not normalized, we redo the normalization to improve the KMeans result. Using SVD to reduce the dimensionality of TF-IDF document vectors is often known as latent semantic analysis (LSA)在信息检索和文本挖掘文献中。
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
lsa = make_pipeline(TruncatedSVD(n_components=100), Normalizer(copy=False))
t0 = time()
X_lsa = lsa.fit_transform(X_tfidf)
explained_variance = lsa[0].explained_variance_ratio_.sum()
print(f"LSA done in {time() - t0:.3f} s")
print(f"Explained variance of the SVD step: {explained_variance * 100:.1f}%")
LSA done in 0.388 s
Explained variance of the SVD step: 18.4%
使用单个初始化意味着将减少两个处理时间 KMeans 和 MiniBatchKMeans .
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=1,
)
fit_and_evaluate(kmeans, X_lsa, name="KMeans\nwith LSA on tf-idf vectors")
clustering done in 0.03 ± 0.01 s
Homogeneity: 0.404 ± 0.008
Completeness: 0.437 ± 0.008
V-measure: 0.419 ± 0.002
Adjusted Rand-Index: 0.325 ± 0.021
Silhouette Coefficient: 0.030 ± 0.001
我们可以观察到,在文档的LSA表示上的聚类明显更快(这两个原因都是因为 n_init=1 并且因为LSA特征空间的维数小得多)。此外,所有的聚类评价指标都得到了改进。我们重复这个实验, MiniBatchKMeans .
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(
n_clusters=true_k,
n_init=1,
init_size=1000,
batch_size=1000,
)
fit_and_evaluate(
minibatch_kmeans,
X_lsa,
name="MiniBatchKMeans\nwith LSA on tf-idf vectors",
)
clustering done in 0.02 ± 0.00 s
Homogeneity: 0.324 ± 0.090
Completeness: 0.343 ± 0.074
V-measure: 0.332 ± 0.083
Adjusted Rand-Index: 0.275 ± 0.077
Silhouette Coefficient: 0.026 ± 0.004
每个集群的顶级术语#
以来 TfidfVectorizer 可以倒置,我们可以识别集群中心,这提供了对最有影响力的单词的直觉 for each cluster .查看示例脚本 使用稀疏特征对文本文档进行分类 与最具预测性的词进行比较 for each target class .
original_space_centroids = lsa[0].inverse_transform(kmeans.cluster_centers_)
order_centroids = original_space_centroids.argsort()[:, ::-1]
terms = vectorizer.get_feature_names_out()
for i in range(true_k):
print(f"Cluster {i}: ", end="")
for ind in order_centroids[i, :10]:
print(f"{terms[ind]} ", end="")
print()
Cluster 0: graphics thanks image files file program know looking help format
Cluster 1: space launch orbit nasa shuttle earth moon like mission just
Cluster 2: just think don know like ve time say said did
Cluster 3: god people jesus bible believe don religion say think christian
HashingVectorizer#
另一种载体化可以使用 HashingVectorizer 实例,它不提供IDF加权,因为这是一个无状态模型(fit方法不起任何作用)。当需要IDF加权时,可以通过流水线进行添加 HashingVectorizer 输出到 TfidfTransformer instance.在这种情况下,我们还将LSA添加到管道中,以减少哈希化的载体空间的维度和稀疏度。
from sklearn.feature_extraction.text import HashingVectorizer, TfidfTransformer
lsa_vectorizer = make_pipeline(
HashingVectorizer(stop_words="english", n_features=50_000),
TfidfTransformer(),
TruncatedSVD(n_components=100, random_state=0),
Normalizer(copy=False),
)
t0 = time()
X_hashed_lsa = lsa_vectorizer.fit_transform(dataset.data)
print(f"vectorization done in {time() - t0:.3f} s")
vectorization done in 1.729 s
可以观察到,LSA步骤需要相对较长的时间来适应,尤其是对于哈希化的载体。原因是哈希空间通常很大(设置为 n_features=50_000 在这个例子中)。可以尝试减少功能的数量,但代价是更大比例的功能具有哈希冲突,如示例笔记本中所示 收件箱Hasher和DictVectorizer比较 .
我们现在拟合并评估 kmeans 和 minibatch_kmeans 此哈希lsa简化数据上的实例:
fit_and_evaluate(kmeans, X_hashed_lsa, name="KMeans\nwith LSA on hashed vectors")
clustering done in 0.02 ± 0.01 s
Homogeneity: 0.387 ± 0.011
Completeness: 0.429 ± 0.017
V-measure: 0.407 ± 0.013
Adjusted Rand-Index: 0.328 ± 0.023
Silhouette Coefficient: 0.029 ± 0.001
fit_and_evaluate(
minibatch_kmeans,
X_hashed_lsa,
name="MiniBatchKMeans\nwith LSA on hashed vectors",
)
clustering done in 0.02 ± 0.00 s
Homogeneity: 0.357 ± 0.043
Completeness: 0.378 ± 0.046
V-measure: 0.367 ± 0.043
Adjusted Rand-Index: 0.322 ± 0.030
Silhouette Coefficient: 0.028 ± 0.004
这两种方法都会产生良好的结果,类似于在传统的LSA载体上运行相同的模型(没有哈希)。
聚类评价总结#
import matplotlib.pyplot as plt
import pandas as pd
fig, (ax0, ax1) = plt.subplots(ncols=2, figsize=(16, 6), sharey=True)
df = pd.DataFrame(evaluations[::-1]).set_index("estimator")
df_std = pd.DataFrame(evaluations_std[::-1]).set_index("estimator")
df.drop(
["train_time"],
axis="columns",
).plot.barh(ax=ax0, xerr=df_std)
ax0.set_xlabel("Clustering scores")
ax0.set_ylabel("")
df["train_time"].plot.barh(ax=ax1, xerr=df_std["train_time"])
ax1.set_xlabel("Clustering time (s)")
plt.tight_layout()
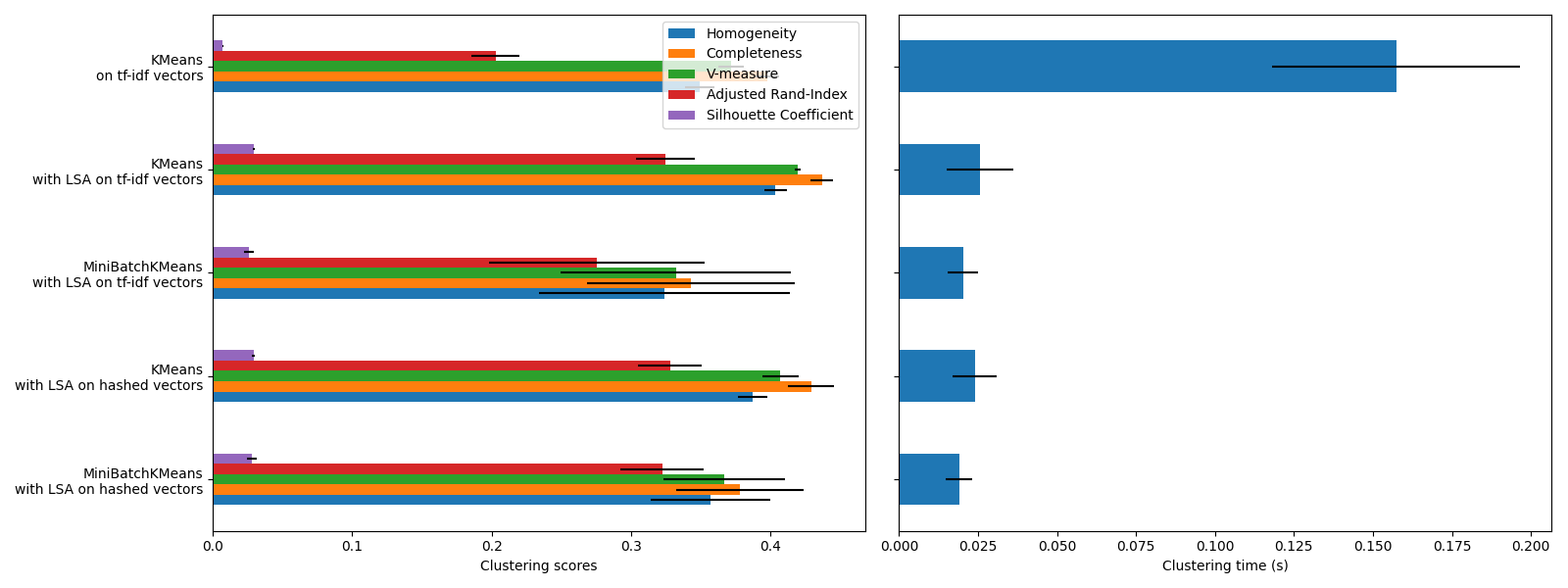
KMeans 和 MiniBatchKMeans 患有一种称为“ Curse of Dimensionality 对于文本数据等多维数据集。这就是使用LSA时总分提高的原因。使用LSA简化数据还可以提高稳定性,并且需要更短的集群时间,但请记住,LSA步骤本身需要很长时间,尤其是对于哈希载体。
剪影系数定义在0和1之间。在所有情况下,我们都会获得接近0的值(即使使用LSA后它们有所改善),因为它的定义需要测量距离,而与V测量和调整后的兰德指数等其他评估指标形成鲜明对比,后者仅基于集群分配而不是距离。请注意,严格来说,不应该比较不同维度的空间之间的剪影系数,因为它们所隐含的距离概念不同。
均匀性、完整性以及v测量指标不会产生随机标记的基线:这意味着根据样本、集群和地面真值类别的数量,完全随机标记并不总是产生相同的值。特别是,随机标记不会产生零分,尤其是当集群数量很大时。当样本数量超过一千并且集群数量小于10时(本示例的情况),可以安全地忽略这个问题。对于较小的样本量或较多的集群,使用调整后的指数(例如调整后的兰德指数(ARI))会更安全。查看示例 集群绩效评估中的机会调整 演示随机标签的效果。
误差线的大小表明, MiniBatchKMeans 的稳定性低于 KMeans 对于这个相对较小的数据集。当样本数量大得多时,使用它会更有趣,但与传统的k均值算法相比,它可能会以集群质量的小幅下降为代价。
Total running time of the script: (0分6.539秒)
相关实例


Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _