备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
绘制学习曲线并检查模型的可扩展性#
在这个示例中,我们展示了如何使用此类 LearningCurveDisplay 轻松绘制学习曲线。此外,我们给出了一个解释的学习曲线获得的朴素贝叶斯和SVM分类器。
然后,我们通过研究这些预测模型的计算成本而不仅仅是统计准确性来探索这些预测模型的可扩展性并得出一些结论。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
学习曲线#
学习曲线显示了在训练过程中添加更多样本的影响。通过检查模型的训练分数和测试分数的统计性能来描述效果。
在这里,我们使用数字数据集计算朴素Bayes分类器和具有RBS核的支持者分类器的学习曲线。
from sklearn.datasets import load_digits
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
X, y = load_digits(return_X_y=True)
naive_bayes = GaussianNB()
svc = SVC(kernel="rbf", gamma=0.001)
的 from_estimator 在给定要分析的数据集和预测模型的情况下显示学习曲线。为了估计分数不确定性,该方法使用交叉验证程序。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import LearningCurveDisplay, ShuffleSplit
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 6), sharey=True)
common_params = {
"X": X,
"y": y,
"train_sizes": np.linspace(0.1, 1.0, 5),
"cv": ShuffleSplit(n_splits=50, test_size=0.2, random_state=0),
"score_type": "both",
"n_jobs": 4,
"line_kw": {"marker": "o"},
"std_display_style": "fill_between",
"score_name": "Accuracy",
}
for ax_idx, estimator in enumerate([naive_bayes, svc]):
LearningCurveDisplay.from_estimator(estimator, **common_params, ax=ax[ax_idx])
handles, label = ax[ax_idx].get_legend_handles_labels()
ax[ax_idx].legend(handles[:2], ["Training Score", "Test Score"])
ax[ax_idx].set_title(f"Learning Curve for {estimator.__class__.__name__}")
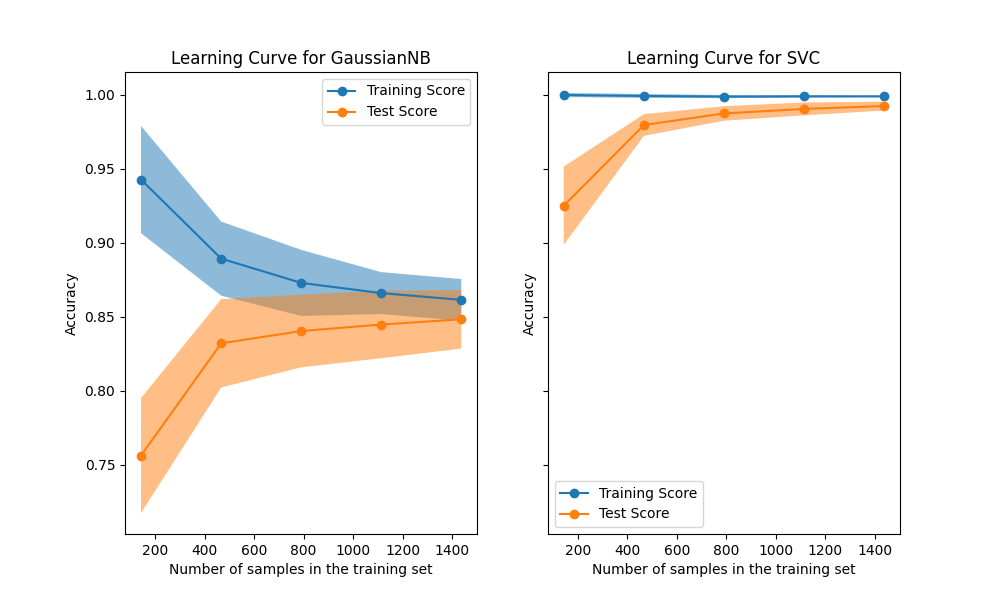
我们首先分析朴素贝叶斯分类器的学习曲线。它的形状经常出现在更复杂的数据集中:当使用很少的样本进行训练时,训练分数非常高,当增加样本数量时,训练分数会降低,而测试分数在开始时非常低,然后在添加样本时增加。当所有样本都用于训练时,训练和测试分数变得更加真实。
我们看到了具有RBS核的支持者分类器的另一个典型学习曲线。无论训练集的大小,训练分数都保持很高。另一方面,测试分数随着训练数据集的大小而增加。事实上,它会增加到达到平台的程度。观察到这样的平台表明获取新数据来训练模型可能没有用,因为模型的概括性能将不再增加。
复杂性分析#
除了这些学习曲线之外,还可以在训练和评分时间方面查看预测模型的可扩展性。
的 LearningCurveDisplay 类不提供此类信息。我们需要诉诸 learning_curve 功能并手动制作情节。
from sklearn.model_selection import learning_curve
common_params = {
"X": X,
"y": y,
"train_sizes": np.linspace(0.1, 1.0, 5),
"cv": ShuffleSplit(n_splits=50, test_size=0.2, random_state=0),
"n_jobs": 4,
"return_times": True,
}
train_sizes, _, test_scores_nb, fit_times_nb, score_times_nb = learning_curve(
naive_bayes, **common_params
)
train_sizes, _, test_scores_svm, fit_times_svm, score_times_svm = learning_curve(
svc, **common_params
)
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(16, 12), sharex=True)
for ax_idx, (fit_times, score_times, estimator) in enumerate(
zip(
[fit_times_nb, fit_times_svm],
[score_times_nb, score_times_svm],
[naive_bayes, svc],
)
):
# scalability regarding the fit time
ax[0, ax_idx].plot(train_sizes, fit_times.mean(axis=1), "o-")
ax[0, ax_idx].fill_between(
train_sizes,
fit_times.mean(axis=1) - fit_times.std(axis=1),
fit_times.mean(axis=1) + fit_times.std(axis=1),
alpha=0.3,
)
ax[0, ax_idx].set_ylabel("Fit time (s)")
ax[0, ax_idx].set_title(
f"Scalability of the {estimator.__class__.__name__} classifier"
)
# scalability regarding the score time
ax[1, ax_idx].plot(train_sizes, score_times.mean(axis=1), "o-")
ax[1, ax_idx].fill_between(
train_sizes,
score_times.mean(axis=1) - score_times.std(axis=1),
score_times.mean(axis=1) + score_times.std(axis=1),
alpha=0.3,
)
ax[1, ax_idx].set_ylabel("Score time (s)")
ax[1, ax_idx].set_xlabel("Number of training samples")
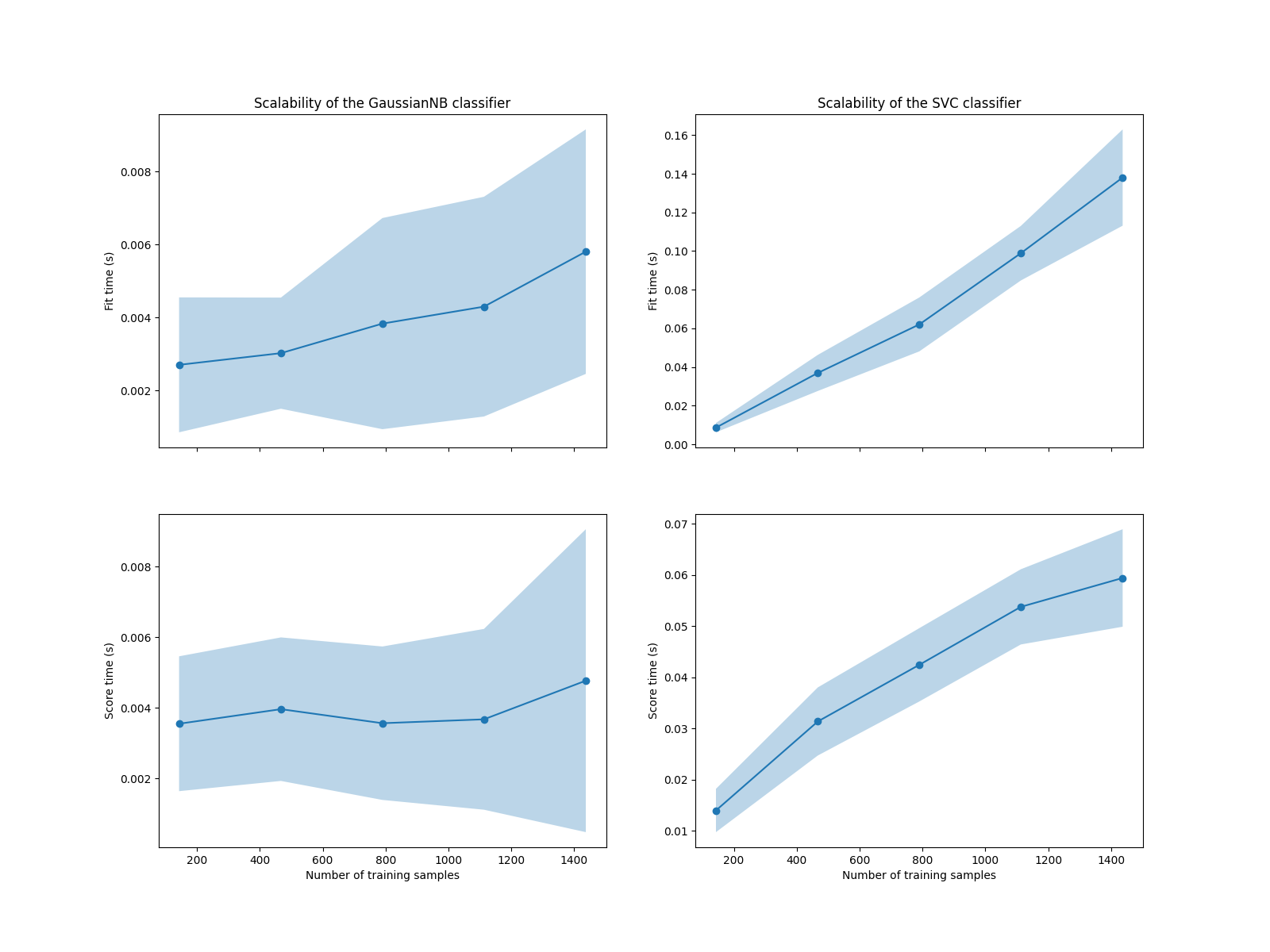
我们看到SVM和朴素贝叶斯分类器的可扩展性是非常不同的。SVM分类器在拟合和评分时的复杂度随着样本数量的增加而迅速增加。事实上,已知该分类器的拟合时间复杂度超过样本数量的二次方,这使得难以扩展到具有超过10,000个样本的数据集。相比之下,朴素贝叶斯分类器在拟合和评分时具有更低的复杂性。
随后,我们可以检查增加的训练时间和交叉验证分数之间的权衡。
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))
for ax_idx, (fit_times, test_scores, estimator) in enumerate(
zip(
[fit_times_nb, fit_times_svm],
[test_scores_nb, test_scores_svm],
[naive_bayes, svc],
)
):
ax[ax_idx].plot(fit_times.mean(axis=1), test_scores.mean(axis=1), "o-")
ax[ax_idx].fill_between(
fit_times.mean(axis=1),
test_scores.mean(axis=1) - test_scores.std(axis=1),
test_scores.mean(axis=1) + test_scores.std(axis=1),
alpha=0.3,
)
ax[ax_idx].set_ylabel("Accuracy")
ax[ax_idx].set_xlabel("Fit time (s)")
ax[ax_idx].set_title(
f"Performance of the {estimator.__class__.__name__} classifier"
)
plt.show()
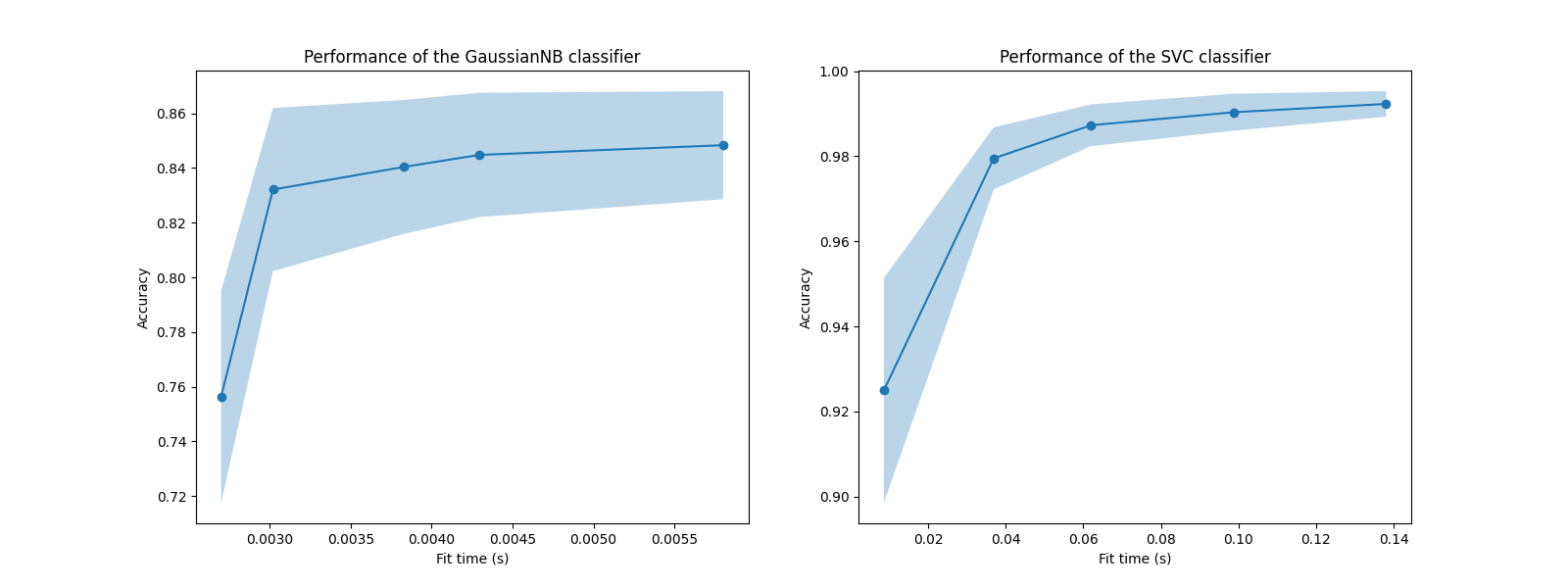
在这些图中,我们可以寻找交叉验证分数不再增加的拐点,只有训练时间增加。
Total running time of the script: (0分32.713秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _