备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
基于RBS核的显式特征图逼近#
示例说明了RBS核特征图的逼近。
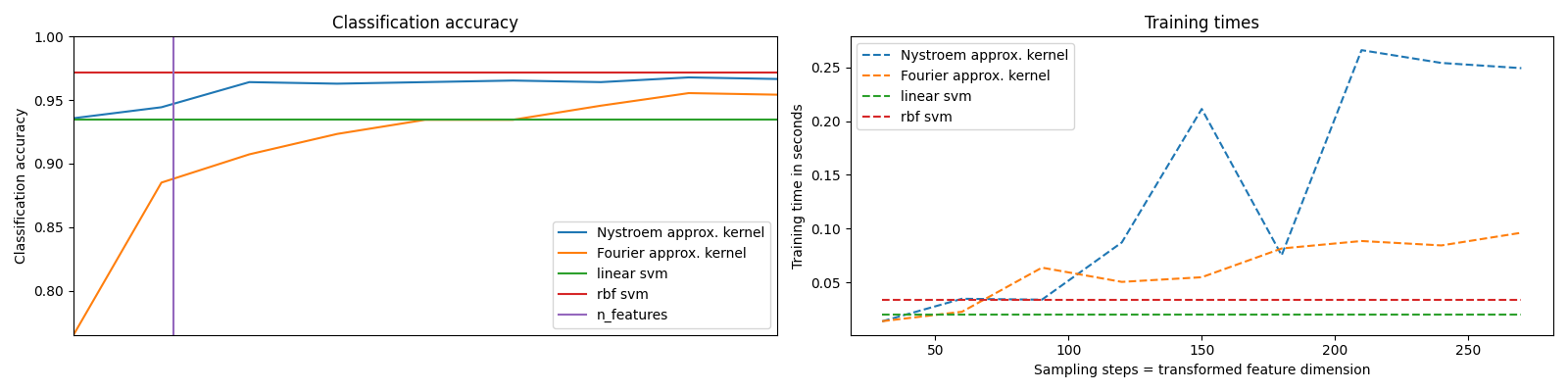
它展示了如何使用 RBFSampler 和 Nystroem 在数字数据集上使用支持支持机逼近用于分类的RBS核的特征图。比较了在原始空间中使用线性支持者、使用近似映射的线性支持者和使用核化支持者的结果。不同蒙特卡洛采样量的计时和准确性(在 RBFSampler ,使用随机傅里叶特征)和训练集的不同大小子集(用于 Nystroem )的大致映射已显示。
请注意,这里的数据集不够大,无法显示核逼近的好处,因为精确的支持者仍然相当快。
对更多维度进行抽样显然会带来更好的分类结果,但成本更高。这意味着运行时间和准确性之间存在权衡,由参数n_components给出。请注意,通过使用随机梯度下降可以大大加速线性支持机和逼近核支持机的求解 SGDClassifier .对于核化的支持者来说,这是不容易实现的。
Python包和数据集导入、加载数据集#
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
# Standard scientific Python imports
from time import time
import matplotlib.pyplot as plt
import numpy as np
# Import datasets, classifiers and performance metrics
from sklearn import datasets, pipeline, svm
from sklearn.decomposition import PCA
from sklearn.kernel_approximation import Nystroem, RBFSampler
# The digits dataset
digits = datasets.load_digits(n_class=9)
时间和准确性图#
要对该数据应用分类器,我们需要拉平图像,将数据转换为(样本、特征)矩阵:
n_samples = len(digits.data)
data = digits.data / 16.0
data -= data.mean(axis=0)
# We learn the digits on the first half of the digits
data_train, targets_train = (data[: n_samples // 2], digits.target[: n_samples // 2])
# Now predict the value of the digit on the second half:
data_test, targets_test = (data[n_samples // 2 :], digits.target[n_samples // 2 :])
# data_test = scaler.transform(data_test)
# Create a classifier: a support vector classifier
kernel_svm = svm.SVC(gamma=0.2)
linear_svm = svm.LinearSVC(random_state=42)
# create pipeline from kernel approximation
# and linear svm
feature_map_fourier = RBFSampler(gamma=0.2, random_state=1)
feature_map_nystroem = Nystroem(gamma=0.2, random_state=1)
fourier_approx_svm = pipeline.Pipeline(
[
("feature_map", feature_map_fourier),
("svm", svm.LinearSVC(random_state=42)),
]
)
nystroem_approx_svm = pipeline.Pipeline(
[
("feature_map", feature_map_nystroem),
("svm", svm.LinearSVC(random_state=42)),
]
)
# fit and predict using linear and kernel svm:
kernel_svm_time = time()
kernel_svm.fit(data_train, targets_train)
kernel_svm_score = kernel_svm.score(data_test, targets_test)
kernel_svm_time = time() - kernel_svm_time
linear_svm_time = time()
linear_svm.fit(data_train, targets_train)
linear_svm_score = linear_svm.score(data_test, targets_test)
linear_svm_time = time() - linear_svm_time
sample_sizes = 30 * np.arange(1, 10)
fourier_scores = []
nystroem_scores = []
fourier_times = []
nystroem_times = []
for D in sample_sizes:
fourier_approx_svm.set_params(feature_map__n_components=D)
nystroem_approx_svm.set_params(feature_map__n_components=D)
start = time()
nystroem_approx_svm.fit(data_train, targets_train)
nystroem_times.append(time() - start)
start = time()
fourier_approx_svm.fit(data_train, targets_train)
fourier_times.append(time() - start)
fourier_score = fourier_approx_svm.score(data_test, targets_test)
nystroem_score = nystroem_approx_svm.score(data_test, targets_test)
nystroem_scores.append(nystroem_score)
fourier_scores.append(fourier_score)
# plot the results:
plt.figure(figsize=(16, 4))
accuracy = plt.subplot(121)
# second y axis for timings
timescale = plt.subplot(122)
accuracy.plot(sample_sizes, nystroem_scores, label="Nystroem approx. kernel")
timescale.plot(sample_sizes, nystroem_times, "--", label="Nystroem approx. kernel")
accuracy.plot(sample_sizes, fourier_scores, label="Fourier approx. kernel")
timescale.plot(sample_sizes, fourier_times, "--", label="Fourier approx. kernel")
# horizontal lines for exact rbf and linear kernels:
accuracy.plot(
[sample_sizes[0], sample_sizes[-1]],
[linear_svm_score, linear_svm_score],
label="linear svm",
)
timescale.plot(
[sample_sizes[0], sample_sizes[-1]],
[linear_svm_time, linear_svm_time],
"--",
label="linear svm",
)
accuracy.plot(
[sample_sizes[0], sample_sizes[-1]],
[kernel_svm_score, kernel_svm_score],
label="rbf svm",
)
timescale.plot(
[sample_sizes[0], sample_sizes[-1]],
[kernel_svm_time, kernel_svm_time],
"--",
label="rbf svm",
)
# vertical line for dataset dimensionality = 64
accuracy.plot([64, 64], [0.7, 1], label="n_features")
# legends and labels
accuracy.set_title("Classification accuracy")
timescale.set_title("Training times")
accuracy.set_xlim(sample_sizes[0], sample_sizes[-1])
accuracy.set_xticks(())
accuracy.set_ylim(np.min(fourier_scores), 1)
timescale.set_xlabel("Sampling steps = transformed feature dimension")
accuracy.set_ylabel("Classification accuracy")
timescale.set_ylabel("Training time in seconds")
accuracy.legend(loc="best")
timescale.legend(loc="best")
plt.tight_layout()
plt.show()
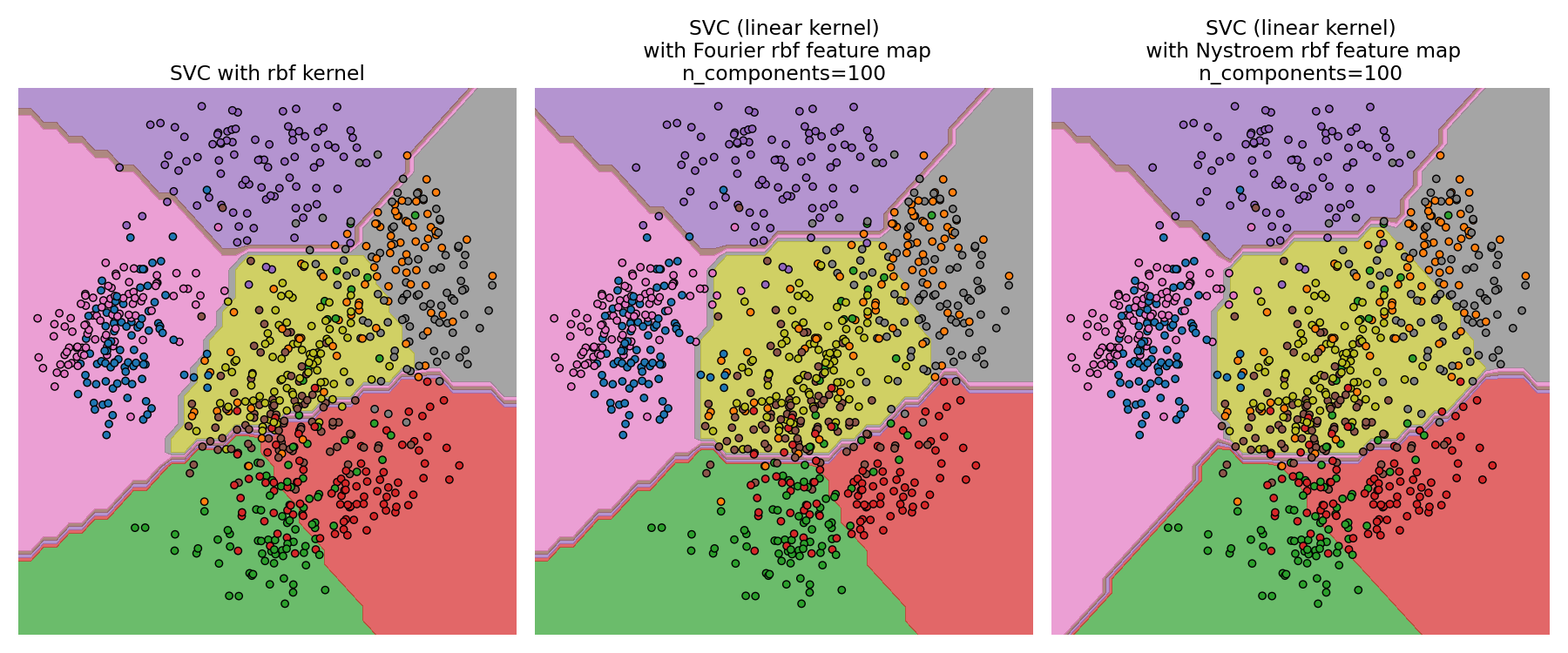
RBS核支持者和线性支持者的决策面#
第二个图通过近似核映射可视化了RBS核支持者和线性支持者的决策面。该图显示了投影到数据前两个主成分上的分类器的决策面。这种可视化应该持保留态度,因为它只是64维决策表面的有趣切片。特别要注意的是,数据点(表示为点)不一定被分类到它所在的区域中,因为它不会位于前两个主成分跨越的平面上。的使用 RBFSampler 和 Nystroem 中详细描述 核近似 .
# visualize the decision surface, projected down to the first
# two principal components of the dataset
pca = PCA(n_components=8, random_state=42).fit(data_train)
X = pca.transform(data_train)
# Generate grid along first two principal components
multiples = np.arange(-2, 2, 0.1)
# steps along first component
first = multiples[:, np.newaxis] * pca.components_[0, :]
# steps along second component
second = multiples[:, np.newaxis] * pca.components_[1, :]
# combine
grid = first[np.newaxis, :, :] + second[:, np.newaxis, :]
flat_grid = grid.reshape(-1, data.shape[1])
# title for the plots
titles = [
"SVC with rbf kernel",
"SVC (linear kernel)\n with Fourier rbf feature map\nn_components=100",
"SVC (linear kernel)\n with Nystroem rbf feature map\nn_components=100",
]
plt.figure(figsize=(18, 7.5))
plt.rcParams.update({"font.size": 14})
# predict and plot
for i, clf in enumerate((kernel_svm, nystroem_approx_svm, fourier_approx_svm)):
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
plt.subplot(1, 3, i + 1)
Z = clf.predict(flat_grid)
# Put the result into a color plot
Z = Z.reshape(grid.shape[:-1])
levels = np.arange(10)
lv_eps = 0.01 # Adjust a mapping from calculated contour levels to color.
plt.contourf(
multiples,
multiples,
Z,
levels=levels - lv_eps,
cmap=plt.cm.tab10,
vmin=0,
vmax=10,
alpha=0.7,
)
plt.axis("off")
# Plot also the training points
plt.scatter(
X[:, 0],
X[:, 1],
c=targets_train,
cmap=plt.cm.tab10,
edgecolors=(0, 0, 0),
vmin=0,
vmax=10,
)
plt.title(titles[i])
plt.tight_layout()
plt.show()
Total running time of the script: (0分2.487秒)
相关实例
Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _