备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
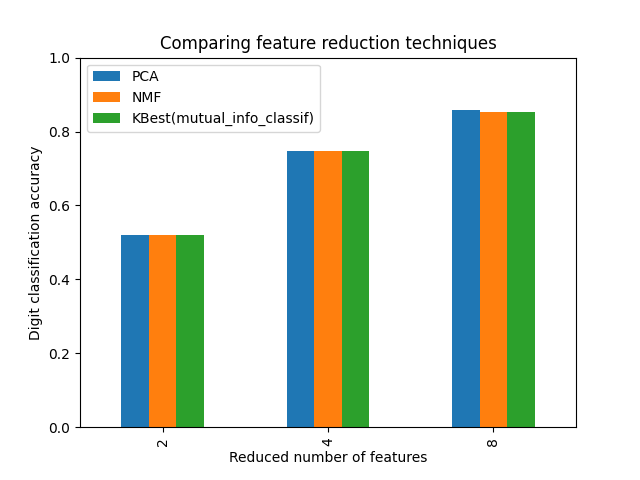
使用Pipeline和GridSearchCV选择降维#
此示例构建了一个管道,该管道先进行降维,然后使用支持载体分类器进行预测。它演示了 GridSearchCV 和 Pipeline 在单次CV运行中优化不同类别的估计量--无监督 PCA 和 NMF 将维度缩减与网格搜索期间的单变量特征选择进行比较。
Additionally, Pipeline can be instantiated with the memory
argument to memoize the transformers within the pipeline, avoiding to fit
again the same transformers over and over.
请注意,使用 memory 当Transformer的安装成本很高时,启用缓存就会变得有趣。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
说明 Pipeline 和 GridSearchCV#
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import NMF, PCA
from sklearn.feature_selection import SelectKBest, mutual_info_classif
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import LinearSVC
X, y = load_digits(return_X_y=True)
pipe = Pipeline(
[
("scaling", MinMaxScaler()),
# the reduce_dim stage is populated by the param_grid
("reduce_dim", "passthrough"),
("classify", LinearSVC(dual=False, max_iter=10000)),
]
)
N_FEATURES_OPTIONS = [2, 4, 8]
C_OPTIONS = [1, 10, 100, 1000]
param_grid = [
{
"reduce_dim": [PCA(iterated_power=7), NMF(max_iter=1_000)],
"reduce_dim__n_components": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
{
"reduce_dim": [SelectKBest(mutual_info_classif)],
"reduce_dim__k": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
]
reducer_labels = ["PCA", "NMF", "KBest(mutual_info_classif)"]
grid = GridSearchCV(pipe, n_jobs=1, param_grid=param_grid)
grid.fit(X, y)
import pandas as pd
mean_scores = np.array(grid.cv_results_["mean_test_score"])
# scores are in the order of param_grid iteration, which is alphabetical
mean_scores = mean_scores.reshape(len(C_OPTIONS), -1, len(N_FEATURES_OPTIONS))
# select score for best C
mean_scores = mean_scores.max(axis=0)
# create a dataframe to ease plotting
mean_scores = pd.DataFrame(
mean_scores.T, index=N_FEATURES_OPTIONS, columns=reducer_labels
)
ax = mean_scores.plot.bar()
ax.set_title("Comparing feature reduction techniques")
ax.set_xlabel("Reduced number of features")
ax.set_ylabel("Digit classification accuracy")
ax.set_ylim((0, 1))
ax.legend(loc="upper left")
plt.show()
在一个内缓存变压器 Pipeline#
有时,存储特定Transformer的状态是值得的,因为它可以再次使用。使用管道在 GridSearchCV 触发此类情况。因此,我们使用这个论点 memory 以启用缓存。
警告
但是,请注意,这个示例只是一个说明,因为对于这种特定情况,匹配PCA不一定比加载缓存慢。因此,使用 memory 当Transformer的装配成本很高时,则需要使用构造函数参数。
from shutil import rmtree
from joblib import Memory
# Create a temporary folder to store the transformers of the pipeline
location = "cachedir"
memory = Memory(location=location, verbose=10)
cached_pipe = Pipeline(
[("reduce_dim", PCA()), ("classify", LinearSVC(dual=False, max_iter=10000))],
memory=memory,
)
# This time, a cached pipeline will be used within the grid search
# Delete the temporary cache before exiting
memory.clear(warn=False)
rmtree(location)
的 PCA 仅在评估的第一个配置时计算配合 C 参数 LinearSVC 分类器的其他配置 C 将触发缓存的加载 PCA 估计器数据,从而节省处理时间。因此,使用缓存管道的使用 memory 当安装Transformer成本很高时,
Total running time of the script: (0分41.371秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _