备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
scikit-learn 1.5的发布亮点#
我们很高兴宣布scikit-learn 1.5的发布!添加了许多错误修复和改进,以及一些关键的新功能。下面我们详细介绍了该版本的亮点。 For an exhaustive list of all the changes ,请参阅 release notes .
安装最新版本(使用pip):
pip install --upgrade scikit-learn
或带有conda::
conda install -c conda-forge scikit-learn
FixedDeliverholdClassifier:设置二元分类器的决策阈值#
scikit-learn的所有二进制分类器都使用0.5的固定决策阈值来转换概率估计(即 predict_proba )到类的预测。然而,对于给定的问题,0.5几乎从来都不是理想的阈值。 FixedThresholdClassifier 允许包装任何二元分类器并设置自定义决策阈值。
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=10_000, weights=[0.9, 0.1], random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
classifier_05 = LogisticRegression(C=1e6, random_state=0).fit(X_train, y_train)
_ = ConfusionMatrixDisplay.from_estimator(classifier_05, X_test, y_test)
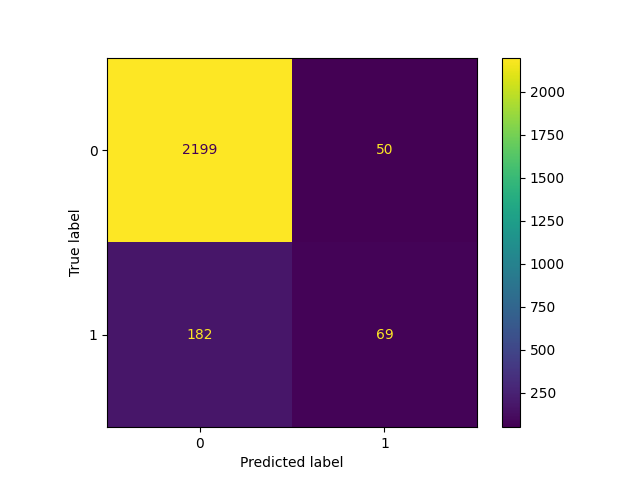
降低阈值,即允许更多样本被分类为阳性类别,会以更多假阳性为代价增加真阳性的数量(正如从ROC曲线的预设中所熟知的那样)。
from sklearn.model_selection import FixedThresholdClassifier
classifier_01 = FixedThresholdClassifier(classifier_05, threshold=0.1)
classifier_01.fit(X_train, y_train)
_ = ConfusionMatrixDisplay.from_estimator(classifier_01, X_test, y_test)
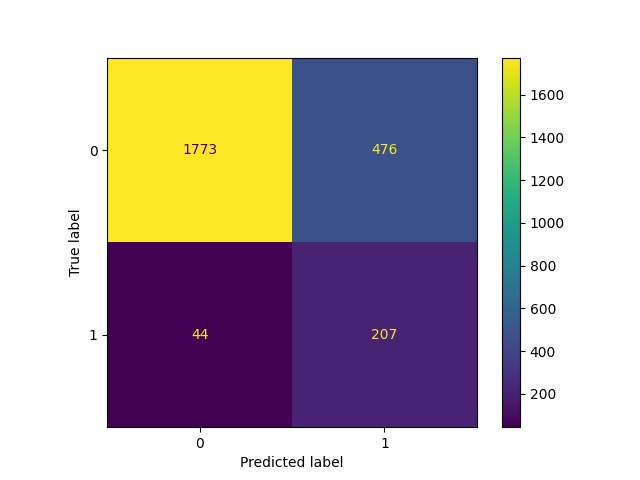
TunedHoldClassifierCV:调整二元分类器的决策阈值#
二元分类器的决策阈值可以被调整以优化给定的度量,使用 TunedThresholdClassifierCV .
当模型打算部署在特定的应用环境中时,找到最佳决策阈值特别有用,在特定的应用环境中,我们可以为真阳性、真阴性、假阳性和假阴性分配不同的收益或成本。
让我们通过考虑一个任意情况来说明这一点:
每一个真正获得1个单位的利润,例如欧元、健康的寿命等;
真正的否定不会带来任何好处或代价;
每个假阴性费用2;
每一个假阳性的代价是0.1。
我们的指标量化了每个样本的平均利润,该利润由以下Python函数定义:
from sklearn.metrics import confusion_matrix
def custom_score(y_observed, y_pred):
tn, fp, fn, tp = confusion_matrix(y_observed, y_pred, normalize="all").ravel()
return tp - 2 * fn - 0.1 * fp
print("Untuned decision threshold: 0.5")
print(f"Custom score: {custom_score(y_test, classifier_05.predict(X_test)):.2f}")
Untuned decision threshold: 0.5
Custom score: -0.12
有趣的是,观察到每个预测的平均增益是负的,这意味着这个决策系统平均损失。
调整阈值以优化此自定义指标会提供更小的阈值,允许更多样本被分类为阳性类别。结果,每次预测的平均收益得到改善。
from sklearn.metrics import make_scorer
from sklearn.model_selection import TunedThresholdClassifierCV
custom_scorer = make_scorer(
custom_score, response_method="predict", greater_is_better=True
)
tuned_classifier = TunedThresholdClassifierCV(
classifier_05, cv=5, scoring=custom_scorer
).fit(X, y)
print(f"Tuned decision threshold: {tuned_classifier.best_threshold_:.3f}")
print(f"Custom score: {custom_score(y_test, tuned_classifier.predict(X_test)):.2f}")
Tuned decision threshold: 0.071
Custom score: 0.04
我们观察到,调整决策阈值可以将基于机器学习的系统从平均损失变成有益的损失。
在实践中,定义有意义的特定于应用程序的指标可能涉及使坏预测的成本和好预测的收益取决于特定于每个单独数据点的辅助元数据,例如欺诈检测系统中的交易金额。
为了实现这一目标, TunedThresholdClassifierCV 利用元数据路由支持 (Metadata Routing User Guide )允许优化复杂的业务指标,详细说明 Post-tuning the decision threshold for cost-sensitive learning .
PCA的性能改进#
PCA 有一个新的求解器, "covariance_eigh" ,对于数据点多且特征少的数据集,它比其他求解器快一个数量级,内存效率更高。
from sklearn.datasets import make_low_rank_matrix
from sklearn.decomposition import PCA
X = make_low_rank_matrix(
n_samples=10_000, n_features=100, tail_strength=0.1, random_state=0
)
pca = PCA(n_components=10, svd_solver="covariance_eigh").fit(X)
print(f"Explained variance: {pca.explained_variance_ratio_.sum():.2f}")
Explained variance: 0.88
新的求解器还接受稀疏输入数据:
from scipy.sparse import random
X = random(10_000, 100, format="csr", random_state=0)
pca = PCA(n_components=10, svd_solver="covariance_eigh").fit(X)
print(f"Explained variance: {pca.explained_variance_ratio_.sum():.2f}")
Explained variance: 0.13
的 "full" 求解器也进行了改进,可以使用更少的内存并允许更快的转换。默认 svd_solver="auto" 选项利用了新的求解器,现在可以为稀疏数据集选择适当的求解器。
与大多数其他PCA求解器类似,新的 "covariance_eigh" 如果输入数据作为PyTorch或CuPy阵列传递,则求解器可以通过启用实验支持来利用图形处理器计算 Array API .
专栏Transformer可订阅#
一个的变形金刚 ColumnTransformer 现在可以使用按名称索引直接访问。
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
X = np.array([[0, 1, 2], [3, 4, 5]])
column_transformer = ColumnTransformer(
[("std_scaler", StandardScaler(), [0]), ("one_hot", OneHotEncoder(), [1, 2])]
)
column_transformer.fit(X)
print(column_transformer["std_scaler"])
print(column_transformer["one_hot"])
StandardScaler()
OneHotEncoder()
SimpleImputer的自定义归责策略#
SimpleImputer 现在支持自定义插补策略,使用可调用函数从列载体的非缺失值计算纯量值。
from sklearn.impute import SimpleImputer
X = np.array(
[
[-1.1, 1.1, 1.1],
[3.9, -1.2, np.nan],
[np.nan, 1.3, np.nan],
[-0.1, -1.4, -1.4],
[-4.9, 1.5, -1.5],
[np.nan, 1.6, 1.6],
]
)
def smallest_abs(arr):
"""Return the smallest absolute value of a 1D array."""
return np.min(np.abs(arr))
imputer = SimpleImputer(strategy=smallest_abs)
imputer.fit_transform(X)
array([[-1.1, 1.1, 1.1],
[ 3.9, -1.2, 1.1],
[ 0.1, 1.3, 1.1],
[-0.1, -1.4, -1.4],
[-4.9, 1.5, -1.5],
[ 0.1, 1.6, 1.6]])
非数字数组的成对距离#
pairwise_distances 现在可以使用可调用的指标计算非数字数组之间的距离。
from sklearn.metrics import pairwise_distances
X = ["cat", "dog"]
Y = ["cat", "fox"]
def levenshtein_distance(x, y):
"""Return the Levenshtein distance between two strings."""
if x == "" or y == "":
return max(len(x), len(y))
if x[0] == y[0]:
return levenshtein_distance(x[1:], y[1:])
return 1 + min(
levenshtein_distance(x[1:], y),
levenshtein_distance(x, y[1:]),
levenshtein_distance(x[1:], y[1:]),
)
pairwise_distances(X, Y, metric=levenshtein_distance)
array([[0., 3.],
[3., 2.]])
Total running time of the script: (0分0.733秒)
相关实例


Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _