备注
Go to the end 下载完整的示例代码。或者通过浏览器中的MysterLite或Binder运行此示例
使用堆叠组合预测因子#
Stacking是一种混合估计量的方法。在这种策略中,一些估计量单独拟合在一些训练数据上,而最终估计量使用这些基本估计量的堆叠预测来训练。
在这个例子中,我们说明了不同的回归量堆叠在一起并使用最终的线性惩罚回归量来输出预测的用例。我们将每个回归量的性能与堆叠策略进行比较。堆叠稍微提高了整体性能。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
下载数据集#
我们将使用 Ames Housing 该数据集首先由Dean De Cock编制,并在Kaggle挑战中使用后变得更加出名。它是爱荷华州艾姆斯的一套1460套住宅,每套住宅由80个特征描述。我们将使用它来预测房屋的最终对数价格。在这个例子中,我们将仅使用EntityBoostingRegressor()选择的20个最有趣的功能并限制条目数量(在这里我们不会详细说明如何选择最有趣的功能)。
Ames住房数据集没有随scikit-learn一起提供,因此我们将从 OpenML .
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
def load_ames_housing():
df = fetch_openml(name="house_prices", as_frame=True)
X = df.data
y = df.target
features = [
"YrSold",
"HeatingQC",
"Street",
"YearRemodAdd",
"Heating",
"MasVnrType",
"BsmtUnfSF",
"Foundation",
"MasVnrArea",
"MSSubClass",
"ExterQual",
"Condition2",
"GarageCars",
"GarageType",
"OverallQual",
"TotalBsmtSF",
"BsmtFinSF1",
"HouseStyle",
"MiscFeature",
"MoSold",
]
X = X.loc[:, features]
X, y = shuffle(X, y, random_state=0)
X = X.iloc[:600]
y = y.iloc[:600]
return X, np.log(y)
X, y = load_ames_housing()
制作管道预处理数据#
在使用Ames数据集之前,我们仍然需要进行一些预处理。首先,我们将选择数据集的类别和数字列来构建管道的第一步。
from sklearn.compose import make_column_selector
cat_selector = make_column_selector(dtype_include=object)
num_selector = make_column_selector(dtype_include=np.number)
cat_selector(X)
['HeatingQC', 'Street', 'Heating', 'MasVnrType', 'Foundation', 'ExterQual', 'Condition2', 'GarageType', 'HouseStyle', 'MiscFeature']
num_selector(X)
['YrSold', 'YearRemodAdd', 'BsmtUnfSF', 'MasVnrArea', 'MSSubClass', 'GarageCars', 'OverallQual', 'TotalBsmtSF', 'BsmtFinSF1', 'MoSold']
然后,我们需要根据结束回归量设计预处理管道。如果结束回归量是线性模型,则需要对类别进行一次性编码。如果结束回归量是基于树的模型,有序编码器就足够了。此外,线性模型的数值需要标准化,而原始数字数据可以通过基于树的模型原样处理。然而,这两个模型都需要插补器来处理缺失的值。
我们将首先设计基于树的模型所需的管道。
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder
cat_tree_processor = OrdinalEncoder(
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-2,
)
num_tree_processor = SimpleImputer(strategy="mean", add_indicator=True)
tree_preprocessor = make_column_transformer(
(num_tree_processor, num_selector), (cat_tree_processor, cat_selector)
)
tree_preprocessor
然后,我们现在将定义当结束回归量是线性模型时使用的预处理器。
from sklearn.preprocessing import OneHotEncoder, StandardScaler
cat_linear_processor = OneHotEncoder(handle_unknown="ignore")
num_linear_processor = make_pipeline(
StandardScaler(), SimpleImputer(strategy="mean", add_indicator=True)
)
linear_preprocessor = make_column_transformer(
(num_linear_processor, num_selector), (cat_linear_processor, cat_selector)
)
linear_preprocessor
单个数据集上的预测器堆栈#
找到在给定数据集上表现最佳的模型有时很乏味。堆叠通过组合多个学习者的输出提供了一种替代方案,而无需专门选择模型。堆叠的性能通常接近最佳模型,有时它可能会优于每个单个模型的预测性能。
在这里,我们组合3个学习器(线性和非线性)并使用岭回归器将它们的输出组合在一起。
备注
尽管我们将使用我们在上一节中为3个学习器(最终估计器)编写的处理器来创建新的管道 RidgeCV() 不需要对数据进行预处理,因为它将被馈送来自3个学习器的已经预处理的输出。
from sklearn.linear_model import LassoCV
lasso_pipeline = make_pipeline(linear_preprocessor, LassoCV())
lasso_pipeline
from sklearn.ensemble import RandomForestRegressor
rf_pipeline = make_pipeline(tree_preprocessor, RandomForestRegressor(random_state=42))
rf_pipeline
from sklearn.ensemble import HistGradientBoostingRegressor
gbdt_pipeline = make_pipeline(
tree_preprocessor, HistGradientBoostingRegressor(random_state=0)
)
gbdt_pipeline
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import RidgeCV
estimators = [
("Random Forest", rf_pipeline),
("Lasso", lasso_pipeline),
("Gradient Boosting", gbdt_pipeline),
]
stacking_regressor = StackingRegressor(estimators=estimators, final_estimator=RidgeCV())
stacking_regressor
测量并绘制结果#
现在我们可以使用Ames Housing数据集进行预测。我们检查每个单独的预测器以及回归器堆栈的性能。
import time
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
from sklearn.model_selection import cross_val_predict, cross_validate
fig, axs = plt.subplots(2, 2, figsize=(9, 7))
axs = np.ravel(axs)
for ax, (name, est) in zip(
axs, estimators + [("Stacking Regressor", stacking_regressor)]
):
scorers = {"R2": "r2", "MAE": "neg_mean_absolute_error"}
start_time = time.time()
scores = cross_validate(
est, X, y, scoring=list(scorers.values()), n_jobs=-1, verbose=0
)
elapsed_time = time.time() - start_time
y_pred = cross_val_predict(est, X, y, n_jobs=-1, verbose=0)
scores = {
key: (
f"{np.abs(np.mean(scores[f'test_{value}'])):.2f} +- "
f"{np.std(scores[f'test_{value}']):.2f}"
)
for key, value in scorers.items()
}
display = PredictionErrorDisplay.from_predictions(
y_true=y,
y_pred=y_pred,
kind="actual_vs_predicted",
ax=ax,
scatter_kwargs={"alpha": 0.2, "color": "tab:blue"},
line_kwargs={"color": "tab:red"},
)
ax.set_title(f"{name}\nEvaluation in {elapsed_time:.2f} seconds")
for name, score in scores.items():
ax.plot([], [], " ", label=f"{name}: {score}")
ax.legend(loc="upper left")
plt.suptitle("Single predictors versus stacked predictors")
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
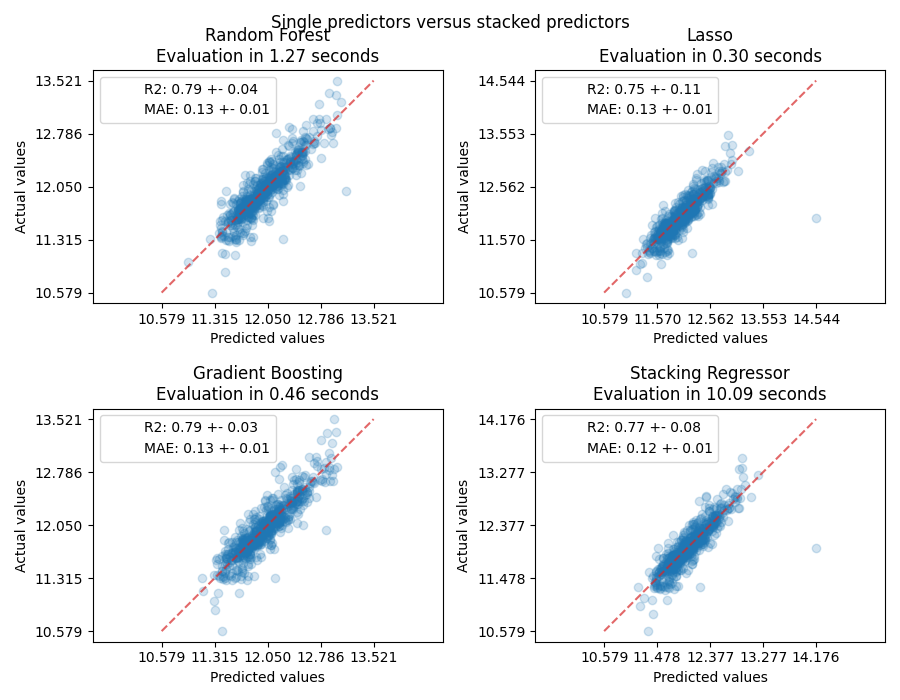
堆叠回归量将结合不同回归量的优势。然而,我们也看到训练堆叠回归量的计算成本要高得多。
Total running time of the script: (0分24.523秒)
相关实例

Gallery generated by Sphinx-Gallery <https://sphinx-gallery.github.io> _