ConfusionMatrixDisplay#
- class sklearn.metrics.ConfusionMatrixDisplay(confusion_matrix, *, display_labels=None)[源代码]#
混乱矩阵可视化。
建议使用
from_estimator或from_predictions创建一个ConfusionMatrixDisplay.所有参数都存储为属性。阅读更多的 User Guide .
- 参数:
- confusion_matrix形状的ndarray(n_classes,n_classes)
混淆矩阵。
- display_labelsndarray of shape(n_classes,),default=None
显示绘图的标签。如果无,则显示标签设置为从0到
n_classes - 1.
- 属性:
- im_matplotlib AxesImage
代表混淆矩阵的图像。
- text_nd形状数组(n_classes,n_classes),dype =matplotlib文本, 或没有
matplotlib轴数组。
None如果include_values是错误的。- ax_matplotlib轴
带有混淆矩阵的轴。
- figure_matplotlib图
包含混淆矩阵的图。
参见
confusion_matrix计算混淆矩阵以评估分类的准确性。
ConfusionMatrixDisplay.from_estimator在给定估计量、数据和标签的情况下绘制混淆矩阵。
ConfusionMatrixDisplay.from_predictions给定真实和预测标签,绘制混淆矩阵。
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay >>> from sklearn.model_selection import train_test_split >>> from sklearn.svm import SVC >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... random_state=0) >>> clf = SVC(random_state=0) >>> clf.fit(X_train, y_train) SVC(random_state=0) >>> predictions = clf.predict(X_test) >>> cm = confusion_matrix(y_test, predictions, labels=clf.classes_) >>> disp = ConfusionMatrixDisplay(confusion_matrix=cm, ... display_labels=clf.classes_) >>> disp.plot() <...> >>> plt.show()
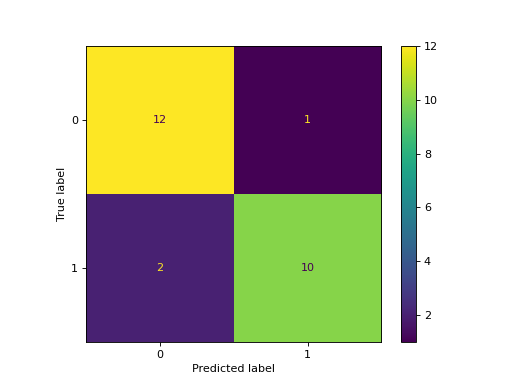
- classmethod from_estimator(estimator, X, y, *, labels=None, sample_weight=None, normalize=None, display_labels=None, include_values=True, xticks_rotation='horizontal', values_format=None, cmap='viridis', ax=None, colorbar=True, im_kw=None, text_kw=None)[源代码]#
给定估计量和一些数据,绘制混乱矩阵。
阅读更多的 User Guide .
Added in version 1.0.
- 参数:
- estimator估计器实例
安装分类器或安装
Pipeline其中最后一个估计器是分类器。- X形状(n_samples,n_features)的{类数组,稀疏矩阵}
输入值。
- y形状类似阵列(n_samples,)
目标值。
- labels形状类似数组(n_classes,),默认=无
用于索引混淆矩阵的标签列表。这可以用于重新排序或选择标签的子集。如果
None给出的是那些至少出现一次的y_true或y_pred按排序顺序使用。- sample_weight形状类似数组(n_samples,),默认=无
样本重量。
- normalize' true ',' pred ','},默认=无
要么规范化矩阵中显示的计数:
如果
'true',混淆矩阵在真实条件(例如行)上进行标准化;如果
'pred'在预测条件(例如列)上对混淆矩阵进行归一化;如果
'all',混淆矩阵通过样本总数进行标准化;如果
None(默认),混淆矩阵将不会被规范化。
- display_labels形状类似数组(n_classes,),默认=无
用于绘图的目标名称。默认情况下,
labels如果已定义,将使用,否则将使用的唯一标签y_true和y_pred将用于- include_values布尔,默认=True
Includes values in confusion matrix.
- xticks_rotation“垂直”、“水平”}或浮动, 默认='水平'
xtick标签的旋转。
- values_format字符串,默认=无
混淆矩阵中值的格式规范。如果
None,格式规范为“d”或“.2g”,以较短者为准。- cmap字符串或matplotlib Color map,默认=' viridis '
由matplotlib识别的色彩映射表。
- axmatplotlib轴,默认=无
轴反对绘图。如果
None,创建新图形和轴。- colorbar布尔,默认=True
是否向情节添加彩色条。
- im_kwdict,默认=无
关键词传递给的直接内容
matplotlib.pyplot.imshow电话- text_kwdict,默认=无
关键词传递给的直接内容
matplotlib.pyplot.text电话Added in version 1.2.
- 返回:
参见
ConfusionMatrixDisplay.from_predictions给定真实和预测标签,绘制混淆矩阵。
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.metrics import ConfusionMatrixDisplay >>> from sklearn.model_selection import train_test_split >>> from sklearn.svm import SVC >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = SVC(random_state=0) >>> clf.fit(X_train, y_train) SVC(random_state=0) >>> ConfusionMatrixDisplay.from_estimator( ... clf, X_test, y_test) <...> >>> plt.show()
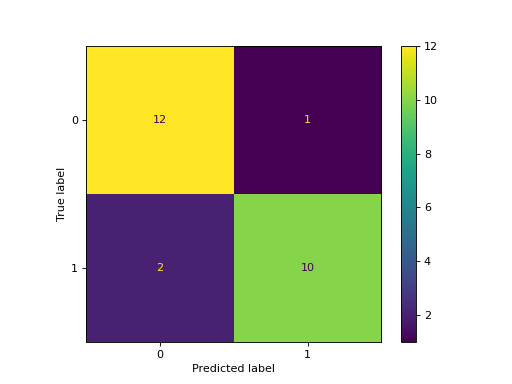
- classmethod from_predictions(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None, display_labels=None, include_values=True, xticks_rotation='horizontal', values_format=None, cmap='viridis', ax=None, colorbar=True, im_kw=None, text_kw=None)[源代码]#
绘制混淆矩阵,给出真实和预测标签。
阅读更多的 User Guide .
Added in version 1.0.
- 参数:
- y_true形状类似阵列(n_samples,)
真正的标签。
- y_pred形状类似阵列(n_samples,)
该方法给出的预测标签
predict分类器的。- labels形状类似数组(n_classes,),默认=无
用于索引混淆矩阵的标签列表。这可以用于重新排序或选择标签的子集。如果
None给出的是那些至少出现一次的y_true或y_pred按排序顺序使用。- sample_weight形状类似数组(n_samples,),默认=无
样本重量。
- normalize' true ',' pred ','},默认=无
要么规范化矩阵中显示的计数:
如果
'true',混淆矩阵在真实条件(例如行)上进行标准化;如果
'pred'在预测条件(例如列)上对混淆矩阵进行归一化;如果
'all',混淆矩阵通过样本总数进行标准化;如果
None(默认),混淆矩阵将不会被规范化。
- display_labels形状类似数组(n_classes,),默认=无
用于绘图的目标名称。默认情况下,
labels如果已定义,将使用,否则将使用的唯一标签y_true和y_pred将用于- include_values布尔,默认=True
Includes values in confusion matrix.
- xticks_rotation“垂直”、“水平”}或浮动, 默认='水平'
xtick标签的旋转。
- values_format字符串,默认=无
混淆矩阵中值的格式规范。如果
None,格式规范为“d”或“.2g”,以较短者为准。- cmap字符串或matplotlib Color map,默认=' viridis '
由matplotlib识别的色彩映射表。
- axmatplotlib轴,默认=无
轴反对绘图。如果
None,创建新图形和轴。- colorbar布尔,默认=True
是否向情节添加彩色条。
- im_kwdict,默认=无
关键词传递给的直接内容
matplotlib.pyplot.imshow电话- text_kwdict,默认=无
关键词传递给的直接内容
matplotlib.pyplot.text电话Added in version 1.2.
- 返回:
参见
ConfusionMatrixDisplay.from_estimator在给定估计量、数据和标签的情况下绘制混淆矩阵。
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.metrics import ConfusionMatrixDisplay >>> from sklearn.model_selection import train_test_split >>> from sklearn.svm import SVC >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = SVC(random_state=0) >>> clf.fit(X_train, y_train) SVC(random_state=0) >>> y_pred = clf.predict(X_test) >>> ConfusionMatrixDisplay.from_predictions( ... y_test, y_pred) <...> >>> plt.show()

- plot(*, include_values=True, cmap='viridis', xticks_rotation='horizontal', values_format=None, ax=None, colorbar=True, im_kw=None, text_kw=None)[源代码]#
情节可视化。
- 参数:
- include_values布尔,默认=True
Includes values in confusion matrix.
- cmap字符串或matplotlib Color map,默认=' viridis '
由matplotlib识别的色彩映射表。
- xticks_rotation“垂直”、“水平”}或浮动, 默认='水平'
xtick标签的旋转。
- values_format字符串,默认=无
混淆矩阵中值的格式规范。如果
None,格式规范为“d”或“.2g”,以较短者为准。- axmatplotlib轴,默认=无
轴反对绘图。如果
None,创建新图形和轴。- colorbar布尔,默认=True
是否向情节添加彩色条。
- im_kwdict,默认=无
关键词传递给的直接内容
matplotlib.pyplot.imshow电话- text_kwdict,默认=无
关键词传递给的直接内容
matplotlib.pyplot.text电话Added in version 1.2.
- 返回:
- display :
ConfusionMatrixDisplayConfusionMatrixDisplay 返回一个
ConfusionMatrixDisplay包含绘制混淆矩阵的所有信息的实例。
- display :