>>> from env_helper import info; info()
页面更新时间: 2024-03-14 20:52:55
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-18-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
4.7. —般情况使用ElementTree解析XML¶
xml.dom.minidom和xml.sax大槪是Python中解析XML文件最广为人知的两个模块了,
原因一是这两个模块自Python
2.0以来就成为Python的标准库;二是网上关于这两个模块的
使用方面的资料最多。作为主要解析XML方法的两种实现,DOM需要将整个XML文件加
载到内存中并解析为一棵树,虽然使用较为简单,但占用内存较多.性能方面不占优势,并
且不够Pythonic;而SAX是基于事件驱动的,虽不需要全部装人XML文件,但其处理过程
却较为复杂实际上Python中对XML的处理还有更好的选择,ElementTree便是其中一个,
–般情况下使用ElementTree便已足够。它从Python2.5开始成为标准模块,cEkraentTree是
ElememTree的Cython实现,速度更快,消耗内存更少,性能上更占优势,在实际使用过程
中应该尽ft优先使用cElemcntTree。由于两者使用方式上完全兼容本文将两者看做一个物件,
除非说明不再刻意区分。ElememTree在解析XML文件上具有以下特性:
使用简单。它将整个XML文件以树的形式展示.每一个元素的属性以字典的形式表 示,非常方便处理。
内存上消耗明显低于DOM解折。由于ElementTree底层进行了一定的优化,并且它 的iterparse解析工具支持SAX事件驱动,能够以迭代的形式返回XML部分数据结 构,从而避免将整个XML文件加载到内存中,因此性能上更优化,相比于SAX使 用起来更为简单明了。
支持XPath查询,非常方便获取任意节点的值。
这里需要说明的是,一般情况指的是:XML文件大小适中,对性能要求并非非常严格。 如果在实际过程中需要处理的XML文件大小在GB或近似GB级别,第三方模块 lxml 会获得较优的处理结果。关于lxml模块的介绍请参考本章后续小节或者参考文章“使用由Python 编写的lxml 实现高性能 XML 解析”,可通过链接 http://www.ibm.comAleveloperworks/cn/xml/x-hiperfparse/ 可以访问。
下面结合具体的实例来说明dementtree解析XML文件常用的方法。需要解析的XML 实例如下:
>>> !cat test2.xml
<?xml version="1.0" encoding="UTF-8" ?>
<books>
<book id="1001">
<name>面纱</name>
<userid>root2</userid>
<info>请记住我,虽然再见必须说</info>
</book>
<book id="1002">
<name>人生第一次</name>
<userid>root3</userid>
<info>愿他们、我们的一生平淡而有意义</info>
</book>
</books>
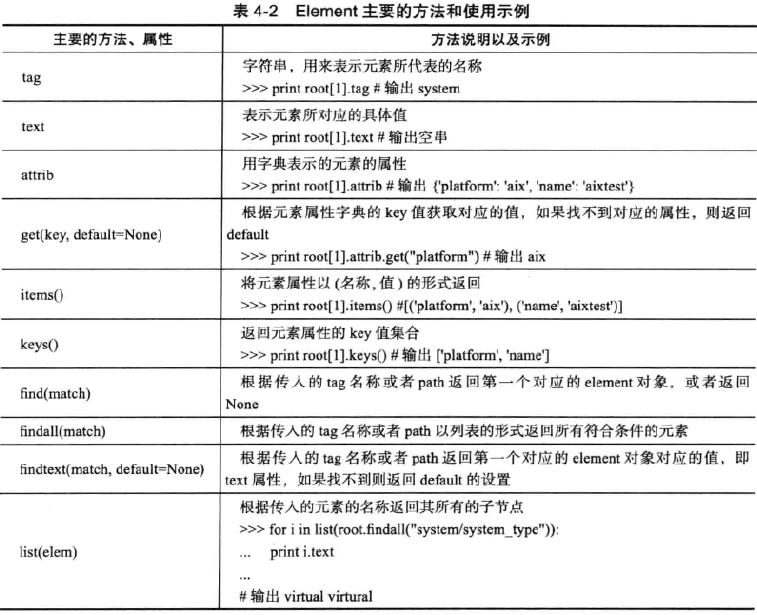
模块ElementTrec主要存在两种类型EkmeutTree和Ekment,它们支持的方法以及对应 的使用示例如下表。
表一:

表二:

表三:
前面我们提到elementree的iterparse工具能够避免将整个XML文件加载到内存。 从 而解决当读人文件过大内存而消耗过多的问题。 iterparse返回一个可以迭代的由元组(时间,元素)组成的流对象,支持两个参数:source和events,其中event有4种选择:start、end k startns 和 endns (默认为 end ),分別与 SAX 解析的 startElement、endElemenU startElementNS 和 endElementNS 一一对应。
本节最后来看一下iterparse的使用示例:统计userid在整个XML出现的次数。
>>> count=0
>>> import xml.etree.ElementTree as ET
>>> for event,elem in ET.iterparse("test2.xml"): # 对 iterparse 的返回值进行迭代
>>> if event== "end":
>>> if elem.tag=="userid":
>>> count+=1
>>> elem.clear()
>>> print(count)
2