>>> from env_helper import info; info()
页面更新时间: 2024-03-29 11:56:41
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-18-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
1.1. 理解Python中的数据类型¶
想要有效的掌握数据驱动科学和计算需要理解数据是如何存储和处理的。 本节将描述和对比数组在Python语言中和在NumPy中是怎么处理的,NumPy是如何优化了这部分的内容。 理解这个区别是理解本书后续内容的基础。
Python的用户通常都是被它的易用性吸引来的,其中很重要一环就是动态类型。静态类型的语言,例如C或者Java,每个变量都需要明确声明,而动态类型语言如Python就略过了这个部分。例如,在C中,你可能会写如下的代码片段:
int result = 0;
for(int i=0; i<100; i++){
result += i;
}
但是在Python当中,等效的代码如下:
result = 0
for i in range(100):
result += i
注意其中主要的区别:在C当中,每个变量都需要显式声明,Python的类型是动态推断的。这意味着,我们可以给任何的变量赋值为任何类型的数据,例如:
x = 4
x = "four"
上面的例子中我们将x变量的内容从一个整数变成了一个字符串。如果你想在C语言中这样做,取决于不同的编译器,可能会导致一个编译错误或者其他无法预料的结果。
int x = 4;
x = "four"; // 编译错误
理解这里面的工作原理对于在Python中高效准确的学习和分析数据是非常重要的。
Python和其他动态类型语言的这种灵活性提供了在使用上的简易性。 Python的这种类型灵活性,实际上是付出了额外的存储代价的,变量不仅仅存储了数据本身,还需要存储其相应的类型。
我们会在本节接下来的部分继续讨论。
1.1.1. Python的整数不仅仅是一个整数¶
标准的Python实现是使用C语言编写的。这意味着每个Python当中的对象都是一个伪装良好的C结构体,结构体内不仅仅包括它的值,还有其他的信息。例如,当我们在Python中定义了一个整数,比方说x=10000,x不仅仅是一个原始的整数,它在底层实际上是一个指向复杂C结构体的指针,里面含有若干个字段。当你查阅Python
3.4的源代码的时候,你会发现整数(实际上是长整形)的定义如下(我们将C语言中的宏定义展开后):
struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
};
一个Python的整数实际上包含四个部分:
ob_refcnt:引用计数器,Python用这个字段来进行内存分配和垃圾收集ob_type:变量类型的编码内容ob_size:表示下面的数据字段的长度ob_digit:真正的整数值存储在这个字段
这意味着在Python中存储一个整数要比在像C这样的编译语言中存储一个整数要有损耗,就像下图展示的那样:
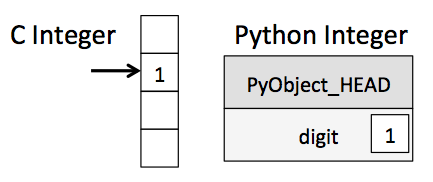
图 1.1 Integer Memory Layout¶
这里的PyObject_HEAD代表了前面的引用计数器、类型代码和数据长度的三个字段内容。
再次注意一下这里的区别:C的整数就是简单一个内存位置,这个位置上的固定长度的字节可以表示一个整数;Python中的一个整数是一个指向内存位置的指针,该内存位置包括Python需要表示一个整数的所有信息,其中最后固定长度的字节才真正存储这个整数。这些额外的信息提供了Python的灵活性和易用性。这些Python类型需要的额外信息是有额外损失的,特别是当有一个集合需要存储许多这种类型的数据时。
1.1.2. Python的列表不仅仅是一个列表¶
现在我们继续考虑当我们使用Python的数据结构来存储许多这样的Python对象时的情况。Python中标准的可变多元素的容器集合就是列表。我们按如下的方式创建一个整数的列表:
>>> L = list(range(10))
>>> L
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> type(L[0])
int
又或者,类似的,字符串的列表:
>>> L2 = [str(c) for c in L] # 列表解析
>>> L2
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
>>> type(L2[0])
str
因为Python是动态类型,我们甚至可以创建不同类型元素的列表:
>>> L3 = [True, "2", 3.0, 4]
>>> [type(item) for item in L3]
[bool, str, float, int]
这种灵活性是要付出代价的:要让列表能够容纳不同的类型,每个列表中的元素都必须带有自己的类型信息、引用计数器和其他的信息。 一句话,里面的每个元素都是一个完整的Python的对象。
如果在所有的元素都是同一种类型的情况下,这里面绝大部分的信息都是冗余的。 从而可知,如果我们能将数据存储在一个固定类型的数组中,显然会更加高效。
下图展示了动态类型的列表和固定类型的数组(NumPy实现的)的区别:
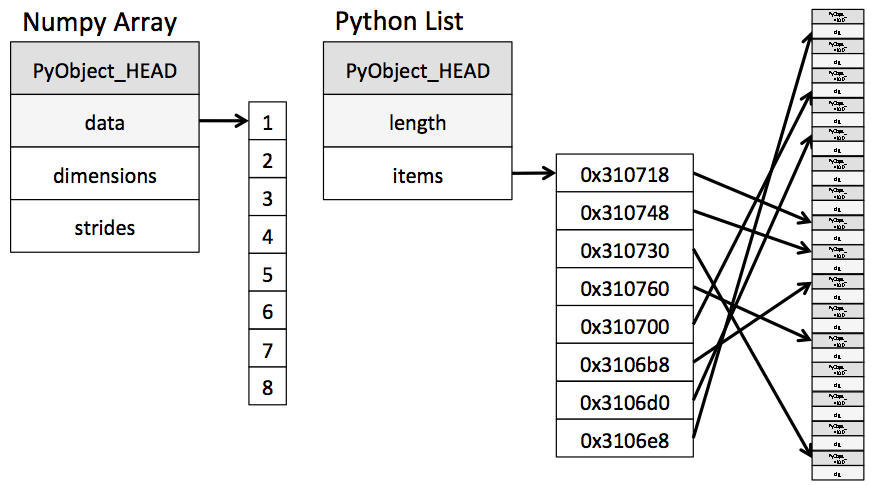
图 1.2 Array Memory Layout¶
从底层实现上看,数组仅仅包含一个指针指向一块连续的内存空间。而Python列表,含有一个指针指向一块连续的指针内存空间,里面的每个指针再指向内存中每个独立的Python对象,如我们前面看到的整数。列表的优势在于灵活:因为每个元素都是完整的Python的类型对象结构,包含了数据和类型信息,因此列表可以存储任何类型的数据。NumPy使用的固定类型的数组缺少这种灵活性,但是对于存储和操作数据会高效许多。
1.1.3. Python的固定类型数组¶
Python提供了许多不同的选择能让你高效的存储数据,使用固定类型数据。內建的
array 模块(从Python 3.3开始提供)可以用来创建同一类型的数组:
>>> import array
>>> L = list(range(10))
>>> A = array.array('i', L)
>>> A
array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
这里的i是表示数据类型是整数的类型代码。
更常用的是ndarray对象,由NumPy包提供。虽然Python的array提供了数组的高效存储,但
NumPy 提供了更加高效的数组 运算 。
我们会在后续小节中陆续介绍这些操作;这里我们首先介绍创建NumPy数组的集中方式。
当然最开始要做的是将NumPy包载入,惯例上提供别名np:
>>> import numpy as np
1.1.4. 使用Python列表创建数组¶
首先,我们可以使用np.array来将一个Python列表变成一个数组:
>>> # 整数数组:
>>> np.array([1, 4, 2, 5, 3])
array([1, 4, 2, 5, 3])
记住和Python列表不同,NumPy数组只能含有同一种类型的数据。如果类型不一样,NumPy会尝试向上扩展类型(下面例子中会将整数向上扩展为浮点数):
>>> np.array([3.14, 4, 2, 3])
array([3.14, 4. , 2. , 3. ])
如果你需要明确指定数据的类型,你可以使用dtype关键字参数:
>>> np.array([1, 2, 3, 4], dtype='float32')
array([1., 2., 3., 4.], dtype=float32)
最后,不同于Python的列表,NumPy的数组可以明确表示为多维;下面例子是一个使用列表的列表来创建二维数组的方法:
>>> # 更准确的说,应该是生成器的列表,列表解析中有三个range生成器
>>> # 分别是range(2, 5), range(4, 7) 和 range(6, 9)
>>> np.array([range(i, i + 3) for i in [2, 4, 6]])
array([[2, 3, 4],
[4, 5, 6],
[6, 7, 8]])
内部的列表作为二维数组的行。
1.1.5. 直接创建 NumPy 数组¶
使用NumPy的方法直接创建数组会更加高效,特别对于大型数组来说。
下面有几个例子:
>>> # zeros将数组元素都填充为0,10是数组长度
>>> np.zeros(10, dtype=int)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> # ones将数组元素都填充为1,(3, 5)是数组的维度说明,表明数组是二维的3行5列
>>> np.ones((3, 5), dtype=float)
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
>>> # full将数组元素都填充为参数值3.14,(3, 5)是数组的维度说明,表明数组是二维的3行5列
>>> np.full((3, 5), 3.14)
array([[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14]])
>>> # arange类似range,创建一段序列值
>>> # 起始值是0(包含),结束值是20(不包含),步长为2
>>> np.arange(0, 20, 2)
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
>>> # linspace创建一段序列值,其中元素按照区域进行线性(平均)划分
>>> # 起始值是0(包含),结束值是1(包含),共5个元素
>>> np.linspace(0, 1, 5)
array([0. , 0.25, 0.5 , 0.75, 1. ])
>>> # random.random随机分布创建数组
>>> # 随机值范围为[0, 1),(3, 3)是维度说明,二维数组3行3列
>>> np.random.random((3, 3))
array([[0.81160819, 0.88681841, 0.01635144],
[0.92427162, 0.86720756, 0.53677897],
[0.48519443, 0.89502805, 0.65398555]])
>>> # random.normal正态分布创建数组
>>> # 均值0,标准差1,(3, 3)是维度说明,二维数组3行3列
>>> np.random.normal(0, 1, (3, 3))
array([[-0.42215473, -0.96124866, 1.37605412],
[ 1.1650768 , -0.78189751, 0.15893883],
[ 0.97936122, 0.35686162, 0.55893652]])
>>> # random.randint随机整数创建数组,随机数范围[0, 10)
>>> np.random.randint(0, 10, (3, 3))
array([[2, 4, 2],
[5, 3, 0],
[0, 8, 3]])
>>> # 3x3的单位矩阵数组
>>> np.eye(3)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
>>> # empty创建一个未初始化的数组,数组元素的值保持为原有的内存空间值
>>> np.empty(3)
array([1., 1., 1.])
1.1.6. NumPy标准数据类型¶
NumPy数组仅包含一种类型数据,因此它的类型系统和Python也有所区别,因为对于每一种NumPy类型,都需要更详细的类型信息和限制。因为NumPy是使用C构建的,它的类型系统对于C、Fortran的用户来说不会陌生。
标准NumPy数据类型见下表。正如上面介绍的,当我们创建数组的时候,我们可以将dtype参数指定为下面类型的字符串名称来指定数组的数据类型。
np.zeros(10, dtype='int16')
也可以将dtype指定为对应的NumPy对象:
np.zeros(10, dtype=np.int16)
Data type |
Description |
|---|---|
|
布尔(True 或 False) 一个字节 |
|
默认整数类型
(类似C的 |
|
类似C的 |
|
用于索引
值的整数(类似C的 |
|
整数,1字节 (-128 ~ 127) |
|
整数,2字节 (-32768 ~ 32767) |
|
整数,4字节 (-2147483648 ~ 2147483647) |
|
整数,8字节 (-9223372036854775808 ~ 9223372036854775807) |
|
字节 (0 ~ 255) |
|
无符号整数 (0 ~ 65535) |
|
无符号整数 (0 ~ 4294967295) |
|
无符号整数 (0 ~ 18446744073709551615) |
|
|
|
半精度浮点数: 1比特符号位, 5比特指数位, 10比特尾数位 |
|
单精度浮点数: 1比特符号位, 8比特指数位, 23比特尾数位 |
|
双精度浮点数: 1比特符号位, 11比特指数位, 52比特尾数位 |
|
|
|
复数, 由2个单精度浮点数组成 |
|
复数, 由2个双精度浮点数组成 |
还有更多的高级的类型声明,比如指定大尾或小尾表示;需要获得更多内容,请查阅NumPy在线文档。
NumPy也支持复合数据类型。