>>> from env_helper import info; info()
页面更新时间: 2023-12-29 21:04:05
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-16-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
5.1. Seaborn介绍¶
Seaborn是一个用于在 Python 中制作统计图形的库,它能够创建高度吸引人的可视化图表,它建立在 matplotlib 之上,并与 pandas 数据结构紧密集成,提供了更为简便的API和更为丰富的可视化函数,使得数据分析与可视化变得更加容易。Seaborn 的设计哲学是以美学为中心,致力于创建最佳的数据可视化,同时也保持着与 Python 生态系统的高度兼容性,可以轻松集成到 Python 数据分析以及机器学习的工作流程中。
Seaborn 可帮助您探索和理解您的数据。其绘图功能对包含整个数据集的数据帧和数组进行操作,并在内部执行必要的语义映射和统计聚合以生成信息图。其面向数据集的声明性 API 可让您专注于绘图的不同元素的含义,而不是如何绘制它们的细节。
5.1.1. 特点:¶
丰富的可视化函数: Seaborn拥有一系列丰富的可视化函数,能够创建多种类型的图表,包括折线图、柱状图、散点图、核密度图、热力图等等。
简洁的API: Seaborn的API设计简洁,代码易读易写,让用户能够轻松地创建高质量的可视化图表。
支持数据分组: Seaborn支持按照数据分组进行可视化,使得用户能够更好地分析数据的差异。
自动化调整: Seaborn能够自动调整图表的各种参数,包括颜色、标签、坐标轴等等,使得用户能够更专注于数据分析。
5.1.2. 功能:¶
计算多变量间关系的面向数据集接口
可视化类别变量的观测与统计
可视化单变量或多变量分布并与其子数据集比较
控制线性回归的不同因变量并进行参数估计与作图
对复杂数据进行易行的整体结构可视化
对多表统计图的制作高度抽象并简化可视化过程
提供多个内建主题渲染 matplotlib 的图像样式
提供调色板工具生动再现数据
以下是 seaborn 可以做什么的一个例子:
>>> # 导入 seaborn
>>> import seaborn as sns
>>>
>>> # 应用默认主题
>>> sns.set_theme()
>>>
>>> # 加载一个示例数据集
>>> # tips = sns.load_dataset("tips")
>>> tips = sns.load_dataset("tips",data_home='seaborn-data',cache=True)
>>>
>>> # 创建一个可视化
>>> sns.relplot(
>>> data=tips,
>>> x="total_bill", y="tip", col="time",
>>> hue="smoker", style="smoker", size="size",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7effa23c4bd0>
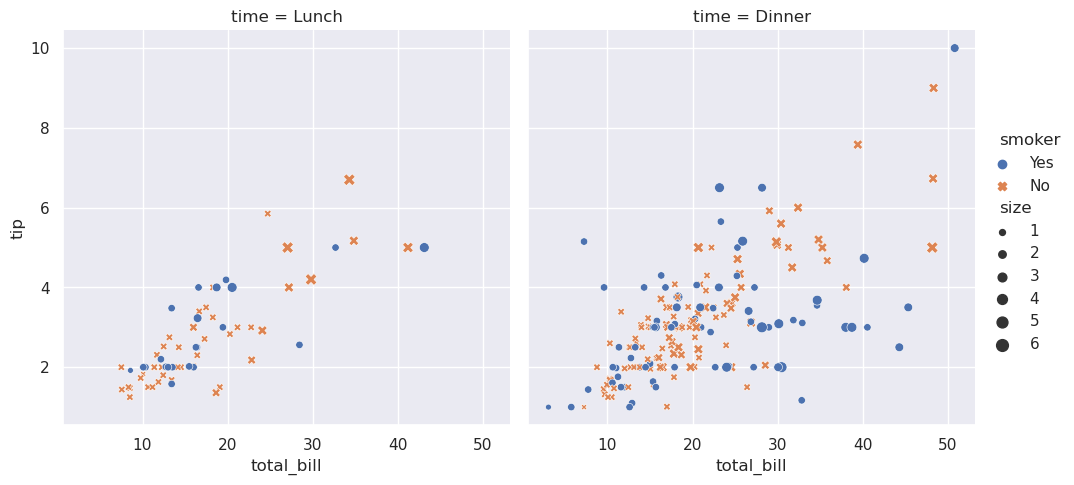
这里发生了一些事情。让我们一一介绍一下:
>>> # 导入 seaborn
>>> import seaborn as sns
Seaborn
是这个简单示例中唯一需要导入的库。按照惯例,它是用简写导入的sns。
在幕后,seaborn使用matplotlib来绘制它的情节。对于交互式工作,建议在matplotlib模式下使用Jupyter/IPython接口,否则当您想要查看绘图时,必须调用matplotlib.pyplot.show()。
>>> # 应用默认主题
>>> sns.set_theme()
这将使用matplotlib rcParam系统,并将影响所有matplotlib图的外观,即使您不使用seaborn制作它们。除了默认主题之外,还有其他几个选项,您可以独立控制情节的样式和缩放,以便在演示上下文之间快速翻译您的工作(例如,在演讲期间投影时制作具有可读字体的图形版本),示例请移步相关章节查看。如果您喜欢matplotlib默认值或喜欢不同的主题,您可以跳过这一步,仍然使用seaborn绘图函数。
>>> # 加载一个示例数据集
>>> # tips = sns.load_dataset("tips")
文档中的大多数代码将使用load_dataset()函数来快速访问示例数据集。这些数据集没有什么特别之处:它们只是pandas数据帧,我们可以用pandas.read_csv()加载它们,也可以手工构建它们。文档中的大多数示例将使用pandas数据框架指定数据,但是seaborn对它接受的数据结构非常灵活。
但是在国内在用seaborn进行画图时,有时想引用其自带的数据,往往会遇到如下错误:
URLError: <urlopen error [Errno 61] Connection refused>
这不用说是因为无法访问外网的原因,那么看load_datasett方法我们可以发现,有以下的注释:
>>> def load_dataset(name, cache=True, data_home=None, **kws):
>>> """Load a dataset from the online repository (requires internet).
>>>
>>> Parameters
>>> ----------
>>> name : str
>>> Name of the dataset (`name`.csv on
>>> https://github.com/mwaskom/seaborn-data). You can obtain list of
>>> available datasets using :func:`get_dataset_names`
>>> cache : boolean, optional
>>> If True, then cache data locally and use the cache on subsequent calls
>>> data_home : string, optional
>>> The directory in which to cache data. By default, uses ~/seaborn-data/
>>> kws : dict, optional
>>> Passed to pandas.read_csv
>>>
>>> """
从这里可以发现,这个数据集其实可以在github上下载,网址如下: https://github.com/mwaskom/seaborn-data
其实load_dataset预留了通过本地来加载数据的接口,只需要提前将数据下载下来,然后从本地加载就好了。
load_dataset包含有三个参数:
name: str,代表数据集名字;
cache: boolean,当为True时,从本地加载数据,反之则从网上下载;
data_home: string,代表本地数据的路径
可见只要设置好数据路径,然后再把cache设为True即可从本地加载数据了,如下所示:
>>> tips = sns.load_dataset("tips",data_home='seaborn-data',cache=True)
>>> # 创建一个可视化
>>> sns.relplot(
>>> data=tips,
>>> x="total_bill", y="tip", col="time",
>>> hue="smoker", style="smoker", size="size",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7eff99e97190>
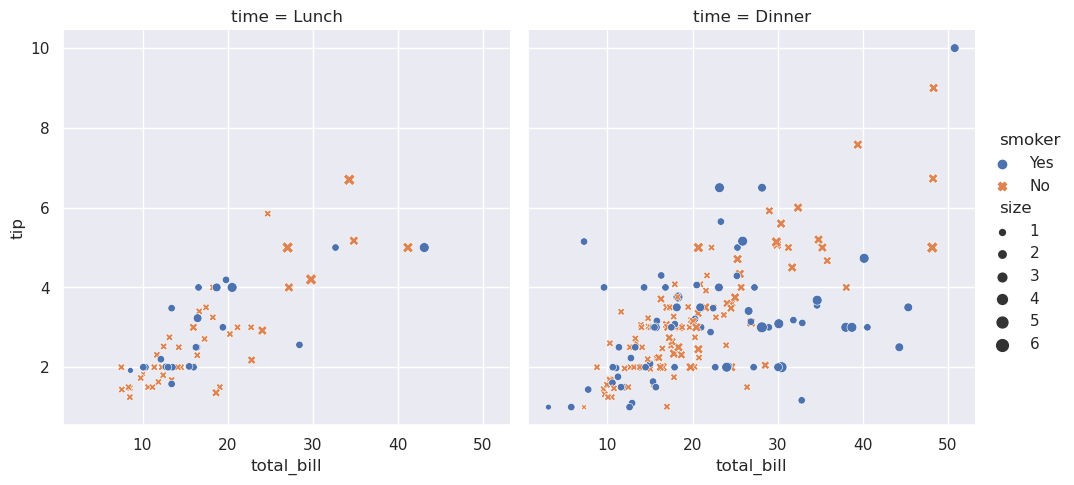
该图通过调用seaborn函数relplot()显示了tips数据集中五个变量之间的关系。请注意,我们只提供了变量的名称及其在图中的角色。与直接使用matplotlib不同,它不需要根据颜色值或标记代码来指定绘图元素的属性。在幕后,seaborn处理从数据框架中的值到matplotlib可以理解的参数的转换。这种声明性方法使您可以将注意力集中在想要回答的问题上,而不是放在如何控制matplotlib的细节上。
用于统计图形的高级API¶
没有普遍适用的最佳数据可视化方法。不同的问题最好用不同的情节来回答。Seaborn通过使用一致的面向数据集的API,可以轻松地在不同的视觉表示之间切换。
函数relplot()之所以这样命名,是因为它被设计用于可视化许多不同的统计关系。虽然散点图通常是有效的,但一个变量代表时间度量的关系最好用一条线来表示。relplot()函数有一个方便的kind参数,可以让你轻松切换到这种替代表示:
>>> dots = sns.load_dataset("dots",data_home='seaborn-data',cache=True)
>>> sns.relplot(
>>> data=dots, kind="line",
>>> x="time", y="firing_rate", col="align",
>>> hue="choice", size="coherence", style="choice",
>>> facet_kws=dict(sharex=False),
>>> )
<seaborn.axisgrid.FacetGrid at 0x7eff99e45b90>
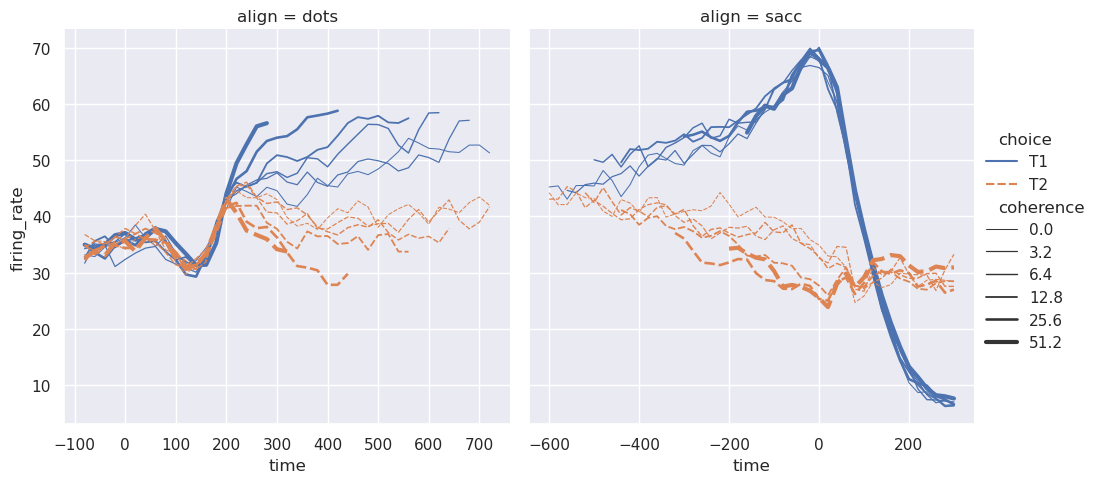
请注意size和style参数是如何在散点图和线形图中使用的,但它们对两种可视化效果的影响是不同的:改变散点图中的标记区域和符号,而改变线形图中的线宽和样式。我们不需要记住这些细节,让我们专注于情节的整体结构和我们想要传达的信息。
统计估计¶
通常,我们感兴趣的是一个变量的平均值作为其他变量的函数。许多 seaborn 函数将自动执行统计估计,这是回答这些问题所必需的:
>>> fmri = sns.load_dataset("fmri",data_home='seaborn-data',cache=True)
>>>
>>> sns.relplot(
>>> data=fmri, kind="line",
>>> x="timepoint", y="signal", col="region",
>>> hue="event", style="event",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7eff99de5c10>
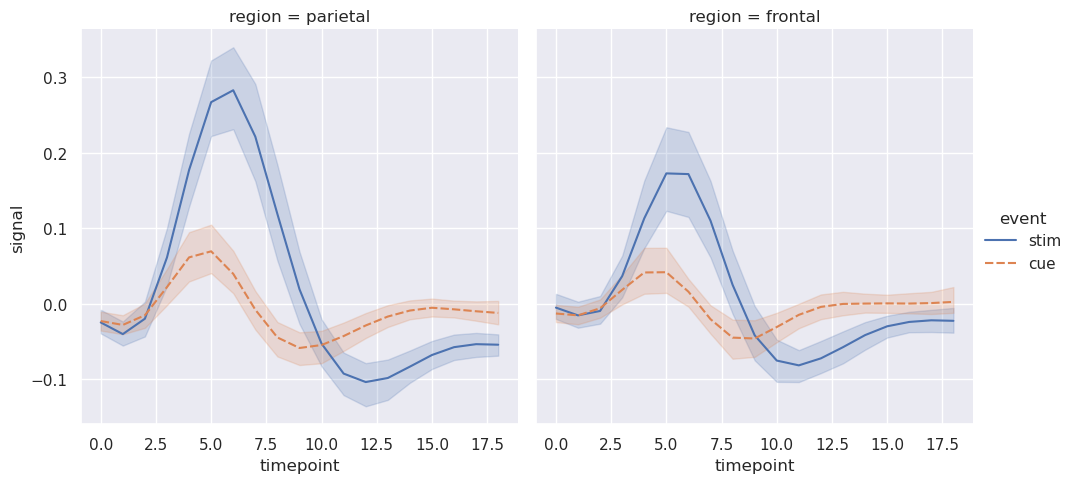
当估计统计值时,seaborn将使用自举计算置信区间并绘制表示估计不确定性的误差线。
seaborn
的统计估计超出了描述性统计。例如,可以通过使用lmplot()包含线性回归模型(及其不确定性)来增强散点图:
>>> sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker")
<seaborn.axisgrid.FacetGrid at 0x7eff99f07690>
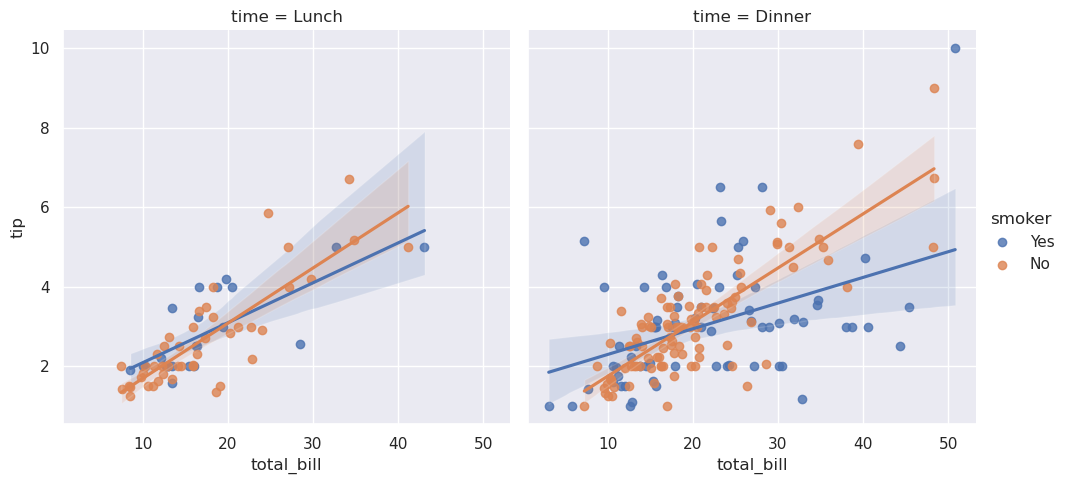
分布表示¶
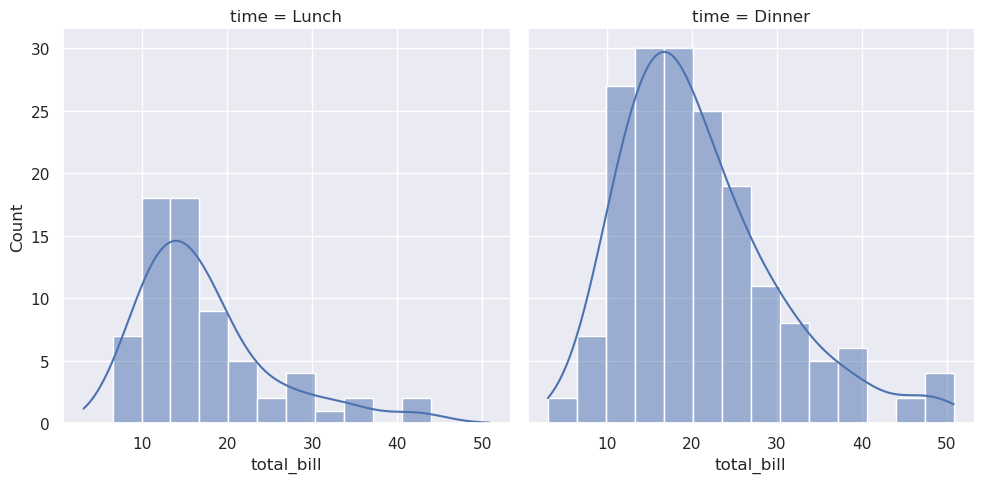
统计分析需要了解数据集中变量的分布。函数displot()支持几种可视化分布的方法。其中包括直方图等经典技术和核密度估计等计算密集型方法:
>>> sns.displot(data=tips, x="total_bill", col="time", kde=True)
<seaborn.axisgrid.FacetGrid at 0x7eff93e862d0>
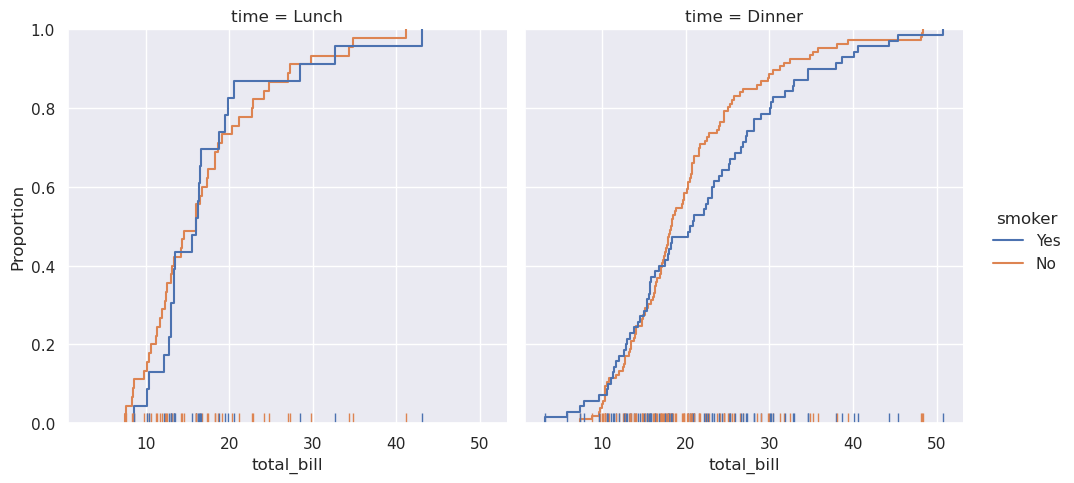
Seaborn还试图推广一些功能强大但不太熟悉的技术,比如计算和绘制数据的经验累积分布函数:
>>> sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True)
<seaborn.axisgrid.FacetGrid at 0x7eff93ee1ed0>
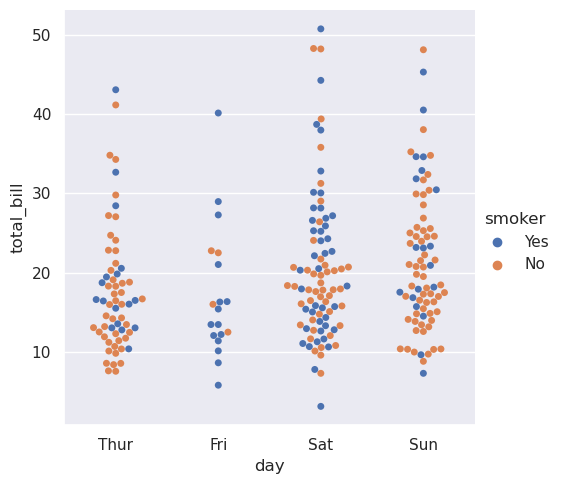
分类数据图¶
seaborn
中的几种专用绘图类型面向可视化分类数据。可以通过catplot()访问它们。这些图提供了不同的粒度级别。在最好的水平上,你可能希望通过绘制“群”图来查看每个观察结果:散点图,调整点沿着分类轴的位置,这样它们就不会重叠。
>>> sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")
<seaborn.axisgrid.FacetGrid at 0x7eff93c6df50>
或者,你可以使用核密度估计来表示采样点的底层分布:
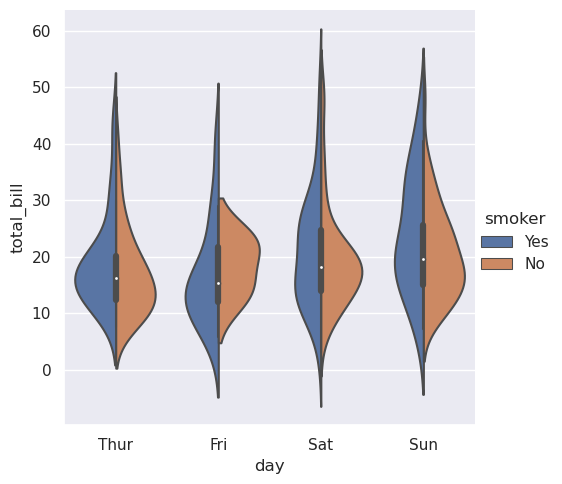
>>> sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True)
<seaborn.axisgrid.FacetGrid at 0x7eff93ce1ed0>
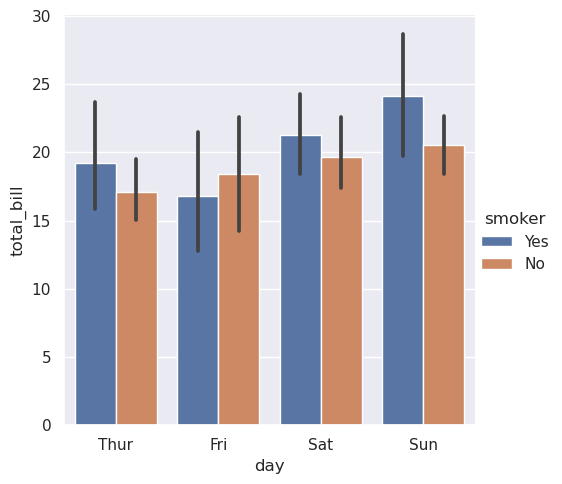
或者您可以只显示每个嵌套类别中的平均值及其置信区间:
>>> sns.catplot(data=tips, kind="bar", x="day", y="total_bill", hue="smoker")
<seaborn.axisgrid.FacetGrid at 0x7eff93c4d3d0>
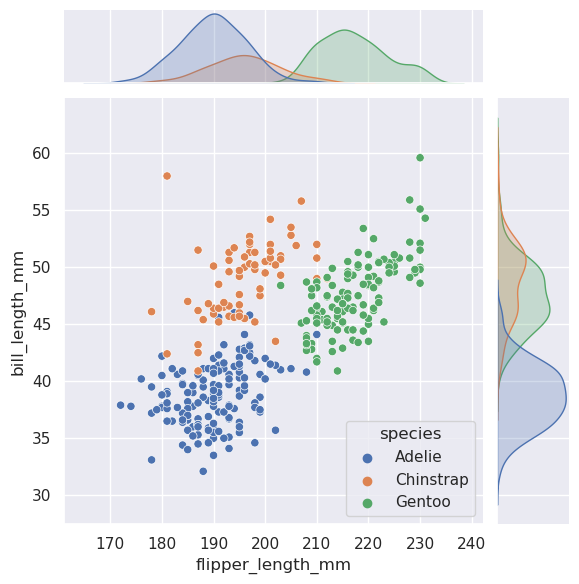
复杂数据集的多变量视图¶
一些 seaborn
函数结合了多种图,以快速提供数据集的信息摘要。jointplot()侧重于单个关系。它绘制了两个变量之间的联合分布以及每个变量的边际分布:
>>> penguins = sns.load_dataset("penguins")
>>> sns.jointplot(data=penguins, x="flipper_length_mm", y="bill_length_mm", hue="species")
<seaborn.axisgrid.JointGrid at 0x7eff93a7bb50>
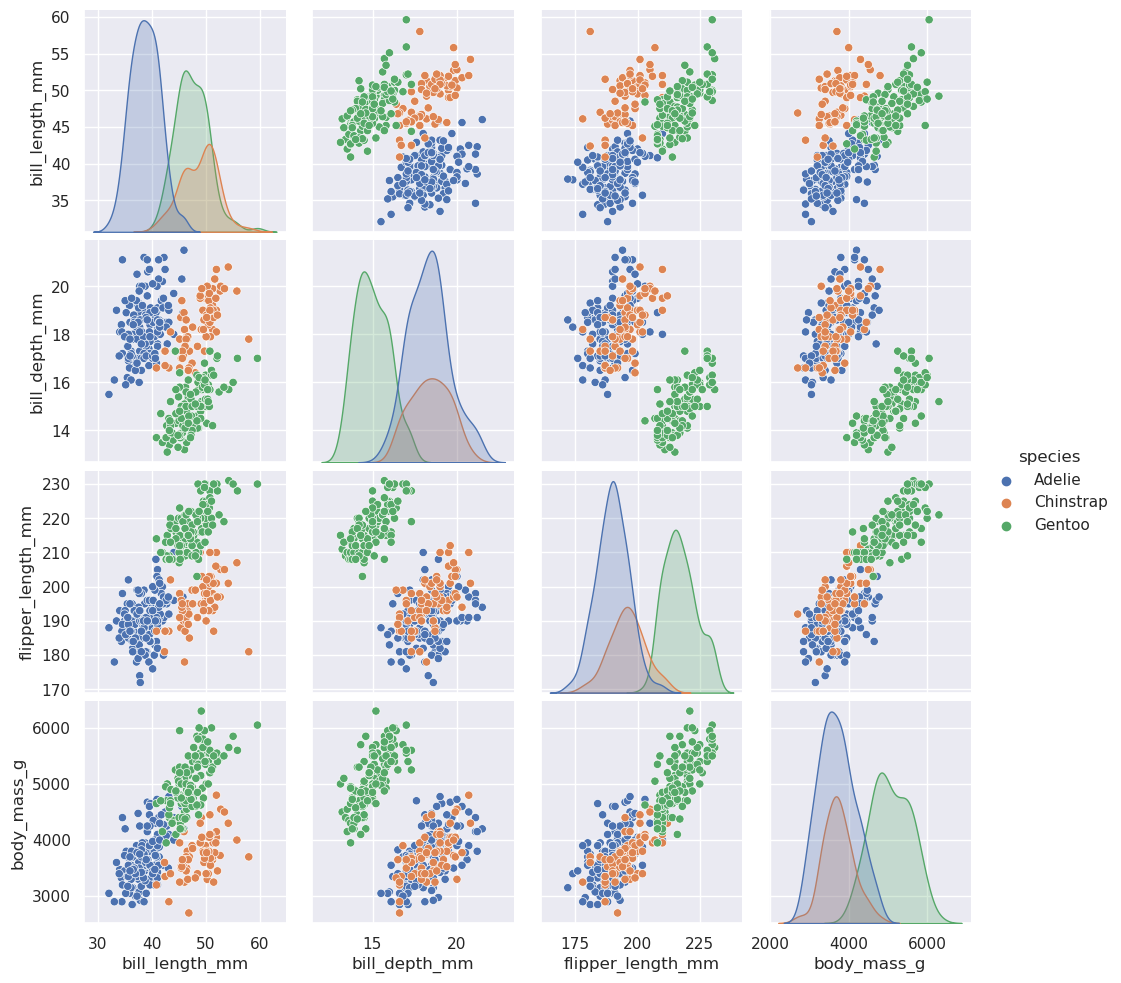
另一个,pairplot(),采用了更广泛的观点:它分别显示了所有成对关系和每个变量的联合分布和边际分布:
>>> sns.pairplot(data=penguins, hue="species")
<seaborn.axisgrid.PairGrid at 0x7eff93919450>
用于构建图形的低级工具¶
这些工具通过将轴级绘图功能与管理图形布局的对象相结合来工作,将数据集的结构链接到轴网格。这两个元素都是公共API的一部分,你可以直接使用它们来创建复杂的图形,只需要几行代码:
>>> g = sns.PairGrid(penguins, hue="species", corner=True)
>>> g.map_lower(sns.kdeplot, hue=None, levels=5, color=".2")
>>> g.map_lower(sns.scatterplot, marker="+")
>>> g.map_diag(sns.histplot, element="step", linewidth=0, kde=True)
>>> g.add_legend(frameon=True)
>>> g.legend.set_bbox_to_anchor((.61, .6))
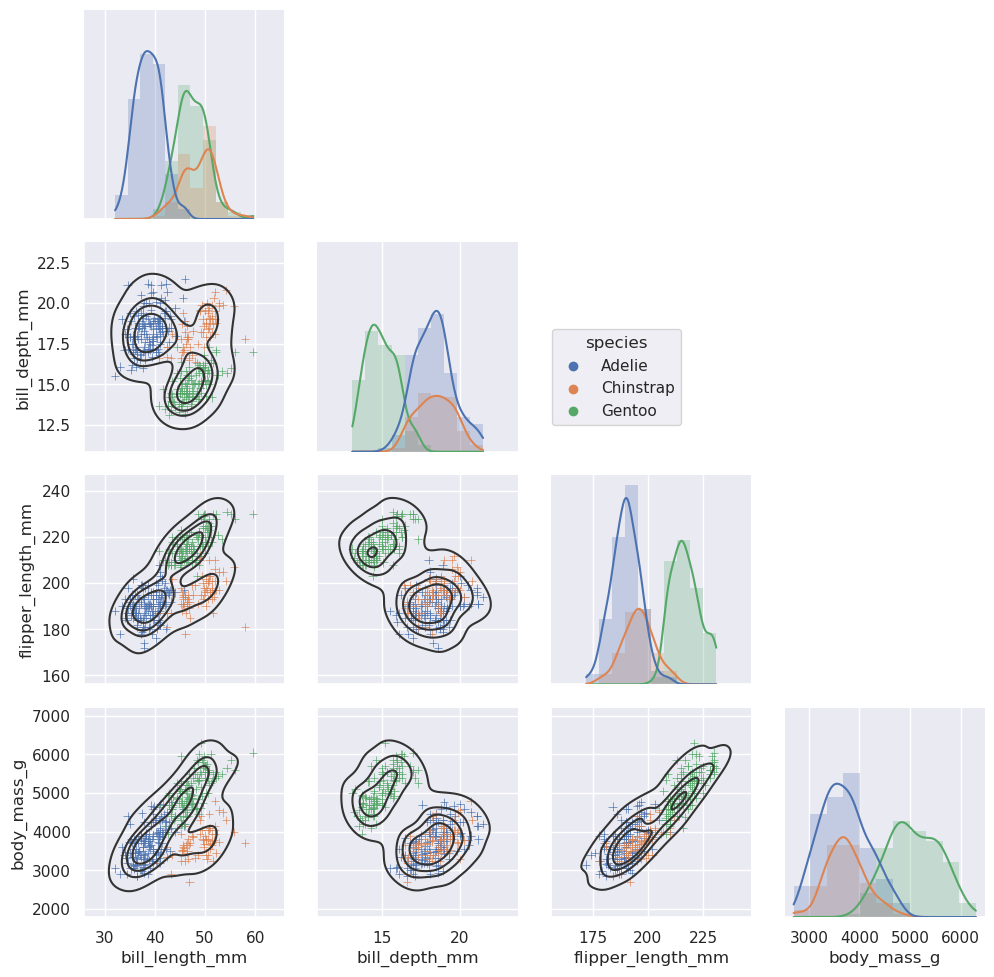
固执的默认值和灵活的自定义¶
Seaborn通过单个函数调用创建完整的图形:在可能的情况下,它的函数将自动添加信息轴标签和图例,以解释绘图中的语义映射。
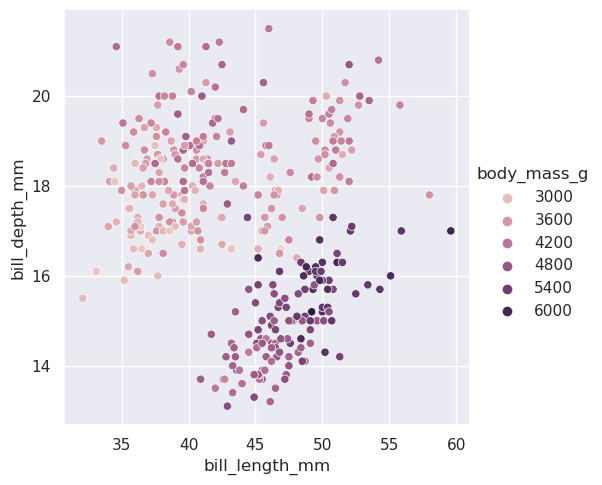
在许多情况下,seaborn还将根据数据的特征为其参数选择默认值。例如,到目前为止我们看到的颜色映射使用不同的色调(蓝色、橙色,有时还有绿色)来表示分配给色调的分类变量的不同级别。当映射一个数值变量时,一些函数会切换到连续梯度:
>>> sns.relplot(
>>> data=penguins,
>>> x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g"
>>> )
<seaborn.axisgrid.FacetGrid at 0x7eff922c3750>
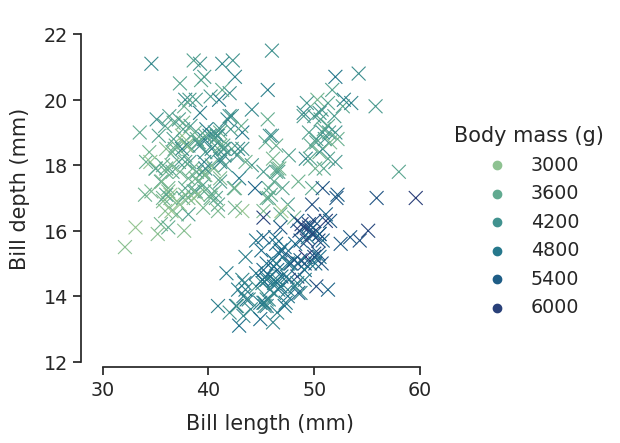
当你准备好分享或发布你的作品时,你可能会想要在默认值的基础上对图形进行润色。Seaborn允许几个级别的定制。它定义了多个适用于所有图形的内置主题,其函数具有标准化参数,可以修改每个绘图的语义映射,并且将其他关键字参数传递给底层matplotlib艺术家,从而允许更多的控制。一旦你创建了一个图,它的属性可以通过seaborn API修改,也可以通过下拉到matplotlib层进行细粒度的调整:
>>> sns.set_theme(style="ticks", font_scale=1.25)
>>> g = sns.relplot(
>>> data=penguins,
>>> x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g",
>>> palette="crest", marker="x", s=100,
>>> )
>>> g.set_axis_labels("Bill length (mm)", "Bill depth (mm)", labelpad=10)
>>> g.legend.set_title("Body mass (g)")
>>> g.figure.set_size_inches(6.5, 4.5)
>>> g.ax.margins(.15)
>>> g.despine(trim=True)
<seaborn.axisgrid.FacetGrid at 0x7eff922f8dd0>
与matplotlib的关系¶
Seaborn与matplotlib的集成允许您在matplotlib支持的许多环境中使用它,包括笔记本中的探索性分析,GUI应用程序中的实时交互,以及许多光栅和矢量格式的存档输出。
虽然您可以只使用生成的函数,但完全定制图形将需要了解matplotlib的概念和API。对于seaborn的新用户来说,学习曲线的一个方面是知道什么时候下拉到matplotlib层是实现特定定制所必需的。另一方面,来自matplotlib的用户会发现他们的大部分知识转移了。
Matplotlib有一个全面而强大的API;人物的任何属性都可以根据自己的喜好来改变。seaborn的高级界面和matplotlib的深度可定制性的结合将允许您快速探索您的数据并创建可定制为出版物质量最终产品的图形。
下一个步骤¶
你有几个选择下一步去哪里。您可能首先要学习如何安装seaborn。完成后,您可以浏览示例库,以更广泛地了解seaborn可以生成哪种图形。或者,您可以通读用户指南和教程的其余部分,以更深入地讨论不同的工具及其设计目的。如果您心中有一个特定的图,并且想知道如何制作它,您可以查看API参考,其中记录了每个函数的参数,并显示了许多示例来说明用法。