>>> from env_helper import info; info()
页面更新时间: 2024-01-06 20:43:45
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-16-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
5.3. seaborn 接受的数据结构¶
作为一个数据可视化库,seaborn
需要您为其提供数据。本章介绍完成该任务的各种方法。 Seaborn
支持多种不同的数据集格式,大多数函数接受用 pandas 或 numpy
库中的对象表示的数据, 以及内置的 Python 类型,如列表和字典。
了解与这些不同选项关联的使用模式将有助于您快速为几乎任何数据集创建有用的可视化效果。
注意
在撰写本文时(v0.13.0),seaborn
中的大多数(但不是全部)函数都支持此处涵盖的全部选项。
也就是说,一些较旧的函数(例如,lmplot()和regplot()
)在接受的内容上受到更多限制。
5.3.1. 长格式数据与宽格式数据¶
seaborn 中的大多数绘图函数都面向数据向量。作图时,每个变量都应该是一个向量。 Seaborn 接受以某种表格方式组织多个向量的数据集。“长格式”和“宽格式”数据表之间存在根本区别,seaborn 将以不同的方式对待它们。
长格式数据¶
长格式数据表具有以下特征:
每个变量都是一列
每个观测值都是一行
举个简单的例子,考虑“航班”数据集,该数据集记录了 1949 年至 1960 年间每月飞行的航空公司乘客数量。此数据集有三个变量(年、月和乘客人数):
>>> import seaborn as sns
>>> sns.set_theme()
>>>
>>> flights = sns.load_dataset("flights",data_home='seaborn-data',cache=True)
>>> flights.head()
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
| 2 | 1949 | Mar | 132 |
| 3 | 1949 | Apr | 129 |
| 4 | 1949 | May | 121 |
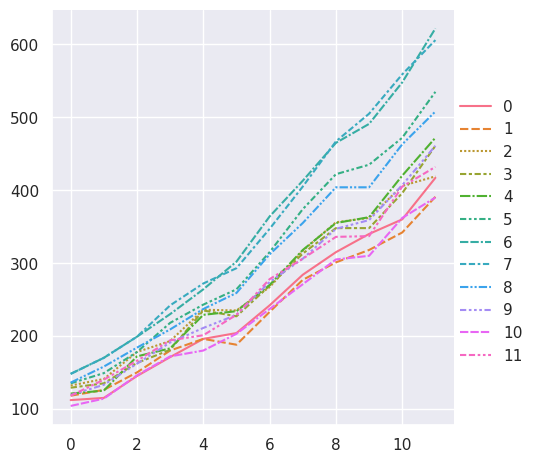
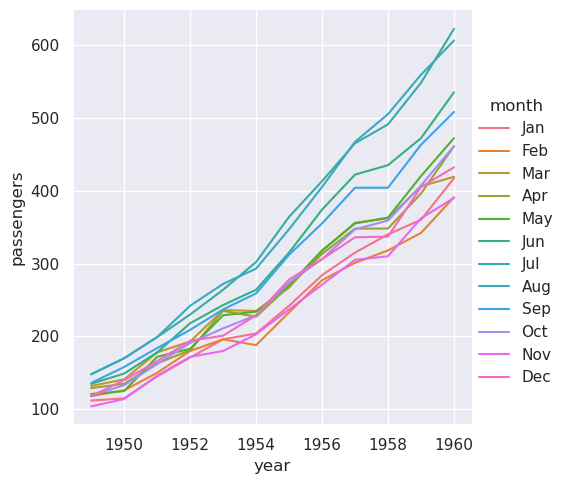
对于长格式数据,表中的列通过显式分配给其中一个变量,在图中赋予它们角色。例如,制作每年乘客人数的月度图如下所示:
>>> sns.relplot(data=flights, x="year", y="passengers", hue="month", kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bce538590>
长格式数据的优点是它非常适合于绘图的这种显式规范。它可以容纳任意复杂度的数据集,只要变量和观测值可以明确定义。但这种格式需要一些时间来适应,因为它通常不是人们脑海中的数据模型。
宽格式数据¶
对于简单的数据集,通常更直观地考虑数据的方式,就像在电子表格中查看数据一样,其中列和行包含不同变量的级别。例如,我们可以通过“透视”航班数据集将它转换为宽格式组织,以便每列都有多年来每个月的时间序列:
>>> flights_wide = flights.pivot(index="year", columns="month", values="passengers")
>>> flights_wide.head()
| month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| year | ||||||||||||
| 1949 | 112 | 118 | 132 | 129 | 121 | 135 | 148 | 148 | 136 | 119 | 104 | 118 |
| 1950 | 115 | 126 | 141 | 135 | 125 | 149 | 170 | 170 | 158 | 133 | 114 | 140 |
| 1951 | 145 | 150 | 178 | 163 | 172 | 178 | 199 | 199 | 184 | 162 | 146 | 166 |
| 1952 | 171 | 180 | 193 | 181 | 183 | 218 | 230 | 242 | 209 | 191 | 172 | 194 |
| 1953 | 196 | 196 | 236 | 235 | 229 | 243 | 264 | 272 | 237 | 211 | 180 | 201 |
在这里,我们有相同的三个变量,但它们的组织方式不同。此数据集中的变量链接到表的维度,而不是命名字段。每个观测值都由表中单元格的值以及该单元格相对于行和列索引的坐标定义。
对于长格式数据,我们可以按变量名称访问数据集中的变量。宽格式数据并非如此。然而,由于表的维度与数据集中的变量之间存在明显的关联,因此 seaborn 能够在图中分配这些变量的角色。
注意
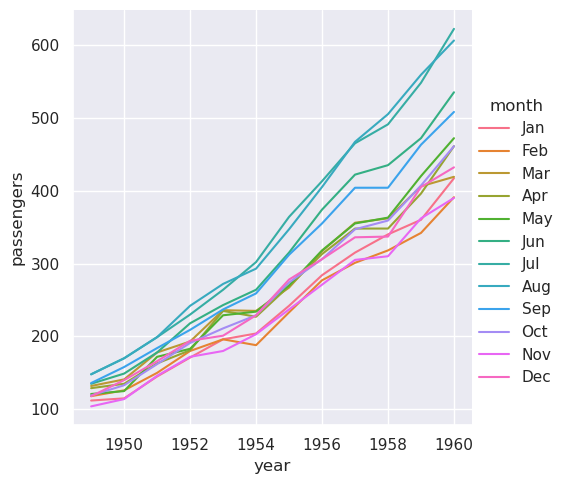
Seaborn将未赋值x和y的data参数视为宽格式。
>>> sns.relplot(data=flights_wide, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc6114250>
这张图看起来和之前的很像。Seaborn将数据框的索引赋值为x,将数据框的值赋值为y,并为每个月分别绘制了一条线。然而,这两幅图有一个显著的区别。当数据集经过从长格式转换为宽格式的“枢轴”操作时,关于这些值的含义的信息丢失了。因此,没有y轴标签。(这些行在这里也有破折号,因为relplot()将列变量映射到
hue 和
style语义,以便更容易访问该图。在长格式的情况下,我们没有这样做,但我们可以通过设置style="month"来实现。
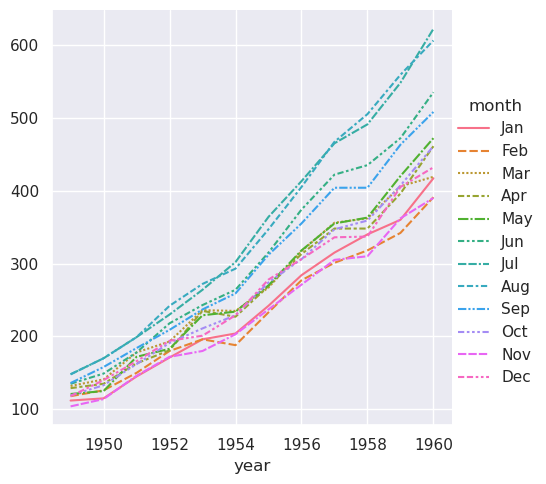
到目前为止,我们在使用宽幅数据时所做的打字要少得多,并且制作了几乎相同的绘图。这似乎更容易!但长格式数据的一大优势是,一旦你拥有了正确格式的数据,你就不再需要考虑它的结构。您可以通过仅考虑其中包含的变量来设计绘图。例如,要绘制表示每年每月时间序列的线条,只需重新分配变量即可:
>>> sns.relplot(data=flights, x="month", y="passengers", hue="year", kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc5ffd1d0>
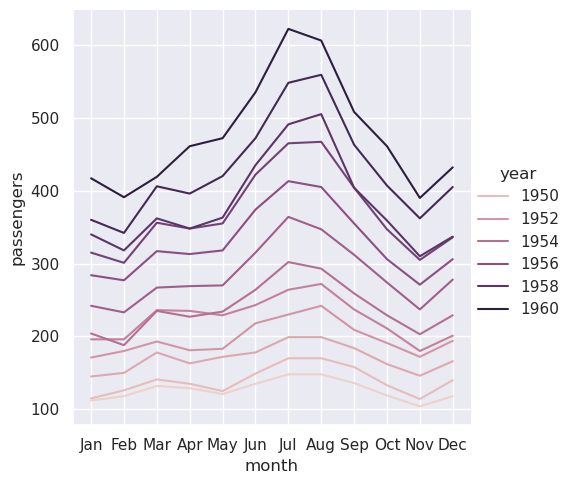
为了实现与宽格式数据集相同的重映射,我们需要转置表:
>>> sns.relplot(data=flights_wide.transpose(), kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc6086c50>
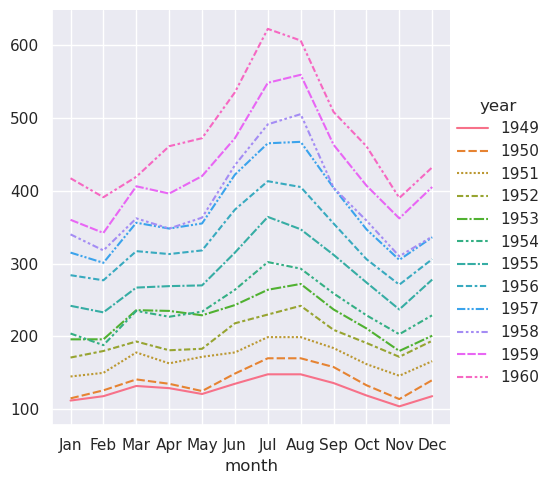
(此示例还说明了另一个问题,即 seaborn 当前认为宽格式数据集中的列变量是分类的,而不管其数据类型如何,而由于长格式变量是数值,因此它被分配了定量调色板和图例。这在未来可能会改变)。
没有显式变量赋值还意味着每种绘图类型都需要在宽格式数据的维度和绘图中的角色之间定义固定映射。由于这种自然映射可能因绘图类型而异,因此在使用宽格式数据时,结果的可预测性较差。例如,分类图将表的列维度分配给x,然后跨行聚合(忽略索引):
>>> sns.catplot(data=flights_wide, kind="box")
<seaborn.axisgrid.FacetGrid at 0x7f8bc44ab3d0>
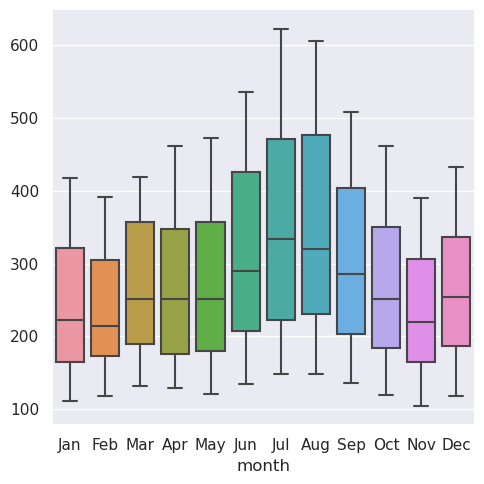
当使用pandas表示宽格式数据时,您只能使用几个变量(不超过三个)。这是因为seaborn不使用多索引信息,而这正是pandas以表格格式表示附加变量的方式。xarray项目提供了带标签的n维数组对象,可以将其视为广义数据向高维的泛化。目前,seaborn不直接支持来自xarray的对象,但可以将它们转换为长格式的pandas.DataFrame使用to_pandas方法,然后像任何其他长格式数据集一样在seaborn中绘制。
总而言之,我们可以将长格式和宽格式数据集视为如下所示:
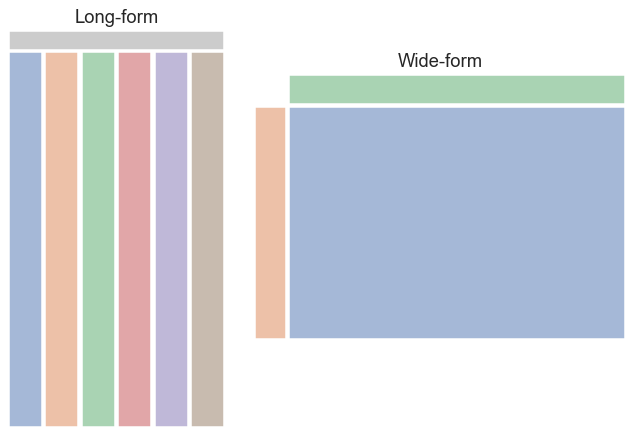
杂乱的数据¶
许多数据集无法使用长格式或宽格式规则进行清晰解释。如果明显是长格式或宽格式的数据集是“整洁的”,我们可能会说这些更模糊的数据集是“凌乱的”。在杂乱无章的数据集中,变量既不是由键唯一定义的,也不是由表的维度唯一定义的。这通常发生在重复测量数据中,其中很自然地组织一个表,使每一行对应于数据收集的单位。考虑一下这个来自心理学实验的简单数据集,其中 20 名受试者执行了一项记忆任务,他们在注意力分散或集中的情况下研究字谜:
>>> anagrams = sns.load_dataset("anagrams")
>>> anagrams
| subidr | attnr | num1 | num2 | num3 | |
|---|---|---|---|---|---|
| 0 | 1 | divided | 2 | 4.0 | 7 |
| 1 | 2 | divided | 3 | 4.0 | 5 |
| 2 | 3 | divided | 3 | 5.0 | 6 |
| 3 | 4 | divided | 5 | 7.0 | 5 |
| 4 | 5 | divided | 4 | 5.0 | 8 |
| 5 | 6 | divided | 5 | 5.0 | 6 |
| 6 | 7 | divided | 5 | 4.5 | 6 |
| 7 | 8 | divided | 5 | 7.0 | 8 |
| 8 | 9 | divided | 2 | 3.0 | 7 |
| 9 | 10 | divided | 6 | 5.0 | 6 |
| 10 | 11 | focused | 6 | 5.0 | 6 |
| 11 | 12 | focused | 8 | 9.0 | 8 |
| 12 | 13 | focused | 6 | 5.0 | 9 |
| 13 | 14 | focused | 8 | 8.0 | 7 |
| 14 | 15 | focused | 8 | 8.0 | 7 |
| 15 | 16 | focused | 6 | 8.0 | 7 |
| 16 | 17 | focused | 7 | 7.0 | 6 |
| 17 | 18 | focused | 7 | 8.0 | 6 |
| 18 | 19 | focused | 5 | 6.0 | 6 |
| 19 | 20 | focused | 6 | 6.0 | 5 |
注意力变量是受试者之间的,但也有一个受试者内部变量:字谜的可能解的数量,从 1 到 3 不等。相关度量是内存性能的分数。这两个变量(数字和分数)在多个列中联合编码。因此,整个数据集既不明显是长格式,也不是明显的宽格式。
我们如何告诉 seaborn
将平均分数绘制为注意力和解决方案数量的函数?我们首先需要将数据强制转换为我们的两个结构之一。让我们将其转换为一个整洁的长格式表,这样每个变量都是一列,每行都是一个观测值。我们可以使用pandas.DataFrame.melt()方法来完成此任务:
>>> anagrams_long = anagrams.melt(id_vars=["subidr", "attnr"], var_name="solutions", value_name="score")
>>> anagrams_long.head()
| subidr | attnr | solutions | score | |
|---|---|---|---|---|
| 0 | 1 | divided | num1 | 2.0 |
| 1 | 2 | divided | num1 | 3.0 |
| 2 | 3 | divided | num1 | 3.0 |
| 3 | 4 | divided | num1 | 5.0 |
| 4 | 5 | divided | num1 | 4.0 |
现在我们可以制作我们想要的情节:
>>> sns.catplot(data=anagrams_long, x="solutions", y="score", hue="attnr", kind="point")
<seaborn.axisgrid.FacetGrid at 0x7f8bc427d250>
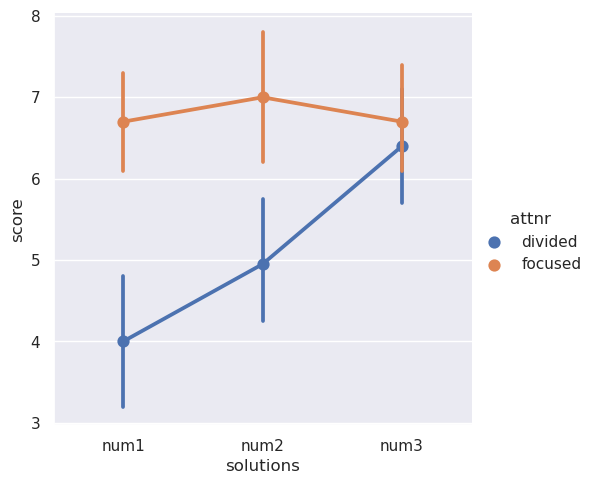
进一步阅读和带回家的要点¶
有关表格数据结构的更详细讨论,您可以阅读 Hadley Whickham 的“Tidy Data”论文。请注意,seaborn 使用的概念集与本文中定义的概念略有不同。虽然本文将整洁与长格式结构联系起来,但我们已经区分了“整洁的宽格式”数据和“杂乱的数据”,前者在数据集中的变量和表的维度之间存在明确的映射,后者不存在这种映射。
长格式结构具有明显的优势。它允许您通过将数据集中的变量显式分配给绘图中的角色来创建图形,并且您可以使用三个以上的变量来执行此操作。如果可能,在开始认真分析时,请尝试使用长格式结构来表示数据。seaborn 文档中的大多数示例都将使用长格式数据。但是,在保持数据集较宽更自然的情况下,请记住,seaborn 可以保持有用。
5.3.2. 用于可视化长格式数据的选项¶
虽然长格式数据具有精确的定义,但 seaborn
在内存中数据结构的实际组织方式方面相当灵活。文档其余部分的示例通常会使用pandas.DataFrame对象和引用变量,方法是将其列的名称分配给图中的变量。但也可以将向量存储在
Python 字典或实现该接口的类中:
>>> flights_dict = flights.to_dict()
>>> sns.relplot(data=flights_dict, x="year", y="passengers", hue="month", kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc434da50>
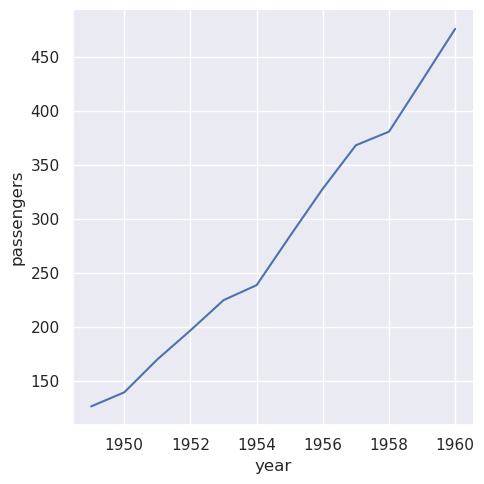
许多 pandas 操作(例如 group-by 的 split-apply-combine 操作)将生成一个 DataFrame,其中信息已从输入 DataFrame 的列移动到输出的索引。只要保留名称,您仍然可以正常引用数据:
>>> flights_avg = flights.groupby("year").mean(numeric_only=True)
>>> sns.relplot(data=flights_avg, x="year", y="passengers", kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc408e6d0>
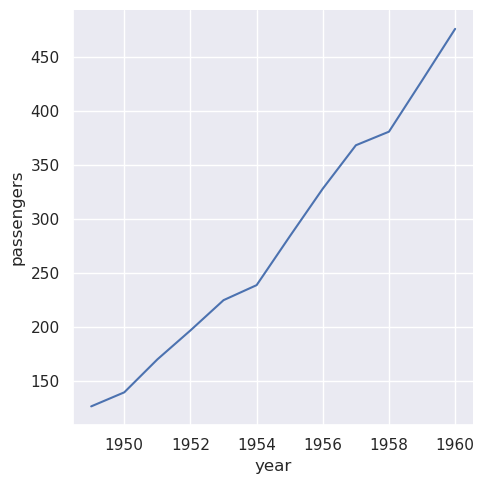
此外,还可以将数据向量作为参数直接传递给x、y
和其他绘图变量。如果这些向量是 pandas
对象,则name属性将用于标记绘图:
>>> year = flights_avg.index
>>> passengers = flights_avg["passengers"]
>>> sns.relplot(x=year, y=passengers, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc4191990>
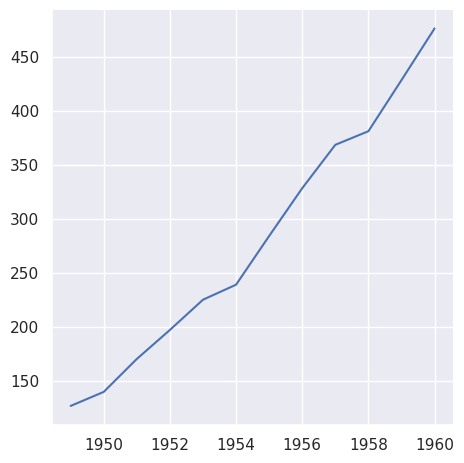
Numpy 数组和其他实现 Python 序列接口的对象也可以工作,但如果它们没有名称,如果不进一步调整,绘图将不会提供信息:
>>> sns.relplot(x=year.to_numpy(), y=passengers.to_list(), kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc41bf3d0>
5.3.3. 用于可视化宽格式数据的选项¶
传递宽格式数据的选项更加灵活。与长格式数据一样,pandas
对象更可取,因为可以使用名称(在某些情况下,还可以使用索引)信息。但从本质上讲,任何可以被视为单个向量或向量集合的格式都可以传递给data,并且通常可以构造一个有效的图。
我们上面看到的例子使用了一个矩形pandas.DataFrame,可以将其视为其列的集合。pandas
对象的 dict 或列表也可以工作,但我们将丢失轴标签:
>>> flights_wide_list = [col for _, col in flights_wide.items()]
>>> sns.relplot(data=flights_wide_list, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc41f2b50>
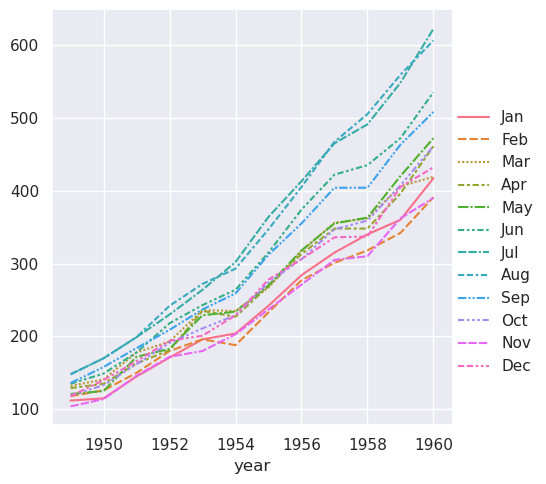
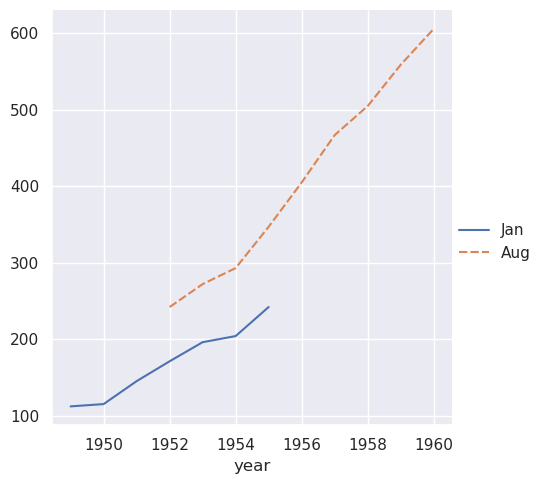
集合中的向量不需要具有相同的长度。如果它们有一个index
,它将用于对齐它们:
>>> two_series = [flights_wide.loc[:1955, "Jan"], flights_wide.loc[1952:, "Aug"]]
>>> sns.relplot(data=two_series, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bce2d8590>
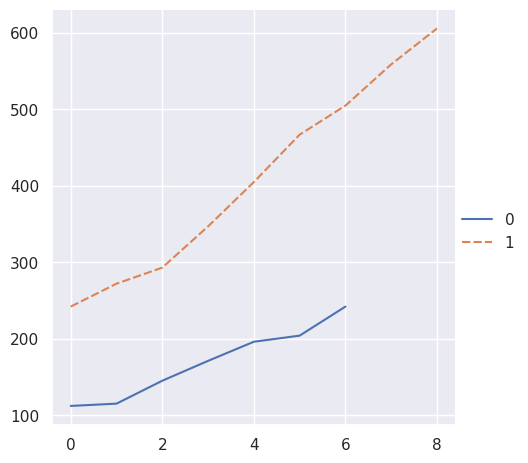
而序号索引将用于 numpy 数组或简单的 Python 序列:
>>> two_arrays = [s.to_numpy() for s in two_series]
>>> sns.relplot(data=two_arrays, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bc60a1750>
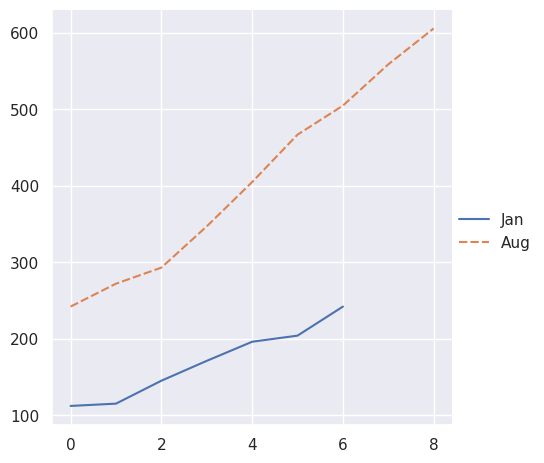
但是此类向量的字典至少会使用以下键:
>>> two_arrays_dict = {s.name: s.to_numpy() for s in two_series}
>>> sns.relplot(data=two_arrays_dict, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bbfd36d10>
矩形 numpy 数组被视为没有索引信息的数据帧,因此它们被视为列向量的集合。请注意,这与 numpy 索引操作的工作方式不同,在 numpy 索引操作中,单个索引器将访问一行。但这与 pandas 如何将数组转换为 DataFrame 或 matplotlib 如何绘制它是一致的:
>>> flights_array = flights_wide.to_numpy()
>>> sns.relplot(data=flights_array, kind="line")
<seaborn.axisgrid.FacetGrid at 0x7f8bbfd3c0d0>