>>> from env_helper import info; info()
页面更新时间: 2024-01-06 20:46:11
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-16-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
5.8. 可视化分类数据¶
在关系图教程中,我们了解了如何使用不同的视觉表示来显示数据集中多个变量之间的关系。在示例中,我们重点关注主要关系在两个数值变量之间的情况。如果其中一个主要变量是“分类”(分为离散组),则使用更专业的可视化方法可能会有所帮助。
在seaborn中,有几种不同的方法来可视化涉及分类数据的关系。与relplot()与scatterplot()或lineplot()之间的关系类似,有两种方法可以制作这些图。有许多用于以不同方式绘制分类数据的轴级函数,还有一个图形级接口catplot(),它提供了对它们的统一高层访问。
将不同的分类图类型视为属于三个不同的家族是很有帮助的,我们将在下面详细讨论。他们是:
分类散点图:
stripplot()(和默认值kind="strip")swarmplot()(和kind="swarm")
分类分布图:
boxplot()(和kind="box")violinplot()(和kind="violin")boxenplot()(和kind="boxen")
分类估计图:
pointplot()(和kind="point")barplot()(和kind="bar")countplot()(和kind="count")
这些族使用不同的粒度级别来表示数据。在决定使用哪个时,您必须考虑要回答的问题。统一的 API 使您可以在不同类型之间轻松切换,并从多个角度查看数据。
在本教程中,我们将主要关注图形级界面catplot()。请记住,这个函数是上面每个函数的高级接口,因此我们将在显示每种类型的图时引用它们,同时保留更详细的特定于类型的API文档。
5.8.1. 分类散点图¶
catplot()中数据的默认表示使用散点图。实际上在海产中有两种不同的分类散点图。他们采用不同的方法来解决用散点图表示分类数据的主要挑战,即属于一个类别的所有点将落在与分类变量对应的轴上的同一位置。stripplot()是catplot()中的默认“kind”,它使用的方法是通过少量随机“抖动”来调整分类轴上点的位置:
>>> import seaborn as sns
>>>
>>> sns.set_theme()
>>>
>>> tips = sns.load_dataset("tips")
>>> sns.catplot(data=tips, x="day", y="total_bill")
<seaborn.axisgrid.FacetGrid at 0x7f486b2faf50>
jitter参数控制抖动的大小或完全禁用它:
>>> sns.catplot(data=tips, x="day", y="total_bill", jitter=False)
<seaborn.axisgrid.FacetGrid at 0x7f0025570b50>
第二种方法是使用一种防止它们重叠的算法沿分类轴调整点。它可以更好地表示观测值的分布,尽管它只适用于相对较小的数据集。这种类型的图有时被称为“蜂群”,由swarmplot()在seaborn中绘制,通过在catplot()中设置kind=“swarm”来激活:
>>> sns.catplot(data=tips, x="day", y="total_bill", kind="swarm")
<seaborn.axisgrid.FacetGrid at 0x7f002558f150>
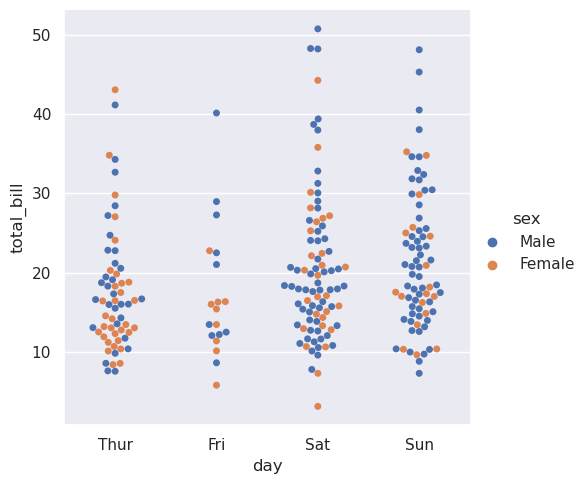
与关系图类似,可以通过使用hue语义向分类图添加另一个维度。(分类图目前不支持size或style语义)。每个不同的分类绘图函数处理hue语义的方式不同。对于散点图,只需要改变点的颜色:
>>> sns.catplot(data=tips, x="day", y="total_bill", hue="sex", kind="swarm")
<seaborn.axisgrid.FacetGrid at 0x7f00253c0490>
与数值数据不同的是,如何沿着分类变量的轴对其级别进行排序并不总是很明显的。一般来说,固有的分类绘图函数试图从数据中推断类别的顺序。如果数据具有pandas
Categorical数据类型,则可以在那里设置类别的默认顺序。如果传递给分类轴的变量看起来是数字,则将对级别进行排序。但是,默认情况下,数据仍然被视为分类,并在分类轴上的顺序位置绘制(具体来说,在0,1,…),即使使用数字来标记它们:
>>> sns.catplot(data=tips.query("size != 3"), x="size", y="total_bill")
<seaborn.axisgrid.FacetGrid at 0x7f00253b3910>
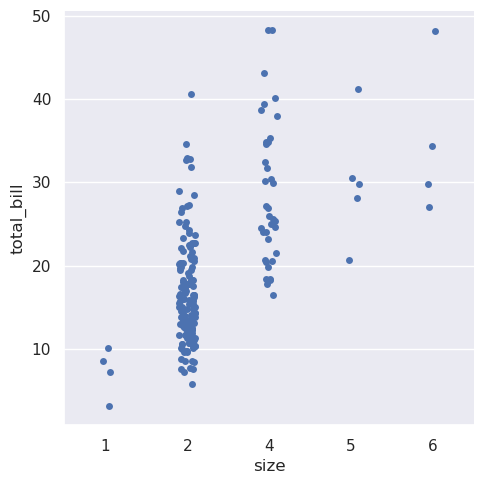
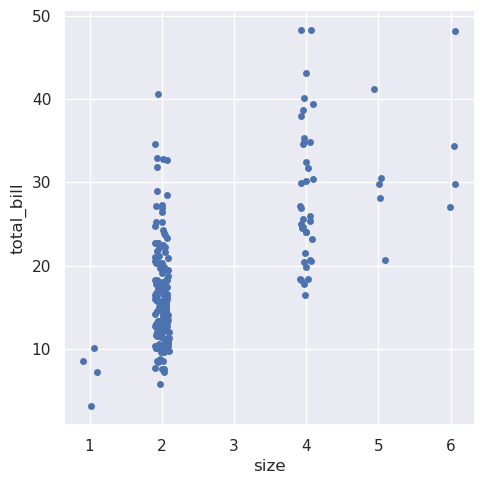
从v0.13.0开始,所有分类绘图函数都有一个native_scale参数,当你想在不改变底层数据属性的情况下使用数字或日期时间数据进行分类分组时,可以将其设置为True:
>>> sns.catplot(data=tips.query("size != 3"), x="size", y="total_bill", native_scale=True)
<seaborn.axisgrid.FacetGrid at 0x7f00252b4590>
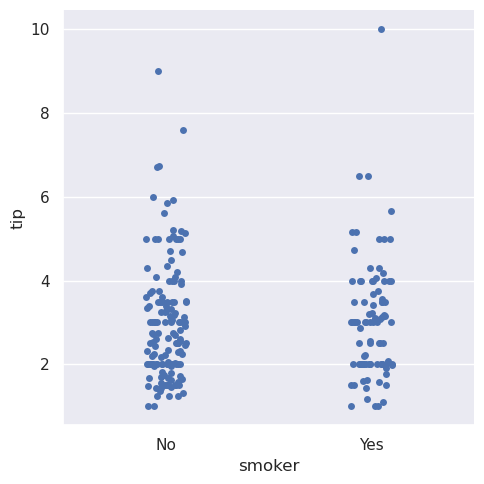
选择默认排序的另一种选择是在数据集中显示类别的级别。还可以使用order参数在特定于plot的基础上控制排序。当在同一张图中绘制多个分类图时,这一点很重要,我们将在下面看到更多:
>>> sns.catplot(data=tips, x="smoker", y="tip", order=["No", "Yes"])
<seaborn.axisgrid.FacetGrid at 0x7f0025337810>
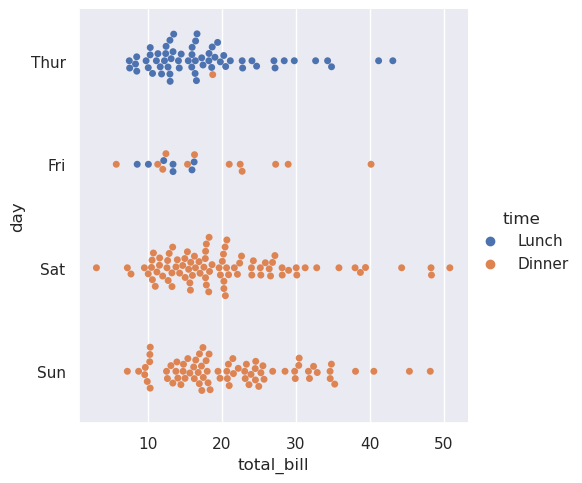
我们提到了“分类轴”的概念。在这些示例中,它始终与水平轴相对应。但是,将分类变量放在垂直轴上通常会有所帮助(尤其是当类别名称相对较长或类别较多时)。为此,请将变量的赋值交换到轴:
>>> sns.catplot(data=tips, x="total_bill", y="day", hue="time", kind="swarm")
<seaborn.axisgrid.FacetGrid at 0x7f002d844050>
5.8.2. 比较分布¶
随着数据集大小的增长,分类散点图可以提供的有关每个类别中值分布的信息将受到限制。发生这种情况时,有几种方法可以总结分布信息,以便于跨类别级别进行比较。
箱线图¶
首先是熟悉的boxplot()这种图显示了分布的三个四分位数值以及极值。“晶须”延伸到位于下四分位数和上四分位数
1.5 IQR
范围内的点,然后独立显示超出此范围的观测值。这意味着箱线图中的每个值都对应于数据中的实际观测值。
>>> sns.catplot(data=tips, x="day", y="total_bill", kind="box")
<seaborn.axisgrid.FacetGrid at 0x7f0025247450>
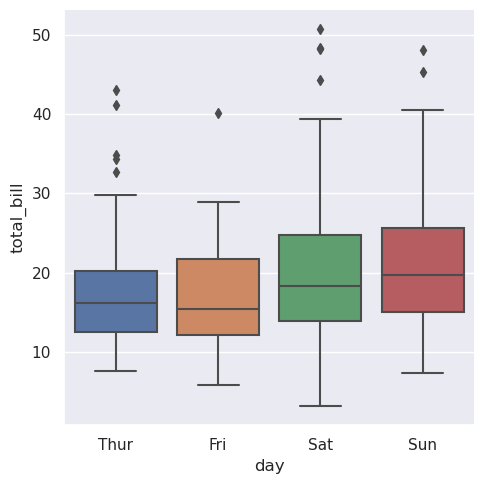
当添加hue语义时,每一级语义变量的方框变窄,并沿着分类轴移动:
>>> sns.catplot(data=tips, x="day", y="total_bill", hue="smoker", kind="box")
<seaborn.axisgrid.FacetGrid at 0x7f0024fc3410>
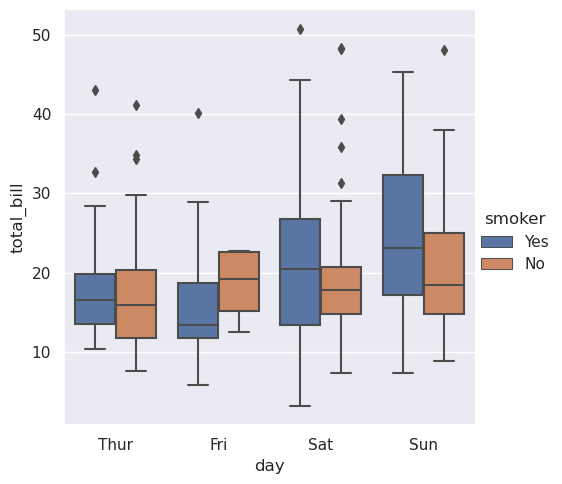
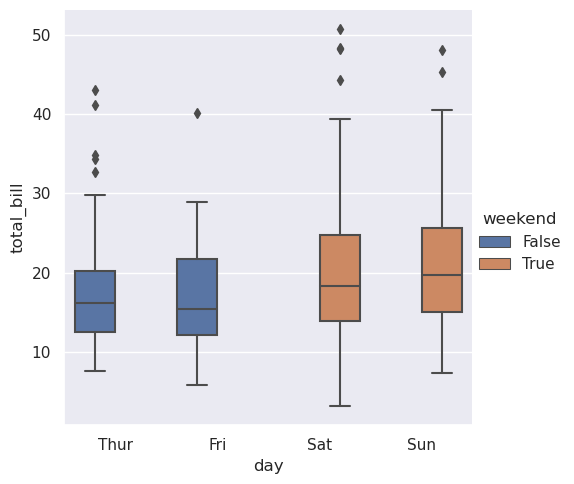
这种行为被称为“闪避”,它由dodge参数控制。默认情况下(从v0.13.0开始),元素只有在重叠时才会闪避:
>>> tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
>>> sns.catplot(data=tips, x="day", y="total_bill", hue="weekend", kind="box")
<seaborn.axisgrid.FacetGrid at 0x7f0024e6d910>
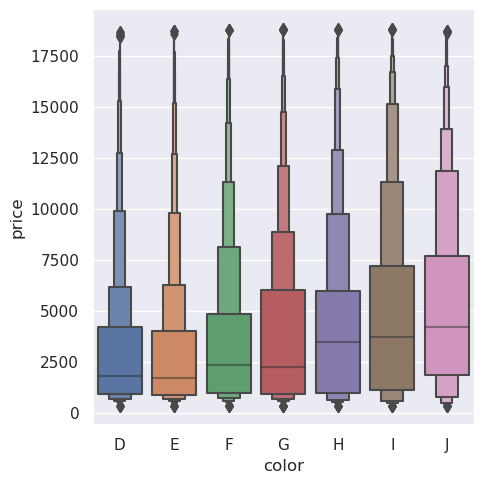
一个相关的函数boxenplot()绘制了一个类似于箱形图的图,但对其进行了优化,以显示有关分布形状的更多信息。它最适合于较大的数据集:
>>> diamonds = sns.load_dataset("diamonds")
>>> sns.catplot(
>>> data=diamonds.sort_values("color"),
>>> x="color", y="price", kind="boxen",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f0024d5d310>
小提琴情节¶
另一种方法是violinplot()
,它将箱线图与分布教程中描述的核密度估计过程相结合:
>>> sns.catplot(
>>> data=tips, x="total_bill", y="day", hue="sex", kind="violin",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f0024de1550>
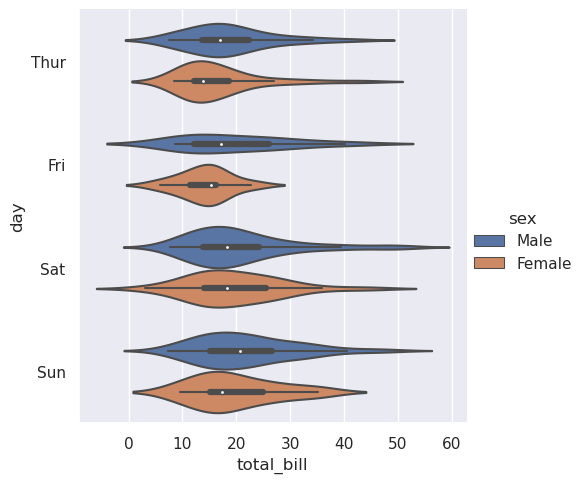
此方法使用核密度估计值来提供更丰富的值分布描述。此外,箱线图中的四分位数和晶须值显示在小提琴内部。缺点是,由于小提琴图使用了 KDE,因此还有一些其他参数可能需要调整,相对于简单的箱线图,增加了一些复杂性:
>>> sns.catplot(
>>> data=tips, x="total_bill", y="day", hue="sex",
>>> kind="violin", bw_adjust=.5, cut=0,
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f00251cd310>
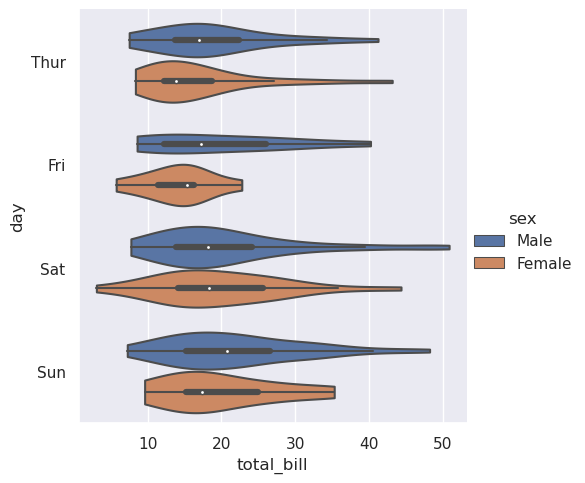
也可以“拆分”小提琴,这样可以更有效地利用空间:
>>> sns.catplot(
>>> data=tips, x="day", y="total_bill", hue="sex",
>>> kind="violin", split=True,
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f0023c60710>
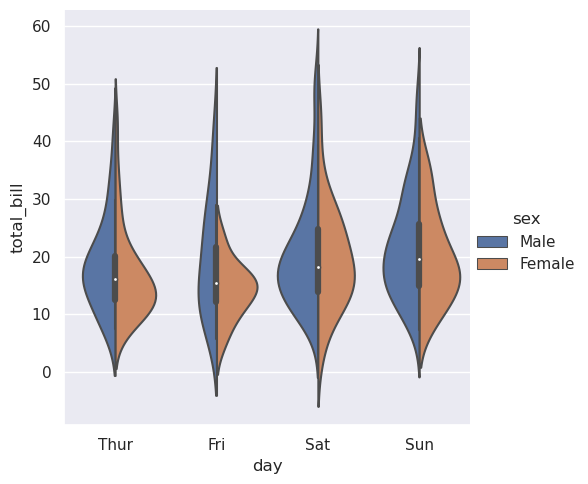
最后,在小提琴内部绘制的绘图有几个选项,包括显示每个单独观测值而不是汇总箱线图值的方法:
>>> sns.catplot(
>>> data=tips, x="day", y="total_bill", hue="sex",
>>> kind="violin", inner="stick", split=True, palette="pastel",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f0023c2d310>
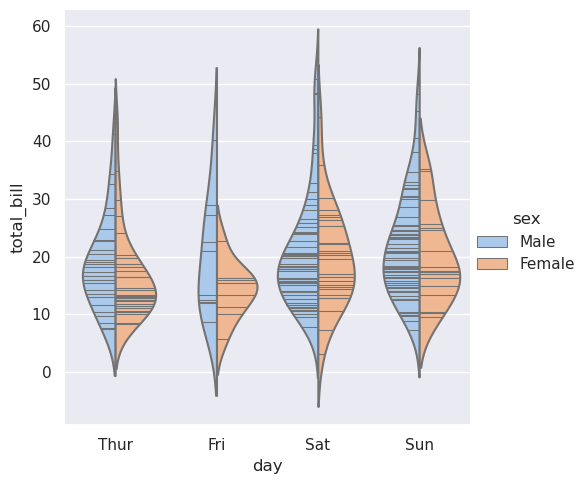
将swarmplot()或stripplot()与盒子图或小提琴图结合起来也很有用,可以显示每个观察结果以及分布的摘要:
>>> g = sns.catplot(data=tips, x="day", y="total_bill", kind="violin", inner=None)
>>> sns.swarmplot(data=tips, x="day", y="total_bill", color="k", size=3, ax=g.ax)
<AxesSubplot: xlabel='day', ylabel='total_bill'>
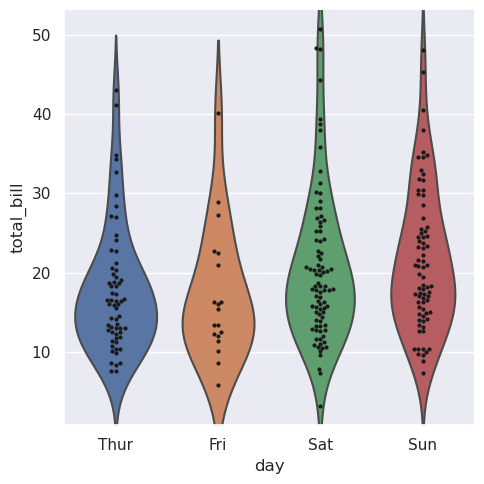
5.8.3. 估计集中趋势¶
对于其他应用程序,您可能希望显示值的集中趋势的估计值,而不是显示每个类别中的分布。Seaborn 有两种主要方式来显示此信息。重要的是,这些函数的基本 API 与上面讨论的 API 相同。
条形图¶
实现此目标的一种熟悉的情节风格是条形图。在 seaborn
中,barplot()函数对完整数据集进行操作,并应用函数来获取估计值(默认取平均值)。当每个类别中有多个观测值时,它还使用自举来计算估计值周围的置信区间,该置信区间使用误差线绘制:
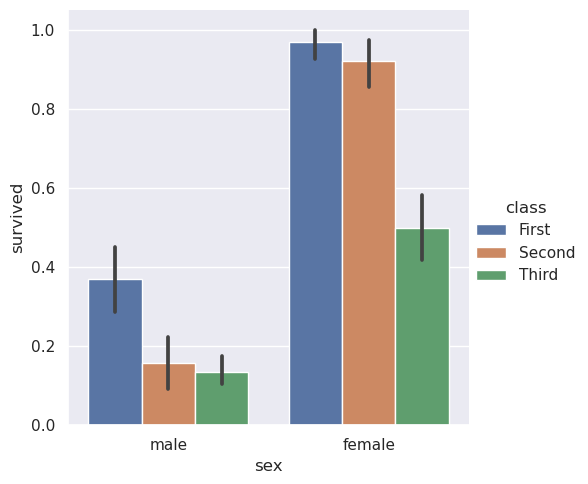
>>> titanic = sns.load_dataset("titanic",data_home='seaborn-data',cache=True)
>>> sns.catplot(data=titanic, x="sex", y="survived", hue="class", kind="bar")
<seaborn.axisgrid.FacetGrid at 0x7f48630877d0>
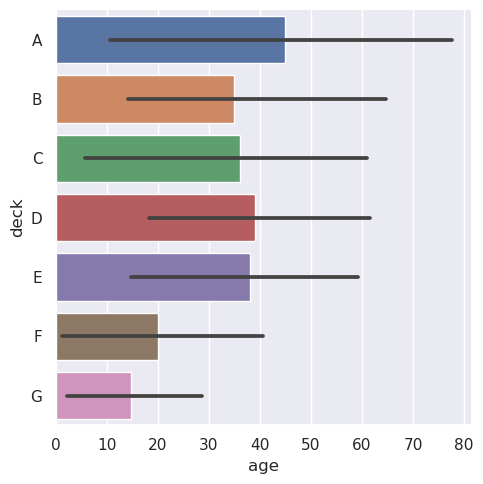
默认误差线显示 95% 置信区间,但(从 v0.12),可以从许多其他表示形式中进行选择:
>>> sns.catplot(data=titanic, x="age", y="deck", errorbar=("pi", 95), kind="bar")
<seaborn.axisgrid.FacetGrid at 0x7f486315bf90>
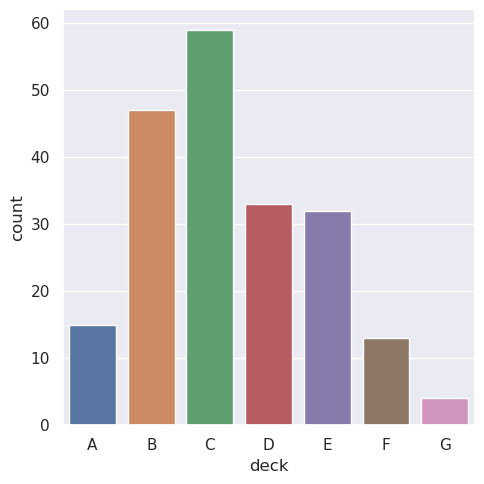
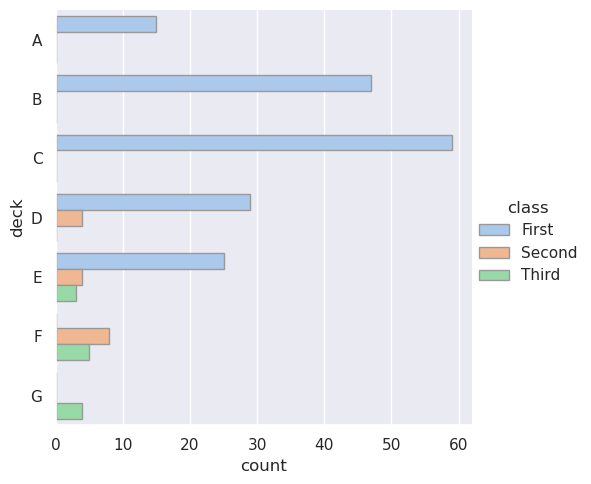
条形图的一个特殊情况是,当您想要显示每个类别中的观测值数,而不是计算第二个变量的统计量时。这类似于分类变量(而非定量变量)上的直方图。在 seaborn 中,使用以下功能可以轻松做到这一点:
>>> sns.catplot(data=titanic, x="deck", kind="count")
<seaborn.axisgrid.FacetGrid at 0x7f4862e95010>
barplot()和countplot()都可以用上面讨论的所有选项调用,以及在每个函数的详细文档中演示的其他选项:
>>> sns.catplot(
>>> data=titanic, y="deck", hue="class", kind="count",
>>> palette="pastel", edgecolor=".6",
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f4862d915d0>
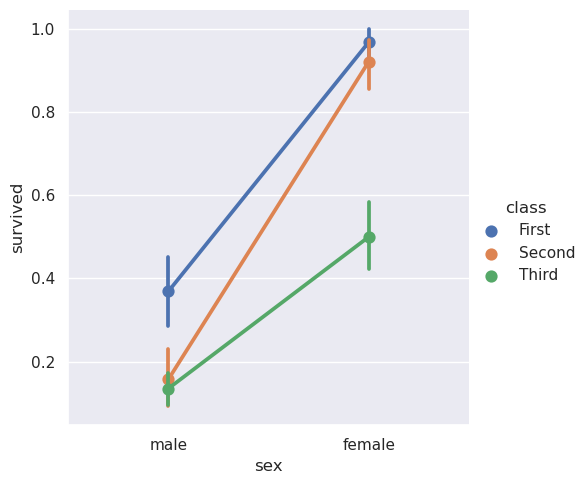
点的情节¶
pointplot()函数提供了可视化相同信息的另一种样式。该函数还用另一个轴上的高度对估计值进行编码,但不是显示完整的条形图,而是绘制点估计值和置信区间。此外,pointplot()连接来自相同色调类别的点。这使得我们很容易看到主要关系是如何随着色调语义的变化而变化的,因为你的眼睛很擅长辨别坡度的差异:
>>> sns.catplot(data=titanic, x="sex", y="survived", hue="class", kind="point")
<seaborn.axisgrid.FacetGrid at 0x7f4862da5490>
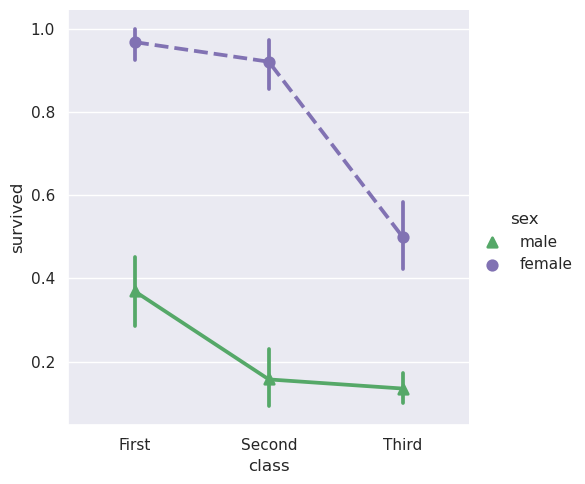
虽然分类函数缺乏关系函数的style语义,但改变标记和/或线条风格以及色调仍然是一个好主意,以使图形在最大程度上易于访问并在黑白中很好地再现:
>>> sns.catplot(
>>> data=titanic, x="class", y="survived", hue="sex",
>>> palette={"male": "g", "female": "m"},
>>> markers=["^", "o"], linestyles=["-", "--"],
>>> kind="point"
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f4862e91010>
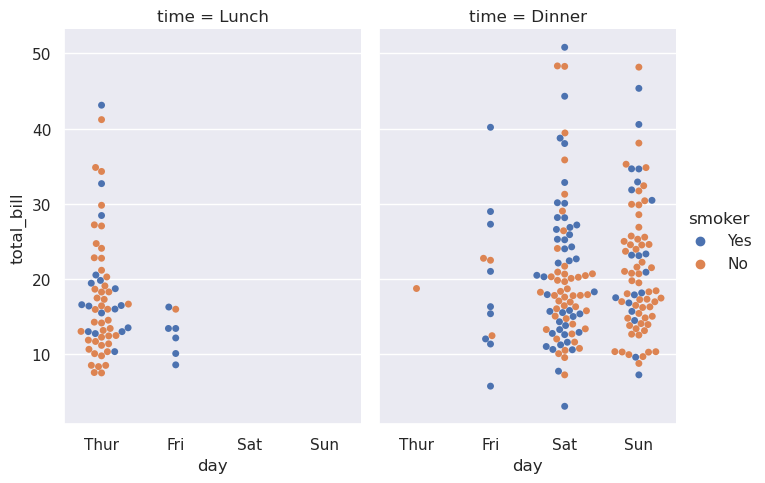
5.8.4. 显示额外的维度¶
就像relplot()一样,catplot()是建立在FacetGrid上的,这意味着很容易添加faceting变量来可视化高维关系:
>>> sns.catplot(
>>> data=tips, x="day", y="total_bill", hue="smoker",
>>> kind="swarm", col="time", aspect=.7,
>>> )
<seaborn.axisgrid.FacetGrid at 0x7f4862b59510>
为了进一步定制绘图,你可以使用它返回的FacetGrid对象上的方法:
>>> g = sns.catplot(
>>> data=titanic,
>>> x="fare", y="embark_town", row="class",
>>> kind="box", orient="h",
>>> sharex=False, margin_titles=True,
>>> height=1.5, aspect=4,
>>> )
>>> g.set(xlabel="Fare", ylabel="")
>>> g.set_titles(row_template="{row_name} class")
>>> for ax in g.axes.flat:
>>> ax.xaxis.set_major_formatter('${x:.0f}')
