>>> from env_helper import info; info()
页面更新时间: 2024-01-17 22:23:37
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-17-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
2.1. 使用 NLTK 分析单词和句子¶
NLTK 模块是一个巨大的工具包,目的是在整个自然语言处理(NLP)方法上帮助您。 NLTK 将为您提供一切,从将段落拆分为句子,拆分词语,识别这些词语的词性,高亮主题,甚至帮助您的机器了解文本关于什么。在这个系列中,我们将要解决意见挖掘或情感分析的领域。
在我们学习如何使用 NLTK 进行情感分析的过程中,我们将学习以下内容:
分词 - 将文本正文分割为句子和单词。
词性标注
机器学习与朴素贝叶斯分类器
如何一起使用 Scikit Learn(sklearn)与 NLTK
用数据集训练分类器
用 Twitter 进行实时的流式情感分析。
…以及更多。
2.1.1. 安装 NLTK¶
安装 NLTK 模块的最简单方法是使用 pip 。
对于所有的用户来说,这通过打开cmd.exe,bash,或者你使用的任何
shell,并键入以下命令来完成:
pip install nltk
2.1.2. 配置 NLTK 数据¶
数据是软件的一部分,运行NLTK需要使用相应的数据。 有两种方法,第一种自动化方法比较方便,但是因为网络原因安装成功很难;所以一般使用第二种方法。
自动安装数据¶
接下来,我们需要为 NLTK 安装一些组件。通过你的任何常用方式打开 python,然后键入:
>>> import nltk
>>> nltk.download()
除非你正在操作无头版本,否则一个 GUI 会弹出来,可能只有红色而不是绿色:
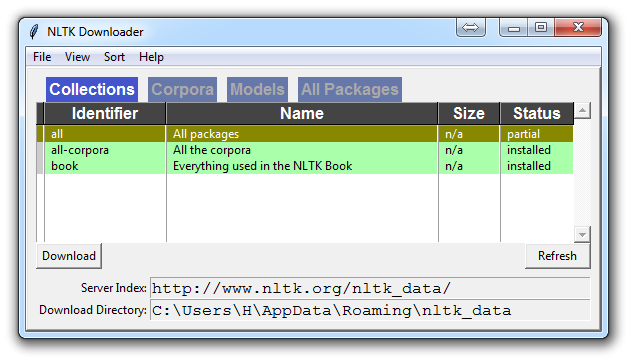
为所有软件包选择下载“全部”,然后单击“下载”。 这会给你所有分词器,分块器,其他算法和所有的语料库。 如果空间是个问题,您可以选择手动选择性下载所有内容。
NLTK 模块将占用大约 7MB,整个nltk_data目录将占用大约
1.8GB,其中包括您的分块器,解析器和语料库。
如果您正在使用 VPS 运行无头版本,您可以通过运行 Python ,并执行以下操作来安装所有内容:
import nltk nltk.download() d (for download all (for download everything)
这将为你下载一切东西。
手工安装数据¶
需要找到nltk_data下载包,下载到本地之后导入。一般完成下面第1项就可以。
到GitHub查找源,https://github.com/nltk/nltk_data ;也可以使用 Gitee 同步过来的源: https://gitee.com/gislite/nltk_data 。
如果需要另外一些包,请访问 http://www.nltk.org/nltk_data/
为了国内方便使用,目前在 Gitee 中镜像了这个库,使用的话按下面命令:
git clone https://gitee.com/gislite/nltk_data.git
注意存放此数据的路径。
2.1.3. 开始使用 NLTK¶
手工下载的NLTK数据使用时需要让NLTK知道在什么地方, nltk 模块
data 用来完成这个任务。
>>> import nltk
>>> from nltk import data
>>>
>>> data.path.append("/home/bk/nltk_data/packages")
>>> data.path
['/home/bk/nltk_data',
'/usr/nltk_data',
'/usr/share/nltk_data',
'/usr/lib/nltk_data',
'/usr/share/nltk_data',
'/usr/local/share/nltk_data',
'/usr/lib/nltk_data',
'/usr/local/lib/nltk_data',
'/home/bk/nltk_data/packages']
现在你已经拥有了所有你需要的东西,让我们敲一些简单的词汇:
语料库(Corpus) - 文本的正文,单数。Corpora 是它的复数。示例:
A collection of medical journals。词库(Lexicon) - 词汇及其含义。例如:英文字典。但是,考虑到各个领域会有不同的词库。例如:对于金融投资者来说,
Bull(牛市)这个词的第一个含义是对市场充满信心的人,与“普通英语词汇”相比,这个词的第一个含义是动物。因此,金融投资者,医生,儿童,机械师等都有一个特殊的词库。标记(Token) - 每个“实体”都是根据规则分割的一部分。例如,当一个句子被“拆分”成单词时,每个单词都是一个标记。如果您将段落拆分为句子,则每个句子也可以是一个标记。
这些是在进入自然语言处理(NLP)领域时,最常听到的词语,但是我们将及时涵盖更多的词汇。以此,我们来展示一个例子,说明如何用 NLTK 模块将某些东西拆分为标记。
>>> from nltk.tokenize import sent_tokenize, word_tokenize
>>>
>>> EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."
此时如果运行 sent_tokenize(EXAMPLE_TEXT) 会出现错误:
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
对于手工下载的nltk数据,还需要额外的步骤,就是将提供的数据解压缩,以便 Python 能够识别、调用。
punkt 位于:~/nltk_data/packages/tokenizers , 在此文件夹下解压缩即可。
cd ~/nltk_data/packages/tokenizers
unzip punkt.zip
划分句子¶
然后再次运行,完成对句子的划分。
>>> sent_tokenize(EXAMPLE_TEXT)
['Hello Mr. Smith, how are you doing today?',
'The weather is great, and Python is awesome.',
'The sky is pinkish-blue.',
"You shouldn't eat cardboard."]
起初,你可能会认为按照词或句子来分词,是一件相当微不足道的事情。
对于很多句子来说,它可能是。
第一步可能是执行一个简单的.split('. '),或按照句号,然后是空格分割。
之后也许你会引入一些正则表达式,来按照句号,空格,然后是大写字母分割。
问题是像Mr. Smith这样的事情,还有很多其他的事情会给你带来麻烦。
按照词分割也是一个挑战,特别是在考虑缩写的时候,例如we和we're。
NLTK 用这个看起来简单但非常复杂的操作为您节省大量的时间。
上面的代码会输出句子,分成一个句子列表,你可以用for循环来遍历。
所以这里,我们创建了标记,它们都是句子。
分词¶
让我们这次按照词来分词。
>>> word_tokenize(EXAMPLE_TEXT)
['Hello',
'Mr.',
'Smith',
',',
'how',
'are',
'you',
'doing',
'today',
'?',
'The',
'weather',
'is',
'great',
',',
'and',
'Python',
'is',
'awesome',
'.',
'The',
'sky',
'is',
'pinkish-blue',
'.',
'You',
'should',
"n't",
'eat',
'cardboard',
'.']
这里有几件事要注意。 首先,注意标点符号被视为一个单独的标记。
另外,注意单词shouldn't分隔为should和n't。
最后要注意的是,pinkish-blue确实被当作“一个词”来对待,本来就是这样。很酷!
现在,看着这些分词后的单词,我们必须开始思考我们的下一步可能是什么。 我们开始思考如何通过观察这些词汇来获得含义。 我们可以想清楚,如何把价值放在许多单词上,但我们也看到一些基本上毫无价值的单词。 这是一种“停止词”的形式,我们也可以处理。 这就是我们将在下一个教程中讨论的内容。