3.5. 验证曲线:绘制分数以评估模型#
每个估计器都有其优点和缺点。它的概括误差可以用偏差、方差和噪音来分解。的 bias 估计器的平均误差是不同训练集的平均误差。的 variance 估计器的值指示它对变化的训练集的敏感程度。噪音是数据的一种属性。
在下面的图中,我们看到一个函数 \(f(x) = \cos (\frac{3}{2} \pi x)\) 以及来自该函数的一些有噪的样本。我们使用三种不同的估计量来匹配该函数:具有1次、4次和15次多项特征的线性回归。我们看到,第一个估计器最多只能提供对样本和真函数的不良匹配,因为它太简单(高偏差),第二个估计器几乎完美地逼近它,而最后一个估计器完美地逼近训练数据,但不能很好地匹配真函数,即它对变化的训练数据非常敏感(高方差)。
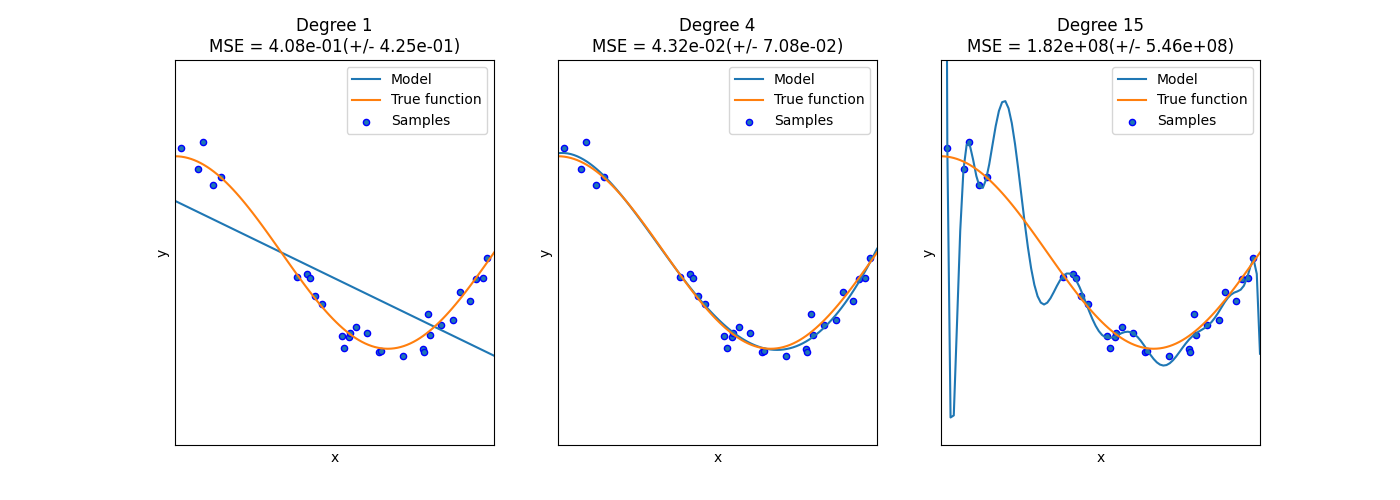
偏差和方差是估计器的固有属性,我们通常必须选择学习算法和超参数,以便偏差和方差尽可能低(请参阅 Bias-variance dilemma ).减少模型方差的另一种方法是使用更多训练数据。然而,只有当真函数太复杂而无法用方差较低的估计器进行逼近时,您才应该收集更多训练数据。
在我们在示例中看到的简单一维问题中,很容易看出估计器是否存在偏差或方差。然而,在多维空间中,模型可能变得非常难以可视化。因此,使用下面描述的工具通常很有帮助。
示例
3.5.1. 验证曲线#
要验证模型,我们需要一个评分功能(请参阅 预设和评分:量化预测的质量 ),例如分类器的准确性。选择估计器的多个超参数的正确方法当然是网格搜索或类似方法(请参阅 调整估计器的超参数 )选择一个或多个验证集中具有最大分数的超参数。请注意,如果我们基于验证分数优化超参数,验证分数就会有偏差,并且不再是对概括的良好估计。为了获得对概括性的正确估计,我们必须计算另一个测试集的分数。
然而,绘制单个超参数对训练分数和验证分数的影响有时会很有帮助,以了解估计器对于某些超参数值是否过度适合或不足。
功能 validation_curve 可以帮助在这种情况下::
>>> import numpy as np
>>> from sklearn.model_selection import validation_curve
>>> from sklearn.datasets import load_iris
>>> from sklearn.svm import SVC
>>> np.random.seed(0)
>>> X, y = load_iris(return_X_y=True)
>>> indices = np.arange(y.shape[0])
>>> np.random.shuffle(indices)
>>> X, y = X[indices], y[indices]
>>> train_scores, valid_scores = validation_curve(
... SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 3),
... )
>>> train_scores
array([[0.90, 0.94, 0.91, 0.89, 0.92],
[0.9 , 0.92, 0.93, 0.92, 0.93],
[0.97, 1 , 0.98, 0.97, 0.99]])
>>> valid_scores
array([[0.9, 0.9 , 0.9 , 0.96, 0.9 ],
[0.9, 0.83, 0.96, 0.96, 0.93],
[1. , 0.93, 1 , 1 , 0.9 ]])
如果您仅打算绘制验证曲线,则类 ValidationCurveDisplay 比手动使用matplotlib处理调用的结果更直接 validation_curve .你可以用这个方法 from_estimator 类似于 validation_curve 生成并绘制验证曲线:
from sklearn.datasets import load_iris
from sklearn.model_selection import ValidationCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
ValidationCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 10)
)
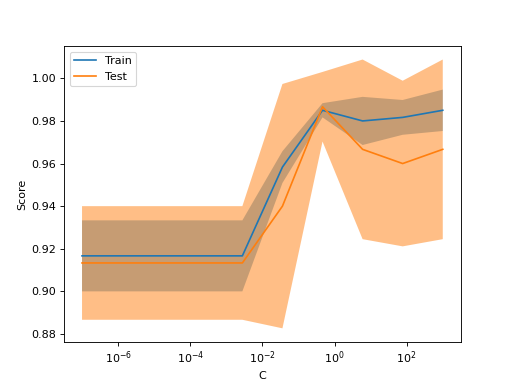
如果训练分数和验证分数都很低,则估计器将不适合。如果训练分数很高而验证分数很低,则估计器是过拟的,否则它工作得很好。低训练分数和高验证分数通常是不可能的。
3.5.2. 学习曲线#
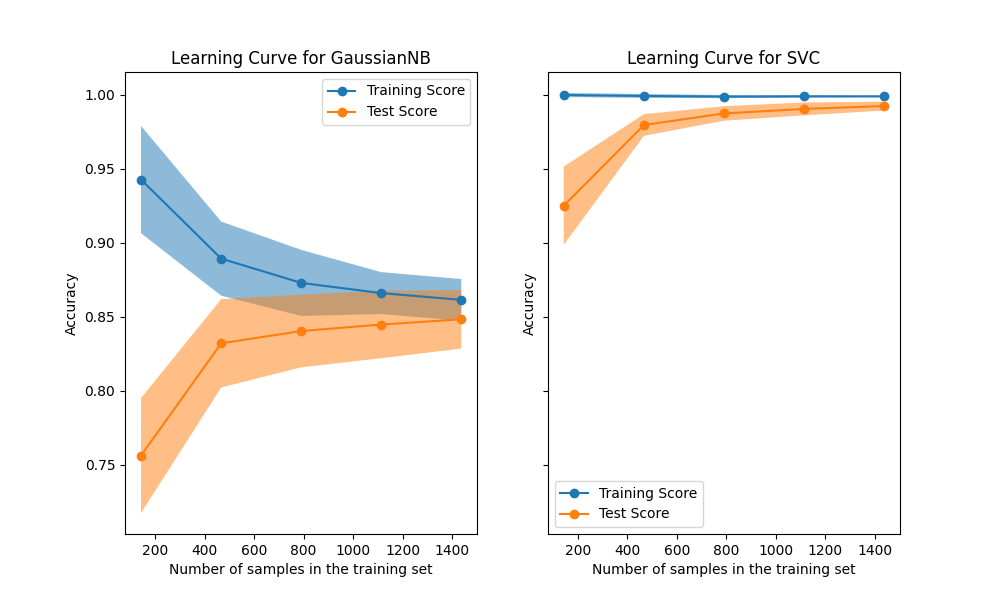
学习曲线显示了估计器对不同训练样本数量的验证和训练分数。它是一个工具,可以了解我们从添加更多训练数据中受益多少,以及估计器是否因方差误差或偏差误差而受到更多影响。考虑下面的例子,我们绘制了原始Bayes分类器和支持者的学习曲线。
对于天真的Bayes,验证分数和训练分数都随着训练集大小的增加而收敛到相当低的值。因此,我们可能不会从更多的训练数据中受益太多。
相比之下,对于少量数据,支持者的训练分数远大于验证分数。添加更多的训练样本很可能会提高概括性。
我们可以使用该功能 learning_curve 生成绘制此类学习曲线所需的值(已使用的样本数量、训练集的平均分数和验证集的平均分数)::
>>> from sklearn.model_selection import learning_curve
>>> from sklearn.svm import SVC
>>> train_sizes, train_scores, valid_scores = learning_curve(
... SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5)
>>> train_sizes
array([ 50, 80, 110])
>>> train_scores
array([[0.98, 0.98 , 0.98, 0.98, 0.98],
[0.98, 1. , 0.98, 0.98, 0.98],
[0.98, 1. , 0.98, 0.98, 0.99]])
>>> valid_scores
array([[1. , 0.93, 1. , 1. , 0.96],
[1. , 0.96, 1. , 1. , 0.96],
[1. , 0.96, 1. , 1. , 0.96]])
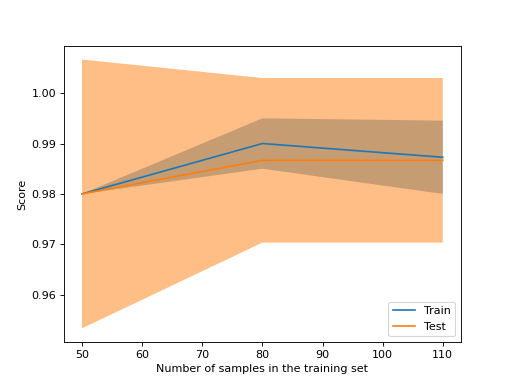
如果您仅打算绘制学习曲线,则课程 LearningCurveDisplay 会更容易使用。你可以用这个方法 from_estimator 类似于 learning_curve 生成并绘制学习曲线:
from sklearn.datasets import load_iris
from sklearn.model_selection import LearningCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
LearningCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, train_sizes=[50, 80, 110], cv=5)
示例
看到 绘制学习曲线并检查模型的可扩展性 使用学习曲线检查预测模型可扩展性的示例。