8.3. 生成的数据集#
此外,scikit-learn包括各种随机样本生成器,可用于构建大小和复杂性受控的人工数据集。
8.3.1. 用于分类和集群的生成器#
这些生成器生成特征矩阵和相应的离散目标。
8.3.1.1. 单个标签#
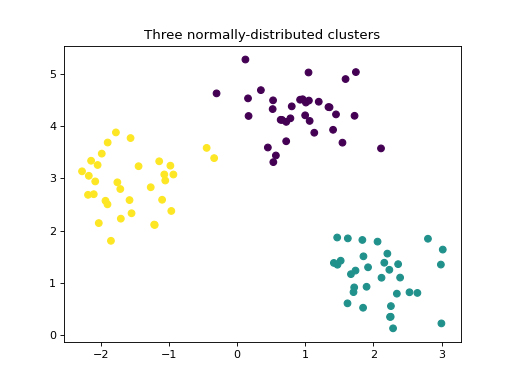
make_blobs 通过将每个类分配给一个正态分布的点集群来创建多类数据集。它提供对每个集群的中心和标准差的控制。此数据集用于演示集群。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=3, cluster_std=0.5, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title("Three normally-distributed clusters")
plt.show()
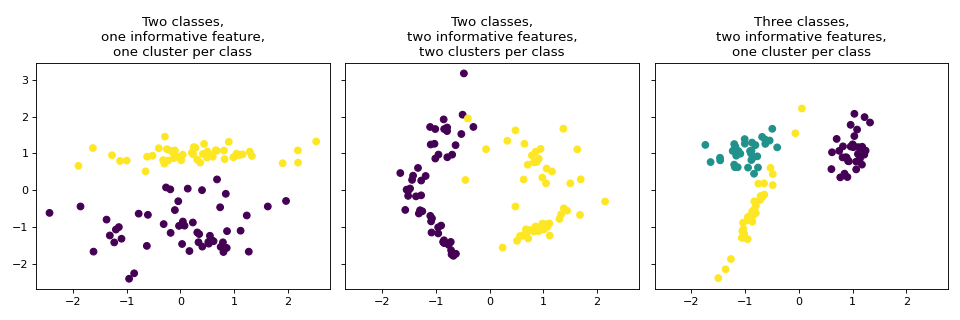
make_classification 还创建多类数据集,但专门通过以下方式引入噪音:相关、冗余和无信息特征;每个类的多个高斯集群;以及特征空间的线性变换。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True, sharex=True)
titles = ["Two classes,\none informative feature,\none cluster per class",
"Two classes,\ntwo informative features,\ntwo clusters per class",
"Three classes,\ntwo informative features,\none cluster per class"]
params = [
{"n_informative": 1, "n_clusters_per_class": 1, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 2, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 1, "n_classes": 3}
]
for i, param in enumerate(params):
X, Y = make_classification(n_features=2, n_redundant=0, random_state=1, **param)
axs[i].scatter(X[:, 0], X[:, 1], c=Y)
axs[i].set_title(titles[i])
plt.tight_layout()
plt.show()
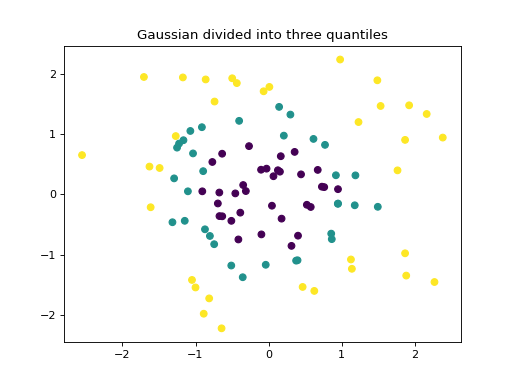
make_gaussian_quantiles 将单个高斯集群分为由同心超球分开的几乎相等大小的类。
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
X, Y = make_gaussian_quantiles(n_features=2, n_classes=3, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.title("Gaussian divided into three quantiles")
plt.show()
make_hastie_10_2 生成类似的二元、10维问题。
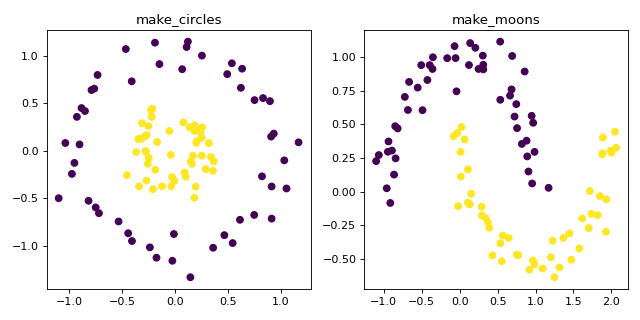
make_circles 和 make_moons 生成对某些算法具有挑战性的2D二进制分类数据集(例如,基于中心的集群或线性分类),包括可选的高斯噪音。它们对于可视化很有用。 make_circles 生成具有球形决策边界的高斯数据以进行二进制分类,而 make_moons 产生两个交错的半圆。
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_moons
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
X, Y = make_circles(noise=0.1, factor=0.3, random_state=0)
ax1.scatter(X[:, 0], X[:, 1], c=Y)
ax1.set_title("make_circles")
X, Y = make_moons(noise=0.1, random_state=0)
ax2.scatter(X[:, 0], X[:, 1], c=Y)
ax2.set_title("make_moons")
plt.tight_layout()
plt.show()
8.3.1.2. 多标记#
make_multilabel_classification 生成带有多个标签的随机样本,反映从混合主题中提取的一袋单词。每个文档的主题数来自泊松分布,主题本身来自固定的随机分布。类似地,单词的数量是从泊松中得出的,单词是从多项式中得出的,其中每个主题定义了单词的概率分布。关于真正的词袋混合的简化包括:
每个主题的单词分布是独立绘制的,实际上所有单词都会受到稀疏基本分布的影响,并且会相互关联。
对于从多个主题生成的文档,在生成其单词包时,所有主题的权重相等。
没有标签单词的文档是随机的,而不是来自基本分布。

8.3.1.3. 双聚类#
|
生成用于双集群的恒定块对角线结构阵列。 |
|
生成具有块棋盘结构的数组以进行双集群化。 |
8.3.2. 回归生成器#
make_regression 将回归目标生成为随机特征与噪音的可选稀疏随机线性组合。它的信息特征可能不相关,或排名较低(很少有特征解释了大部分方差)。
其他回归生成器从随机化特征确定性地生成函数。 make_sparse_uncorrelated 将目标生成为具有固定系数的四个特征的线性组合。其他人则明确编码非线性关系: make_friedman1 通过多项变换和sin变换相关; make_friedman2 包括特征相乘和互惠;以及 make_friedman3 类似于目标上的反正切变形。
8.3.3. 用于多种学习的生成器#
|
生成S曲线数据集。 |
|
生成瑞士卷数据集。 |
8.3.4. Generators for decomposition#
|
生成一个具有钟形奇异值的基本上低阶矩阵。 |
|
Generate a signal as a sparse combination of dictionary elements. |
|
生成一个随机对称、正定矩阵。 |
|
生成稀疏对称定正矩阵。 |