1.16. 概率定标#
执行分类时,您通常不仅希望预测类别标签,还希望获得相应标签的概率。这个概率让您对预测有一定的信心。有些模型可能会为您提供较差的类别概率估计,有些甚至不支持概率预测(例如,的一些实例 SGDClassifier ).校准模块允许您更好地校准给定模型的概率,或添加对概率预测的支持。
经过良好校准的分类器是概率分类器,其 predict_proba 方法可以直接解释为置信水平。例如,一个经过良好校准的(二进制)分类器应该对样本进行分类,以便在它给予的样本中 predict_proba 值接近0.8,大约80%实际上属于阳性类。
在展示如何重新校准分类器之前,我们首先需要一种方法来检测分类器的校准程度。
备注
严格正确的概率预测评分规则,例如 sklearn.metrics.brier_score_loss 和 sklearn.metrics.log_loss 同时评估模型的校准(可靠性)和辨别力(分辨率),以及数据的随机性(不确定性)。这源于墨菲著名的Brier乐谱分解 [1]. 由于尚不清楚哪个项占主导地位,因此分数对于单独评估校准的用途有限(除非计算分解的每个项)。例如,较低的布里尔损失并不一定意味着校准的模型更好,它还可能意味着校准的模型更差,具有更大的区分能力,例如使用更多的特征。
1.16.1. 校准曲线#
校准曲线,也称为 reliability diagrams (威尔克斯,1995年 [2]) ,比较二进制分类器的概率预测的校准情况。它绘制了阳性标签的频率(更准确地说,是对 conditional event probability \(P(Y=1|\text{predict_proba})\) )与预测概率的关系 predict_proba x轴上的模型。棘手的部分是获取y轴的值。在scikit-learn中,这是通过将预测分组来实现的,以便x轴代表每个分组中的平均预测概率。那么y轴就是 fraction of positives 给定该箱的预测,即类别为正类别的样本比例(每个箱中)。
顶部校准曲线图是使用 CalibrationDisplay.from_estimator ,它使用 calibration_curve 计算每箱平均预测概率和阳性分数。 CalibrationDisplay.from_estimator 将适合的分类器作为输入,用于计算预测概率。因此,分类器必须具有 predict_proba 法对于少数没有 predict_proba 方法,可以使用 CalibratedClassifierCV 将分类器输出校准为概率。
底部的图表通过显示每个预测概率箱中的样本数量来深入了解每个分类器的行为。
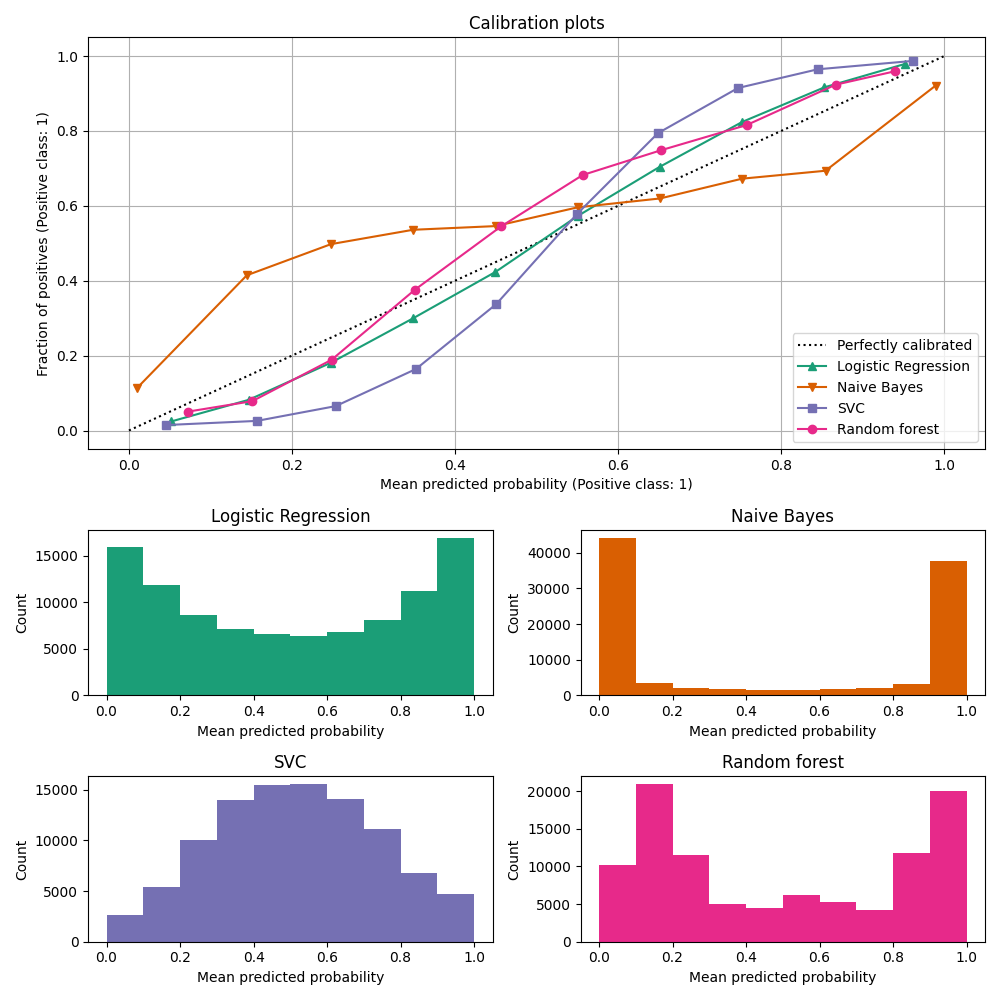
LogisticRegression 更有可能自己返回经过良好校准的预测,因为它具有针对其损失的典型链接函数,即 对数损失 .在未受处罚的情况下,这就导致了所谓的 balance property ,看到了 [8] 和 Logistic回归 .在上图中,数据是根据线性机制生成的,这与 LogisticRegression 模型(模型“已明确指定”),以及正规化参数的值 C 它被调整为适当的(既不太强也不太低)。因此,该模型从其 predict_proba 法与此相反,显示的其他模型返回有偏差的概率;每个模型具有不同的偏差。
GaussianNB (天真的Bayes)倾向于将概率推至0或1(请注意矩形图中的计数)。这主要是因为它假设特征在给定类别的情况下是有条件独立的,但在包含2个冗余特征的这个数据集中,情况并非如此。
RandomForestClassifier 显示相反的行为:矩形图显示峰值的概率约为0.2和0.9,而接近0或1的概率非常罕见。Niculescu-Mizil和Caruana对此给出了解释 [3]: “诸如装袋和随机森林等方法,对一组基本模型的预测进行平均,可能很难做出接近0和1的预测,因为基础基本模型的方差会使本应接近0或与这些值相差1的预测产生偏差。因为预测仅限于区间 [0,1] ,方差引起的误差往往是单边的,接近零和一。例如,如果模型应该预测 \(p = 0\) 在某种情况下,装袋实现这一目标的唯一方法是所有袋装树木预测为零。如果我们向装袋平均值的树木添加噪音,则这种噪音将导致一些树木在这种情况下预测大于0的值,从而将袋装集合的平均预测从0移开。我们在随机森林中观察到这种效果最强烈,因为使用随机森林训练的基础树由于特征子集设置而具有相对较高的方差。结果,校准曲线显示出典型的S形形状,这表明分类器可以更多地相信其“直觉”,并返回的概率通常接近0或1。
LinearSVC (SVC)显示出比随机森林更S形的曲线,随机森林是最大利润方法的典型特征(比较Niculescu-Mizil和Caruana [3]) ,重点关注难以分类的接近决策边界的样本(支持载体)。
1.16.2. 校准分类器#
Calibrating a classifier consists of fitting a regressor (called a calibrator) that maps the output of the classifier (as given by decision_function or predict_proba) to a calibrated probability in [0, 1]. Denoting the output of the classifier for a given sample by \(f_i\), the calibrator tries to predict the conditional event probability \(P(y_i = 1 | f_i)\).
理想情况下,校准器适合于独立于最初用于适合分类器的训练数据的数据集。这是因为分类器在其训练数据上的性能将优于新数据。因此,使用训练数据的分类器输出来适应校准品将导致有偏差的校准品,该校准品映射到比应有的更接近0和1的概率。
1.16.3. 使用#
的 CalibratedClassifierCV 类用于校准分类器。
CalibratedClassifierCV 使用交叉验证方法来确保始终使用无偏见的数据来适应校准品。数据分为 \(k\) (train_set, test_set) 夫妇(由 cv ).当 ensemble=True (默认),对于每个交叉验证拆分独立重复以下过程:
的克隆
base_estimator在火车子集上训练经训练的
base_estimator对测试子集做出预测预测用于适应校准品(S形回归量或等张回归量)(当数据是多类时,校准品适合每个类)
这导致了一系列 \(k\) (classifier, calibrator) 每个校准器将其相应分类器的输出映射到 [0, 1] .每对选手都将在 calibrated_classifiers_ 属性,其中每个条目都是经过校准的分类器,具有 predict_proba 输出校准概率的方法。的输出 predict_proba 用于主 CalibratedClassifierCV 实例对应于 \(k\) 估计者 calibrated_classifiers_ 名单的输出 predict 是概率最高的类。
重要的是选择 cv 在使用我们 ensemble=True .对于每次拆分,所有类别都应出现在训练和测试子集中。当火车子集中不存在某个类别时,对于 (classifier, calibrator) 几个分裂。这扭曲了 predict_proba 所有夫妇的平均值当测试子集中不存在类时,该类的校准器(在 (classifier, calibrator) 几个分裂)适合没有正类的数据。这导致校准无效。
当 ensemble=False ,交叉验证用于通过 cross_val_predict .然后使用这些无偏差的预测来训练校准器。属性 calibrated_classifiers_ 只包含一个 (classifier, calibrator) 其中分类器是 base_estimator 根据所有数据进行训练。在这种情况下, predict_proba 为 CalibratedClassifierCV 是从单个 (classifier, calibrator) 夫妇
的主要优点 ensemble=True 是受益于传统的合奏效应(类似于 装袋元估计器 ).生成的集合应该经过良好校准,并且比 ensemble=False .使用的主要优势 ensemble=False 是计算性的:它通过仅训练单个基本分类器和校准品对来缩短总体匹配时间,减少最终模型大小并提高预测速度。
或者,可以通过使用 FrozenEstimator 作为 CalibratedClassifierCV(estimator=FrozenEstimator(estimator)) .用户有责任确保用于匹配分类器的数据与用于匹配回归量的数据不相交。
CalibratedClassifierCV 支持使用两种回归技术进行校准 method 参数: "sigmoid" 和 "isotonic" .
1.16.3.1. 乙状#
乙状回归子, method="sigmoid" 是基于普拉特的逻辑模型 [4]:
哪里 \(y_i\) 是样品的真实标签 \(i\) 和 \(f_i\) 是样本未校准分类器的输出 \(i\) . \(A\) 和 \(B\) 是通过最大似然度来匹配回归量时要确定的真实数字。
Sigmoid方法假设 calibration curve 可以通过对原始预测应用Sigmoid函数来纠正。在以下情况下,这一假设在经验上是合理的 支持向量机 在Platt 1999的第2.1节中, [4] 但不一定普遍成立。此外,如果校准误差对称,则逻辑模型效果最好,这意味着每个二进制类的分类器输出以相同的方差正态分布 [7]. 对于高度不平衡的分类问题来说,这可能是一个问题,其中输出的方差不相等。
一般来说,这种方法对于小样本量或未校准的模型信心不足并且高输出和低输出的校准误差相似时最有效。
1.16.3.2. 等渗#
的 method="isotonic" 适合非参数等序回归量,该回归量输出逐步非递减函数,请参阅 sklearn.isotonic .它最小化了:
subject to \(\hat{f}_i \geq \hat{f}_j\) whenever
\(f_i \geq f_j\). \(y_i\) is the true
label of sample \(i\) and \(\hat{f}_i\) is the output of the
calibrated classifier for sample \(i\) (i.e., the calibrated probability).
This method is more general when compared to 'sigmoid' as the only restriction
is that the mapping function is monotonically increasing. It is thus more
powerful as it can correct any monotonic distortion of the un-calibrated model.
However, it is more prone to overfitting, especially on small datasets [6].
总体而言, 'isotonic' 表现将与之一样好或更好 'sigmoid' 当有足够的数据(大于~1000个样本)来避免过度匹配时 [3].
备注
对排名指标(例如AUR)的影响
通常预计校准不会影响ROC-AUC等排名指标。然而,使用时,校准后这些指标可能会有所不同 method="isotonic" 因为等张回归在预测概率中引入了联系。这可以被视为模型预测的不确定性范围内。如果您严格希望保留排名并因此保留UC分数,请使用 method="sigmoid" 这是一个严格的单调变换,因此保持排名。
1.16.3.3. 多类支持#
等张回归子和S型回归子都仅支持1维数据(例如,二进制分类输出),但如果 base_estimator 支持多类预测。对于多类预测, CalibratedClassifierCV 分别在 OneVsRestClassifier 时尚 [5]. 预测概率时,会单独预测每个类别的校准概率。由于这些概率之和不一定等于一,因此执行后处理以将它们规格化。
示例
引用