pandas.Series.plot.density#
- Series.plot.density(bw_method=None, ind=None, **kwargs)[源代码]#
使用高斯核生成核密度估计图。
在统计中, kernel density estimation (KDE)是一种估计随机变量概率密度函数(PDF)的非参数方法。此函数使用高斯核,并包括自动带宽确定。
- 参数
- bw_method字符串,标量或可调用,可选
用于计算估计器带宽的方法。它可以是‘Scott’、‘Silverman’、标量常量或可调用的。如果无(默认),则使用‘Scott’。看见
scipy.stats.gaussian_kde了解更多信息。- indNumPy数组或int,可选
评估PDF的评估点。如果为None(默认),则使用1000个等距点。如果 ind 是一个NumPy数组,则在传递的点处计算KDE。如果 ind 是一个整数, ind 使用多个等间距的点。
- **kwargs
中记录了其他关键字参数
DataFrame.plot()。
- 退货
- Matplotlib.axs.轴或数字.ndarray
参见
scipy.stats.gaussian_kde使用高斯核的核密度估计的表示。这是内部用于估计PDF的函数。
示例
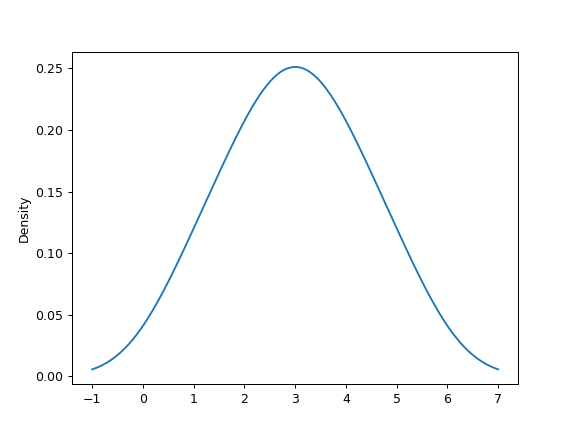
给出从未知分布中随机抽样的一系列点,使用具有自动带宽确定功能的KDE估计其PDF,并绘制结果,以1000个等距点进行评估(默认):
>>> s = pd.Series([1, 2, 2.5, 3, 3.5, 4, 5]) >>> ax = s.plot.kde()
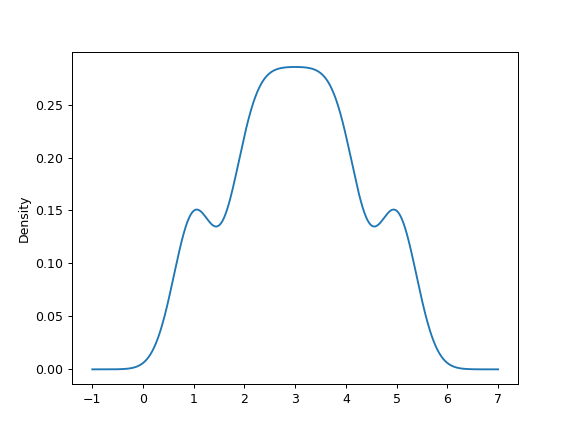
可以指定标量带宽。使用较小的带宽值可能会导致过度适配,而使用较大的带宽值可能会导致适配不足:
>>> ax = s.plot.kde(bw_method=0.3)
>>> ax = s.plot.kde(bw_method=3)

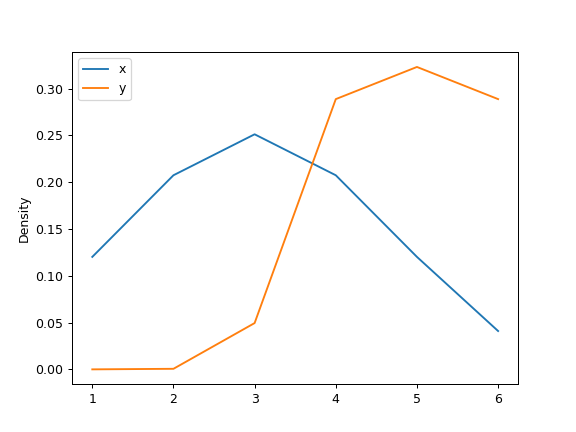
最后, ind 参数确定估计的PDF的曲线图的评估点:
>>> ax = s.plot.kde(ind=[1, 2, 3, 4, 5])

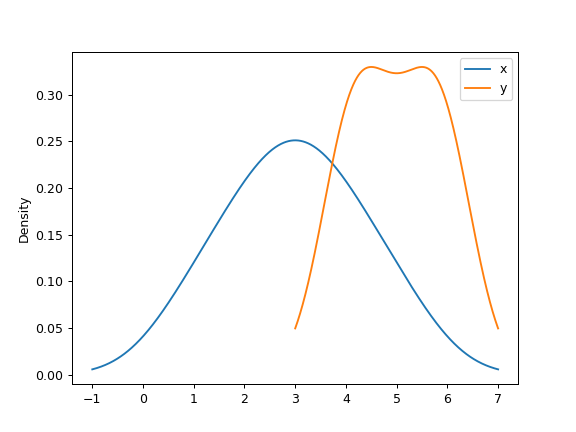
对于DataFrame,它的工作方式相同:
>>> df = pd.DataFrame({ ... 'x': [1, 2, 2.5, 3, 3.5, 4, 5], ... 'y': [4, 4, 4.5, 5, 5.5, 6, 6], ... }) >>> ax = df.plot.kde()
可以指定标量带宽。使用较小的带宽值可能会导致过度适配,而使用较大的带宽值可能会导致适配不足:
>>> ax = df.plot.kde(bw_method=0.3)

>>> ax = df.plot.kde(bw_method=3)
最后, ind 参数确定估计的PDF的曲线图的评估点:
>>> ax = df.plot.kde(ind=[1, 2, 3, 4, 5, 6])