线性代数 (scipy.linalg )¶
当使用优化的ATLAS LAPACK和BLAS库构建SciPy时,它具有非常快的线性代数功能。如果你的挖洞足够深入,所有原始的lapack和blas库都可以供你使用,速度会更快。在本节中,将介绍这些例程的一些更易于使用的接口。
所有这些线性代数例程都需要一个可以转换为二维数组的对象。这些例程的输出也是一个二维数组。
scipy.linalg vs numpy.linalg¶
scipy.linalg 包含中的所有函数 numpy.linalg 。外加一些未包含在 numpy.linalg 。
使用的另一个优点是 scipy.linalg 完毕 numpy.linalg 它总是使用BLAS/LAPACK支持进行编译,而对于Numpy,这是可选的。因此,根据安装Numpy的方式不同,Scipy版本可能会更快。
因此,除非您不想添加 scipy 作为对您的 numpy 程序,使用 scipy.linalg 而不是 numpy.linalg 。
Numpy.Matrix vs 2-D Numpy.ndarray¶
表示矩阵和基本运算(如矩阵乘法和转置)的类是 numpy 。为方便起见,我们总结了 numpy.matrix 和 numpy.ndarray 这里。
numpy.matrix 是一个接口比矩阵类更方便的矩阵类 numpy.ndarray 用于矩阵运算。例如,此类通过分号支持类似MATLAB的创建语法,将矩阵乘法作为 * 运算符,并包含 I 和 T 用作反转和转置快捷方式的成员:
>>> import numpy as np
>>> A = np.mat('[1 2;3 4]')
>>> A
matrix([[1, 2],
[3, 4]])
>>> A.I
matrix([[-2. , 1. ],
[ 1.5, -0.5]])
>>> b = np.mat('[5 6]')
>>> b
matrix([[5, 6]])
>>> b.T
matrix([[5],
[6]])
>>> A*b.T
matrix([[17],
[39]])
尽管很方便,但使用 numpy.matrix 类是不受欢迎的,因为它没有添加使用2-D无法完成的任何内容 numpy.ndarray 对象,并可能导致正在使用哪个类的念力。例如,上面的代码可以重写为:
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,2],[3,4]])
>>> A
array([[1, 2],
[3, 4]])
>>> linalg.inv(A)
array([[-2. , 1. ],
[ 1.5, -0.5]])
>>> b = np.array([[5,6]]) #2D array
>>> b
array([[5, 6]])
>>> b.T
array([[5],
[6]])
>>> A*b #not matrix multiplication!
array([[ 5, 12],
[15, 24]])
>>> A.dot(b.T) #matrix multiplication
array([[17],
[39]])
>>> b = np.array([5,6]) #1D array
>>> b
array([5, 6])
>>> b.T #not matrix transpose!
array([5, 6])
>>> A.dot(b) #does not matter for multiplication
array([17, 39])
scipy.linalg 操作可以平等地应用于 numpy.matrix 或转换为2D numpy.ndarray 对象。
基本套路¶
求逆¶
矩阵的逆 \(\mathbf{{A}}\) 是矩阵 \(\mathbf{{B}}\) ,以便 \(\mathbf{{AB}}=\mathbf{{I}}\) ,在哪里 \(\mathbf{{I}}\) 是由主对角线下面的单位组成的单位矩阵。通常, \(\mathbf{{B}}\) 表示为 \(\mathbf{{B}}=\mathbf{{A}}^{{-1}}\) 。在SciPy中,NumPy数组A的矩阵逆是使用 linalg.inv (A) ,或使用 A.I 如果 A 是一个矩阵。例如,让我们
然后
下面的示例演示了在SciPy中进行此计算
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,3,5],[2,5,1],[2,3,8]])
>>> A
array([[1, 3, 5],
[2, 5, 1],
[2, 3, 8]])
>>> linalg.inv(A)
array([[-1.48, 0.36, 0.88],
[ 0.56, 0.08, -0.36],
[ 0.16, -0.12, 0.04]])
>>> A.dot(linalg.inv(A)) #double check
array([[ 1.00000000e+00, -1.11022302e-16, -5.55111512e-17],
[ 3.05311332e-16, 1.00000000e+00, 1.87350135e-16],
[ 2.22044605e-16, -1.11022302e-16, 1.00000000e+00]])
解线性系统¶
使用scipy命令可以直接求解线性方程组 linalg.solve 。该命令需要输入矩阵和右侧向量。然后计算解向量。提供了用于输入对称矩阵的选项,这可以在适用时加速处理。例如,假设需要解以下联立方程:
我们可以使用矩阵求逆来求解向量:
但是,最好使用linalg.solve命令,该命令速度更快,数值更稳定。但是,在本例中,它给出的答案与以下示例中所示的答案相同:
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1, 2], [3, 4]])
>>> A
array([[1, 2],
[3, 4]])
>>> b = np.array([[5], [6]])
>>> b
array([[5],
[6]])
>>> linalg.inv(A).dot(b) # slow
array([[-4. ],
[ 4.5]])
>>> A.dot(linalg.inv(A).dot(b)) - b # check
array([[ 8.88178420e-16],
[ 2.66453526e-15]])
>>> np.linalg.solve(A, b) # fast
array([[-4. ],
[ 4.5]])
>>> A.dot(np.linalg.solve(A, b)) - b # check
array([[ 0.],
[ 0.]])
寻找行列式¶
方阵的行列式 \(\mathbf{{A}}\) 通常表示为 \(\left|\mathbf{{A}}\right|\) 是线性代数中经常使用的一个量。假设 \(a_{{ij}}\) 是矩阵的元素 \(\mathbf{{A}}\) 让我们 \(M_{{ij}}=\left|\mathbf{{A}}_{{ij}}\right|\) 是剩余矩阵的行列式,方法是将 \(i^{{\textrm{{th}}}}\) 行和 \(j^{{\textrm{{th}}}}\) 列自 \(\mathbf{{A}}\) 。然后,对于任何行, \(i,\)
这是定义行列式的递归方式,其中基本情况是通过接受 \(1\times1\) 矩阵是唯一的矩阵元素。在SciPy中,行列式可以用以下公式计算 linalg.det 。例如,的行列式
是
在SciPy中,这是按照以下示例中所示进行计算的:
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,2],[3,4]])
>>> A
array([[1, 2],
[3, 4]])
>>> linalg.det(A)
-2.0
计算规范¶
矩阵和向量范数也可以用SciPy计算。对于的Order参数使用不同的参数,可以使用多种范数定义 linalg.norm 。此函数接受秩1(向量)或秩2(矩阵)数组和可选的阶参数(默认值为2)。基于这些输入,计算所请求阶数的向量或矩阵范数。
对于矢量 x ,顺序参数可以是任何实数,包括 inf 或 -inf 。计算的范数是
对于矩阵 \(\mathbf{{A}}\) ,则Norm的唯一有效值是 \(\pm2,\pm1,\) \(\pm\) Inf和‘Fro’(或‘f’)因此,
哪里 \(\sigma_{{i}}\) 是的奇异值 \(\mathbf{{A}}\) 。
示例:
>>> import numpy as np
>>> from scipy import linalg
>>> A=np.array([[1,2],[3,4]])
>>> A
array([[1, 2],
[3, 4]])
>>> linalg.norm(A)
5.4772255750516612
>>> linalg.norm(A,'fro') # frobenius norm is the default
5.4772255750516612
>>> linalg.norm(A,1) # L1 norm (max column sum)
6
>>> linalg.norm(A,-1)
4
>>> linalg.norm(A,np.inf) # L inf norm (max row sum)
7
解线性最小二乘问题与伪逆¶
线性最小二乘问题存在于应用数学的许多分支中。在这个问题中,寻求一组允许模型拟合数据的线性比例系数。特别地,假设数据 \(y_{{i}}\) 与数据相关 \(\mathbf{{x}}_{{i}}\) 通过一组系数 \(c_{{j}}\) 和模型函数 \(f_{{j}}\left(\mathbf{{x}}_{{i}}\right)\) 通过模型
哪里 \(\epsilon_{{i}}\) 表示数据中的不确定性。最小二乘的策略是选取系数 \(c_{{j}}\) 要最小化,请执行以下操作
从理论上讲,全局最小值将在以下情况下出现
或
哪里
什么时候 \(\mathbf{{A^{{H}}A}}\) 是可逆的,那么
哪里 \(\mathbf{{A}}^{{\dagger}}\) 称为的伪逆 \(\mathbf{{A}}.\) 请注意,使用此定义 \(\mathbf{{A}}\) 模型可以写成
该命令 linalg.lstsq 将解决线性最小二乘问题 \(\mathbf{{c}}\) 给定的 \(\mathbf{{A}}\) 和 \(\mathbf{{y}}\) 。此外, linalg.pinv 或 linalg.pinv2 (使用基于奇异值分解的不同方法)将找到 \(\mathbf{{A}}^{{\dagger}}\) 给定的 \(\mathbf{{A}}.\)
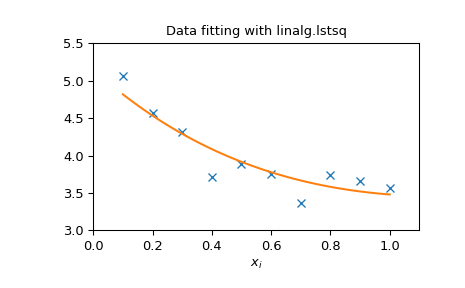
下面的示例和图演示了 linalg.lstsq 和 linalg.pinv 来解决数据拟合问题。下面显示的数据是使用该模型生成的:
哪里 \(x_{{i}}=0.1i\) 为 \(i=1\ldots10\) , \(c_{{1}}=5\) ,以及 \(c_{{2}}=4.\) 将噪波添加到 \(y_{{i}}\) 以及这些系数 \(c_{{1}}\) 和 \(c_{{2}}\) 使用线性最小二乘估计。
>>> import numpy as np
>>> from scipy import linalg
>>> import matplotlib.pyplot as plt
>>> rng = np.random.default_rng()
>>> c1, c2 = 5.0, 2.0
>>> i = np.r_[1:11]
>>> xi = 0.1*i
>>> yi = c1*np.exp(-xi) + c2*xi
>>> zi = yi + 0.05 * np.max(yi) * rng.standard_normal(len(yi))
>>> A = np.c_[np.exp(-xi)[:, np.newaxis], xi[:, np.newaxis]]
>>> c, resid, rank, sigma = linalg.lstsq(A, zi)
>>> xi2 = np.r_[0.1:1.0:100j]
>>> yi2 = c[0]*np.exp(-xi2) + c[1]*xi2
>>> plt.plot(xi,zi,'x',xi2,yi2)
>>> plt.axis([0,1.1,3.0,5.5])
>>> plt.xlabel('$x_i$')
>>> plt.title('Data fitting with linalg.lstsq')
>>> plt.show()
广义逆¶
使用以下命令计算广义逆 linalg.pinv 或 linalg.pinv2 。这两个命令在计算广义逆的方式上有所不同。第一种使用linalg.lstsq算法,第二种使用奇异值分解。让我们 \(\mathbf{{A}}\) 成为一名 \(M\times N\) 矩阵,则如果 \(M>N\) ,广义逆是
而如果 \(M<N\) 矩阵,则广义逆是
在这种情况下 \(M=N\) ,那么
只要 \(\mathbf{{A}}\) 是可逆的。
分解¶
在许多应用中,使用其他表示法分解矩阵是有用的。本网站支持几种分解方式。
特征值和特征向量¶
特征值-特征向量问题是最常用的线性代数运算之一。在一种流行的形式中,特征值-特征向量问题是为了求某个方阵 \(\mathbf{{A}}\) 标量 \(\lambda\) 以及相应的向量 \(\mathbf{{v}}\) ,以便
对于 \(N\times N\) 矩阵,这里有 \(N\) 特征值(不一定是不同的)-(特征)多项式的根
特征向量, \(\mathbf{{v}}\) 有时也称为右特征向量,以将它们与满足以下条件的另一组左特征向量区分开来
或
使用其默认的可选参数,该命令 linalg.eig 退货 \(\lambda\) 和 \(\mathbf{{v}}.\) 但是,它也可以返回 \(\mathbf{{v}}_{{L}}\) 然后就是 \(\lambda\) 本身( linalg.eigvals 返回的只是 \(\lambda\) 也是如此)。
此外, linalg.eig 也可以解决更一般的特征值问题
对于方阵 \(\mathbf{{A}}\) 和 \(\mathbf{{B}}.\) 标准特征值问题是一般特征值问题的一个例子 \(\mathbf{{B}}=\mathbf{{I}}.\) 当广义特征值问题可以求解时,它提供了 \(\mathbf{{A}}\) 作为
哪里 \(\mathbf{{V}}\) 是特征向量到列中的集合,并且 \(\boldsymbol{{\Lambda}}\) 是特征值的对角矩阵。
根据定义,特征向量仅定义为恒定比例因子。在SciPy中,选择特征向量的比例因子,以便 \(\left\Vert \mathbf{{v}}\right\Vert ^{{2}}=\sum_{{i}}v_{{i}}^{{2}}=1.\)
例如,考虑找出矩阵的特征值和特征向量
特征多项式为
这个多项式的根是 \(\mathbf{{A}}\) :
使用原始方程可以找到与每个特征值相对应的特征向量。然后可以找到与这些特征值相关联的特征向量。
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1, 2], [3, 4]])
>>> la, v = linalg.eig(A)
>>> l1, l2 = la
>>> print(l1, l2) # eigenvalues
(-0.3722813232690143+0j) (5.372281323269014+0j)
>>> print(v[:, 0]) # first eigenvector
[-0.82456484 0.56576746]
>>> print(v[:, 1]) # second eigenvector
[-0.41597356 -0.90937671]
>>> print(np.sum(abs(v**2), axis=0)) # eigenvectors are unitary
[1. 1.]
>>> v1 = np.array(v[:, 0]).T
>>> print(linalg.norm(A.dot(v1) - l1*v1)) # check the computation
3.23682852457e-16
奇异值分解¶
奇异值分解(SVD)可以看作是将特征值问题推广到非平方矩阵。让我们 \(\mathbf{{A}}\) 成为一名 \(M\times N\) 包含以下内容的矩阵 \(M\) 和 \(N\) 武断的。矩阵 \(\mathbf{{A}}^{{H}}\mathbf{{A}}\) 和 \(\mathbf{{A}}\mathbf{{A}}^{{H}}\) 是平方厄米特矩阵 1 大小的 \(N\times N\) 和 \(M\times M\) ,分别为。众所周知,平方厄米特矩阵的特征值是实数且非负的。另外呢,最多也就是 \(\min\left(M,N\right)\) 的全等非零本征值 \(\mathbf{{A}}^{{H}}\mathbf{{A}}\) 和 \(\mathbf{{A}}\mathbf{{A}}^{{H}}.\) 将这些正特征值定义为 \(\sigma_{{i}}^{{2}}.\) 这些值的平方根称为奇异值 \(\mathbf{{A}}.\) 的特征向量 \(\mathbf{{A}}^{{H}}\mathbf{{A}}\) 按列收集到一个 \(N\times N\) 酉性 2 矩阵 \(\mathbf{{V}}\) 的特征向量,而其特征向量 \(\mathbf{{A}}\mathbf{{A}}^{{H}}\) 是按酉矩阵中的列收集的 \(\mathbf{{U}}\) ,则将奇异值收集在 \(M\times N\) 零矩阵 \(\mathbf{{\boldsymbol{{\Sigma}}}}\) 其中主对角线条目设置为奇异值。然后
是的奇异值分解 \(\mathbf{{A}}.\) 每个矩阵都有一个奇异值分解。有时,奇异值称为谱 \(\mathbf{{A}}.\) 该命令 linalg.svd 会回来的 \(\mathbf{{U}}\) , \(\mathbf{{V}}^{{H}}\) ,以及 \(\sigma_{{i}}\) 作为奇异值的数组。要获得矩阵,请执行以下操作 \(\boldsymbol{{\Sigma}}\) ,使用 linalg.diagsvd 。下面的示例说明如何使用 linalg.svd :
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,2,3],[4,5,6]])
>>> A
array([[1, 2, 3],
[4, 5, 6]])
>>> M,N = A.shape
>>> U,s,Vh = linalg.svd(A)
>>> Sig = linalg.diagsvd(s,M,N)
>>> U, Vh = U, Vh
>>> U
array([[-0.3863177 , -0.92236578],
[-0.92236578, 0.3863177 ]])
>>> Sig
array([[ 9.508032 , 0. , 0. ],
[ 0. , 0.77286964, 0. ]])
>>> Vh
array([[-0.42866713, -0.56630692, -0.7039467 ],
[ 0.80596391, 0.11238241, -0.58119908],
[ 0.40824829, -0.81649658, 0.40824829]])
>>> U.dot(Sig.dot(Vh)) #check computation
array([[ 1., 2., 3.],
[ 4., 5., 6.]])
鲁分解¶
LU分解为 \(M\times N\) 矩阵 \(\mathbf{{A}}\) 作为
哪里 \(\mathbf{{P}}\) 是一种 \(M\times M\) 排列矩阵(单位矩阵行的排列), \(\mathbf{{L}}\) 是在 \(M\times K\) 下三角形或梯形矩阵( \(K=\min\left(M,N\right)\) ),单位对角线,以及 \(\mathbf{{U}}\) 是上三角形或梯形矩阵。用于此分解的SciPy命令为 linalg.lu 。
这样的分解在求解许多联立方程时通常是有用的,其中左边不变,而右边变了。例如,假设我们要解决
对于许多不同的 \(\mathbf{{b}}_{{i}}\) 。LU分解允许将其编写为
因为 \(\mathbf{{L}}\) 是下三角的,则方程可解为 \(\mathbf{{U}}\mathbf{{x}}_{{i}}\) 最后, \(\mathbf{{x}}_{{i}}\) 非常迅速地使用前置和后置替补。进行保理所用的初始时间 \(\mathbf{{A}}\) 允许在将来非常快速地求解类似的方程组。如果执行LU分解的目的是解线性系统,则命令 linalg.lu_factor 应该在重复应用该命令之后使用 linalg.lu_solve 为每个新的右手边解决系统问题。
乔列斯基分解¶
Cholesky分解是适用于厄米正定矩阵的LU分解的特例。什么时候 \(\mathbf{{A}}=\mathbf{{A}}^{{H}}\) 和 \(\mathbf{{x}}^{{H}}\mathbf{{Ax}}\geq0\) 为了所有人 \(\mathbf{{x}}\) ,然后分解 \(\mathbf{{A}}\) 可以找到,这样就可以
哪里 \(\mathbf{{L}}\) 是下三角形,并且 \(\mathbf{{U}}\) 是上三角形。请注意, \(\mathbf{{L}}=\mathbf{{U}}^{{H}}.\) 该命令 linalg.cholesky 计算Cholesky因式分解。对于使用Cholesky因式分解来求解方程组,还有 linalg.cho_factor 和 linalg.cho_solve 工作方式类似于其LU分解对应物的例程。
QR分解¶
QR分解(有时称为极分解)适用于任何 \(M\times N\) 数组,并找到一个 \(M\times M\) 酉阵 \(\mathbf{{Q}}\) 和一个 \(M\times N\) 上梯形矩阵 \(\mathbf{{R}}\) ,以便
请注意,如果奇异值分解(SVD) \(\mathbf{{A}}\) 是已知的,则可以找到QR分解。
暗示着 \(\mathbf{{Q}}=\mathbf{{U}}\) 和 \(\mathbf{{R}}=\boldsymbol{{\Sigma}}\mathbf{{V}}^{{H}}.\) 然而,请注意,在SciPy中,独立的算法被用来寻找QR和SVD分解。QR分解的命令是 linalg.qr 。
舒尔分解¶
为了一个正方形 \(N\times N\) 矩阵, \(\mathbf{{A}}\) ,Schur分解查找(不一定是唯一的)矩阵 \(\mathbf{{T}}\) 和 \(\mathbf{{Z}}\) ,以便
哪里 \(\mathbf{{Z}}\) 是酉矩阵,并且 \(\mathbf{{T}}\) 是上三角形还是准上三角形,取决于请求的是实舒尔形式还是复舒尔形式。对于真正的舒尔形式,两者都 \(\mathbf{{T}}\) 和 \(\mathbf{{Z}}\) 在以下情况下是实值的 \(\mathbf{{A}}\) 是真实价值的。什么时候 \(\mathbf{{A}}\) 是实值矩阵,则实舒尔形式仅是准上三角形,因为 \(2\times2\) 块从对应于任何复值特征值的主对角线挤出。该命令 linalg.schur 查找Schur分解,而命令 linalg.rsf2csf 转换 \(\mathbf{{T}}\) 和 \(\mathbf{{Z}}\) 从实舒尔形式到复舒尔形式。Schur形式在计算矩阵函数时特别有用。
下面的示例说明了Schur分解:
>>> from scipy import linalg
>>> A = np.mat('[1 3 2; 1 4 5; 2 3 6]')
>>> T, Z = linalg.schur(A)
>>> T1, Z1 = linalg.schur(A, 'complex')
>>> T2, Z2 = linalg.rsf2csf(T, Z)
>>> T
array([[ 9.90012467, 1.78947961, -0.65498528],
[ 0. , 0.54993766, -1.57754789],
[ 0. , 0.51260928, 0.54993766]])
>>> T2
array([[ 9.90012467+0.00000000e+00j, -0.32436598+1.55463542e+00j,
-0.88619748+5.69027615e-01j],
[ 0. +0.00000000e+00j, 0.54993766+8.99258408e-01j,
1.06493862+3.05311332e-16j],
[ 0. +0.00000000e+00j, 0. +0.00000000e+00j,
0.54993766-8.99258408e-01j]])
>>> abs(T1 - T2) # different
array([[ 1.06604538e-14, 2.06969555e+00, 1.69375747e+00], # may vary
[ 0.00000000e+00, 1.33688556e-15, 4.74146496e-01],
[ 0.00000000e+00, 0.00000000e+00, 1.13220977e-15]])
>>> abs(Z1 - Z2) # different
array([[ 0.06833781, 0.88091091, 0.79568503], # may vary
[ 0.11857169, 0.44491892, 0.99594171],
[ 0.12624999, 0.60264117, 0.77257633]])
>>> T, Z, T1, Z1, T2, Z2 = map(np.mat,(T,Z,T1,Z1,T2,Z2))
>>> abs(A - Z*T*Z.H) # same
matrix([[ 5.55111512e-16, 1.77635684e-15, 2.22044605e-15],
[ 0.00000000e+00, 3.99680289e-15, 8.88178420e-16],
[ 1.11022302e-15, 4.44089210e-16, 3.55271368e-15]])
>>> abs(A - Z1*T1*Z1.H) # same
matrix([[ 4.26993904e-15, 6.21793362e-15, 8.00007092e-15],
[ 5.77945386e-15, 6.21798014e-15, 1.06653681e-14],
[ 7.16681444e-15, 8.90271058e-15, 1.77635764e-14]])
>>> abs(A - Z2*T2*Z2.H) # same
matrix([[ 6.02594127e-16, 1.77648931e-15, 2.22506907e-15],
[ 2.46275555e-16, 3.99684548e-15, 8.91642616e-16],
[ 8.88225111e-16, 8.88312432e-16, 4.44104848e-15]])
插值分解¶
scipy.linalg.interpolative 包含计算矩阵的插值分解(ID)的例程。对于矩阵, \(A \in \mathbb{{C}}^{{m \times n}}\) 级别的 \(k \leq \min \{{ m, n \}}\) 这是一种因式分解
哪里 \(\Pi = [\Pi_{{1}}, \Pi_{{2}}]\) 是一个置换矩阵,它具有 \(\Pi_{{1}} \in \{{ 0, 1 \}}^{{n \times k}}\) ,即, \(A \Pi_{{2}} = A \Pi_{{1}} T\) 。这可以等效地写成 \(A = BP\) ,在哪里 \(B = A \Pi_{{1}}\) 和 \(P = [I, T] \Pi^{{\mathsf{{T}}}}\) 是不是 骨架 和 插值矩阵 ,分别为。
参见
scipy.linalg.interpolative -了解更多信息。
矩阵函数¶
考虑一下函数 \(f\left(x\right)\) 用泰勒级数展开
可以使用该方阵的泰勒级数来定义矩阵函数 \(\mathbf{{A}}\) 作为
虽然这是矩阵函数的有用表示形式,但它很少是计算矩阵函数的最佳方法。
指数和对数函数¶
矩阵指数是比较常见的矩阵函数之一。实现矩阵指数的首选方法是使用缩放和Padé近似 \(e^{{x}}\) 。此算法实现为 linalg.expm 。
矩阵指数的逆是定义为矩阵指数的逆的矩阵对数:
矩阵对数可以用以下公式获得 linalg.logm 。
三角函数¶
三角函数, \(\sin\) , \(\cos\) ,以及 \(\tan\) 中的矩阵实现 linalg.sinm , linalg.cosm ,以及 linalg.tanm ,分别为。矩阵正弦和余弦可以使用欧拉恒等式定义为
切线是
因此矩阵的切线定义为
双曲三角函数¶
双曲三角函数, \(\sinh\) , \(\cosh\) ,以及 \(\tanh\) ,也可以使用熟悉的定义为矩阵定义:
可以使用以下命令找到这些矩阵函数 linalg.sinhm , linalg.coshm ,以及 linalg.tanhm 。
任意函数¶
最后,任何接受一个复数并返回一个复数的任意函数都可以使用以下命令作为矩阵函数调用 linalg.funm 。此命令接受矩阵和任意Python函数。然后,它实现了Golub和Van Loan的“矩阵计算”一书中的算法,使用Schur分解计算应用于矩阵的函数。请注意, 该函数需要接受复数 作为输入以便使用此算法。例如,下面的代码计算应用于矩阵的零阶贝塞尔函数。
>>> from scipy import special, linalg
>>> rng = np.random.default_rng()
>>> A = rng.random((3, 3))
>>> B = linalg.funm(A, lambda x: special.jv(0, x))
>>> A
array([[0.06369197, 0.90647174, 0.98024544],
[0.68752227, 0.5604377 , 0.49142032],
[0.86754578, 0.9746787 , 0.37932682]])
>>> B
array([[ 0.6929219 , -0.29728805, -0.15930896],
[-0.16226043, 0.71967826, -0.22709386],
[-0.19945564, -0.33379957, 0.70259022]])
>>> linalg.eigvals(A)
array([ 1.94835336+0.j, -0.72219681+0.j, -0.22270006+0.j])
>>> special.jv(0, linalg.eigvals(A))
array([0.25375345+0.j, 0.87379738+0.j, 0.98763955+0.j])
>>> linalg.eigvals(B)
array([0.25375345+0.j, 0.87379738+0.j, 0.98763955+0.j])
请注意,根据矩阵分析函数的定义,贝塞尔函数是如何作用于矩阵特征值的。
特殊矩阵¶
SciPy和NumPy提供了几个用于创建工程和科学中经常使用的特殊矩阵的函数。
类型 |
功能 |
描述 |
|---|---|---|
挡路对角线 |
根据提供的数组创建挡路对角线矩阵。 |
|
循环数 |
创建循环矩阵。 |
|
同伴 |
创建一个同伴矩阵。 |
|
卷积 |
创建卷积矩阵。 |
|
离散傅立叶 |
创建离散傅立叶变换矩阵。 |
|
菲德勒 |
创建对称的费德勒矩阵。 |
|
“菲德勒伙伴”(Fiedler Companion) |
创建一个菲德勒同伴矩阵。 |
|
阿达玛 |
创建Hadamard矩阵。 |
|
汉克尔 |
创建汉克尔矩阵。 |
|
赫尔默特 |
创建赫尔默特矩阵。 |
|
希尔伯特 |
创建一个希尔伯特矩阵。 |
|
逆希尔伯特 |
创建希尔伯特矩阵的逆。 |
|
莱斯利 |
创建莱斯利矩阵。 |
|
帕斯卡 |
创建一个帕斯卡矩阵。 |
|
逆帕斯卡 |
创建一个帕斯卡矩阵的逆矩阵。 |
|
托普利茨 |
创建Toeplitz矩阵。 |
|
范德蒙德 |
创建范德蒙德矩阵。 |
有关这些函数的用法示例,请参见它们各自的文档字符串。