优化 (scipy.optimize )¶
目录
这个 scipy.optimize 软件包提供了几种常用的优化算法。详细列表如下: scipy.optimize (也可以通过以下方式找到 help(scipy.optimize) )。
多元标量函数的无约束最小化 (minimize )¶
这个 minimize 函数为多变量标量函数的无约束和约束最小化算法提供了通用接口 scipy.optimize 。为了演示最小化函数,考虑最小化的Rosenbrock函数的问题 \(N\) 变量:
此函数的最小值为0,这是在以下情况下实现的 \(x_{{i}}=1.\)
请注意,Rosenbrock函数及其导数包含在 scipy.optimize 。以下各节中显示的实现提供了如何定义目标函数及其雅可比函数和赫斯函数的示例。
内尔德-米德单纯形算法 (method='Nelder-Mead' )¶
在下面的示例中, minimize 例程与 Nelder-Mead 单纯形算法(通过 method 参数):
>>> import numpy as np
>>> from scipy.optimize import minimize
>>> def rosen(x):
... """The Rosenbrock function"""
... return sum(100.0*(x[1:]-x[:-1]**2.0)**2.0 + (1-x[:-1])**2.0)
>>> x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2])
>>> res = minimize(rosen, x0, method='nelder-mead',
... options={'xatol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 339
Function evaluations: 571
>>> print(res.x)
[1. 1. 1. 1. 1.]
单纯形算法可能是最小化行为相当良好的函数的最简单方法。它只需要函数求值,对于简单的极小化问题是一个很好的选择。但是,由于它不使用任何渐变求值,因此可能需要更长时间才能找到最小值。
另一种只需调用函数即可找到最小值的优化算法是 鲍威尔 的方法可通过设置 method='powell' 在……里面 minimize 。
Broyden-Fletcher-Goldfarb-Shanno算法 (method='BFGS' )¶
为了更快地收敛到解,此例程使用目标函数的梯度。如果梯度不是由用户给出的,则使用第一差值来估计它。Broyden-Fletcher-Goldfarb-Shanno(BFGS)方法通常比单纯形算法需要更少的函数调用,即使在必须估计梯度的情况下也是如此。
为了演示该算法,再次使用了Rosenbrock函数。Rosenbrock函数的梯度是向量:
这个表达式对内部导数是有效的。特殊情况有
计算此渐变的Python函数由以下代码段构造:
>>> def rosen_der(x):
... xm = x[1:-1]
... xm_m1 = x[:-2]
... xm_p1 = x[2:]
... der = np.zeros_like(x)
... der[1:-1] = 200*(xm-xm_m1**2) - 400*(xm_p1 - xm**2)*xm - 2*(1-xm)
... der[0] = -400*x[0]*(x[1]-x[0]**2) - 2*(1-x[0])
... der[-1] = 200*(x[-1]-x[-2]**2)
... return der
此渐变信息在 minimize 函数通过 jac 参数,如下所示。
>>> res = minimize(rosen, x0, method='BFGS', jac=rosen_der,
... options={'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 51 # may vary
Function evaluations: 63
Gradient evaluations: 63
>>> res.x
array([1., 1., 1., 1., 1.])
牛顿共轭梯度算法 (method='Newton-CG' )¶
牛顿-共轭梯度算法是一种改进的牛顿算法,它使用共轭梯度算法来(近似)反演局部海森 [NW]. 牛顿的方法基于将函数局部拟合为二次型:
哪里 \(\mathbf{{H}}\left(\mathbf{{x}}_{{0}}\right)\) 是一个二阶导数矩阵(黑森矩阵)。如果黑森函数是正定的,则可以通过将二次型的梯度设置为零来找到该函数的局部最小值,从而导致
用共轭梯度法求出黑森方程的逆。下面给出了使用该方法最小化Rosenbrock函数的示例。为了充分利用牛顿-CG方法,必须提供一个计算黑森函数的函数。不需要构造Hessian矩阵本身,只需要将Hessian矩阵与任意向量的乘积的向量用于最小化例程。结果,用户可以提供计算海森矩阵的函数,或者提供计算海森矩阵与任意向量的乘积的函数。
完整的黑森语示例:¶
Rosenbrock函数的黑森公式是
如果 \(i,j\in\left[1,N-2\right]\) 使用 \(i,j\in\left[0,N-1\right]\) 定义 \(N\times N\) 矩阵。矩阵的其他非零项是
例如,当黑森人 \(N=5\) 是
下面的示例显示了计算此海森函数的代码以及使用牛顿-CG方法最小化函数的代码:
>>> def rosen_hess(x):
... x = np.asarray(x)
... H = np.diag(-400*x[:-1],1) - np.diag(400*x[:-1],-1)
... diagonal = np.zeros_like(x)
... diagonal[0] = 1200*x[0]**2-400*x[1]+2
... diagonal[-1] = 200
... diagonal[1:-1] = 202 + 1200*x[1:-1]**2 - 400*x[2:]
... H = H + np.diag(diagonal)
... return H
>>> res = minimize(rosen, x0, method='Newton-CG',
... jac=rosen_der, hess=rosen_hess,
... options={'xtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 19 # may vary
Function evaluations: 22
Gradient evaluations: 19
Hessian evaluations: 19
>>> res.x
array([1., 1., 1., 1., 1.])
Hessian产品示例:¶
对于较大的最小化问题,存储整个海森矩阵可能会消耗相当多的时间和内存。牛顿-CG算法只需要黑森乘以任意向量的乘积。因此,用户可以提供代码来计算此产品,而不是提供完整的海森代码,方法是给出 hess 函数,该函数将最小化向量作为第一个参数,将任意向量作为第二个参数(以及传递给要最小化的函数的额外参数)。如果可能,将牛顿-CG与黑森乘积选项一起使用可能是最小化函数的最快方法。
在这种情况下,Rosenbrock Hessian与任意向量的乘积不难计算。如果 \(\mathbf{{p}}\) 是任意向量,那么 \(\mathbf{{H}}\left(\mathbf{{x}}\right)\mathbf{{p}}\) 具有元素:
使用此黑森乘积最小化Rosenbrock函数的代码 minimize 如下所示:
>>> def rosen_hess_p(x, p):
... x = np.asarray(x)
... Hp = np.zeros_like(x)
... Hp[0] = (1200*x[0]**2 - 400*x[1] + 2)*p[0] - 400*x[0]*p[1]
... Hp[1:-1] = -400*x[:-2]*p[:-2]+(202+1200*x[1:-1]**2-400*x[2:])*p[1:-1] \
... -400*x[1:-1]*p[2:]
... Hp[-1] = -400*x[-2]*p[-2] + 200*p[-1]
... return Hp
>>> res = minimize(rosen, x0, method='Newton-CG',
... jac=rosen_der, hessp=rosen_hess_p,
... options={'xtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20 # may vary
Function evaluations: 23
Gradient evaluations: 20
Hessian evaluations: 44
>>> res.x
array([1., 1., 1., 1., 1.])
根据 [NW] 第170页 Newton-CG 当Hessian是病态的时,由于该方法在这些情况下提供的搜索方向的质量较差,算法可能效率低下。该方法 trust-ncg 根据作者的说法,它更有效地处理了这种有问题的情况,下面将对其进行描述。
信赖域牛顿共轭梯度算法 (method='trust-ncg' )¶
这个 Newton-CG 方法是一种线搜索方法:它找到一个搜索方向,使函数的二次逼近最小化,然后使用线搜索算法在该方向上找到(几乎)最优的步长。另一种方法是,首先确定步长限制 \(\Delta\) 然后找出最优的步长 \(\mathbf{{p}}\) 在给定的信任半径内,通过求解以下二次子问题:
然后更新解决方案 \(\mathbf{{x}}_{{k+1}} = \mathbf{{x}}_{{k}} + \mathbf{{p}}\) 和信任半径 \(\Delta\) 根据二次模型与实函数的吻合程度进行调整。这一类方法称为信赖域方法。这个 trust-ncg 算法是一种使用共轭梯度算法求解信赖域子问题的信赖域方法 [NW].
完整的黑森语示例:¶
>>> res = minimize(rosen, x0, method='trust-ncg',
... jac=rosen_der, hess=rosen_hess,
... options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20 # may vary
Function evaluations: 21
Gradient evaluations: 20
Hessian evaluations: 19
>>> res.x
array([1., 1., 1., 1., 1.])
Hessian产品示例:¶
>>> res = minimize(rosen, x0, method='trust-ncg',
... jac=rosen_der, hessp=rosen_hess_p,
... options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20 # may vary
Function evaluations: 21
Gradient evaluations: 20
Hessian evaluations: 0
>>> res.x
array([1., 1., 1., 1., 1.])
信赖域截断的广义Lanczos/共轭梯度算法 (method='trust-krylov' )¶
类似于 trust-ncg 方法时, trust-krylov 该方法是一种适合于大规模问题的方法,因为它只利用矩阵向量积作为线性算子。它能更精确地解决二次子问题。 trust-ncg 方法。
此方法包装 [TRLIB] 实施 [GLTR] 精确求解限制在截断Krylov子空间上的信赖域子问题的方法。对于不确定的问题,通常更好地使用这种方法,因为它减少了非线性迭代的次数,代价是每个子问题求解的矩阵向量积比 trust-ncg 方法。
完整的黑森语示例:¶
>>> res = minimize(rosen, x0, method='trust-krylov',
... jac=rosen_der, hess=rosen_hess,
... options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 19 # may vary
Function evaluations: 20
Gradient evaluations: 20
Hessian evaluations: 18
>>> res.x
array([1., 1., 1., 1., 1.])
Hessian产品示例:¶
>>> res = minimize(rosen, x0, method='trust-krylov',
... jac=rosen_der, hessp=rosen_hess_p,
... options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 19 # may vary
Function evaluations: 20
Gradient evaluations: 20
Hessian evaluations: 0
>>> res.x
array([1., 1., 1., 1., 1.])
- TRLIB
F.Lender,C.Kirches,A.Potschka:“trlib:迭代求解信赖域问题的GLTR方法的无向量实现”, arXiv:1611.04718
- GLTR
古尔德,S.Lucidi,M.Roman,P.Toint:“使用Lanczos方法解决信任域子问题”,SIAM J.Optim,9(2),504-525,(1999)。 DOI:10.1137/S1052623497322735
信赖域近似精确算法 (method='trust-exact' )¶
所有方法 Newton-CG , trust-ncg 和 trust-krylov 适用于处理大规模问题(具有数千个变量的问题)。这是因为共轭梯度算法在没有显式Hessian分解的情况下,通过迭代近似求解信赖域子问题(或求逆Hessian)。由于只需要Hessian与任意向量的乘积,该算法特别适合于处理稀疏Hessian,对于这些稀疏问题,存储需求很低,并且节省了大量的时间。
对于海森函数的存储和因式分解代价不是关键的中型问题,通过几乎精确地求解信赖域子问题,可以在较少的迭代次数内得到解。为此,对每个二次子问题迭代求解一定的非线性方程。 [CGT]. 此解通常需要3或4个海森矩阵的Cholesky分解。结果表明,与其他信赖域方法相比,该方法收敛的迭代次数更少,对目标函数的求值也更少。此算法不支持Hessian产品选项。下面是使用Rosenbrock函数的示例:
>>> res = minimize(rosen, x0, method='trust-exact',
... jac=rosen_der, hess=rosen_hess,
... options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 13 # may vary
Function evaluations: 14
Gradient evaluations: 13
Hessian evaluations: 14
>>> res.x
array([1., 1., 1., 1., 1.])
多元标量函数的约束最小化 (minimize )¶
这个 minimize 函数提供了约束最小化的算法,即 'trust-constr' , 'SLSQP' 和 'COBYLA' 。它们要求使用略微不同的结构定义约束。该方法 'trust-constr' 要求将约束定义为对象序列 LinearConstraint 和 NonlinearConstraint 。方法: 'SLSQP' 和 'COBYLA' 另一方面,需要将约束定义为带有键的字典序列 type , fun 和 jac 。
例如,让我们考虑Rosenbrock函数的约束最小化:
该优化问题有唯一解 \([x_0, x_1] = [0.4149,~ 0.1701]\) ,它只有第一个和第四个约束处于活动状态。
信赖域约束算法 (method='trust-constr' )¶
信赖域约束方法处理以下形式的约束最小化问题:
什么时候 \(c^l_j = c^u_j\) 该方法读取 \(j\) -th约束作为相等约束,并相应地处理它。此外,还可以通过将上限或下限设置为来指定单边约束 np.inf 有合适的标志。
该实现基于 [EQSQP] 对于等式约束问题和 [TRIP] 用于具有不等式约束的问题。这两种算法都是适用于大规模问题的信赖域算法。
定义边界约束:¶
约束条件 \(0 \leq x_0 \leq 1\) 和 \(-0.5 \leq x_1 \leq 2.0\) 是使用 Bounds 对象。
>>> from scipy.optimize import Bounds
>>> bounds = Bounds([0, -0.5], [1.0, 2.0])
定义线性约束:¶
约束条件 \(x_0 + 2 x_1 \leq 1\) 和 \(2 x_0 + x_1 = 1\) 可以在线性约束标准格式中写入:
并使用 LinearConstraint 对象。
>>> from scipy.optimize import LinearConstraint
>>> linear_constraint = LinearConstraint([[1, 2], [2, 1]], [-np.inf, 1], [1, 1])
定义非线性约束:¶
非线性约束:
使用雅可比矩阵:
以及黑森人的线性组合:
是使用 NonlinearConstraint 对象。
>>> def cons_f(x):
... return [x[0]**2 + x[1], x[0]**2 - x[1]]
>>> def cons_J(x):
... return [[2*x[0], 1], [2*x[0], -1]]
>>> def cons_H(x, v):
... return v[0]*np.array([[2, 0], [0, 0]]) + v[1]*np.array([[2, 0], [0, 0]])
>>> from scipy.optimize import NonlinearConstraint
>>> nonlinear_constraint = NonlinearConstraint(cons_f, -np.inf, 1, jac=cons_J, hess=cons_H)
或者,也可以定义黑森语 \(H(x, v)\) 作为稀疏矩阵,
>>> from scipy.sparse import csc_matrix
>>> def cons_H_sparse(x, v):
... return v[0]*csc_matrix([[2, 0], [0, 0]]) + v[1]*csc_matrix([[2, 0], [0, 0]])
>>> nonlinear_constraint = NonlinearConstraint(cons_f, -np.inf, 1,
... jac=cons_J, hess=cons_H_sparse)
或作为 LinearOperator 对象。
>>> from scipy.sparse.linalg import LinearOperator
>>> def cons_H_linear_operator(x, v):
... def matvec(p):
... return np.array([p[0]*2*(v[0]+v[1]), 0])
... return LinearOperator((2, 2), matvec=matvec)
>>> nonlinear_constraint = NonlinearConstraint(cons_f, -np.inf, 1,
... jac=cons_J, hess=cons_H_linear_operator)
当对黑森的评价 \(H(x, v)\) 难以实现或在计算上不可行,则可以使用 HessianUpdateStrategy 。目前可用的策略有 BFGS 和 SR1 。
>>> from scipy.optimize import BFGS
>>> nonlinear_constraint = NonlinearConstraint(cons_f, -np.inf, 1, jac=cons_J, hess=BFGS())
或者,黑森可以用有限差分来近似。
>>> nonlinear_constraint = NonlinearConstraint(cons_f, -np.inf, 1, jac=cons_J, hess='2-point')
约束的雅可比也可以用有限差分近似。但是,在这种情况下,不能使用有限差计算海森,而需要由用户提供或使用 HessianUpdateStrategy 。
>>> nonlinear_constraint = NonlinearConstraint(cons_f, -np.inf, 1, jac='2-point', hess=BFGS())
解决优化问题:¶
使用以下方法解决优化问题:
>>> x0 = np.array([0.5, 0])
>>> res = minimize(rosen, x0, method='trust-constr', jac=rosen_der, hess=rosen_hess,
... constraints=[linear_constraint, nonlinear_constraint],
... options={'verbose': 1}, bounds=bounds)
# may vary
`gtol` termination condition is satisfied.
Number of iterations: 12, function evaluations: 8, CG iterations: 7, optimality: 2.99e-09, constraint violation: 1.11e-16, execution time: 0.016 s.
>>> print(res.x)
[0.41494531 0.17010937]
当需要时,目标函数Hessian可以使用 LinearOperator 对象,
>>> def rosen_hess_linop(x):
... def matvec(p):
... return rosen_hess_p(x, p)
... return LinearOperator((2, 2), matvec=matvec)
>>> res = minimize(rosen, x0, method='trust-constr', jac=rosen_der, hess=rosen_hess_linop,
... constraints=[linear_constraint, nonlinear_constraint],
... options={'verbose': 1}, bounds=bounds)
# may vary
`gtol` termination condition is satisfied.
Number of iterations: 12, function evaluations: 8, CG iterations: 7, optimality: 2.99e-09, constraint violation: 1.11e-16, execution time: 0.018 s.
>>> print(res.x)
[0.41494531 0.17010937]
或通过参数的黑森向量积 hessp 。
>>> res = minimize(rosen, x0, method='trust-constr', jac=rosen_der, hessp=rosen_hess_p,
... constraints=[linear_constraint, nonlinear_constraint],
... options={'verbose': 1}, bounds=bounds)
# may vary
`gtol` termination condition is satisfied.
Number of iterations: 12, function evaluations: 8, CG iterations: 7, optimality: 2.99e-09, constraint violation: 1.11e-16, execution time: 0.018 s.
>>> print(res.x)
[0.41494531 0.17010937]
或者,可以近似目标函数的一阶和二阶导数。例如,黑森可以用以下公式近似 SR1 拟牛顿近似与有限差分梯度。
>>> from scipy.optimize import SR1
>>> res = minimize(rosen, x0, method='trust-constr', jac="2-point", hess=SR1(),
... constraints=[linear_constraint, nonlinear_constraint],
... options={'verbose': 1}, bounds=bounds)
# may vary
`gtol` termination condition is satisfied.
Number of iterations: 12, function evaluations: 24, CG iterations: 7, optimality: 4.48e-09, constraint violation: 0.00e+00, execution time: 0.016 s.
>>> print(res.x)
[0.41494531 0.17010937]
序列最小二乘规划(SLSQP)算法 (method='SLSQP' )¶
SLSQP方法处理以下形式的约束最小化问题:
哪里 \(\mathcal{{E}}\) 或 \(\mathcal{{I}}\) 是包含相等和不等约束的索引集。
线性约束和非线性约束都定义为带键的字典 type , fun 和 jac 。
>>> ineq_cons = {'type': 'ineq',
... 'fun' : lambda x: np.array([1 - x[0] - 2*x[1],
... 1 - x[0]**2 - x[1],
... 1 - x[0]**2 + x[1]]),
... 'jac' : lambda x: np.array([[-1.0, -2.0],
... [-2*x[0], -1.0],
... [-2*x[0], 1.0]])}
>>> eq_cons = {'type': 'eq',
... 'fun' : lambda x: np.array([2*x[0] + x[1] - 1]),
... 'jac' : lambda x: np.array([2.0, 1.0])}
并通过以下方式解决优化问题:
>>> x0 = np.array([0.5, 0])
>>> res = minimize(rosen, x0, method='SLSQP', jac=rosen_der,
... constraints=[eq_cons, ineq_cons], options={'ftol': 1e-9, 'disp': True},
... bounds=bounds)
# may vary
Optimization terminated successfully. (Exit mode 0)
Current function value: 0.342717574857755
Iterations: 5
Function evaluations: 6
Gradient evaluations: 5
>>> print(res.x)
[0.41494475 0.1701105 ]
该方法的大多数可用选项 'trust-constr' 不适用于 'SLSQP' 。
全局优化¶
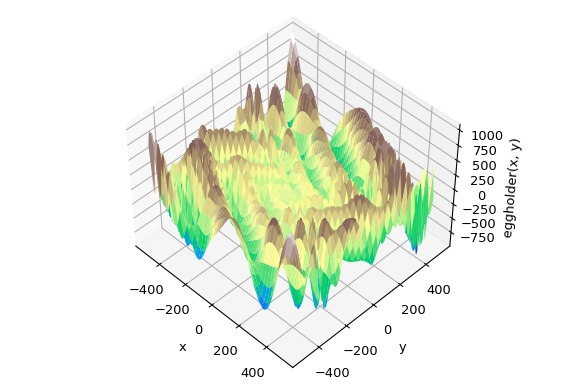
全局优化的目标是在给定的边界内,在可能存在许多局部极小值的情况下,找到函数的全局最小值。通常,全局最小化器在使用局部最小化器的同时高效地搜索参数空间(例如, minimize )在引擎盖下。SciPy包含许多优秀的全局优化器。在这里,我们将在相同的目标函数上使用这些函数,即(恰当地命名) eggholder 功能::
>>> def eggholder(x):
... return (-(x[1] + 47) * np.sin(np.sqrt(abs(x[0]/2 + (x[1] + 47))))
... -x[0] * np.sin(np.sqrt(abs(x[0] - (x[1] + 47)))))
>>> bounds = [(-512, 512), (-512, 512)]
此函数看起来像一个蛋盒::
>>> import matplotlib.pyplot as plt
>>> from mpl_toolkits.mplot3d import Axes3D
>>> x = np.arange(-512, 513)
>>> y = np.arange(-512, 513)
>>> xgrid, ygrid = np.meshgrid(x, y)
>>> xy = np.stack([xgrid, ygrid])
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111, projection='3d')
>>> ax.view_init(45, -45)
>>> ax.plot_surface(xgrid, ygrid, eggholder(xy), cmap='terrain')
>>> ax.set_xlabel('x')
>>> ax.set_ylabel('y')
>>> ax.set_zlabel('eggholder(x, y)')
>>> plt.show()
现在我们使用全局优化器来获得最小值和最小函数值。我们将结果存储在字典中,以便稍后可以比较不同的优化结果。
>>> from scipy import optimize
>>> results = dict()
>>> results['shgo'] = optimize.shgo(eggholder, bounds)
>>> results['shgo']
fun: -935.3379515604197 # may vary
funl: array([-935.33795156])
message: 'Optimization terminated successfully.'
nfev: 42
nit: 2
nlfev: 37
nlhev: 0
nljev: 9
success: True
x: array([439.48096952, 453.97740589])
xl: array([[439.48096952, 453.97740589]])
>>> results['DA'] = optimize.dual_annealing(eggholder, bounds)
>>> results['DA']
fun: -956.9182316237413 # may vary
message: ['Maximum number of iteration reached']
nfev: 4091
nhev: 0
nit: 1000
njev: 0
x: array([482.35324114, 432.87892901])
所有优化器都返回一个 OptimizeResult ,它除了包含解决方案之外,还包含有关函数求值次数、优化是否成功等信息。为简洁起见,我们不会显示其他优化器的全部输出::
>>> results['DE'] = optimize.differential_evolution(eggholder, bounds)
>>> results['BH'] = optimize.basinhopping(eggholder, bounds)
shgo 有第二个方法,它返回所有局部最小值,而不仅仅是它认为的全局最小值::
>>> results['shgo_sobol'] = optimize.shgo(eggholder, bounds, n=200, iters=5,
... sampling_method='sobol')
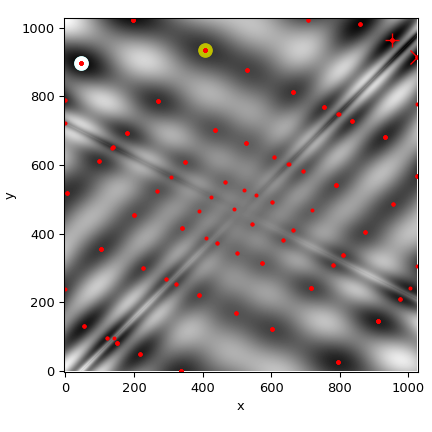
现在,我们将在函数的热图上绘制所有找到的最小值::
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> im = ax.imshow(eggholder(xy), interpolation='bilinear', origin='lower',
... cmap='gray')
>>> ax.set_xlabel('x')
>>> ax.set_ylabel('y')
>>>
>>> def plot_point(res, marker='o', color=None):
... ax.plot(512+res.x[0], 512+res.x[1], marker=marker, color=color, ms=10)
>>> plot_point(results['BH'], color='y') # basinhopping - yellow
>>> plot_point(results['DE'], color='c') # differential_evolution - cyan
>>> plot_point(results['DA'], color='w') # dual_annealing. - white
>>> # SHGO produces multiple minima, plot them all (with a smaller marker size)
>>> plot_point(results['shgo'], color='r', marker='+')
>>> plot_point(results['shgo_sobol'], color='r', marker='x')
>>> for i in range(results['shgo_sobol'].xl.shape[0]):
... ax.plot(512 + results['shgo_sobol'].xl[i, 0],
... 512 + results['shgo_sobol'].xl[i, 1],
... 'ro', ms=2)
>>> ax.set_xlim([-4, 514*2])
>>> ax.set_ylim([-4, 514*2])
>>> plt.show()
最小二乘极小化 (least_squares )¶
SciPy能够求解鲁棒有界约束的非线性最小二乘问题:
这里 \(f_i(\mathbf{{x}})\) 是来自 \(\mathbb{{R}}^n\) 至 \(\mathbb{{R}}\) ,我们将它们称为残余物。标量值函数的用途 \(\rho(\cdot)\) 是为了减少离群点残差的影响,增强解的稳健性,我们称其为损失函数。线性损失函数给出了一个标准的最小二乘问题。此外,以下限和上限的形式对某些 \(x_j\) 是被允许的。
所有特定于最小二乘最小化的方法都利用 \(m \times n\) 称为雅可比的偏导数矩阵,定义为 \(J_{{ij}} = \partial f_i / \partial x_j\) 。强烈建议您解析计算此矩阵并将其传递给 least_squares 否则,它将通过有限差分来估计,这需要大量的额外时间,并且在困难的情况下可能非常不准确。
功能 least_squares 可用于拟合函数 \(\varphi(t; \mathbf{{x}})\) 到经验数据 \(\{{(t_i, y_i), i = 0, \ldots, m-1\}}\) 。要做到这一点,只需将残差预计算为 \(f_i(\mathbf{{x}}) = w_i (\varphi(t_i; \mathbf{{x}}) - y_i)\) ,在哪里 \(w_i\) 是分配给每个观测值的权重。
解决配件问题的示例¶
这里我们考虑一种酶反应。 1. 有11个残差被定义为
哪里 \(y_i\) 是测量值和 \(u_i\) 是自变量的值。参数的未知向量为 \(\mathbf{{x}} = (x_0, x_1, x_2, x_3)^T\) 。如前所述,建议以封闭形式计算雅可比矩阵:
中定义的“硬”起点 2. 为了找到物理上有意义的解,避免潜在的被零除,并确保收敛到全局最小值,我们施加了约束 \(0 \leq x_j \leq 100, j = 0, 1, 2, 3\) 。
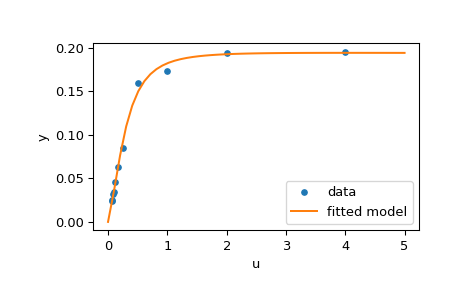
下面的代码实现了以下参数的最小二乘估计 \(\mathbf{{x}}\) 最后绘制原始数据和拟合后的模型函数:
>>> from scipy.optimize import least_squares
>>> def model(x, u):
... return x[0] * (u ** 2 + x[1] * u) / (u ** 2 + x[2] * u + x[3])
>>> def fun(x, u, y):
... return model(x, u) - y
>>> def jac(x, u, y):
... J = np.empty((u.size, x.size))
... den = u ** 2 + x[2] * u + x[3]
... num = u ** 2 + x[1] * u
... J[:, 0] = num / den
... J[:, 1] = x[0] * u / den
... J[:, 2] = -x[0] * num * u / den ** 2
... J[:, 3] = -x[0] * num / den ** 2
... return J
>>> u = np.array([4.0, 2.0, 1.0, 5.0e-1, 2.5e-1, 1.67e-1, 1.25e-1, 1.0e-1,
... 8.33e-2, 7.14e-2, 6.25e-2])
>>> y = np.array([1.957e-1, 1.947e-1, 1.735e-1, 1.6e-1, 8.44e-2, 6.27e-2,
... 4.56e-2, 3.42e-2, 3.23e-2, 2.35e-2, 2.46e-2])
>>> x0 = np.array([2.5, 3.9, 4.15, 3.9])
>>> res = least_squares(fun, x0, jac=jac, bounds=(0, 100), args=(u, y), verbose=1)
# may vary
`ftol` termination condition is satisfied.
Function evaluations 130, initial cost 4.4383e+00, final cost 1.5375e-04, first-order optimality 4.92e-08.
>>> res.x
array([ 0.19280596, 0.19130423, 0.12306063, 0.13607247])
>>> import matplotlib.pyplot as plt
>>> u_test = np.linspace(0, 5)
>>> y_test = model(res.x, u_test)
>>> plt.plot(u, y, 'o', markersize=4, label='data')
>>> plt.plot(u_test, y_test, label='fitted model')
>>> plt.xlabel("u")
>>> plt.ylabel("y")
>>> plt.legend(loc='lower right')
>>> plt.show()
进一步的例子¶
下面的三个交互示例说明了 least_squares 更详细地说。
Large-scale bundle adjustment in scipy 演示了
least_squares以及如何有效地计算稀疏雅可比的有限差分近似。Robust nonlinear regression in scipy 演示如何在非线性回归中使用稳健的损失函数处理异常值。
Solving a discrete boundary-value problem in scipy 研究如何求解大型方程组,并使用界限来实现所需的解的性质。
有关实现背后的数学算法的详细信息,请参阅 least_squares 。
一元函数极小化 (minimize_scalar )¶
通常只需要单变量函数的最小值(即,接受标量作为输入的函数)。在这些情况下,已经开发了其他可以更快工作的优化技术。可从 minimize_scalar 函数,提出了几种算法。
无约束极小化 (method='brent' )¶
实际上,有两种方法可以用来最小化单变量函数: brent 和 golden ,但是 golden 仅用于学术目的,不应使用。这两个选项可以分别通过 method 中的参数 minimize_scalar 。这个 brent 方法使用布伦特算法来定位最小值。最理想的情况是,括号( bracket 参数)应包含所需的最小值。括号是一个三元组 \(\left( a, b, c \right)\) 这样一来, \(f \left( a \right) > f \left( b \right) < f \left( c \right)\) 和 \(a < b < c\) 。如果没有给出这一点,那么或者可以选择两个起始点,并使用简单的行进算法从这些点找到一个括号。如果不提供这两个起点, 0 和 1 将被使用(对于您的函数,这可能不是正确的选择,并导致返回意外的最小值)。
下面是一个示例:
>>> from scipy.optimize import minimize_scalar
>>> f = lambda x: (x - 2) * (x + 1)**2
>>> res = minimize_scalar(f, method='brent')
>>> print(res.x)
1.0
有界极小化 (method='bounded' )¶
通常,在最小化发生之前,可以在解空间上放置一些约束。这个 bounded 中的方法 minimize_scalar 是为标量函数提供基本区间约束的约束最小化过程的示例。间隔约束允许最小化仅在两个固定端点之间进行,这两个固定端点使用强制 bounds 参数。
例如,要查找最小的 \(J_{{1}}\left( x \right)\) 附近 \(x=5\) , minimize_scalar 可以使用时间间隔调用 \(\left[ 4, 7 \right]\) 作为一种约束。结果是 \(x_{{\textrm{{min}}}}=5.3314\) :
>>> from scipy.special import j1
>>> res = minimize_scalar(j1, bounds=(4, 7), method='bounded')
>>> res.x
5.33144184241
自定义最小化程序¶
有时,将自定义方法用作(多变量或单变量)最小化可能很有用,例如,在使用 minimize (例如, basinhopping )。
我们可以通过以下方式来实现这一点,而不是传递方法名,而是传递一个可调用的(实现 __call__ 方法)作为 method 参数。
让我们考虑一种(诚然相当虚拟的)需要使用普通的自定义多变量最小化方法,该方法将以固定的步长独立地搜索每个维度中的邻域:
>>> from scipy.optimize import OptimizeResult
>>> def custmin(fun, x0, args=(), maxfev=None, stepsize=0.1,
... maxiter=100, callback=None, **options):
... bestx = x0
... besty = fun(x0)
... funcalls = 1
... niter = 0
... improved = True
... stop = False
...
... while improved and not stop and niter < maxiter:
... improved = False
... niter += 1
... for dim in range(np.size(x0)):
... for s in [bestx[dim] - stepsize, bestx[dim] + stepsize]:
... testx = np.copy(bestx)
... testx[dim] = s
... testy = fun(testx, *args)
... funcalls += 1
... if testy < besty:
... besty = testy
... bestx = testx
... improved = True
... if callback is not None:
... callback(bestx)
... if maxfev is not None and funcalls >= maxfev:
... stop = True
... break
...
... return OptimizeResult(fun=besty, x=bestx, nit=niter,
... nfev=funcalls, success=(niter > 1))
>>> x0 = [1.35, 0.9, 0.8, 1.1, 1.2]
>>> res = minimize(rosen, x0, method=custmin, options=dict(stepsize=0.05))
>>> res.x
array([1., 1., 1., 1., 1.])
这在单变量优化的情况下也同样有效:
>>> def custmin(fun, bracket, args=(), maxfev=None, stepsize=0.1,
... maxiter=100, callback=None, **options):
... bestx = (bracket[1] + bracket[0]) / 2.0
... besty = fun(bestx)
... funcalls = 1
... niter = 0
... improved = True
... stop = False
...
... while improved and not stop and niter < maxiter:
... improved = False
... niter += 1
... for testx in [bestx - stepsize, bestx + stepsize]:
... testy = fun(testx, *args)
... funcalls += 1
... if testy < besty:
... besty = testy
... bestx = testx
... improved = True
... if callback is not None:
... callback(bestx)
... if maxfev is not None and funcalls >= maxfev:
... stop = True
... break
...
... return OptimizeResult(fun=besty, x=bestx, nit=niter,
... nfev=funcalls, success=(niter > 1))
>>> def f(x):
... return (x - 2)**2 * (x + 2)**2
>>> res = minimize_scalar(f, bracket=(-3.5, 0), method=custmin,
... options=dict(stepsize = 0.05))
>>> res.x
-2.0
寻根¶
标量函数¶
如果有一个单变量方程,可以尝试多种不同的求根算法。这些算法中的大多数都需要期望根的区间的端点(因为函数会改变符号)。总体而言, brentq 是最好的选择,但其他方法在某些情况下或出于学术目的也可能有用。当括号不可用,但有一个或多个派生函数可用时,则 newton (或 halley , secant )可能适用。如果函数定义在复平面的子集上,并且不能使用括号方法,则情况尤其如此。
定点求解¶
与寻找函数的零点密切相关的一个问题是寻找函数的不动点。函数的固定点是函数求值返回点的点: \(g\left(x\right)=x.\) 很明显,这个固定点 \(g\) 是……的根源 \(f\left(x\right)=g\left(x\right)-x.\) 等同地, \(f\) 是的固定点 \(g\left(x\right)=f\left(x\right)+x.\) 例行公事 fixed_point 给出了一种利用Aitkens序列加速估计不动点的简单迭代方法 \(g\) 给出了一个起点。
方程式组¶
属性可以找到一组非线性方程的根。 root 功能。有几种方法可用,其中包括 hybr (默认值)和 lm 分别使用了MINPACK的Powell混合方法和Levenberg-MarQuardt方法。
下面的示例考虑单变量超越方程
其根可以找到如下所示::
>>> import numpy as np
>>> from scipy.optimize import root
>>> def func(x):
... return x + 2 * np.cos(x)
>>> sol = root(func, 0.3)
>>> sol.x
array([-1.02986653])
>>> sol.fun
array([ -6.66133815e-16])
现在考虑一组非线性方程
我们定义目标函数,以便它也返回雅可比,并通过设置 jac 参数设置为 True 。此外,这里还使用了Levenberg-MarQuardt求解器。
>>> def func2(x):
... f = [x[0] * np.cos(x[1]) - 4,
... x[1]*x[0] - x[1] - 5]
... df = np.array([[np.cos(x[1]), -x[0] * np.sin(x[1])],
... [x[1], x[0] - 1]])
... return f, df
>>> sol = root(func2, [1, 1], jac=True, method='lm')
>>> sol.x
array([ 6.50409711, 0.90841421])
大型问题的寻根¶
方法: hybr 和 lm 在……里面 root 无法处理非常多的变量( N ),因为他们需要计算和反演稠密的 N x N 每个牛顿步长上的雅可比矩阵。在以下情况下,这会变得相当低效 N 生长。
例如,考虑下面的问题:我们需要在正方形上解下面的积分微分方程 \([0,1]\times[0,1]\) :
使用边界条件 \(P(x,1) = 1\) 在上边缘,并且 \(P=0\) 在广场边界的其他地方。这可以通过近似连续函数来实现 P 通过它在网格上的值, \(P_{{n,m}}\approx{{}}P(n h, m h)\) ,具有较小的网格间距 h 。然后可以近似导数和积分;例如 \(\partial_x^2 P(x,y)\approx{{}}(P(x+h,y) - 2 P(x,y) + P(x-h,y))/h^2\) 。这个问题就等同于求某个函数的根。 residual(P) ,在哪里 P 是一个长度向量 \(N_x N_y\) 。
现在,因为 \(N_x N_y\) 可以很大,方法 hybr 或 lm 在……里面 root 要解决这个问题需要很长时间。但是,例如,可以使用其中一个大型求解器找到解决方案 krylov , broyden2 ,或 anderson 。这些方法使用的是所谓的不精确牛顿法,它不是精确地计算雅可比矩阵,而是形成它的近似值。
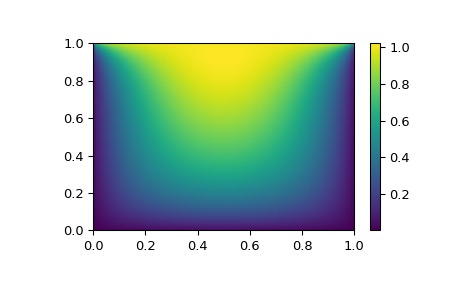
我们现在的问题可以解决如下:
import numpy as np
from scipy.optimize import root
from numpy import cosh, zeros_like, mgrid, zeros
# parameters
nx, ny = 75, 75
hx, hy = 1./(nx-1), 1./(ny-1)
P_left, P_right = 0, 0
P_top, P_bottom = 1, 0
def residual(P):
d2x = zeros_like(P)
d2y = zeros_like(P)
d2x[1:-1] = (P[2:] - 2*P[1:-1] + P[:-2]) / hx/hx
d2x[0] = (P[1] - 2*P[0] + P_left)/hx/hx
d2x[-1] = (P_right - 2*P[-1] + P[-2])/hx/hx
d2y[:,1:-1] = (P[:,2:] - 2*P[:,1:-1] + P[:,:-2])/hy/hy
d2y[:,0] = (P[:,1] - 2*P[:,0] + P_bottom)/hy/hy
d2y[:,-1] = (P_top - 2*P[:,-1] + P[:,-2])/hy/hy
return d2x + d2y + 5*cosh(P).mean()**2
# solve
guess = zeros((nx, ny), float)
sol = root(residual, guess, method='krylov', options={'disp': True})
#sol = root(residual, guess, method='broyden2', options={'disp': True, 'max_rank': 50})
#sol = root(residual, guess, method='anderson', options={'disp': True, 'M': 10})
print('Residual: %g' % abs(residual(sol.x)).max())
# visualize
import matplotlib.pyplot as plt
x, y = mgrid[0:1:(nx*1j), 0:1:(ny*1j)]
plt.pcolormesh(x, y, sol.x, shading='gouraud')
plt.colorbar()
plt.show()
还是太慢了吗?预处理。¶
在查找函数的零点时 \(f_i({{\bf x}}) = 0\) , i = 1, 2, ..., N ,即 krylov 求解器花费大部分时间求逆雅可比矩阵,
如果你有逆矩阵的近似值 \(M\approx{{}}J^{{-1}}\) ,你可以用它来 预处理 线性反演问题。我们的想法是,与其解决 \(J{{\bf s}}={{\bf y}}\) 一个解决方案 \(MJ{{\bf s}}=M{{\bf y}}\) :自矩阵 \(MJ\) 更接近于单位矩阵,而不是 \(J\) 对于Krylov方法来说,这个方程应该更容易处理。
矩阵 M 可以传递给 root 使用方法 krylov 作为一种选择 options['jac_options']['inner_M'] 。它可以是(稀疏)矩阵或 scipy.sparse.linalg.LinearOperator 实例。
对于上一节中的问题,我们注意到要求解的函数由两部分组成:第一部分是拉普拉斯运算符的应用, \([\partial_x^2 + \partial_y^2] P\) ,第二个是积分。我们实际上可以很容易地计算对应于拉普拉斯算符部分的雅可比:我们知道在一维空间中
因此整个2-D运算符由
矩阵 \(J_2\) 与积分相对应的雅可比矩阵的值更难计算,而且由于 all 其中的条目都是非零的,将很难倒置。 \(J_1\) 另一方面是一个相对简单的矩阵,并且可以求逆 scipy.sparse.linalg.splu (或者反转可以近似为 scipy.sparse.linalg.spilu )。所以我们满足于 \(M\approx{{}}J_1^{{-1}}\) 并抱着最好的希望。
在下面的示例中,我们使用预处理器 \(M=J_1^{{-1}}\) 。
import numpy as np
from scipy.optimize import root
from scipy.sparse import spdiags, kron
from scipy.sparse.linalg import spilu, LinearOperator
from numpy import cosh, zeros_like, mgrid, zeros, eye
# parameters
nx, ny = 75, 75
hx, hy = 1./(nx-1), 1./(ny-1)
P_left, P_right = 0, 0
P_top, P_bottom = 1, 0
def get_preconditioner():
"""Compute the preconditioner M"""
diags_x = zeros((3, nx))
diags_x[0,:] = 1/hx/hx
diags_x[1,:] = -2/hx/hx
diags_x[2,:] = 1/hx/hx
Lx = spdiags(diags_x, [-1,0,1], nx, nx)
diags_y = zeros((3, ny))
diags_y[0,:] = 1/hy/hy
diags_y[1,:] = -2/hy/hy
diags_y[2,:] = 1/hy/hy
Ly = spdiags(diags_y, [-1,0,1], ny, ny)
J1 = kron(Lx, eye(ny)) + kron(eye(nx), Ly)
# Now we have the matrix `J_1`. We need to find its inverse `M` --
# however, since an approximate inverse is enough, we can use
# the *incomplete LU* decomposition
J1_ilu = spilu(J1)
# This returns an object with a method .solve() that evaluates
# the corresponding matrix-vector product. We need to wrap it into
# a LinearOperator before it can be passed to the Krylov methods:
M = LinearOperator(shape=(nx*ny, nx*ny), matvec=J1_ilu.solve)
return M
def solve(preconditioning=True):
"""Compute the solution"""
count = [0]
def residual(P):
count[0] += 1
d2x = zeros_like(P)
d2y = zeros_like(P)
d2x[1:-1] = (P[2:] - 2*P[1:-1] + P[:-2])/hx/hx
d2x[0] = (P[1] - 2*P[0] + P_left)/hx/hx
d2x[-1] = (P_right - 2*P[-1] + P[-2])/hx/hx
d2y[:,1:-1] = (P[:,2:] - 2*P[:,1:-1] + P[:,:-2])/hy/hy
d2y[:,0] = (P[:,1] - 2*P[:,0] + P_bottom)/hy/hy
d2y[:,-1] = (P_top - 2*P[:,-1] + P[:,-2])/hy/hy
return d2x + d2y + 5*cosh(P).mean()**2
# preconditioner
if preconditioning:
M = get_preconditioner()
else:
M = None
# solve
guess = zeros((nx, ny), float)
sol = root(residual, guess, method='krylov',
options={'disp': True,
'jac_options': {'inner_M': M}})
print('Residual', abs(residual(sol.x)).max())
print('Evaluations', count[0])
return sol.x
def main():
sol = solve(preconditioning=True)
# visualize
import matplotlib.pyplot as plt
x, y = mgrid[0:1:(nx*1j), 0:1:(ny*1j)]
plt.clf()
plt.pcolor(x, y, sol)
plt.clim(0, 1)
plt.colorbar()
plt.show()
if __name__ == "__main__":
main()
结果运行,第一次没有预处理::
0: |F(x)| = 803.614; step 1; tol 0.000257947
1: |F(x)| = 345.912; step 1; tol 0.166755
2: |F(x)| = 139.159; step 1; tol 0.145657
3: |F(x)| = 27.3682; step 1; tol 0.0348109
4: |F(x)| = 1.03303; step 1; tol 0.00128227
5: |F(x)| = 0.0406634; step 1; tol 0.00139451
6: |F(x)| = 0.00344341; step 1; tol 0.00645373
7: |F(x)| = 0.000153671; step 1; tol 0.00179246
8: |F(x)| = 6.7424e-06; step 1; tol 0.00173256
Residual 3.57078908664e-07
Evaluations 317
然后进行预处理::
0: |F(x)| = 136.993; step 1; tol 7.49599e-06
1: |F(x)| = 4.80983; step 1; tol 0.00110945
2: |F(x)| = 0.195942; step 1; tol 0.00149362
3: |F(x)| = 0.000563597; step 1; tol 7.44604e-06
4: |F(x)| = 1.00698e-09; step 1; tol 2.87308e-12
Residual 9.29603061195e-11
Evaluations 77
使用预处理器减少了对 residual 函数的系数为 4 。对于残差计算成本很高的问题,良好的预处理可能是至关重要的-它甚至可以决定问题在实践中是否可解。
预处理是一门艺术、科学和产业。在这里,我们幸运地做出了一个相当有效的简单选择,但这个主题的深度比这里显示的要深得多。
线性规划 (linprog )¶
该函数 linprog 可以最小化受线性等式和不等式约束的线性目标函数。这类问题就是众所周知的线性规划问题。线性规划解决以下形式的问题:
哪里 \(x\) 是决策变量的向量; \(c\) , \(b_{{ub}}\) , \(b_{{eq}}\) , \(l\) ,以及 \(u\) 是向量;及 \(A_{{ub}}\) 和 \(A_{{eq}}\) 都是矩阵。
在本教程中,我们将尝试使用 linprog 。
线性规划实例¶
考虑以下简单的线性规划问题:
我们需要一些数学运算来将目标问题转换成我们所接受的形式 linprog 。
首先,让我们考虑一下目标函数。我们想最大化目标函数,但是 linprog 只能接受最小化问题。这很容易通过将最大化的 \(29x_1 + 45x_2\) 到最小化 \(-29x_1 -45x_2\) 。另外, \(x_3, x_4\) 在目标函数中没有显示。这意味着与以下各项相对应的权重 \(x_3, x_4\) 是零。因此,目标函数可以转换为:
如果我们定义决策变量的向量 \(x = [x_1, x_2, x_3, x_4]^T\) ,客观权重向量 \(c\) 的 linprog 在这个问题上应该是
接下来,让我们来考虑这两个不等式约束。第一个是“小于”不等式,所以它已经是 linprog 。第二个是“大于”的不等,所以我们需要把两边都乘以 \(-1\) 把它转化为“小于”的不平等。显式地显示零系数,我们有:
这些方程式可以转换成矩阵形式:
哪里
接下来,让我们考虑两个相等约束。明确显示零权重的是:
这些方程式可以转换成矩阵形式:
哪里
最后,让我们考虑单个决策变量上的独立不等式约束,它们被称为“框约束”或“简单边界”。可以使用的bound参数应用这些约束 linprog 。正如在 linprog 文档中,边界的默认值为 (0, None) 这意味着每个决策变量的下限是0,每个决策变量的上限是无穷大:所有决策变量都是非负的。我们的界限是不同的,因此我们需要将每个决策变量的上下限指定为一个元组,并将这些元组分组到一个列表中。
最后,我们可以使用 linprog 。
>>> import numpy as np
>>> from scipy.optimize import linprog
>>> c = np.array([-29.0, -45.0, 0.0, 0.0])
>>> A_ub = np.array([[1.0, -1.0, -3.0, 0.0],
... [-2.0, 3.0, 7.0, -3.0]])
>>> b_ub = np.array([5.0, -10.0])
>>> A_eq = np.array([[2.0, 8.0, 1.0, 0.0],
... [4.0, 4.0, 0.0, 1.0]])
>>> b_eq = np.array([60.0, 60.0])
>>> x0_bounds = (0, None)
>>> x1_bounds = (0, 5.0)
>>> x2_bounds = (-np.inf, 0.5) # +/- np.inf can be used instead of None
>>> x3_bounds = (-3.0, None)
>>> bounds = [x0_bounds, x1_bounds, x2_bounds, x3_bounds]
>>> result = linprog(c, A_ub=A_ub, b_ub=b_ub, A_eq=A_eq, b_eq=b_eq, bounds=bounds)
>>> print(result)
con: array([15.5361242 , 16.61288005]) # may vary
fun: -370.2321976308326 # may vary
message: 'The algorithm terminated successfully and determined that the problem is infeasible.'
nit: 6 # may vary
slack: array([ 0.79314989, -1.76308532]) # may vary
status: 2
success: False
x: array([ 6.60059391, 3.97366609, -0.52664076, 1.09007993]) # may vary
结果表明我们的问题是不可行的,这意味着没有满足所有约束的解向量。这并不一定意味着我们做错了什么,有些问题确实是不可行的。然而,假设我们决定我们对 \(x_1\) 太紧了,可以松开 \(0 \leq x_1 \leq 6\) 。在调整我们的代码之后 x1_bounds = (0, 6) 要反映更改并再次执行更改,请执行以下操作:
>>> x1_bounds = (0, 6)
>>> bounds = [x0_bounds, x1_bounds, x2_bounds, x3_bounds]
>>> result = linprog(c, A_ub=A_ub, b_ub=b_ub, A_eq=A_eq, b_eq=b_eq, bounds=bounds)
>>> print(result)
con: array([9.78840831e-09, 1.04662945e-08]) # may vary
fun: -505.97435889013434 # may vary
message: 'Optimization terminated successfully.'
nit: 4 # may vary
slack: array([ 6.52747190e-10, -2.26730279e-09]) # may vary
status: 0
success: True
x: array([ 9.41025641, 5.17948718, -0.25641026, 1.64102564]) # may vary
结果表明,优化是成功的。我们可以检查目标值 (result.fun )与相同 \(c^Tx\) :
>>> x = np.array(result.x)
>>> print(c @ x)
-505.97435889013434 # may vary
我们还可以检查所有约束是否都在合理公差内得到满足:
>>> print(b_ub - (A_ub @ x).flatten()) # this is equivalent to result.slack
[ 6.52747190e-10, -2.26730279e-09] # may vary
>>> print(b_eq - (A_eq @ x).flatten()) # this is equivalent to result.con
[ 9.78840831e-09, 1.04662945e-08]] # may vary
>>> print([0 <= result.x[0], 0 <= result.x[1] <= 6.0, result.x[2] <= 0.5, -3.0 <= result.x[3]])
[True, True, True, True]
如果我们需要更高的精度,通常是以牺牲速度为代价,我们可以使用 revised simplex 方法:
>>> result = linprog(c, A_ub=A_ub, b_ub=b_ub, A_eq=A_eq, b_eq=b_eq, bounds=bounds, method='revised simplex')
>>> print(result)
con: array([0.00000000e+00, 7.10542736e-15]) # may vary
fun: -505.97435897435895 # may vary
message: 'Optimization terminated successfully.'
nit: 5 # may vary
slack: array([ 1.77635684e-15, -3.55271368e-15]) # may vary
status: 0
success: True
x: array([ 9.41025641, 5.17948718, -0.25641026, 1.64102564]) # may vary
指派问题¶
线性和分配问题实例¶
考虑一下为游泳混合泳接力队挑选学生的问题。我们有一个表格,显示五名学生每种游泳方式的时间:
学生 |
仰泳 |
蛙泳 |
蝴蝶 |
自由式 |
|---|---|---|---|---|
A |
43.5 |
47.1 |
48.4 |
38.2 |
B |
45.5 |
42.1 |
49.6 |
36.8 |
C |
43.4 |
39.1 |
42.1 |
43.2 |
D |
46.5 |
44.1 |
44.5 |
41.2 |
E |
46.3 |
47.8 |
50.4 |
37.2 |
我们需要为四种游泳方式中的每一种选择一名学生,这样总的接力时间才能最小化。这是一个典型的线性和分配问题。我们可以利用 linear_sum_assignment 来解决它。
线性和分配问题是最著名的组合优化问题之一。给出一个“成本矩阵” \(C\) ,问题是如何选择
每行恰好有一个元素
而无需从任何列中选择多个元素
使得所选元素的总和最小化
换句话说,我们需要将每行分配给一列,以便最小化相应条目的总和。
正式地说,让 \(X\) 是布尔矩阵,其中 \(X[i,j] = 1\) IFF行 \(i\) 指定给列 \(j\) 。那么最优分配是有成本的。
第一步是定义成本矩阵。在本例中,我们希望将每种游泳方式分配给一个学生。 linear_sum_assignment 能够将成本矩阵的每一行分配给列。因此,要形成成本矩阵,需要调换上表,使行与游泳风格相对应,列与学生相对应:
>>> import numpy as np
>>> cost = np.array([[43.5, 45.5, 43.4, 46.5, 46.3],
... [47.1, 42.1, 39.1, 44.1, 47.8],
... [48.4, 49.6, 42.1, 44.5, 50.4],
... [38.2, 36.8, 43.2, 41.2, 37.2]])
我们可以用以下方法解决分配问题 linear_sum_assignment :
>>> from scipy.optimize import linear_sum_assignment
>>> row_ind, col_ind = linear_sum_assignment(cost)
这个 row_ind 和 col_ind 是成本矩阵的最佳分配矩阵索引:
>>> row_ind
array([0, 1, 2, 3])
>>> col_ind
array([0, 2, 3, 1])
最佳分配为:
>>> styles = np.array(["backstroke", "breaststroke", "butterfly", "freestyle"])[row_ind]
>>> students = np.array(["A", "B", "C", "D", "E"])[col_ind]
>>> dict(zip(styles, students))
{'backstroke': 'A', 'breaststroke': 'C', 'butterfly': 'D', 'freestyle': 'B'}
最佳的总混合泳时间为:
>>> cost[row_ind, col_ind].sum()
163.89999999999998
请注意,此结果与每种游泳方式的最小次数之和不同:
>>> np.min(cost, axis=1).sum()
161.39999999999998
因为学生“C”在“蛙泳”和“蝶泳”风格上都是最好的游泳运动员。我们不能将学生“C”分配给这两种泳姿,因此我们将学生C分配给“蛙泳”泳姿,将D分配给“蝶泳”泳姿,以最大限度地减少总时间。
参考文献
一些进一步阅读和相关的软件,如牛顿-克里洛夫(Newton-Krylov) [KK], PETSc [PP], 和PyAMG [AMG]:
- KK
D.A.Knoll和D.E.Kyes,“无雅可比牛顿-克里洛夫方法”,J.Comp。太棒了。193,357(2004)。 DOI:10.1016/j.jcp.2003.08.010
- PP
PETSCPythonPython及其绑定https://www.mcs.anl.gov/petsc/https://bitbucket.org/petsc/petsc4py/
- AMG
PYAMG(代数多重网格预处理器/求解器)https://github.com/pyamg/pyamg/issues