索引和选择数据#
Pandas对象中的轴标签信息有多种用途:
标识数据(即提供 元数据 )使用对于分析、可视化和交互式控制台显示很重要的已知指示器。
启用自动和显式数据对齐。
允许直观地获取和设置数据集的子集。
在本节中,我们将重点介绍最后一点:即如何对Pandas对象进行切片、分割,以及获取和设置Pandas对象的子集。主要的重点将放在Series和DataFrame上,因为它们在这一领域得到了更多的开发关注。
备注
Python和NumPy索引运算符 [] and attribute operator . 在广泛的使用案例中提供对PANDA数据结构的快速、轻松的访问。这使得交互工作变得直观,因为如果您已经知道如何处理Python字典和NumPy数组,那么就没有什么新东西需要学习了。然而,由于事先不知道要访问的数据的类型,直接使用标准操作符有一些优化限制。对于产品代码,我们建议您利用本章中介绍的经过优化的PANAS数据访问方法。
警告
是否为设置操作返回副本或引用可取决于上下文。这有时被称为 chained assignment 而且应该避免。看见 Returning a View versus Copy 。
请参阅 MultiIndex / Advanced Indexing 为 MultiIndex 和更高级的索引文档。
请参阅 cookbook 一些先进的策略。
不同的索引选择#
为了支持更明确的基于位置的索引,对象选择已经有了许多用户请求的添加。Pandas现在支持三种类型的多轴分度。
.loc主要基于标签,但也可以与布尔数组一起使用。.loc将筹集KeyError当找不到项目时。允许的输入包括:单个标签,例如
5或'a'(请注意5被解释为 标签 在索引中。此用法是 not 沿索引的整数位置。)。标签列表或标签数组
['a', 'b', 'c']。带标签的切片对象
'a':'f'(请注意,与通常的Python切片相反, both 如果出现在索引中,则包括开始和停止!看见 Slicing with labels 和 Endpoints are inclusive 。)布尔数组(ANY
NA值将被视为False)。A
callable函数只有一个参数(调用Series或DataFrame),并返回用于索引的有效输出(上面的一个)。
见更多 Selection by Label 。
.iloc主要基于整数位置(从0至length-1轴),但也可以与布尔数组一起使用。.iloc将筹集IndexError如果请求的索引器超出范围,则 切片 允许出界索引的索引器。(这符合Python/NumPy 切片 语义学)。允许的输入包括:一个整数,例如
5。整数列表或整数数组
[4, 3, 0]。带有整型的切片对象
1:7。布尔数组(ANY
NA值将被视为False)。A
callable函数只有一个参数(调用Series或DataFrame),并返回用于索引的有效输出(上面的一个)。
见更多 Selection by Position , Advanced Indexing 和 Advanced Hierarchical 。
.loc,.iloc,并且还[]索引可以接受callable作为索引者。见更多 Selection By Callable 。
使用多轴选择从对象获取值使用以下表示法(使用 .loc as an example, but the following applies to .iloc as well). Any of the axes accessors may be the null slice :. Axes left out of the specification are assumed to be `` :,例如 ``p.loc['a'] 相当于 p.loc['a', :] 。
对象类型 |
索引器 |
|---|---|
系列 |
|
DataFrame |
|
基础知识#
中介绍数据结构时提到的 last section ,索引的主要功能是 [] (又名a. __getitem__ 对于那些熟悉在Python中实现类行为的人来说)就是选择较低维度的切片。下表显示了使用索引Pandas对象时的返回类型值 [] :
对象类型 |
选择 |
返回值类型 |
|---|---|---|
系列 |
|
标量值 |
DataFrame |
|
|
这里我们构造了一个简单的时间序列数据集,用于说明索引功能:
In [1]: dates = pd.date_range('1/1/2000', periods=8)
In [2]: df = pd.DataFrame(np.random.randn(8, 4),
...: index=dates, columns=['A', 'B', 'C', 'D'])
...:
In [3]: df
Out[3]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
备注
除非特别说明,否则所有索引功能都不是特定于时间序列的。
因此,如上所述,我们有最基本的索引,使用 [] :
In [4]: s = df['A']
In [5]: s[dates[5]]
Out[5]: -0.6736897080883706
您可以将列列表传递给 [] 若要按该顺序选择列,请执行以下操作。如果列不包含在DataFrame中,则会引发异常。也可以按此方式设置多个列:
In [6]: df
Out[6]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
In [7]: df[['B', 'A']] = df[['A', 'B']]
In [8]: df
Out[8]:
A B C D
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
2000-01-04 -0.706771 0.721555 -1.039575 0.271860
2000-01-05 0.567020 -0.424972 0.276232 -1.087401
2000-01-06 0.113648 -0.673690 -1.478427 0.524988
2000-01-07 0.577046 0.404705 -1.715002 -1.039268
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885
您可能会发现这对于将转换(就地)应用到列的子集很有用。
警告
Pandas在设置时对齐所有轴 Series 和 DataFrame 从… .loc ,以及 .iloc 。
这将 not 修改 df 因为列对齐在赋值之前。
In [9]: df[['A', 'B']]
Out[9]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
In [10]: df.loc[:, ['B', 'A']] = df[['A', 'B']]
In [11]: df[['A', 'B']]
Out[11]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
交换列值的正确方法是使用原始值:
In [12]: df.loc[:, ['B', 'A']] = df[['A', 'B']].to_numpy()
In [13]: df[['A', 'B']]
Out[13]:
A B
2000-01-01 0.469112 -0.282863
2000-01-02 1.212112 -0.173215
2000-01-03 -0.861849 -2.104569
2000-01-04 0.721555 -0.706771
2000-01-05 -0.424972 0.567020
2000-01-06 -0.673690 0.113648
2000-01-07 0.404705 0.577046
2000-01-08 -0.370647 -1.157892
属性访问#
您可以访问 Series 或列在 DataFrame 直接作为属性:
In [14]: sa = pd.Series([1, 2, 3], index=list('abc'))
In [15]: dfa = df.copy()
In [16]: sa.b
Out[16]: 2
In [17]: dfa.A
Out[17]:
2000-01-01 0.469112
2000-01-02 1.212112
2000-01-03 -0.861849
2000-01-04 0.721555
2000-01-05 -0.424972
2000-01-06 -0.673690
2000-01-07 0.404705
2000-01-08 -0.370647
Freq: D, Name: A, dtype: float64
In [18]: sa.a = 5
In [19]: sa
Out[19]:
a 5
b 2
c 3
dtype: int64
In [20]: dfa.A = list(range(len(dfa.index))) # ok if A already exists
In [21]: dfa
Out[21]:
A B C D
2000-01-01 0 -0.282863 -1.509059 -1.135632
2000-01-02 1 -0.173215 0.119209 -1.044236
2000-01-03 2 -2.104569 -0.494929 1.071804
2000-01-04 3 -0.706771 -1.039575 0.271860
2000-01-05 4 0.567020 0.276232 -1.087401
2000-01-06 5 0.113648 -1.478427 0.524988
2000-01-07 6 0.577046 -1.715002 -1.039268
2000-01-08 7 -1.157892 -1.344312 0.844885
In [22]: dfa['A'] = list(range(len(dfa.index))) # use this form to create a new column
In [23]: dfa
Out[23]:
A B C D
2000-01-01 0 -0.282863 -1.509059 -1.135632
2000-01-02 1 -0.173215 0.119209 -1.044236
2000-01-03 2 -2.104569 -0.494929 1.071804
2000-01-04 3 -0.706771 -1.039575 0.271860
2000-01-05 4 0.567020 0.276232 -1.087401
2000-01-06 5 0.113648 -1.478427 0.524988
2000-01-07 6 0.577046 -1.715002 -1.039268
2000-01-08 7 -1.157892 -1.344312 0.844885
警告
只有当索引元素是有效的Python标识符时,才能使用此访问,例如
s.1is not allowed. See here for an explanation of valid identifiers 。如果该属性与现有方法名称冲突,则该属性将不可用,例如
s.min是不允许的,但是s['min']是有可能的。同样,如果该属性与以下任何列表冲突,则该属性将不可用:
index,major_axis,minor_axis,items。在上述任何一种情况下,标准索引仍然有效,例如
s['1'],s['min'],以及s['index']将访问相应的元素或列。
如果您使用的是IPython环境,您还可以使用制表符完成来查看这些可访问的属性。
您还可以将一个 dict 添加到一行 DataFrame :
In [24]: x = pd.DataFrame({'x': [1, 2, 3], 'y': [3, 4, 5]})
In [25]: x.iloc[1] = {'x': 9, 'y': 99}
In [26]: x
Out[26]:
x y
0 1 3
1 9 99
2 3 5
可以使用属性访问来修改DataFrame的系列或列的现有元素,但要小心;如果尝试使用属性访问创建新列,则会创建新属性而不是新列。在0.21.0和更高版本中,这将引发 UserWarning :
In [1]: df = pd.DataFrame({'one': [1., 2., 3.]})
In [2]: df.two = [4, 5, 6]
UserWarning: Pandas doesn't allow Series to be assigned into nonexistent columns - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute_access
In [3]: df
Out[3]:
one
0 1.0
1 2.0
2 3.0
切片范围#
中描述了沿任意轴对范围进行切片的最可靠、最一致的方法 Selection by Position 部分详细介绍了 .iloc 方法。目前,我们将使用 [] 接线员。
对于Series,语法的工作方式与ndarray完全相同,返回值的片段和相应的标签:
In [27]: s[:5]
Out[27]:
2000-01-01 0.469112
2000-01-02 1.212112
2000-01-03 -0.861849
2000-01-04 0.721555
2000-01-05 -0.424972
Freq: D, Name: A, dtype: float64
In [28]: s[::2]
Out[28]:
2000-01-01 0.469112
2000-01-03 -0.861849
2000-01-05 -0.424972
2000-01-07 0.404705
Freq: 2D, Name: A, dtype: float64
In [29]: s[::-1]
Out[29]:
2000-01-08 -0.370647
2000-01-07 0.404705
2000-01-06 -0.673690
2000-01-05 -0.424972
2000-01-04 0.721555
2000-01-03 -0.861849
2000-01-02 1.212112
2000-01-01 0.469112
Freq: -1D, Name: A, dtype: float64
请注意,设置也适用:
In [30]: s2 = s.copy()
In [31]: s2[:5] = 0
In [32]: s2
Out[32]:
2000-01-01 0.000000
2000-01-02 0.000000
2000-01-03 0.000000
2000-01-04 0.000000
2000-01-05 0.000000
2000-01-06 -0.673690
2000-01-07 0.404705
2000-01-08 -0.370647
Freq: D, Name: A, dtype: float64
With DataFrame, slicing inside of [] slices the rows. This is provided
largely as a convenience since it is such a common operation.
In [33]: df[:3]
Out[33]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
In [34]: df[::-1]
Out[34]:
A B C D
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
按标签选择#
警告
是否为设置操作返回副本或引用可取决于上下文。这有时被称为 chained assignment 而且应该避免。看见 Returning a View versus Copy 。
警告
.loc当您呈现与索引类型不兼容(或可转换)的切片器时,是严格的。例如,在DatetimeIndex。这些将提高一个TypeError。
In [35]: dfl = pd.DataFrame(np.random.randn(5, 4),
....: columns=list('ABCD'),
....: index=pd.date_range('20130101', periods=5))
....:
In [36]: dfl
Out[36]:
A B C D
2013-01-01 1.075770 -0.109050 1.643563 -1.469388
2013-01-02 0.357021 -0.674600 -1.776904 -0.968914
2013-01-03 -1.294524 0.413738 0.276662 -0.472035
2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
2013-01-05 0.895717 0.805244 -1.206412 2.565646
In [4]: dfl.loc[2:3]
TypeError: cannot do slice indexing on <class 'pandas.tseries.index.DatetimeIndex'> with these indexers [2] of <type 'int'>
在切片中喜欢串 can 可转换为索引类型并导致自然切片。
In [37]: dfl.loc['20130102':'20130104']
Out[37]:
A B C D
2013-01-02 0.357021 -0.674600 -1.776904 -0.968914
2013-01-03 -1.294524 0.413738 0.276662 -0.472035
2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
警告
在 1.0.0 版更改.
Pandas将养大一只 KeyError 如果使用缺少标签的列表进行索引。看见 list-like Using loc with missing keys in a list is Deprecated 。
Pandas提供了一套方法,以便 纯粹基于标签的索引 。这是一个基于严格包含的协议。请求的每个标签都必须在索引中,或者 KeyError 将会被唤醒。切片时,起始边界和 AND 止损范围为 包括在内 ,如果存在于索引中。整数是有效的标注,但它们引用的是标注 而不是职位 。
这个 .loc 属性是主要的访问方法。以下是有效的输入:
单个标签,例如
5或'a'(请注意5被解释为 标签 在索引中。此用法是 not 沿索引的整数位置。)。标签列表或标签数组
['a', 'b', 'c']。带标签的切片对象
'a':'f'(请注意,与通常的Python切片相反, both 如果出现在索引中,则包括开始和停止!看见 Slicing with labels 。布尔数组。
A
callable,请参见 Selection By Callable 。
In [38]: s1 = pd.Series(np.random.randn(6), index=list('abcdef'))
In [39]: s1
Out[39]:
a 1.431256
b 1.340309
c -1.170299
d -0.226169
e 0.410835
f 0.813850
dtype: float64
In [40]: s1.loc['c':]
Out[40]:
c -1.170299
d -0.226169
e 0.410835
f 0.813850
dtype: float64
In [41]: s1.loc['b']
Out[41]: 1.3403088497993827
请注意,设置也适用:
In [42]: s1.loc['c':] = 0
In [43]: s1
Out[43]:
a 1.431256
b 1.340309
c 0.000000
d 0.000000
e 0.000000
f 0.000000
dtype: float64
使用DataFrame:
In [44]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list('abcdef'),
....: columns=list('ABCD'))
....:
In [45]: df1
Out[45]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
b 1.130127 -1.436737 -1.413681 1.607920
c 1.024180 0.569605 0.875906 -2.211372
d 0.974466 -2.006747 -0.410001 -0.078638
e 0.545952 -1.219217 -1.226825 0.769804
f -1.281247 -0.727707 -0.121306 -0.097883
In [46]: df1.loc[['a', 'b', 'd'], :]
Out[46]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
b 1.130127 -1.436737 -1.413681 1.607920
d 0.974466 -2.006747 -0.410001 -0.078638
通过标签切片访问:
In [47]: df1.loc['d':, 'A':'C']
Out[47]:
A B C
d 0.974466 -2.006747 -0.410001
e 0.545952 -1.219217 -1.226825
f -1.281247 -0.727707 -0.121306
用于使用标注获取横截面(等效于 df.xs('a') ):
In [48]: df1.loc['a']
Out[48]:
A 0.132003
B -0.827317
C -0.076467
D -1.187678
Name: a, dtype: float64
要使用布尔数组获取值,请执行以下操作:
In [49]: df1.loc['a'] > 0
Out[49]:
A True
B False
C False
D False
Name: a, dtype: bool
In [50]: df1.loc[:, df1.loc['a'] > 0]
Out[50]:
A
a 0.132003
b 1.130127
c 1.024180
d 0.974466
e 0.545952
f -1.281247
布尔数组中的NA值传播为 False :
在 1.0.2 版更改.
In [51]: mask = pd.array([True, False, True, False, pd.NA, False], dtype="boolean")
In [52]: mask
Out[52]:
<BooleanArray>
[True, False, True, False, <NA>, False]
Length: 6, dtype: boolean
In [53]: df1[mask]
Out[53]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
c 1.024180 0.569605 0.875906 -2.211372
要显式获取值,请执行以下操作:
# this is also equivalent to ``df1.at['a','A']``
In [54]: df1.loc['a', 'A']
Out[54]: 0.13200317033032932
使用标签进行切片#
在使用时 .loc 对于切片,如果开始标签和停止标签都出现在索引中,则元素 设于 两者之间(包括它们)返回:
In [55]: s = pd.Series(list('abcde'), index=[0, 3, 2, 5, 4])
In [56]: s.loc[3:5]
Out[56]:
3 b
2 c
5 d
dtype: object
如果这两者中至少没有一个,但索引已排序,并且可以与开始和停止标签进行比较,则切片仍将按预期工作,方法是选择 rank 在这两者之间:
In [57]: s.sort_index()
Out[57]:
0 a
2 c
3 b
4 e
5 d
dtype: object
In [58]: s.sort_index().loc[1:6]
Out[58]:
2 c
3 b
4 e
5 d
dtype: object
然而,如果两者中至少有一个缺席 and 如果不对索引进行排序,则会引发错误(因为这样做的计算代价很高,而且对于混合类型的索引可能会有歧义)。例如,在上面的例子中, s.loc[1:6] 会募集到 KeyError 。
有关此行为背后的基本原理,请参见 Endpoints are inclusive 。
In [59]: s = pd.Series(list('abcdef'), index=[0, 3, 2, 5, 4, 2])
In [60]: s.loc[3:5]
Out[60]:
3 b
2 c
5 d
dtype: object
此外,如果索引有重复的标签 and 开始标签或停止标签重复,将引发错误。例如,在上面的例子中, s.loc[2:5] 会引发一个 KeyError 。
有关重复标注的详细信息,请参阅 Duplicate Labels 。
按位置选择#
警告
是否为设置操作返回副本或引用可取决于上下文。这有时被称为 chained assignment 而且应该避免。看见 Returning a View versus Copy 。
Pandas提供了一套方法来获得 纯粹基于整数的索引 。语义紧跟在Python和NumPy切片之后。这些是 0-based 编入索引。切片时,起始界为 包括在内 ,而上限为 已排除 。尝试使用非整数,即使是 有效 标签将引发 IndexError 。
这个 .iloc 属性是主要的访问方法。以下是有效的输入:
一个整数,例如
5。整数列表或整数数组
[4, 3, 0]。带有整型的切片对象
1:7。布尔数组。
A
callable,请参见 Selection By Callable 。
In [61]: s1 = pd.Series(np.random.randn(5), index=list(range(0, 10, 2)))
In [62]: s1
Out[62]:
0 0.695775
2 0.341734
4 0.959726
6 -1.110336
8 -0.619976
dtype: float64
In [63]: s1.iloc[:3]
Out[63]:
0 0.695775
2 0.341734
4 0.959726
dtype: float64
In [64]: s1.iloc[3]
Out[64]: -1.110336102891167
请注意,设置也适用:
In [65]: s1.iloc[:3] = 0
In [66]: s1
Out[66]:
0 0.000000
2 0.000000
4 0.000000
6 -1.110336
8 -0.619976
dtype: float64
使用DataFrame:
In [67]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list(range(0, 12, 2)),
....: columns=list(range(0, 8, 2)))
....:
In [68]: df1
Out[68]:
0 2 4 6
0 0.149748 -0.732339 0.687738 0.176444
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
6 -0.826591 -0.345352 1.314232 0.690579
8 0.995761 2.396780 0.014871 3.357427
10 -0.317441 -1.236269 0.896171 -0.487602
通过整数切片选择:
In [69]: df1.iloc[:3]
Out[69]:
0 2 4 6
0 0.149748 -0.732339 0.687738 0.176444
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
In [70]: df1.iloc[1:5, 2:4]
Out[70]:
4 6
2 0.301624 -2.179861
4 1.462696 -1.743161
6 1.314232 0.690579
8 0.014871 3.357427
通过整数列表选择:
In [71]: df1.iloc[[1, 3, 5], [1, 3]]
Out[71]:
2 6
2 -0.154951 -2.179861
6 -0.345352 0.690579
10 -1.236269 -0.487602
In [72]: df1.iloc[1:3, :]
Out[72]:
0 2 4 6
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
In [73]: df1.iloc[:, 1:3]
Out[73]:
2 4
0 -0.732339 0.687738
2 -0.154951 0.301624
4 -0.954208 1.462696
6 -0.345352 1.314232
8 2.396780 0.014871
10 -1.236269 0.896171
# this is also equivalent to ``df1.iat[1,1]``
In [74]: df1.iloc[1, 1]
Out[74]: -0.1549507744249032
用于使用整数位置(等于 df.xs(1) ):
In [75]: df1.iloc[1]
Out[75]:
0 0.403310
2 -0.154951
4 0.301624
6 -2.179861
Name: 2, dtype: float64
与在Python/NumPy中一样,可以优雅地处理超出范围的切片索引。
# these are allowed in Python/NumPy.
In [76]: x = list('abcdef')
In [77]: x
Out[77]: ['a', 'b', 'c', 'd', 'e', 'f']
In [78]: x[4:10]
Out[78]: ['e', 'f']
In [79]: x[8:10]
Out[79]: []
In [80]: s = pd.Series(x)
In [81]: s
Out[81]:
0 a
1 b
2 c
3 d
4 e
5 f
dtype: object
In [82]: s.iloc[4:10]
Out[82]:
4 e
5 f
dtype: object
In [83]: s.iloc[8:10]
Out[83]: Series([], dtype: object)
请注意,使用超出界限的切片可能会导致空轴(例如,返回空的DataFrame)。
In [84]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB'))
In [85]: dfl
Out[85]:
A B
0 -0.082240 -2.182937
1 0.380396 0.084844
2 0.432390 1.519970
3 -0.493662 0.600178
4 0.274230 0.132885
In [86]: dfl.iloc[:, 2:3]
Out[86]:
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3, 4]
In [87]: dfl.iloc[:, 1:3]
Out[87]:
B
0 -2.182937
1 0.084844
2 1.519970
3 0.600178
4 0.132885
In [88]: dfl.iloc[4:6]
Out[88]:
A B
4 0.27423 0.132885
超出界限的单个索引器将引发 IndexError 。任何元素都超出范围的索引器列表将引发 IndexError 。
>>> dfl.iloc[[4, 5, 6]]
IndexError: positional indexers are out-of-bounds
>>> dfl.iloc[:, 4]
IndexError: single positional indexer is out-of-bounds
按可调用方式选择#
.loc , .iloc ,并且还 [] 索引可以接受 callable 作为索引者。这个 callable 必须是具有一个参数(调用Series或DataFrame)的函数,该参数返回用于索引的有效输出。
In [89]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list('abcdef'),
....: columns=list('ABCD'))
....:
In [90]: df1
Out[90]:
A B C D
a -0.023688 2.410179 1.450520 0.206053
b -0.251905 -2.213588 1.063327 1.266143
c 0.299368 -0.863838 0.408204 -1.048089
d -0.025747 -0.988387 0.094055 1.262731
e 1.289997 0.082423 -0.055758 0.536580
f -0.489682 0.369374 -0.034571 -2.484478
In [91]: df1.loc[lambda df: df['A'] > 0, :]
Out[91]:
A B C D
c 0.299368 -0.863838 0.408204 -1.048089
e 1.289997 0.082423 -0.055758 0.536580
In [92]: df1.loc[:, lambda df: ['A', 'B']]
Out[92]:
A B
a -0.023688 2.410179
b -0.251905 -2.213588
c 0.299368 -0.863838
d -0.025747 -0.988387
e 1.289997 0.082423
f -0.489682 0.369374
In [93]: df1.iloc[:, lambda df: [0, 1]]
Out[93]:
A B
a -0.023688 2.410179
b -0.251905 -2.213588
c 0.299368 -0.863838
d -0.025747 -0.988387
e 1.289997 0.082423
f -0.489682 0.369374
In [94]: df1[lambda df: df.columns[0]]
Out[94]:
a -0.023688
b -0.251905
c 0.299368
d -0.025747
e 1.289997
f -0.489682
Name: A, dtype: float64
您可以在中使用可调用索引 Series 。
In [95]: df1['A'].loc[lambda s: s > 0]
Out[95]:
c 0.299368
e 1.289997
Name: A, dtype: float64
使用这些方法/索引器,可以在不使用临时变量的情况下链接数据选择操作。
In [96]: bb = pd.read_csv('data/baseball.csv', index_col='id')
In [97]: (bb.groupby(['year', 'team']).sum()
....: .loc[lambda df: df['r'] > 100])
....:
Out[97]:
stint g ab r h X2b X3b hr rbi sb cs bb so ibb hbp sh sf gidp
year team
2007 CIN 6 379 745 101 203 35 2 36 125.0 10.0 1.0 105 127.0 14.0 1.0 1.0 15.0 18.0
DET 5 301 1062 162 283 54 4 37 144.0 24.0 7.0 97 176.0 3.0 10.0 4.0 8.0 28.0
HOU 4 311 926 109 218 47 6 14 77.0 10.0 4.0 60 212.0 3.0 9.0 16.0 6.0 17.0
LAN 11 413 1021 153 293 61 3 36 154.0 7.0 5.0 114 141.0 8.0 9.0 3.0 8.0 29.0
NYN 13 622 1854 240 509 101 3 61 243.0 22.0 4.0 174 310.0 24.0 23.0 18.0 15.0 48.0
SFN 5 482 1305 198 337 67 6 40 171.0 26.0 7.0 235 188.0 51.0 8.0 16.0 6.0 41.0
TEX 2 198 729 115 200 40 4 28 115.0 21.0 4.0 73 140.0 4.0 5.0 2.0 8.0 16.0
TOR 4 459 1408 187 378 96 2 58 223.0 4.0 2.0 190 265.0 16.0 12.0 4.0 16.0 38.0
组合位置索引和基于标签的索引#
如果希望从‘A’列的索引中获取第0个和第2个元素,可以执行以下操作:
In [98]: dfd = pd.DataFrame({'A': [1, 2, 3],
....: 'B': [4, 5, 6]},
....: index=list('abc'))
....:
In [99]: dfd
Out[99]:
A B
a 1 4
b 2 5
c 3 6
In [100]: dfd.loc[dfd.index[[0, 2]], 'A']
Out[100]:
a 1
c 3
Name: A, dtype: int64
这也可以用 .iloc ,通过显式获取索引器上的位置,并使用 位置 编入索引以选择事物。
In [101]: dfd.iloc[[0, 2], dfd.columns.get_loc('A')]
Out[101]:
a 1
c 3
Name: A, dtype: int64
因为得到了 多个 索引器,使用 .get_indexer :
In [102]: dfd.iloc[[0, 2], dfd.columns.get_indexer(['A', 'B'])]
Out[102]:
A B
a 1 4
c 3 6
不建议使用缺少标签的列表进行索引#
警告
在 1.0.0 版更改.
使用 .loc 或 [] 具有一个或多个缺失标签的列表将不再重新索引,而是 .reindex 。
在以前的版本中,使用 .loc[list-of-labels] 会一直有效,只要 至少1 的密钥(否则它将引发 KeyError )。此行为已更改,现在将引发 KeyError 如果至少缺少一个标签。推荐的替代方案是使用 .reindex() 。
例如。
In [103]: s = pd.Series([1, 2, 3])
In [104]: s
Out[104]:
0 1
1 2
2 3
dtype: int64
找到所有关键字后的选择不变。
In [105]: s.loc[[1, 2]]
Out[105]:
1 2
2 3
dtype: int64
以前的行为
In [4]: s.loc[[1, 2, 3]]
Out[4]:
1 2.0
2 3.0
3 NaN
dtype: float64
当前行为
In [4]: s.loc[[1, 2, 3]]
Passing list-likes to .loc with any non-matching elements will raise
KeyError in the future, you can use .reindex() as an alternative.
See the documentation here:
https://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike
Out[4]:
1 2.0
2 3.0
3 NaN
dtype: float64
重新编制索引#
实现选择可能找不到的元素的惯用方法是通过 .reindex() 。另请参阅 reindexing 。
In [106]: s.reindex([1, 2, 3])
Out[106]:
1 2.0
2 3.0
3 NaN
dtype: float64
或者,如果您只想选择 有效 键,以下是惯用和有效的;它保证保留所选内容的数据类型。
In [107]: labels = [1, 2, 3]
In [108]: s.loc[s.index.intersection(labels)]
Out[108]:
1 2
2 3
dtype: int64
具有重复的索引将引发 .reindex() :
In [109]: s = pd.Series(np.arange(4), index=['a', 'a', 'b', 'c'])
In [110]: labels = ['c', 'd']
In [17]: s.reindex(labels)
ValueError: cannot reindex on an axis with duplicate labels
通常,可以将所需标签与当前轴相交,然后重新编制索引。
In [111]: s.loc[s.index.intersection(labels)].reindex(labels)
Out[111]:
c 3.0
d NaN
dtype: float64
然而,这将是 静止的 如果结果索引是重复的,则引发。
In [41]: labels = ['a', 'd']
In [42]: s.loc[s.index.intersection(labels)].reindex(labels)
ValueError: cannot reindex on an axis with duplicate labels
随机抽取样本#
属性从Series或DataFrame中随机选择行或列 sample() 方法。默认情况下,该方法将对行进行采样,并接受要返回的特定行数/列数或一小部分行。
In [112]: s = pd.Series([0, 1, 2, 3, 4, 5])
# When no arguments are passed, returns 1 row.
In [113]: s.sample()
Out[113]:
4 4
dtype: int64
# One may specify either a number of rows:
In [114]: s.sample(n=3)
Out[114]:
0 0
4 4
1 1
dtype: int64
# Or a fraction of the rows:
In [115]: s.sample(frac=0.5)
Out[115]:
5 5
3 3
1 1
dtype: int64
默认情况下, sample 将最多返回每行一次,但也可以使用 replace 选项:
In [116]: s = pd.Series([0, 1, 2, 3, 4, 5])
# Without replacement (default):
In [117]: s.sample(n=6, replace=False)
Out[117]:
0 0
1 1
5 5
3 3
2 2
4 4
dtype: int64
# With replacement:
In [118]: s.sample(n=6, replace=True)
Out[118]:
0 0
4 4
3 3
2 2
4 4
4 4
dtype: int64
默认情况下,每行被选中的概率相等,但如果希望行具有不同的概率,则可以将 sample 函数采样权重为 weights 。这些权重可以是List、NumPy数组或Series,但它们必须与要采样的对象具有相同的长度。缺少的值将被视为权重为零,并且不允许使用inf值。如果权重总和不是1,则会通过将所有权重除以权重总和来重新规格化权重。例如:
In [119]: s = pd.Series([0, 1, 2, 3, 4, 5])
In [120]: example_weights = [0, 0, 0.2, 0.2, 0.2, 0.4]
In [121]: s.sample(n=3, weights=example_weights)
Out[121]:
5 5
4 4
3 3
dtype: int64
# Weights will be re-normalized automatically
In [122]: example_weights2 = [0.5, 0, 0, 0, 0, 0]
In [123]: s.sample(n=1, weights=example_weights2)
Out[123]:
0 0
dtype: int64
当应用于DataFrame时,只需将列的名称作为字符串传递,即可将DataFrame的列用作采样权重(假设您对行而不是列进行采样)。
In [124]: df2 = pd.DataFrame({'col1': [9, 8, 7, 6],
.....: 'weight_column': [0.5, 0.4, 0.1, 0]})
.....:
In [125]: df2.sample(n=3, weights='weight_column')
Out[125]:
col1 weight_column
1 8 0.4
0 9 0.5
2 7 0.1
sample 还允许用户使用 axis 论点。
In [126]: df3 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
In [127]: df3.sample(n=1, axis=1)
Out[127]:
col1
0 1
1 2
2 3
最后,人们还可以为 sample 的随机数生成器使用 random_state 参数,它将接受整数(作为种子)或NumPy RandomState对象。
In [128]: df4 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
# With a given seed, the sample will always draw the same rows.
In [129]: df4.sample(n=2, random_state=2)
Out[129]:
col1 col2
2 3 4
1 2 3
In [130]: df4.sample(n=2, random_state=2)
Out[130]:
col1 col2
2 3 4
1 2 3
带放大的设置#
这个 .loc/[] 当为该轴设置不存在的关键点时,操作可以执行放大。
在 Series 这种情况下,这实际上是一个追加操作。
In [131]: se = pd.Series([1, 2, 3])
In [132]: se
Out[132]:
0 1
1 2
2 3
dtype: int64
In [133]: se[5] = 5.
In [134]: se
Out[134]:
0 1.0
1 2.0
2 3.0
5 5.0
dtype: float64
A DataFrame 可以在任一轴上放大通过 .loc 。
In [135]: dfi = pd.DataFrame(np.arange(6).reshape(3, 2),
.....: columns=['A', 'B'])
.....:
In [136]: dfi
Out[136]:
A B
0 0 1
1 2 3
2 4 5
In [137]: dfi.loc[:, 'C'] = dfi.loc[:, 'A']
In [138]: dfi
Out[138]:
A B C
0 0 1 0
1 2 3 2
2 4 5 4
这就像是一个 append 上的操作 DataFrame 。
In [139]: dfi.loc[3] = 5
In [140]: dfi
Out[140]:
A B C
0 0 1 0
1 2 3 2
2 4 5 4
3 5 5 5
标量值的快速获取和设置#
由于使用索引 [] 必须处理很多情况(单标签访问、切片、布尔索引等),为了弄清楚您所要求的是什么,它有一些开销。如果只想访问标量值,最快的方法是使用 at 和 iat 方法,这些方法是在所有数据结构上实现的。
类似于 loc , at 提供 标签 基于标量查找,而, iat 提供 整数 基于查找的类似于 iloc
In [141]: s.iat[5]
Out[141]: 5
In [142]: df.at[dates[5], 'A']
Out[142]: -0.6736897080883706
In [143]: df.iat[3, 0]
Out[143]: 0.7215551622443669
您也可以使用这些相同的索引器进行设置。
In [144]: df.at[dates[5], 'E'] = 7
In [145]: df.iat[3, 0] = 7
at 如果索引器丢失,可以如上所述就地放大对象。
In [146]: df.at[dates[-1] + pd.Timedelta('1 day'), 0] = 7
In [147]: df
Out[147]:
A B C D E 0
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 NaN NaN
2000-01-02 1.212112 -0.173215 0.119209 -1.044236 NaN NaN
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804 NaN NaN
2000-01-04 7.000000 -0.706771 -1.039575 0.271860 NaN NaN
2000-01-05 -0.424972 0.567020 0.276232 -1.087401 NaN NaN
2000-01-06 -0.673690 0.113648 -1.478427 0.524988 7.0 NaN
2000-01-07 0.404705 0.577046 -1.715002 -1.039268 NaN NaN
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885 NaN NaN
2000-01-09 NaN NaN NaN NaN NaN 7.0
布尔索引#
另一个常见的操作是使用布尔向量来过滤数据。这些操作员是: | 为 or , & 为 and ,以及 ~ 为 not 。这些 must 使用圆括号进行分组,因为在默认情况下,Python将计算如下表达式 df['A'] > 2 & df['B'] < 3 作为 df['A'] > (2 & df['B']) < 3 ,而所需的评估顺序为 (df['A'] > 2) & (df['B'] < 3) 。
使用布尔向量为序列编制索引的工作方式与在NumPy ndarray中完全相同:
In [148]: s = pd.Series(range(-3, 4))
In [149]: s
Out[149]:
0 -3
1 -2
2 -1
3 0
4 1
5 2
6 3
dtype: int64
In [150]: s[s > 0]
Out[150]:
4 1
5 2
6 3
dtype: int64
In [151]: s[(s < -1) | (s > 0.5)]
Out[151]:
0 -3
1 -2
4 1
5 2
6 3
dtype: int64
In [152]: s[~(s < 0)]
Out[152]:
3 0
4 1
5 2
6 3
dtype: int64
您可以使用与DataFrame的索引长度相同的布尔向量从DataFrame中选择行(例如,从DataFrame的某一列派生的内容):
In [153]: df[df['A'] > 0]
Out[153]:
A B C D E 0
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 NaN NaN
2000-01-02 1.212112 -0.173215 0.119209 -1.044236 NaN NaN
2000-01-04 7.000000 -0.706771 -1.039575 0.271860 NaN NaN
2000-01-07 0.404705 0.577046 -1.715002 -1.039268 NaN NaN
清单理解和 map 级数法也可以用来产生更复杂的标准:
In [154]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
.....: 'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
.....: 'c': np.random.randn(7)})
.....:
# only want 'two' or 'three'
In [155]: criterion = df2['a'].map(lambda x: x.startswith('t'))
In [156]: df2[criterion]
Out[156]:
a b c
2 two y 0.041290
3 three x 0.361719
4 two y -0.238075
# equivalent but slower
In [157]: df2[[x.startswith('t') for x in df2['a']]]
Out[157]:
a b c
2 two y 0.041290
3 three x 0.361719
4 two y -0.238075
# Multiple criteria
In [158]: df2[criterion & (df2['b'] == 'x')]
Out[158]:
a b c
3 three x 0.361719
用选择的方法 Selection by Label , Selection by Position ,以及 Advanced Indexing 您可以使用布尔向量结合其他索引表达式沿多个轴进行选择。
In [159]: df2.loc[criterion & (df2['b'] == 'x'), 'b':'c']
Out[159]:
b c
3 x 0.361719
警告
iloc 支持两种布尔索引。如果索引器是布尔值 Series ,则会引发错误。例如,在下面的示例中, df.iloc[s.values, 1] 还好吧。布尔索引器是一个数组。但 df.iloc[s, 1] 会募集到 ValueError 。
In [160]: df = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
.....: index=list('abc'),
.....: columns=['A', 'B'])
.....:
In [161]: s = (df['A'] > 2)
In [162]: s
Out[162]:
a False
b True
c True
Name: A, dtype: bool
In [163]: df.loc[s, 'B']
Out[163]:
b 4
c 6
Name: B, dtype: int64
In [164]: df.iloc[s.values, 1]
Out[164]:
b 4
c 6
Name: B, dtype: int64
使用ISIN进行索引#
考虑一下 isin() 一种方法 Series ,它返回一个布尔向量,该向量在 Series 元素存在于传递的列表中。这允许您选择其中一列或多列具有所需值的行:
In [165]: s = pd.Series(np.arange(5), index=np.arange(5)[::-1], dtype='int64')
In [166]: s
Out[166]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
In [167]: s.isin([2, 4, 6])
Out[167]:
4 False
3 False
2 True
1 False
0 True
dtype: bool
In [168]: s[s.isin([2, 4, 6])]
Out[168]:
2 2
0 4
dtype: int64
同样的方法也适用于 Index 对象,并且在您不知道所搜索的标签实际上存在的情况下非常有用:
In [169]: s[s.index.isin([2, 4, 6])]
Out[169]:
4 0
2 2
dtype: int64
# compare it to the following
In [170]: s.reindex([2, 4, 6])
Out[170]:
2 2.0
4 0.0
6 NaN
dtype: float64
除此之外, MultiIndex 允许选择在成员身份检查中使用的单独级别:
In [171]: s_mi = pd.Series(np.arange(6),
.....: index=pd.MultiIndex.from_product([[0, 1], ['a', 'b', 'c']]))
.....:
In [172]: s_mi
Out[172]:
0 a 0
b 1
c 2
1 a 3
b 4
c 5
dtype: int64
In [173]: s_mi.iloc[s_mi.index.isin([(1, 'a'), (2, 'b'), (0, 'c')])]
Out[173]:
0 c 2
1 a 3
dtype: int64
In [174]: s_mi.iloc[s_mi.index.isin(['a', 'c', 'e'], level=1)]
Out[174]:
0 a 0
c 2
1 a 3
c 5
dtype: int64
DataFrame还具有一个 isin() 方法。当呼叫时 isin ,则将一组值作为数组或dict传递。如果值是数组, isin 返回与原始DataFrame形状相同的布尔值的DataFrame,在元素位于值序列中的任何位置都为True。
In [175]: df = pd.DataFrame({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
.....: 'ids2': ['a', 'n', 'c', 'n']})
.....:
In [176]: values = ['a', 'b', 1, 3]
In [177]: df.isin(values)
Out[177]:
vals ids ids2
0 True True True
1 False True False
2 True False False
3 False False False
通常,您会希望将某些值与某些列相匹配。只要让价值成为 dict 其中,键是列,值是要检查的项的列表。
In [178]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [179]: df.isin(values)
Out[179]:
vals ids ids2
0 True True False
1 False True False
2 True False False
3 False False False
返回布尔值的DataFrame not 在原始DataFrame中,使用 ~ 操作员:
In [180]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [181]: ~df.isin(values)
Out[181]:
vals ids ids2
0 False False True
1 True False True
2 False True True
3 True True True
组合DataFrame的 isin 使用 any() 和 all() 方法来快速选择满足给定条件的数据子集。要选择每列满足其自己的标准的行:
In [182]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
In [183]: row_mask = df.isin(values).all(1)
In [184]: df[row_mask]
Out[184]:
vals ids ids2
0 1 a a
这个 where() 方法和掩码#
从带有布尔向量的序列中选择值通常会返回数据的子集。若要确保选择输出具有与原始数据相同的形状,可以使用 where 中的方法 Series 和 DataFrame 。
要仅返回选定的行,请执行以下操作:
In [185]: s[s > 0]
Out[185]:
3 1
2 2
1 3
0 4
dtype: int64
要返回与原始形状相同的系列,请执行以下操作:
In [186]: s.where(s > 0)
Out[186]:
4 NaN
3 1.0
2 2.0
1 3.0
0 4.0
dtype: float64
现在,使用布尔条件从DataFrame选择值还可以保留输入数据形状。 where 在幕后用作实现。下面的代码相当于 df.where(df < 0) 。
In [187]: df[df < 0]
Out[187]:
A B C D
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0.352480 NaN -1.192319 NaN
2000-01-03 -0.864883 NaN -0.227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2.670153 -0.114722 NaN -0.048048
2000-01-08 NaN NaN -0.048788 -0.808838
此外, where 采用可选的 other 参数,用于在返回的副本中替换条件为FALSE的值。
In [188]: df.where(df < 0, -df)
Out[188]:
A B C D
2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166
2000-01-02 -0.352480 -0.390389 -1.192319 -1.655824
2000-01-03 -0.864883 -0.299674 -0.227870 -0.281059
2000-01-04 -0.846958 -1.222082 -0.600705 -1.233203
2000-01-05 -0.669692 -0.605656 -1.169184 -0.342416
2000-01-06 -0.868584 -0.948458 -2.297780 -0.684718
2000-01-07 -2.670153 -0.114722 -0.168904 -0.048048
2000-01-08 -0.801196 -1.392071 -0.048788 -0.808838
您可能希望根据某些布尔标准设置值。这可以像这样直观地完成:
In [189]: s2 = s.copy()
In [190]: s2[s2 < 0] = 0
In [191]: s2
Out[191]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
In [192]: df2 = df.copy()
In [193]: df2[df2 < 0] = 0
In [194]: df2
Out[194]:
A B C D
2000-01-01 0.000000 0.000000 0.485855 0.245166
2000-01-02 0.000000 0.390389 0.000000 1.655824
2000-01-03 0.000000 0.299674 0.000000 0.281059
2000-01-04 0.846958 0.000000 0.600705 0.000000
2000-01-05 0.669692 0.000000 0.000000 0.342416
2000-01-06 0.868584 0.000000 2.297780 0.000000
2000-01-07 0.000000 0.000000 0.168904 0.000000
2000-01-08 0.801196 1.392071 0.000000 0.000000
默认情况下, where 返回数据的修改副本。有一个可选参数 inplace 这样就可以修改原始数据,而无需创建副本:
In [195]: df_orig = df.copy()
In [196]: df_orig.where(df > 0, -df, inplace=True)
In [197]: df_orig
Out[197]:
A B C D
2000-01-01 2.104139 1.309525 0.485855 0.245166
2000-01-02 0.352480 0.390389 1.192319 1.655824
2000-01-03 0.864883 0.299674 0.227870 0.281059
2000-01-04 0.846958 1.222082 0.600705 1.233203
2000-01-05 0.669692 0.605656 1.169184 0.342416
2000-01-06 0.868584 0.948458 2.297780 0.684718
2000-01-07 2.670153 0.114722 0.168904 0.048048
2000-01-08 0.801196 1.392071 0.048788 0.808838
备注
的签名 DataFrame.where() 不同于 numpy.where() 。粗略地说 df1.where(m, df2) 相当于 np.where(m, df1, df2) 。
In [198]: df.where(df < 0, -df) == np.where(df < 0, df, -df)
Out[198]:
A B C D
2000-01-01 True True True True
2000-01-02 True True True True
2000-01-03 True True True True
2000-01-04 True True True True
2000-01-05 True True True True
2000-01-06 True True True True
2000-01-07 True True True True
2000-01-08 True True True True
Alignment
此外, where 对齐输入布尔条件(ndarray或DataFrame),以便可以使用设置进行部分选择。这类似于通过 .loc (但在内容上而不是轴标签上)。
In [199]: df2 = df.copy()
In [200]: df2[df2[1:4] > 0] = 3
In [201]: df2
Out[201]:
A B C D
2000-01-01 -2.104139 -1.309525 0.485855 0.245166
2000-01-02 -0.352480 3.000000 -1.192319 3.000000
2000-01-03 -0.864883 3.000000 -0.227870 3.000000
2000-01-04 3.000000 -1.222082 3.000000 -1.233203
2000-01-05 0.669692 -0.605656 -1.169184 0.342416
2000-01-06 0.868584 -0.948458 2.297780 -0.684718
2000-01-07 -2.670153 -0.114722 0.168904 -0.048048
2000-01-08 0.801196 1.392071 -0.048788 -0.808838
在哪里也可以接受 axis 和 level 参数来对齐输入 where 。
In [202]: df2 = df.copy()
In [203]: df2.where(df2 > 0, df2['A'], axis='index')
Out[203]:
A B C D
2000-01-01 -2.104139 -2.104139 0.485855 0.245166
2000-01-02 -0.352480 0.390389 -0.352480 1.655824
2000-01-03 -0.864883 0.299674 -0.864883 0.281059
2000-01-04 0.846958 0.846958 0.600705 0.846958
2000-01-05 0.669692 0.669692 0.669692 0.342416
2000-01-06 0.868584 0.868584 2.297780 0.868584
2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
2000-01-08 0.801196 1.392071 0.801196 0.801196
这等同于(但快于)以下内容。
In [204]: df2 = df.copy()
In [205]: df.apply(lambda x, y: x.where(x > 0, y), y=df['A'])
Out[205]:
A B C D
2000-01-01 -2.104139 -2.104139 0.485855 0.245166
2000-01-02 -0.352480 0.390389 -0.352480 1.655824
2000-01-03 -0.864883 0.299674 -0.864883 0.281059
2000-01-04 0.846958 0.846958 0.600705 0.846958
2000-01-05 0.669692 0.669692 0.669692 0.342416
2000-01-06 0.868584 0.868584 2.297780 0.868584
2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
2000-01-08 0.801196 1.392071 0.801196 0.801196
where 可以接受可调用的AS条件和 other 争论。该函数必须具有一个参数(调用Series或DataFrame),并将有效输出作为条件和返回 other 论点。
In [206]: df3 = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6],
.....: 'C': [7, 8, 9]})
.....:
In [207]: df3.where(lambda x: x > 4, lambda x: x + 10)
Out[207]:
A B C
0 11 14 7
1 12 5 8
2 13 6 9
遮罩#
mask() 是的逆布尔运算 where 。
In [208]: s.mask(s >= 0)
Out[208]:
4 NaN
3 NaN
2 NaN
1 NaN
0 NaN
dtype: float64
In [209]: df.mask(df >= 0)
Out[209]:
A B C D
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0.352480 NaN -1.192319 NaN
2000-01-03 -0.864883 NaN -0.227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2.670153 -0.114722 NaN -0.048048
2000-01-08 NaN NaN -0.048788 -0.808838
有条件地使用放大进行设置 numpy()#
一种替代 where() 就是使用 numpy.where() 。与设置新列相结合,可以使用它来放大DataFrame,其中的值是有条件地确定的。
假设您在下面的DataFrame中有两个选项可供选择。并且当第二列具有‘Z’时,您想要将新列的颜色设置为‘绿色’。您可以执行以下操作:
In [210]: df = pd.DataFrame({'col1': list('ABBC'), 'col2': list('ZZXY')})
In [211]: df['color'] = np.where(df['col2'] == 'Z', 'green', 'red')
In [212]: df
Out[212]:
col1 col2 color
0 A Z green
1 B Z green
2 B X red
3 C Y red
如果您有多个条件,则可以使用 numpy.select() 来实现这一目标。比方说对应三种情况有三种颜色可供选择,用第四种颜色作为后备,可以做到以下几点。
In [213]: conditions = [
.....: (df['col2'] == 'Z') & (df['col1'] == 'A'),
.....: (df['col2'] == 'Z') & (df['col1'] == 'B'),
.....: (df['col1'] == 'B')
.....: ]
.....:
In [214]: choices = ['yellow', 'blue', 'purple']
In [215]: df['color'] = np.select(conditions, choices, default='black')
In [216]: df
Out[216]:
col1 col2 color
0 A Z yellow
1 B Z blue
2 B X purple
3 C Y black
这个 query() 方法#
DataFrame 对象有一个 query() 允许使用表达式进行选择的方法。
您可以获取Frame Where列的值 b 具有介于列的值之间的值 a 和 c 。例如:
In [217]: n = 10
In [218]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [219]: df
Out[219]:
a b c
0 0.438921 0.118680 0.863670
1 0.138138 0.577363 0.686602
2 0.595307 0.564592 0.520630
3 0.913052 0.926075 0.616184
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
6 0.792342 0.216974 0.564056
7 0.397890 0.454131 0.915716
8 0.074315 0.437913 0.019794
9 0.559209 0.502065 0.026437
# pure python
In [220]: df[(df['a'] < df['b']) & (df['b'] < df['c'])]
Out[220]:
a b c
1 0.138138 0.577363 0.686602
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
7 0.397890 0.454131 0.915716
# query
In [221]: df.query('(a < b) & (b < c)')
Out[221]:
a b c
1 0.138138 0.577363 0.686602
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
7 0.397890 0.454131 0.915716
执行相同的操作,但如果没有名称为的列,则使用命名索引 a 。
In [222]: df = pd.DataFrame(np.random.randint(n / 2, size=(n, 2)), columns=list('bc'))
In [223]: df.index.name = 'a'
In [224]: df
Out[224]:
b c
a
0 0 4
1 0 1
2 3 4
3 4 3
4 1 4
5 0 3
6 0 1
7 3 4
8 2 3
9 1 1
In [225]: df.query('a < b and b < c')
Out[225]:
b c
a
2 3 4
如果您不想或无法命名索引,则可以使用名称 index 在查询表达式中:
In [226]: df = pd.DataFrame(np.random.randint(n, size=(n, 2)), columns=list('bc'))
In [227]: df
Out[227]:
b c
0 3 1
1 3 0
2 5 6
3 5 2
4 7 4
5 0 1
6 2 5
7 0 1
8 6 0
9 7 9
In [228]: df.query('index < b < c')
Out[228]:
b c
2 5 6
备注
如果索引的名称与列名重叠,则该列名优先。例如,
In [229]: df = pd.DataFrame({'a': np.random.randint(5, size=5)})
In [230]: df.index.name = 'a'
In [231]: df.query('a > 2') # uses the column 'a', not the index
Out[231]:
a
a
1 3
3 3
您仍然可以通过使用特殊标识符‘index’在查询表达式中使用索引:
In [232]: df.query('index > 2')
Out[232]:
a
a
3 3
4 2
如果出于某种原因,您有一个名为 index ,则可以将该索引引用为 ilevel_0 同样,在这一点上,您应该考虑将您的专栏重命名为不那么模棱两可的名称。
MultiIndex query() 语法#
您还可以使用 DataFrame 使用一个 MultiIndex 就好像它们是框架中的柱:
In [233]: n = 10
In [234]: colors = np.random.choice(['red', 'green'], size=n)
In [235]: foods = np.random.choice(['eggs', 'ham'], size=n)
In [236]: colors
Out[236]:
array(['red', 'red', 'red', 'green', 'green', 'green', 'green', 'green',
'green', 'green'], dtype='<U5')
In [237]: foods
Out[237]:
array(['ham', 'ham', 'eggs', 'eggs', 'eggs', 'ham', 'ham', 'eggs', 'eggs',
'eggs'], dtype='<U4')
In [238]: index = pd.MultiIndex.from_arrays([colors, foods], names=['color', 'food'])
In [239]: df = pd.DataFrame(np.random.randn(n, 2), index=index)
In [240]: df
Out[240]:
0 1
color food
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
green eggs -0.748199 1.318931
eggs -2.029766 0.792652
ham 0.461007 -0.542749
ham -0.305384 -0.479195
eggs 0.095031 -0.270099
eggs -0.707140 -0.773882
eggs 0.229453 0.304418
In [241]: df.query('color == "red"')
Out[241]:
0 1
color food
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
如果这一水平 MultiIndex 未命名,您可以使用特殊名称来指代它们:
In [242]: df.index.names = [None, None]
In [243]: df
Out[243]:
0 1
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
green eggs -0.748199 1.318931
eggs -2.029766 0.792652
ham 0.461007 -0.542749
ham -0.305384 -0.479195
eggs 0.095031 -0.270099
eggs -0.707140 -0.773882
eggs 0.229453 0.304418
In [244]: df.query('ilevel_0 == "red"')
Out[244]:
0 1
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
大会是这样的 ilevel_0 的第0级的“索引级别0” index 。
query() 用例#
的使用案例 query() 就是当你有一个集合 DataFrame 具有公共列名(或索引级别/名称)子集的对象。您可以将相同的查询传递给两个框架 没有 必须指定您感兴趣的查询帧
In [245]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [246]: df
Out[246]:
a b c
0 0.224283 0.736107 0.139168
1 0.302827 0.657803 0.713897
2 0.611185 0.136624 0.984960
3 0.195246 0.123436 0.627712
4 0.618673 0.371660 0.047902
5 0.480088 0.062993 0.185760
6 0.568018 0.483467 0.445289
7 0.309040 0.274580 0.587101
8 0.258993 0.477769 0.370255
9 0.550459 0.840870 0.304611
In [247]: df2 = pd.DataFrame(np.random.rand(n + 2, 3), columns=df.columns)
In [248]: df2
Out[248]:
a b c
0 0.357579 0.229800 0.596001
1 0.309059 0.957923 0.965663
2 0.123102 0.336914 0.318616
3 0.526506 0.323321 0.860813
4 0.518736 0.486514 0.384724
5 0.190804 0.505723 0.614533
6 0.891939 0.623977 0.676639
7 0.480559 0.378528 0.460858
8 0.420223 0.136404 0.141295
9 0.732206 0.419540 0.604675
10 0.604466 0.848974 0.896165
11 0.589168 0.920046 0.732716
In [249]: expr = '0.0 <= a <= c <= 0.5'
In [250]: map(lambda frame: frame.query(expr), [df, df2])
Out[250]: <map at 0x7f0df40187f0>
query() Python 和Pandas的句法比较#
完整的类似NumPy的语法:
In [251]: df = pd.DataFrame(np.random.randint(n, size=(n, 3)), columns=list('abc'))
In [252]: df
Out[252]:
a b c
0 7 8 9
1 1 0 7
2 2 7 2
3 6 2 2
4 2 6 3
5 3 8 2
6 1 7 2
7 5 1 5
8 9 8 0
9 1 5 0
In [253]: df.query('(a < b) & (b < c)')
Out[253]:
a b c
0 7 8 9
In [254]: df[(df['a'] < df['b']) & (df['b'] < df['c'])]
Out[254]:
a b c
0 7 8 9
去掉圆括号会稍微好一点(比较运算符比 & 和 | ):
In [255]: df.query('a < b & b < c')
Out[255]:
a b c
0 7 8 9
使用英语而不是符号:
In [256]: df.query('a < b and b < c')
Out[256]:
a b c
0 7 8 9
与你写在纸上的方式非常接近:
In [257]: df.query('a < b < c')
Out[257]:
a b c
0 7 8 9
这个 in 和 not in 操作员#
query() 还支持特殊使用Python的 in 和 not in 比较运算符,为调用 isin A的方法 Series 或 DataFrame 。
# get all rows where columns "a" and "b" have overlapping values
In [258]: df = pd.DataFrame({'a': list('aabbccddeeff'), 'b': list('aaaabbbbcccc'),
.....: 'c': np.random.randint(5, size=12),
.....: 'd': np.random.randint(9, size=12)})
.....:
In [259]: df
Out[259]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
In [260]: df.query('a in b')
Out[260]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
# How you'd do it in pure Python
In [261]: df[df['a'].isin(df['b'])]
Out[261]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
In [262]: df.query('a not in b')
Out[262]:
a b c d
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
# pure Python
In [263]: df[~df['a'].isin(df['b'])]
Out[263]:
a b c d
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
您可以将其与其他表达式结合使用,以实现非常简洁的查询:
# rows where cols a and b have overlapping values
# and col c's values are less than col d's
In [264]: df.query('a in b and c < d')
Out[264]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
4 c b 3 6
5 c b 0 2
# pure Python
In [265]: df[df['b'].isin(df['a']) & (df['c'] < df['d'])]
Out[265]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
4 c b 3 6
5 c b 0 2
10 f c 0 6
11 f c 1 2
备注
Note that in and not in are evaluated in Python, since numexpr
has no equivalent of this operation. However, only the in/not in
expression itself is evaluated in vanilla Python. For example, in the
expression
df.query('a in b + c + d')
(b + c + d) 由以下人员评估 numexpr 和 then 这个 in 操作在普通的Python中进行计算。一般而言,任何可以使用 numexpr 一定会的。
的特殊用法 == 运算符带有 list 对象#
比较 list of values to a column using ==/!= 工作原理类似于 in/not in 。
In [266]: df.query('b == ["a", "b", "c"]')
Out[266]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
# pure Python
In [267]: df[df['b'].isin(["a", "b", "c"])]
Out[267]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
In [268]: df.query('c == [1, 2]')
Out[268]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
In [269]: df.query('c != [1, 2]')
Out[269]:
a b c d
1 a a 4 7
4 c b 3 6
5 c b 0 2
6 d b 3 3
8 e c 4 3
10 f c 0 6
# using in/not in
In [270]: df.query('[1, 2] in c')
Out[270]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
In [271]: df.query('[1, 2] not in c')
Out[271]:
a b c d
1 a a 4 7
4 c b 3 6
5 c b 0 2
6 d b 3 3
8 e c 4 3
10 f c 0 6
# pure Python
In [272]: df[df['c'].isin([1, 2])]
Out[272]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
布尔运算符#
你可以用这个词来否定布尔表达式 not 或者 ~ 接线员。
In [273]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [274]: df['bools'] = np.random.rand(len(df)) > 0.5
In [275]: df.query('~bools')
Out[275]:
a b c bools
2 0.697753 0.212799 0.329209 False
7 0.275396 0.691034 0.826619 False
8 0.190649 0.558748 0.262467 False
In [276]: df.query('not bools')
Out[276]:
a b c bools
2 0.697753 0.212799 0.329209 False
7 0.275396 0.691034 0.826619 False
8 0.190649 0.558748 0.262467 False
In [277]: df.query('not bools') == df[~df['bools']]
Out[277]:
a b c bools
2 True True True True
7 True True True True
8 True True True True
当然,表达式也可以是任意复杂的:
# short query syntax
In [278]: shorter = df.query('a < b < c and (not bools) or bools > 2')
# equivalent in pure Python
In [279]: longer = df[(df['a'] < df['b'])
.....: & (df['b'] < df['c'])
.....: & (~df['bools'])
.....: | (df['bools'] > 2)]
.....:
In [280]: shorter
Out[280]:
a b c bools
7 0.275396 0.691034 0.826619 False
In [281]: longer
Out[281]:
a b c bools
7 0.275396 0.691034 0.826619 False
In [282]: shorter == longer
Out[282]:
a b c bools
7 True True True True
的表现 query()#
DataFrame.query() 使用 numexpr 对于较大的帧,它的速度略快于Python。
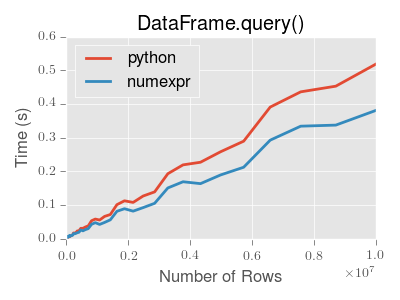
备注
您将只看到使用 numexpr 发动机带有 DataFrame.query() 如果框架的行数超过大约200,000行。
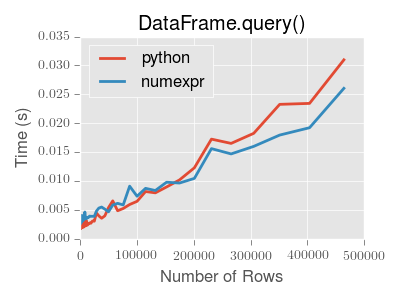
此图是使用 DataFrame 包含3列,每列都包含使用 numpy.random.randn() 。
重复数据#
如果要识别和删除DataFrame中的重复行,有两种方法可以帮助您: duplicated 和 drop_duplicates 。每个函数都将用于标识重复行的列作为参数。
duplicated返回一个布尔向量,该向量的长度为行数,并指示行是否重复。drop_duplicates删除重复行。
默认情况下,重复集合的第一个观察行被认为是唯一的,但每个方法都有 keep 参数指定要保留的目标。
keep='first'(默认):标记/删除除第一个匹配项以外的重复项。keep='last':标记/删除重复项,最后一次出现除外。keep=False:标记/删除所有重复项。
In [283]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
.....: 'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'],
.....: 'c': np.random.randn(7)})
.....:
In [284]: df2
Out[284]:
a b c
0 one x -1.067137
1 one y 0.309500
2 two x -0.211056
3 two y -1.842023
4 two x -0.390820
5 three x -1.964475
6 four x 1.298329
In [285]: df2.duplicated('a')
Out[285]:
0 False
1 True
2 False
3 True
4 True
5 False
6 False
dtype: bool
In [286]: df2.duplicated('a', keep='last')
Out[286]:
0 True
1 False
2 True
3 True
4 False
5 False
6 False
dtype: bool
In [287]: df2.duplicated('a', keep=False)
Out[287]:
0 True
1 True
2 True
3 True
4 True
5 False
6 False
dtype: bool
In [288]: df2.drop_duplicates('a')
Out[288]:
a b c
0 one x -1.067137
2 two x -0.211056
5 three x -1.964475
6 four x 1.298329
In [289]: df2.drop_duplicates('a', keep='last')
Out[289]:
a b c
1 one y 0.309500
4 two x -0.390820
5 three x -1.964475
6 four x 1.298329
In [290]: df2.drop_duplicates('a', keep=False)
Out[290]:
a b c
5 three x -1.964475
6 four x 1.298329
此外,您还可以传递列的列表来标识重复项。
In [291]: df2.duplicated(['a', 'b'])
Out[291]:
0 False
1 False
2 False
3 False
4 True
5 False
6 False
dtype: bool
In [292]: df2.drop_duplicates(['a', 'b'])
Out[292]:
a b c
0 one x -1.067137
1 one y 0.309500
2 two x -0.211056
3 two y -1.842023
5 three x -1.964475
6 four x 1.298329
若要按索引值删除重复项,请使用 Index.duplicated 然后执行切片。同样的一组选项可用于 keep 参数。
In [293]: df3 = pd.DataFrame({'a': np.arange(6),
.....: 'b': np.random.randn(6)},
.....: index=['a', 'a', 'b', 'c', 'b', 'a'])
.....:
In [294]: df3
Out[294]:
a b
a 0 1.440455
a 1 2.456086
b 2 1.038402
c 3 -0.894409
b 4 0.683536
a 5 3.082764
In [295]: df3.index.duplicated()
Out[295]: array([False, True, False, False, True, True])
In [296]: df3[~df3.index.duplicated()]
Out[296]:
a b
a 0 1.440455
b 2 1.038402
c 3 -0.894409
In [297]: df3[~df3.index.duplicated(keep='last')]
Out[297]:
a b
c 3 -0.894409
b 4 0.683536
a 5 3.082764
In [298]: df3[~df3.index.duplicated(keep=False)]
Out[298]:
a b
c 3 -0.894409
词典式的 get() 方法#
每个Series或DataFrame都有一个 get 方法,该方法可以返回默认值。
In [299]: s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
In [300]: s.get('a') # equivalent to s['a']
Out[300]: 1
In [301]: s.get('x', default=-1)
Out[301]: -1
按索引/列标签查找值#
有时,您希望在给定一系列行标签和列标签的情况下提取一组值,这可以通过以下方法实现 pandas.factorize 和NumPy索引。例如:
In [302]: df = pd.DataFrame({'col': ["A", "A", "B", "B"],
.....: 'A': [80, 23, np.nan, 22],
.....: 'B': [80, 55, 76, 67]})
.....:
In [303]: df
Out[303]:
col A B
0 A 80.0 80
1 A 23.0 55
2 B NaN 76
3 B 22.0 67
In [304]: idx, cols = pd.factorize(df['col'])
In [305]: df.reindex(cols, axis=1).to_numpy()[np.arange(len(df)), idx]
Out[305]: array([80., 23., 76., 67.])
以前,这可以通过专门的 DataFrame.lookup 方法,该方法在1.2.0版中已弃用。
索引对象#
大Pandas Index 类及其子类可以被视为实现了 有序多集 。允许重复。但是,如果您尝试将一个 Index 对象中具有重复条目的 set ,则会引发异常。
Index 还提供查找、数据对齐和重建索引所需的基础架构。最简单的方法是创建 Index 直接是传递一个 list 或其他序列以 Index :
In [306]: index = pd.Index(['e', 'd', 'a', 'b'])
In [307]: index
Out[307]: Index(['e', 'd', 'a', 'b'], dtype='object')
In [308]: 'd' in index
Out[308]: True
您还可以传递一个 name 要存储在索引中:
In [309]: index = pd.Index(['e', 'd', 'a', 'b'], name='something')
In [310]: index.name
Out[310]: 'something'
如果设置了该名称,它将显示在控制台显示中:
In [311]: index = pd.Index(list(range(5)), name='rows')
In [312]: columns = pd.Index(['A', 'B', 'C'], name='cols')
In [313]: df = pd.DataFrame(np.random.randn(5, 3), index=index, columns=columns)
In [314]: df
Out[314]:
cols A B C
rows
0 1.295989 -1.051694 1.340429
1 -2.366110 0.428241 0.387275
2 0.433306 0.929548 0.278094
3 2.154730 -0.315628 0.264223
4 1.126818 1.132290 -0.353310
In [315]: df['A']
Out[315]:
rows
0 1.295989
1 -2.366110
2 0.433306
3 2.154730
4 1.126818
Name: A, dtype: float64
设置元数据#
索引“基本上是不变的”,但可以设置和更改它们的 name 属性。您可以使用 rename , set_names 直接设置这些属性,它们默认返回副本。
看见 Advanced Indexing 用于多索引的用法。
In [316]: ind = pd.Index([1, 2, 3])
In [317]: ind.rename("apple")
Out[317]: Int64Index([1, 2, 3], dtype='int64', name='apple')
In [318]: ind
Out[318]: Int64Index([1, 2, 3], dtype='int64')
In [319]: ind.set_names(["apple"], inplace=True)
In [320]: ind.name = "bob"
In [321]: ind
Out[321]: Int64Index([1, 2, 3], dtype='int64', name='bob')
set_names , set_levels ,以及 set_codes 还可以选修一个 level 论据
In [322]: index = pd.MultiIndex.from_product([range(3), ['one', 'two']], names=['first', 'second'])
In [323]: index
Out[323]:
MultiIndex([(0, 'one'),
(0, 'two'),
(1, 'one'),
(1, 'two'),
(2, 'one'),
(2, 'two')],
names=['first', 'second'])
In [324]: index.levels[1]
Out[324]: Index(['one', 'two'], dtype='object', name='second')
In [325]: index.set_levels(["a", "b"], level=1)
Out[325]:
MultiIndex([(0, 'a'),
(0, 'b'),
(1, 'a'),
(1, 'b'),
(2, 'a'),
(2, 'b')],
names=['first', 'second'])
设置索引对象上的操作#
这两个主要操作是 union 和 intersection 。差异是通过 .difference() 方法。
In [326]: a = pd.Index(['c', 'b', 'a'])
In [327]: b = pd.Index(['c', 'e', 'd'])
In [328]: a.difference(b)
Out[328]: Index(['a', 'b'], dtype='object')
还可以使用 symmetric_difference 操作,该操作返回出现在 idx1 或 idx2 ,但不是两者兼而有之。这相当于由创建的索引 idx1.difference(idx2).union(idx2.difference(idx1)) ,并丢弃了副本。
In [329]: idx1 = pd.Index([1, 2, 3, 4])
In [330]: idx2 = pd.Index([2, 3, 4, 5])
In [331]: idx1.symmetric_difference(idx2)
Out[331]: Int64Index([1, 5], dtype='int64')
备注
从集合操作得到的索引将按升序排序。
在表演时 Index.union() 在具有不同数据类型的索引之间,必须将索引转换为公共数据类型。通常情况下,这是对象数据类型,但并非总是如此。在整型和浮点型数据之间执行联合时是个例外。在这种情况下,整数值将转换为浮点型
In [332]: idx1 = pd.Index([0, 1, 2])
In [333]: idx2 = pd.Index([0.5, 1.5])
In [334]: idx1.union(idx2)
Out[334]: Float64Index([0.0, 0.5, 1.0, 1.5, 2.0], dtype='float64')
缺少值#
重要
即使 Index 可以保存缺少的值 (NaN ),如果您不想要任何意外的结果,则应避免这种情况。例如,一些操作隐式排除缺少的值。
Index.fillna 用指定的标量值填充缺少的值。
In [335]: idx1 = pd.Index([1, np.nan, 3, 4])
In [336]: idx1
Out[336]: Float64Index([1.0, nan, 3.0, 4.0], dtype='float64')
In [337]: idx1.fillna(2)
Out[337]: Float64Index([1.0, 2.0, 3.0, 4.0], dtype='float64')
In [338]: idx2 = pd.DatetimeIndex([pd.Timestamp('2011-01-01'),
.....: pd.NaT,
.....: pd.Timestamp('2011-01-03')])
.....:
In [339]: idx2
Out[339]: DatetimeIndex(['2011-01-01', 'NaT', '2011-01-03'], dtype='datetime64[ns]', freq=None)
In [340]: idx2.fillna(pd.Timestamp('2011-01-02'))
Out[340]: DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03'], dtype='datetime64[ns]', freq=None)
设置/重置索引#
有时,您会将数据集加载或创建到DataFrame中,并希望在完成此操作后添加索引。有几种不同的方法。
设置索引#
DataFrame有一个 set_index() 接受列名的方法(对于常规 Index )或列名称列表(对于 MultiIndex )。要创建新的重新索引的DataFrame,请执行以下操作:
In [341]: data
Out[341]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
In [342]: indexed1 = data.set_index('c')
In [343]: indexed1
Out[343]:
a b d
c
z bar one 1.0
y bar two 2.0
x foo one 3.0
w foo two 4.0
In [344]: indexed2 = data.set_index(['a', 'b'])
In [345]: indexed2
Out[345]:
c d
a b
bar one z 1.0
two y 2.0
foo one x 3.0
two w 4.0
这个 append 关键字选项允许您保留现有索引并将给定列追加到多索引:
In [346]: frame = data.set_index('c', drop=False)
In [347]: frame = frame.set_index(['a', 'b'], append=True)
In [348]: frame
Out[348]:
c d
c a b
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
中的其他选项 set_index 允许您不删除索引列或就地添加索引(不创建新对象):
In [349]: data.set_index('c', drop=False)
Out[349]:
a b c d
c
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
In [350]: data.set_index(['a', 'b'], inplace=True)
In [351]: data
Out[351]:
c d
a b
bar one z 1.0
two y 2.0
foo one x 3.0
two w 4.0
重置索引#
为了方便起见,DataFrame上有一个名为 reset_index() 它将索引值传输到DataFrame的列中,并设置一个简单的整数索引。这是的逆运算 set_index() 。
In [352]: data
Out[352]:
c d
a b
bar one z 1.0
two y 2.0
foo one x 3.0
two w 4.0
In [353]: data.reset_index()
Out[353]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
输出更类似于SQL表或记录数组。从索引派生的列的名称是存储在 names 属性。
您可以使用 level 关键字仅删除索引的一部分:
In [354]: frame
Out[354]:
c d
c a b
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
In [355]: frame.reset_index(level=1)
Out[355]:
a c d
c b
z one bar z 1.0
y two bar y 2.0
x one foo x 3.0
w two foo w 4.0
reset_index 接受可选参数 drop 如果为真,则直接丢弃索引,而不是将索引值放入DataFrame的列中。
添加即席索引#
如果您自己创建索引,则只需将其分配给 index 字段:
data.index = index
返回视图与副本#
在Pandas对象中设置值时,必须注意避免所谓的 chained indexing 。这里有一个例子。
In [356]: dfmi = pd.DataFrame([list('abcd'),
.....: list('efgh'),
.....: list('ijkl'),
.....: list('mnop')],
.....: columns=pd.MultiIndex.from_product([['one', 'two'],
.....: ['first', 'second']]))
.....:
In [357]: dfmi
Out[357]:
one two
first second first second
0 a b c d
1 e f g h
2 i j k l
3 m n o p
比较这两种访问方法:
In [358]: dfmi['one']['second']
Out[358]:
0 b
1 f
2 j
3 n
Name: second, dtype: object
In [359]: dfmi.loc[:, ('one', 'second')]
Out[359]:
0 b
1 f
2 j
3 n
Name: (one, second), dtype: object
这两种方法产生的结果相同,那么您应该使用哪种方法呢?理解这些操作的顺序以及方法2的原因是有指导意义的 (.loc )比方法1(链式)更可取 [] )。
dfmi['one'] 选择列的第一级并返回单个索引的DataFrame。然后再执行另一个Python操作 dfmi_with_one['second'] 选择编入索引的系列 'second' 。这是由变量 dfmi_with_one 因为大Pandas认为这些行动是独立的事件。例如,单独调用 __getitem__ ,所以它不得不把它们当作线性运算,它们一个接一个地发生。
与此形成对比的是 df.loc[:,('one','second')] ,它传递嵌套的元组 (slice(None),('one','second')) 只需调用一个 __getitem__ 。这使得Pandas可以作为一个单一的实体来处理这一问题。此外,这一操作顺序 can 速度快得多,并允许用户索引 both 轴,如果需要的话。
为什么在使用链式索引时赋值失败?#
上一节中的问题只是一个性能问题。这是怎么回事 SettingWithCopy 警告?我们没有 通常 当你做一些可能会多花几毫秒的事情时,发出警告!
但事实证明,为链式索引的乘积赋值本身就会产生不可预测的结果。要了解这一点,请考虑一下Python解释器如何执行以下代码:
dfmi.loc[:, ('one', 'second')] = value
# becomes
dfmi.loc.__setitem__((slice(None), ('one', 'second')), value)
但这段代码的处理方式不同:
dfmi['one']['second'] = value
# becomes
dfmi.__getitem__('one').__setitem__('second', value)
看到了吗 __getitem__ 在那里吗?除了简单的情况外,很难预测它将返回视图还是副本(这取决于数组的内存布局,Pandas对此不做保证),因此 __setitem__ 将修改 dfmi 或者是紧接着被扔掉的临时物品。 那是 什么 SettingWithCopy 警告你注意!
备注
您可能想知道我们是否应该关注 loc 第一个示例中的属性。但 dfmi.loc 一定会是 dfmi 自身具有修改后的索引行为,因此 dfmi.loc.__getitem__ / dfmi.loc.__setitem__ 对其进行操作 dfmi 直接去吧。当然了, dfmi.loc.__getitem__(idx) 可以是的视图或副本 dfmi 。
有时是一个 SettingWithCopy 当没有明显的链式索引时,就会出现警告。 这些 是那些错误的 SettingWithCopy 就是为了接球!Pandas可能是在警告你,你已经做到了:
def do_something(df):
foo = df[['bar', 'baz']] # Is foo a view? A copy? Nobody knows!
# ... many lines here ...
# We don't know whether this will modify df or not!
foo['quux'] = value
return foo
呀!
评估顺序很重要#
使用链式索引时,索引操作的顺序和类型部分决定了结果是原始对象的切片还是切片的副本。
Pandas有最好的 SettingWithCopyWarning 因为为切片的副本赋值通常不是故意的,而是链式索引在预期切片的位置返回副本而导致的错误。
如果希望Pandas或多或少信任对链式索引表达式的赋值,可以将 option mode.chained_assignment 设置为下列值之一:
'warn',默认情况下,表示SettingWithCopyWarning是打印出来的。'raise'这意味着Pandas将会养大一个SettingWithCopyException你必须要面对。None将完全禁止显示警告。
In [360]: dfb = pd.DataFrame({'a': ['one', 'one', 'two',
.....: 'three', 'two', 'one', 'six'],
.....: 'c': np.arange(7)})
.....:
# This will show the SettingWithCopyWarning
# but the frame values will be set
In [361]: dfb['c'][dfb['a'].str.startswith('o')] = 42
然而,这是在副本上操作的,不会起作用。
>>> pd.set_option('mode.chained_assignment','warn')
>>> dfb[dfb['a'].str.startswith('o')]['c'] = 42
Traceback (most recent call last)
...
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_index,col_indexer] = value instead
链式赋值也可能出现在混合数据类型框架中的设置中。
备注
这些设置规则适用于所有 .loc/.iloc 。
以下是建议使用的访问方法 .loc 对于多个项目(使用 mask )和使用固定索引的单个项目:
In [362]: dfc = pd.DataFrame({'a': ['one', 'one', 'two',
.....: 'three', 'two', 'one', 'six'],
.....: 'c': np.arange(7)})
.....:
In [363]: dfd = dfc.copy()
# Setting multiple items using a mask
In [364]: mask = dfd['a'].str.startswith('o')
In [365]: dfd.loc[mask, 'c'] = 42
In [366]: dfd
Out[366]:
a c
0 one 42
1 one 42
2 two 2
3 three 3
4 two 4
5 one 42
6 six 6
# Setting a single item
In [367]: dfd = dfc.copy()
In [368]: dfd.loc[2, 'a'] = 11
In [369]: dfd
Out[369]:
a c
0 one 0
1 one 1
2 11 2
3 three 3
4 two 4
5 one 5
6 six 6
以下内容 can 有时工作,但不能保证一定会工作,因此应该避免:
In [370]: dfd = dfc.copy()
In [371]: dfd['a'][2] = 111
In [372]: dfd
Out[372]:
a c
0 one 0
1 one 1
2 111 2
3 three 3
4 two 4
5 one 5
6 six 6
最后,后面的示例将 not 工作,所以应该避免:
>>> pd.set_option('mode.chained_assignment','raise')
>>> dfd.loc[0]['a'] = 1111
Traceback (most recent call last)
...
SettingWithCopyException:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_index,col_indexer] = value instead
警告
链接的分配警告/异常旨在通知用户可能无效的分配。可能会出现误报;无意中报告连锁作业的情况。