处理丢失的数据#
在这一节中,我们将讨论Pandas身上缺失的(也称为NA)值。
备注
选择使用 NaN 在内部表示丢失的数据主要是出于简单性和性能原因。从Pandas 1.0开始,一些可选数据类型开始试验本机数据类型 NA 标量使用基于掩码的方法。看见 here 想要更多。
请参阅 cookbook 一些先进的策略。
被认为是“缺失”的价值#
由于数据的形状和形式多种多样,Pandas的目标是灵活处理丢失的数据。而当 NaN 是默认的缺失值标记出于计算速度和便利性的原因,我们需要能够使用不同类型的数据轻松检测此值:浮点型、整型、布尔型和通用对象。然而,在许多情况下, None 因此,我们希望也将其视为“失踪”、“不可用”或“不适用”。
备注
如果你想考虑 inf 和 -inf 要在计算中使用“NA”,您可以设置 pandas.options.mode.use_inf_as_na = True 。
In [1]: df = pd.DataFrame(
...: np.random.randn(5, 3),
...: index=["a", "c", "e", "f", "h"],
...: columns=["one", "two", "three"],
...: )
...:
In [2]: df["four"] = "bar"
In [3]: df["five"] = df["one"] > 0
In [4]: df
Out[4]:
one two three four five
a 0.469112 -0.282863 -1.509059 bar True
c -1.135632 1.212112 -0.173215 bar False
e 0.119209 -1.044236 -0.861849 bar True
f -2.104569 -0.494929 1.071804 bar False
h 0.721555 -0.706771 -1.039575 bar True
In [5]: df2 = df.reindex(["a", "b", "c", "d", "e", "f", "g", "h"])
In [6]: df2
Out[6]:
one two three four five
a 0.469112 -0.282863 -1.509059 bar True
b NaN NaN NaN NaN NaN
c -1.135632 1.212112 -0.173215 bar False
d NaN NaN NaN NaN NaN
e 0.119209 -1.044236 -0.861849 bar True
f -2.104569 -0.494929 1.071804 bar False
g NaN NaN NaN NaN NaN
h 0.721555 -0.706771 -1.039575 bar True
为了使检测遗漏的值更容易(并且跨不同的数组数据类型),Pandas提供了 isna() 和 notna() 函数,它们也是Series和DataFrame对象上的方法:
In [7]: df2["one"]
Out[7]:
a 0.469112
b NaN
c -1.135632
d NaN
e 0.119209
f -2.104569
g NaN
h 0.721555
Name: one, dtype: float64
In [8]: pd.isna(df2["one"])
Out[8]:
a False
b True
c False
d True
e False
f False
g True
h False
Name: one, dtype: bool
In [9]: df2["four"].notna()
Out[9]:
a True
b False
c True
d False
e True
f True
g False
h True
Name: four, dtype: bool
In [10]: df2.isna()
Out[10]:
one two three four five
a False False False False False
b True True True True True
c False False False False False
d True True True True True
e False False False False False
f False False False False False
g True True True True True
h False False False False False
警告
One has to be mindful that in Python (and NumPy), the nan's don't compare equal, but None's do.
Note that pandas/NumPy uses the fact that np.nan != np.nan, and treats None like np.nan.
In [11]: None == None # noqa: E711
Out[11]: True
In [12]: np.nan == np.nan
Out[12]: False
因此,与上面相比,标量相等比较与 None/np.nan 没有提供有用的信息。
In [13]: df2["one"] == np.nan
Out[13]:
a False
b False
c False
d False
e False
f False
g False
h False
Name: one, dtype: bool
整型数据类型和丢失的数据#
因为 NaN 为浮点型,则将缺少一个值的整型列强制转换为浮点数据类型(请参见 支持整型 NA 了解更多信息)。Pandas提供了一个可为空的整数数组,可以通过显式请求dtype使用该数组:
In [14]: pd.Series([1, 2, np.nan, 4], dtype=pd.Int64Dtype())
Out[14]:
0 1
1 2
2 <NA>
3 4
dtype: Int64
或者,字符串别名 dtype='Int64' (请注意大写 "I" )可以使用。
看见 可为空的整型数据类型 想要更多。
日期时间#
对于DateTime64 [ns] 类型、 NaT 表示缺少的值。这是一个伪本机标记值,可由单一数据类型(日期时间64)中的NumPy表示 [ns] )。Pandas对象提供了 NaT 和 NaN 。
In [15]: df2 = df.copy()
In [16]: df2["timestamp"] = pd.Timestamp("20120101")
In [17]: df2
Out[17]:
one two three four five timestamp
a 0.469112 -0.282863 -1.509059 bar True 2012-01-01
c -1.135632 1.212112 -0.173215 bar False 2012-01-01
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
f -2.104569 -0.494929 1.071804 bar False 2012-01-01
h 0.721555 -0.706771 -1.039575 bar True 2012-01-01
In [18]: df2.loc[["a", "c", "h"], ["one", "timestamp"]] = np.nan
In [19]: df2
Out[19]:
one two three four five timestamp
a NaN -0.282863 -1.509059 bar True NaT
c NaN 1.212112 -0.173215 bar False NaT
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
f -2.104569 -0.494929 1.071804 bar False 2012-01-01
h NaN -0.706771 -1.039575 bar True NaT
In [20]: df2.dtypes.value_counts()
Out[20]:
float64 3
object 1
bool 1
datetime64[ns] 1
dtype: int64
插入丢失的数据#
您可以通过简单地为容器赋值来插入缺少的值。实际使用的缺失值将根据数据类型进行选择。
例如,数字容器将始终使用 NaN 不考虑所选的缺失值类型:
In [21]: s = pd.Series([1, 2, 3])
In [22]: s.loc[0] = None
In [23]: s
Out[23]:
0 NaN
1 2.0
2 3.0
dtype: float64
同样,DateTime容器将始终使用 NaT 。
对于对象容器,Pandas将使用给定的值:
In [24]: s = pd.Series(["a", "b", "c"])
In [25]: s.loc[0] = None
In [26]: s.loc[1] = np.nan
In [27]: s
Out[27]:
0 None
1 NaN
2 c
dtype: object
缺少数据的计算#
缺失的值通过PANAS对象之间的算术运算自然传播。
In [28]: a
Out[28]:
one two
a NaN -0.282863
c NaN 1.212112
e 0.119209 -1.044236
f -2.104569 -0.494929
h -2.104569 -0.706771
In [29]: b
Out[29]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [30]: a + b
Out[30]:
one three two
a NaN NaN -0.565727
c NaN NaN 2.424224
e 0.238417 NaN -2.088472
f -4.209138 NaN -0.989859
h NaN NaN -1.413542
中讨论的描述性统计和计算方法 data structure overview (并列出 here 和 here )都被写入,以说明丢失的数据。例如:
对数据求和时,NA(缺失)值将被视为零。
如果数据都是NA,则结果将为0。
累积法,如
cumsum()和cumprod()默认情况下忽略NA值,但在生成的数组中保留它们。要覆盖此行为并包括NA值,请使用skipna=False。
In [31]: df
Out[31]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [32]: df["one"].sum()
Out[32]: -1.9853605075978744
In [33]: df.mean(1)
Out[33]:
a -0.895961
c 0.519449
e -0.595625
f -0.509232
h -0.873173
dtype: float64
In [34]: df.cumsum()
Out[34]:
one two three
a NaN -0.282863 -1.509059
c NaN 0.929249 -1.682273
e 0.119209 -0.114987 -2.544122
f -1.985361 -0.609917 -1.472318
h NaN -1.316688 -2.511893
In [35]: df.cumsum(skipna=False)
Out[35]:
one two three
a NaN -0.282863 -1.509059
c NaN 0.929249 -1.682273
e NaN -0.114987 -2.544122
f NaN -0.609917 -1.472318
h NaN -1.316688 -2.511893
清空总数/推进量/NAN#
警告
从v0.22.0开始,此行为现在是标准行为,并且与 numpy ;以前全NA或空系列/DataFrames的SUM/PROD将返回NAN。看见 v0.22.0 whatsnew 想要更多。
DataFrame的空系列或全NA系列或列的总和为0。
In [36]: pd.Series([np.nan]).sum()
Out[36]: 0.0
In [37]: pd.Series([], dtype="float64").sum()
Out[37]: 0.0
DataFrame的空系列或全NA系列或列的乘积是1。
In [38]: pd.Series([np.nan]).prod()
Out[38]: 1.0
In [39]: pd.Series([], dtype="float64").prod()
Out[39]: 1.0
组依据中的NA值#
GroupBy中的NA组将自动排除。此行为与R一致,例如:
In [40]: df
Out[40]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [41]: df.groupby("one").mean()
Out[41]:
two three
one
-2.104569 -0.494929 1.071804
0.119209 -1.044236 -0.861849
请参阅GROUPBY部分 here 了解更多信息。
清除/填充丢失的数据#
Pandas对象配备了各种数据操作方法来处理丢失的数据。
填充缺失的值:填充NA#
fillna() 可以通过两种方式使用非NA数据“填充”NA值,我们将对此进行说明:
用标量值替换NA
In [42]: df2
Out[42]:
one two three four five timestamp
a NaN -0.282863 -1.509059 bar True NaT
c NaN 1.212112 -0.173215 bar False NaT
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
f -2.104569 -0.494929 1.071804 bar False 2012-01-01
h NaN -0.706771 -1.039575 bar True NaT
In [43]: df2.fillna(0)
Out[43]:
one two three four five timestamp
a 0.000000 -0.282863 -1.509059 bar True 0
c 0.000000 1.212112 -0.173215 bar False 0
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 00:00:00
f -2.104569 -0.494929 1.071804 bar False 2012-01-01 00:00:00
h 0.000000 -0.706771 -1.039575 bar True 0
In [44]: df2["one"].fillna("missing")
Out[44]:
a missing
c missing
e 0.119209
f -2.104569
h missing
Name: one, dtype: object
向前或向后填充空白
使用与以下相同的填充参数 reindexing ,我们可以向前或向后传播非NA值:
In [45]: df
Out[45]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [46]: df.fillna(method="pad")
Out[46]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h -2.104569 -0.706771 -1.039575
限制填充量
如果我们只希望连续填充一定数量的数据点,则可以使用 limit 关键词:
In [47]: df
Out[47]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e NaN NaN NaN
f NaN NaN NaN
h NaN -0.706771 -1.039575
In [48]: df.fillna(method="pad", limit=1)
Out[48]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e NaN 1.212112 -0.173215
f NaN NaN NaN
h NaN -0.706771 -1.039575
提醒您,以下是可用的填充方法:
方法 |
动作 |
|---|---|
垫片/垫片 |
向前填充值 |
B填充/回填 |
向后填充值 |
对于时间序列数据,使用PAD/FILL是非常常见的,因此在每个时间点都可以获得“最后已知值”。
ffill() is equivalent to fillna(method='ffill')
and bfill() is equivalent to fillna(method='bfill')
使用PandasObject填充#
您也可以使用可对齐的DICT或系列填充NA。词典或丛书索引的标签必须与您要填充的框架的列相匹配。这样做的用例是用该列的平均值填充DataFrame。
In [49]: dff = pd.DataFrame(np.random.randn(10, 3), columns=list("ABC"))
In [50]: dff.iloc[3:5, 0] = np.nan
In [51]: dff.iloc[4:6, 1] = np.nan
In [52]: dff.iloc[5:8, 2] = np.nan
In [53]: dff
Out[53]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 NaN 0.577046 -1.715002
4 NaN NaN -1.157892
5 -1.344312 NaN NaN
6 -0.109050 1.643563 NaN
7 0.357021 -0.674600 NaN
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
In [54]: dff.fillna(dff.mean())
Out[54]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 -0.140857 0.577046 -1.715002
4 -0.140857 -0.401419 -1.157892
5 -1.344312 -0.401419 -0.293543
6 -0.109050 1.643563 -0.293543
7 0.357021 -0.674600 -0.293543
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
In [55]: dff.fillna(dff.mean()["B":"C"])
Out[55]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 NaN 0.577046 -1.715002
4 NaN -0.401419 -1.157892
5 -1.344312 -0.401419 -0.293543
6 -0.109050 1.643563 -0.293543
7 0.357021 -0.674600 -0.293543
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
结果与上面相同,但对齐了‘Fill’值,在本例中是一个系列。
In [56]: dff.where(pd.notna(dff), dff.mean(), axis="columns")
Out[56]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 -0.140857 0.577046 -1.715002
4 -0.140857 -0.401419 -1.157892
5 -1.344312 -0.401419 -0.293543
6 -0.109050 1.643563 -0.293543
7 0.357021 -0.674600 -0.293543
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
丢弃缺少数据的轴标签:Dropna#
您可能只希望从数据集中排除引用缺失数据的标签。要执行此操作,请使用 dropna() :
In [57]: df
Out[57]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e NaN 0.000000 0.000000
f NaN 0.000000 0.000000
h NaN -0.706771 -1.039575
In [58]: df.dropna(axis=0)
Out[58]:
Empty DataFrame
Columns: [one, two, three]
Index: []
In [59]: df.dropna(axis=1)
Out[59]:
two three
a -0.282863 -1.509059
c 1.212112 -0.173215
e 0.000000 0.000000
f 0.000000 0.000000
h -0.706771 -1.039575
In [60]: df["one"].dropna()
Out[60]: Series([], Name: one, dtype: float64)
等价物 dropna() 适用于系列。DataFrame.dropna有比Series.dropna多得多的选项,这是可以研究的 in the API 。
插值#
Series和DataFrame对象都有 interpolate() 在缺省情况下,在缺失的数据点执行线性内插。
In [61]: ts
Out[61]:
2000-01-31 0.469112
2000-02-29 NaN
2000-03-31 NaN
2000-04-28 NaN
2000-05-31 NaN
...
2007-12-31 -6.950267
2008-01-31 -7.904475
2008-02-29 -6.441779
2008-03-31 -8.184940
2008-04-30 -9.011531
Freq: BM, Length: 100, dtype: float64
In [62]: ts.count()
Out[62]: 66
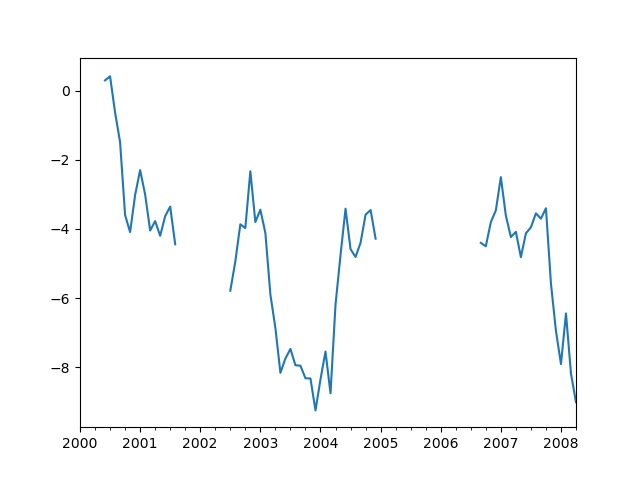
In [63]: ts.plot()
Out[63]: <AxesSubplot:>
In [64]: ts.interpolate()
Out[64]:
2000-01-31 0.469112
2000-02-29 0.434469
2000-03-31 0.399826
2000-04-28 0.365184
2000-05-31 0.330541
...
2007-12-31 -6.950267
2008-01-31 -7.904475
2008-02-29 -6.441779
2008-03-31 -8.184940
2008-04-30 -9.011531
Freq: BM, Length: 100, dtype: float64
In [65]: ts.interpolate().count()
Out[65]: 100
In [66]: ts.interpolate().plot()
Out[66]: <AxesSubplot:>
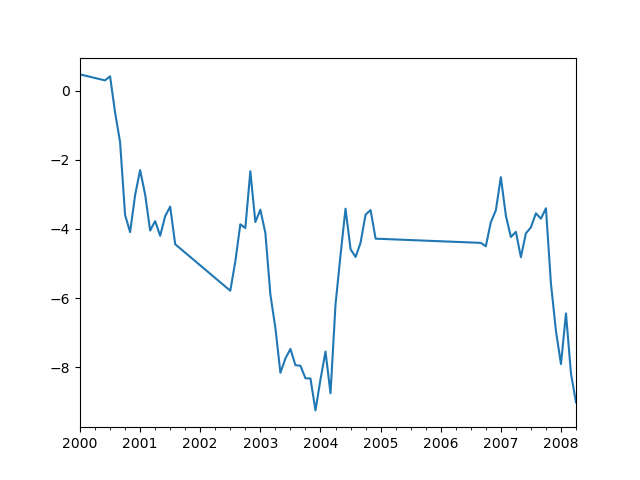
索引感知插补可通过 method 关键词:
In [67]: ts2
Out[67]:
2000-01-31 0.469112
2000-02-29 NaN
2002-07-31 -5.785037
2005-01-31 NaN
2008-04-30 -9.011531
dtype: float64
In [68]: ts2.interpolate()
Out[68]:
2000-01-31 0.469112
2000-02-29 -2.657962
2002-07-31 -5.785037
2005-01-31 -7.398284
2008-04-30 -9.011531
dtype: float64
In [69]: ts2.interpolate(method="time")
Out[69]:
2000-01-31 0.469112
2000-02-29 0.270241
2002-07-31 -5.785037
2005-01-31 -7.190866
2008-04-30 -9.011531
dtype: float64
对于浮点索引,请使用 method='values' :
In [70]: ser
Out[70]:
0.0 0.0
1.0 NaN
10.0 10.0
dtype: float64
In [71]: ser.interpolate()
Out[71]:
0.0 0.0
1.0 5.0
10.0 10.0
dtype: float64
In [72]: ser.interpolate(method="values")
Out[72]:
0.0 0.0
1.0 1.0
10.0 10.0
dtype: float64
您还可以使用DataFrame进行插补:
In [73]: df = pd.DataFrame(
....: {
....: "A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
....: "B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
....: }
....: )
....:
In [74]: df
Out[74]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [75]: df.interpolate()
Out[75]:
A B
0 1.0 0.25
1 2.1 1.50
2 3.4 2.75
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
这个 method 自变量提供了更花哨的插补方法。如果你有 scipy 安装后,可以将一维内插例程的名称传递给 method 。你会想要参考完整的Scipy插值法 documentation 和参考文献 guide 了解更多细节。适当的插补方法将取决于您正在处理的数据类型。
如果你处理的是一个增长速度越来越快的时间序列,
method='quadratic'可能是合适的。如果您的值近似于累积分布函数,则
method='pchip'应该运行得很好。要用流畅打印的目标来填充缺失的值,请考虑
method='akima'。
警告
这些方法需要 scipy 。
In [76]: df.interpolate(method="barycentric")
Out[76]:
A B
0 1.00 0.250
1 2.10 -7.660
2 3.53 -4.515
3 4.70 4.000
4 5.60 12.200
5 6.80 14.400
In [77]: df.interpolate(method="pchip")
Out[77]:
A B
0 1.00000 0.250000
1 2.10000 0.672808
2 3.43454 1.928950
3 4.70000 4.000000
4 5.60000 12.200000
5 6.80000 14.400000
In [78]: df.interpolate(method="akima")
Out[78]:
A B
0 1.000000 0.250000
1 2.100000 -0.873316
2 3.406667 0.320034
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
通过多项式或样条线近似进行插补时,还必须指定近似的阶数或阶数:
In [79]: df.interpolate(method="spline", order=2)
Out[79]:
A B
0 1.000000 0.250000
1 2.100000 -0.428598
2 3.404545 1.206900
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
In [80]: df.interpolate(method="polynomial", order=2)
Out[80]:
A B
0 1.000000 0.250000
1 2.100000 -2.703846
2 3.451351 -1.453846
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
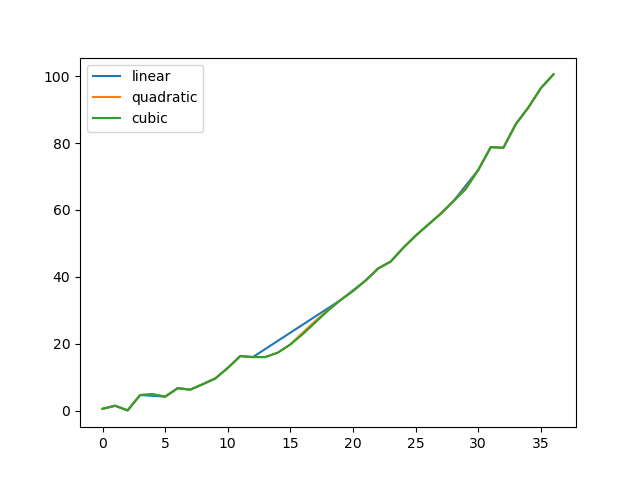
比较几种方法:
In [81]: np.random.seed(2)
In [82]: ser = pd.Series(np.arange(1, 10.1, 0.25) ** 2 + np.random.randn(37))
In [83]: missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
In [84]: ser[missing] = np.nan
In [85]: methods = ["linear", "quadratic", "cubic"]
In [86]: df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
In [87]: df.plot()
Out[87]: <AxesSubplot:>
另一种用例是插值法 new 价值观。假设你有100个来自某一分布的观察结果。让我们假设你对中间发生的事情特别感兴趣。你可以混合大Pandas的 reindex 和 interpolate 方法在新值处进行内插。
In [88]: ser = pd.Series(np.sort(np.random.uniform(size=100)))
# interpolate at new_index
In [89]: new_index = ser.index.union(pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75]))
In [90]: interp_s = ser.reindex(new_index).interpolate(method="pchip")
In [91]: interp_s[49:51]
Out[91]:
49.00 0.471410
49.25 0.476841
49.50 0.481780
49.75 0.485998
50.00 0.489266
50.25 0.491814
50.50 0.493995
50.75 0.495763
51.00 0.497074
dtype: float64
内插极限#
像其他Pandas填充法一样, interpolate() 接受一个 limit 关键字参数。使用此参数可限制连续的 NaN 自上次有效观察以来填充的值:
In [92]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13, np.nan, np.nan])
In [93]: ser
Out[93]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive values in a forward direction
In [94]: ser.interpolate()
Out[94]:
0 NaN
1 NaN
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
# fill one consecutive value in a forward direction
In [95]: ser.interpolate(limit=1)
Out[95]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 NaN
6 13.0
7 13.0
8 NaN
dtype: float64
默认情况下, NaN 值被填充在 forward 方向。使用 limit_direction 要填充的参数 backward 或从 both 方向。
# fill one consecutive value backwards
In [96]: ser.interpolate(limit=1, limit_direction="backward")
Out[96]:
0 NaN
1 5.0
2 5.0
3 NaN
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
# fill one consecutive value in both directions
In [97]: ser.interpolate(limit=1, limit_direction="both")
Out[97]:
0 NaN
1 5.0
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 13.0
8 NaN
dtype: float64
# fill all consecutive values in both directions
In [98]: ser.interpolate(limit_direction="both")
Out[98]:
0 5.0
1 5.0
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
默认情况下, NaN 无论值是在现有有效值内(被现有有效值包围)还是在现有有效值之外,都会填充这些值。这个 limit_area 参数将填充限制为内部或外部值。
# fill one consecutive inside value in both directions
In [99]: ser.interpolate(limit_direction="both", limit_area="inside", limit=1)
Out[99]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive outside values backward
In [100]: ser.interpolate(limit_direction="backward", limit_area="outside")
Out[100]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive outside values in both directions
In [101]: ser.interpolate(limit_direction="both", limit_area="outside")
Out[101]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
dtype: float64
替换泛型值#
我们经常希望用其他值替换任意值。
replace() 在系列和 replace() 在DataFrame中提供了一种高效而灵活的方式来执行此类替换。
对于系列,您可以用另一个值替换单个值或一列值:
In [102]: ser = pd.Series([0.0, 1.0, 2.0, 3.0, 4.0])
In [103]: ser.replace(0, 5)
Out[103]:
0 5.0
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
您可以将值列表替换为其他值的列表:
In [104]: ser.replace([0, 1, 2, 3, 4], [4, 3, 2, 1, 0])
Out[104]:
0 4.0
1 3.0
2 2.0
3 1.0
4 0.0
dtype: float64
您还可以指定映射DICT:
In [105]: ser.replace({0: 10, 1: 100})
Out[105]:
0 10.0
1 100.0
2 2.0
3 3.0
4 4.0
dtype: float64
对于DataFrame,您可以按列指定各个值:
In [106]: df = pd.DataFrame({"a": [0, 1, 2, 3, 4], "b": [5, 6, 7, 8, 9]})
In [107]: df.replace({"a": 0, "b": 5}, 100)
Out[107]:
a b
0 100 100
1 1 6
2 2 7
3 3 8
4 4 9
您可以将所有给定值视为缺失并在其上进行内插,而不是替换为指定值:
In [108]: ser.replace([1, 2, 3], method="pad")
Out[108]:
0 0.0
1 0.0
2 0.0
3 0.0
4 4.0
dtype: float64
字符串/正则表达式替换#
备注
带有前缀的Python字符串 r character such as r'hello world' are so-called "raw" strings. They have different semantics regarding backslashes than strings without this prefix. Backslashes in raw strings will be interpreted as an escaped backslash, e.g., r'\' == '\\'. You should read about them 如果这一点不清楚的话。
替换“.”使用 NaN (字符串->字符串):
In [109]: d = {"a": list(range(4)), "b": list("ab.."), "c": ["a", "b", np.nan, "d"]}
In [110]: df = pd.DataFrame(d)
In [111]: df.replace(".", np.nan)
Out[111]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
现在,使用删除周围空格的正则表达式(regex->regex)执行此操作:
In [112]: df.replace(r"\s*\.\s*", np.nan, regex=True)
Out[112]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
替换几个不同的值(列表->列表):
In [113]: df.replace(["a", "."], ["b", np.nan])
Out[113]:
a b c
0 0 b b
1 1 b b
2 2 NaN NaN
3 3 NaN d
正则表达式列表->正则表达式列表:
In [114]: df.replace([r"\.", r"(a)"], ["dot", r"\1stuff"], regex=True)
Out[114]:
a b c
0 0 astuff astuff
1 1 b b
2 2 dot NaN
3 3 dot d
仅在列中搜索 'b' (词典->词典):
In [115]: df.replace({"b": "."}, {"b": np.nan})
Out[115]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
与上一个示例相同,但使用正则表达式进行搜索(regex的dict->dict):
In [116]: df.replace({"b": r"\s*\.\s*"}, {"b": np.nan}, regex=True)
Out[116]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
可以传递使用以下代码的正则表达式的嵌套词典 regex=True :
In [117]: df.replace({"b": {"b": r""}}, regex=True)
Out[117]:
a b c
0 0 a a
1 1 b
2 2 . NaN
3 3 . d
或者,您可以按如下方式传递嵌套的字典:
In [118]: df.replace(regex={"b": {r"\s*\.\s*": np.nan}})
Out[118]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
也可以在替换时使用正则表达式匹配组(dict of regex->dict of regex),这也适用于列表。
In [119]: df.replace({"b": r"\s*(\.)\s*"}, {"b": r"\1ty"}, regex=True)
Out[119]:
a b c
0 0 a a
1 1 b b
2 2 .ty NaN
3 3 .ty d
您可以传递正则表达式列表,匹配的正则表达式将被标量替换(regex列表->regex)。
In [120]: df.replace([r"\s*\.\s*", r"a|b"], np.nan, regex=True)
Out[120]:
a b c
0 0 NaN NaN
1 1 NaN NaN
2 2 NaN NaN
3 3 NaN d
所有正则表达式示例也可以通过 to_replace 参数作为 regex 争论。在本例中, value 参数必须按名称显式传递或 regex 必须是嵌套词典。在本例中,上一个示例将是:
In [121]: df.replace(regex=[r"\s*\.\s*", r"a|b"], value=np.nan)
Out[121]:
a b c
0 0 NaN NaN
1 1 NaN NaN
2 2 NaN NaN
3 3 NaN d
如果您不想通过,这会很方便 regex=True 每次要使用正则表达式时。
备注
以上的任何地方 replace 你看到的正则表达式的例子编译后的正则表达式也是有效的.
数字替换#
In [122]: df = pd.DataFrame(np.random.randn(10, 2))
In [123]: df[np.random.rand(df.shape[0]) > 0.5] = 1.5
In [124]: df.replace(1.5, np.nan)
Out[124]:
0 1
0 -0.844214 -1.021415
1 0.432396 -0.323580
2 0.423825 0.799180
3 1.262614 0.751965
4 NaN NaN
5 NaN NaN
6 -0.498174 -1.060799
7 0.591667 -0.183257
8 1.019855 -1.482465
9 NaN NaN
通过传递列表可以替换多个值。
In [125]: df00 = df.iloc[0, 0]
In [126]: df.replace([1.5, df00], [np.nan, "a"])
Out[126]:
0 1
0 a -1.021415
1 0.432396 -0.323580
2 0.423825 0.799180
3 1.262614 0.751965
4 NaN NaN
5 NaN NaN
6 -0.498174 -1.060799
7 0.591667 -0.183257
8 1.019855 -1.482465
9 NaN NaN
In [127]: df[1].dtype
Out[127]: dtype('float64')
您还可以就地对DataFrame进行操作:
In [128]: df.replace(1.5, np.nan, inplace=True)
缺少数据转换规则和索引#
虽然Pandas支持存储整数和布尔类型的数组,但这些类型不能存储丢失的数据。在我们可以在NumPy中切换到使用原生NA类型之前,我们已经建立了一些“强制转换规则”。当重建索引操作引入缺失数据时,将根据下表中介绍的规则转换该系列。
数据类型 |
投给 |
|---|---|
整数 |
浮动 |
布尔值 |
对象 |
浮动 |
没有石膏 |
对象 |
没有石膏 |
例如:
In [129]: s = pd.Series(np.random.randn(5), index=[0, 2, 4, 6, 7])
In [130]: s > 0
Out[130]:
0 True
2 True
4 True
6 True
7 True
dtype: bool
In [131]: (s > 0).dtype
Out[131]: dtype('bool')
In [132]: crit = (s > 0).reindex(list(range(8)))
In [133]: crit
Out[133]:
0 True
1 NaN
2 True
3 NaN
4 True
5 NaN
6 True
7 True
dtype: object
In [134]: crit.dtype
Out[134]: dtype('O')
通常,如果您尝试使用对象数组(即使它包含布尔值)而不是布尔数组来从ndarray获取或设置值(例如,根据某些条件选择值),NumPy会发出警告。如果布尔向量包含Nas,则会生成异常:
In [135]: reindexed = s.reindex(list(range(8))).fillna(0)
In [136]: reindexed[crit]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [136], in <cell line: 1>()
----> 1 reindexed[crit]
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/core/series.py:988, in Series.__getitem__(self, key)
985 if is_iterator(key):
986 key = list(key)
--> 988 if com.is_bool_indexer(key):
989 key = check_bool_indexer(self.index, key)
990 key = np.asarray(key, dtype=bool)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/core/common.py:143, in is_bool_indexer(key)
139 na_msg = "Cannot mask with non-boolean array containing NA / NaN values"
140 if lib.infer_dtype(key) == "boolean" and isna(key).any():
141 # Don't raise on e.g. ["A", "B", np.nan], see
142 # test_loc_getitem_list_of_labels_categoricalindex_with_na
--> 143 raise ValueError(na_msg)
144 return False
145 return True
ValueError: Cannot mask with non-boolean array containing NA / NaN values
但是,可以使用以下命令填写这些内容 fillna() 而且它会运行得很好:
In [137]: reindexed[crit.fillna(False)]
Out[137]:
0 0.126504
2 0.696198
4 0.697416
6 0.601516
7 0.003659
dtype: float64
In [138]: reindexed[crit.fillna(True)]
Out[138]:
0 0.126504
1 0.000000
2 0.696198
3 0.000000
4 0.697416
5 0.000000
6 0.601516
7 0.003659
dtype: float64
Pandas提供了一个可以为空的整数数据类型,但您必须在创建序列或列时显式请求它。注意,我们在 dtype="Int64" 。
In [139]: s = pd.Series([0, 1, np.nan, 3, 4], dtype="Int64")
In [140]: s
Out[140]:
0 0
1 1
2 <NA>
3 3
4 4
dtype: Int64
看见 可为空的整型数据类型 想要更多。
实验性的 NA 标量表示缺少的值#
警告
实验性的:行为 pd.NA 仍然可以在没有警告的情况下改变。
1.0.0 新版功能.
从Pandas1.0开始,一个实验性的 pd.NA 值(单例)可用于表示标量缺失值。此时,它用于可以为空的 integer 、布尔值和 dedicated string 数据类型作为缺失值指示符。
的目标是 pd.NA 提供了可跨数据类型一致使用(而不是 np.nan , None 或 pd.NaT 取决于数据类型)。
例如,当具有可为空的整型数据类型的Series中缺少值时,它将使用 pd.NA :
In [141]: s = pd.Series([1, 2, None], dtype="Int64")
In [142]: s
Out[142]:
0 1
1 2
2 <NA>
dtype: Int64
In [143]: s[2]
Out[143]: <NA>
In [144]: s[2] is pd.NA
Out[144]: True
目前,Pandas在默认情况下还不使用这些数据类型(在创建DataFrame或Series时,或者在读取数据时),因此您需要显式指定dtype。本文介绍了一种转换为这些数据类型的简单方法 here 。
算术和比较运算中的传播#
一般而言,缺少值 传播 在涉及以下方面的操作中 pd.NA 。当其中一个操作数未知时,操作的结果也是未知的。
例如, pd.NA 在算术运算中传播,类似于 np.nan :
In [145]: pd.NA + 1
Out[145]: <NA>
In [146]: "a" * pd.NA
Out[146]: <NA>
在一些特殊情况下,即使其中一个操作数是 NA 。
In [147]: pd.NA ** 0
Out[147]: 1
In [148]: 1 ** pd.NA
Out[148]: 1
在相等和比较运算中, pd.NA 也会传播。这与……的行为不同 np.nan ,其中与 np.nan 总是要回来 False 。
In [149]: pd.NA == 1
Out[149]: <NA>
In [150]: pd.NA == pd.NA
Out[150]: <NA>
In [151]: pd.NA < 2.5
Out[151]: <NA>
检查某个值是否等于 pd.NA ,即 isna() 函数可以使用:
In [152]: pd.isna(pd.NA)
Out[152]: True
此基本传播规则的例外情况是 减量 (如平均值或最小值),其中Pandas默认跳过缺失的值。看见 above 想要更多。
逻辑运算#
对于逻辑运算, pd.NA follows the rules of the three-valued logic (或 克莱恩逻辑 ,类似于R、SQL和Julia)。此逻辑意味着仅在逻辑上需要时才传播缺失的值。
例如,对于逻辑“或”运算 (| ),如果其中一个操作数是 True ,我们已经知道结果将是 True ,而不考虑其他值(因此,无论缺少的值是 True 或 False )。在这种情况下, pd.NA 不传播:
In [153]: True | False
Out[153]: True
In [154]: True | pd.NA
Out[154]: True
In [155]: pd.NA | True
Out[155]: True
另一方面,如果其中一个操作数是 False ,则结果取决于另一个操作数的值。因此,在这种情况下, pd.NA 传播:
In [156]: False | True
Out[156]: True
In [157]: False | False
Out[157]: False
In [158]: False | pd.NA
Out[158]: <NA>
逻辑“与”运算的行为 (& )可以使用类似的逻辑(现在 pd.NA 如果其中一个操作数已 False ):
In [159]: False & True
Out[159]: False
In [160]: False & False
Out[160]: False
In [161]: False & pd.NA
Out[161]: False
In [162]: True & True
Out[162]: True
In [163]: True & False
Out[163]: False
In [164]: True & pd.NA
Out[164]: <NA>
NA 在布尔上下文中#
由于安娜的实际值未知,因此将NA转换为布尔值是不明确的。以下代码会引发错误:
In [165]: bool(pd.NA)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [165], in <cell line: 1>()
----> 1 bool(pd.NA)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/_libs/missing.pyx:382, in pandas._libs.missing.NAType.__bool__()
TypeError: boolean value of NA is ambiguous
这也意味着 pd.NA cannot be used in a context where it is evaluated to a boolean, such as if condition: ... 哪里 condition 可能是潜在的 pd.NA 。在这种情况下, isna() 可用于检查 pd.NA 或 condition 存在 pd.NA 例如,可以通过预先填充缺失的值来避免。
在中使用Series或DataFrame对象时也会出现类似情况 if 语句,请参阅 对Pandas使用IF/TRUE语句 。
NumPy不起作用#
pandas.NA 实现NumPy的 __array_ufunc__ 协议。大多数不起作用的应用程序都与 NA ,并通常返回 NA :
In [166]: np.log(pd.NA)
Out[166]: <NA>
In [167]: np.add(pd.NA, 1)
Out[167]: <NA>
警告
目前,涉及ndarray和ndarray的uuncs NA 将返回一个填充了NA值的对象数据类型。
In [168]: a = np.array([1, 2, 3])
In [169]: np.greater(a, pd.NA)
Out[169]: array([<NA>, <NA>, <NA>], dtype=object)
这里的返回类型将来可能会更改为返回不同的数组类型。
看见 DataFrame与NumPy函数的互操作性 了解更多关于UFFICS的信息。
转换#
如果有使用传统类型的DataFrame或Series,而这些类型的缺失数据使用 np.nan ,有一些方便的方法 convert_dtypes() 在系列和 convert_dtypes() 在DataFrame中,可以将数据转换为对列出的整数、字符串和布尔值使用较新的数据类型 here 。这在读入数据集之后尤其有用,因为它让读取器(如 read_csv() 和 read_excel() 推断默认数据类型。
在本例中,虽然更改了所有列的数据类型,但我们显示了前10列的结果。
In [170]: bb = pd.read_csv("data/baseball.csv", index_col="id")
In [171]: bb[bb.columns[:10]].dtypes
Out[171]:
player object
year int64
stint int64
team object
lg object
g int64
ab int64
r int64
h int64
X2b int64
dtype: object
In [172]: bbn = bb.convert_dtypes()
In [173]: bbn[bbn.columns[:10]].dtypes
Out[173]:
player string
year Int64
stint Int64
team string
lg string
g Int64
ab Int64
r Int64
h Int64
X2b Int64
dtype: object