合并、联接、连接和比较#
Pandas提供了各种工具,可以轻松地将Series或DataFrame与连接/合并类型操作中的索引和关系代数功能的各种集合逻辑结合在一起。
此外,Pandas还提供实用程序来比较两个Series或DataFrame,并总结它们的差异。
连接对象#
这个 concat() 函数(在主PANAS名称空间中)执行沿着一个轴执行连接操作的所有繁重任务,同时在其他轴上执行索引(如果有)的可选集合逻辑(并集或交集)。请注意,我之所以说“如果有的话”,是因为级数只有一个可能的串联轴。
在深入了解以下所有细节之前 concat 它能做什么,这里有一个简单的例子:
In [1]: df1 = pd.DataFrame(
...: {
...: "A": ["A0", "A1", "A2", "A3"],
...: "B": ["B0", "B1", "B2", "B3"],
...: "C": ["C0", "C1", "C2", "C3"],
...: "D": ["D0", "D1", "D2", "D3"],
...: },
...: index=[0, 1, 2, 3],
...: )
...:
In [2]: df2 = pd.DataFrame(
...: {
...: "A": ["A4", "A5", "A6", "A7"],
...: "B": ["B4", "B5", "B6", "B7"],
...: "C": ["C4", "C5", "C6", "C7"],
...: "D": ["D4", "D5", "D6", "D7"],
...: },
...: index=[4, 5, 6, 7],
...: )
...:
In [3]: df3 = pd.DataFrame(
...: {
...: "A": ["A8", "A9", "A10", "A11"],
...: "B": ["B8", "B9", "B10", "B11"],
...: "C": ["C8", "C9", "C10", "C11"],
...: "D": ["D8", "D9", "D10", "D11"],
...: },
...: index=[8, 9, 10, 11],
...: )
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
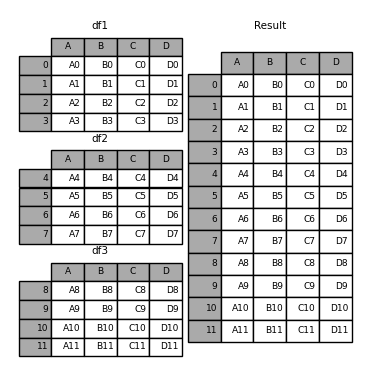
就像它在ndarray上的兄弟功能一样, numpy.concatenate , pandas.concat 获取同类类型对象的列表或字典,并将它们与“如何处理其他轴”的一些可配置处理连接在一起:
pd.concat(
objs,
axis=0,
join="outer",
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True,
)
objs:Series或DataFrame对象的序列或映射。如果传递了一个字典,则排序后的键将用作keys参数,除非它被传递,在这种情况下,这些值将被选择(见下文)。任何None对象都将静默丢弃,除非它们都为None,在这种情况下将引发ValueError。axis:{0,1,...},默认为0。要连接的轴。join:{‘INTERNAL’,‘OUTER’},默认‘OUTER’。如何处理其他轴上的索引。外部表示并集,内部表示相交。ignore_index:布尔值,默认为FALSE。如果为True,则不在串联轴上使用索引值。生成的轴将被标记为0,...,n-1。如果要串联的对象的串联轴没有有意义的索引信息,这将非常有用。请注意,连接中仍考虑其他轴上的索引值。keys:Sequence,默认为无。使用传递的键作为最外层构建分层索引。如果通过了多个级别,则应包含元组。levels:序列列表,默认为无。用于构造多索引的特定级别(唯一值)。否则,将从密钥中推断出它们。names:LIST,默认为无。生成的分层索引中的级别的名称。verify_integrity:布尔值,默认为FALSE。检查新的串联轴是否包含重复项。与实际的数据串联相比,这可能非常昂贵。copy:布尔值,默认为True。如果为False,则不要不必要地复制数据。
如果没有一点背景,这些论点中的许多都没有多大意义。让我们回顾一下上面的例子。假设我们想要将特定的键与分割的DataFrame的每个片段相关联。我们可以使用 keys 论点:
In [6]: result = pd.concat(frames, keys=["x", "y", "z"])
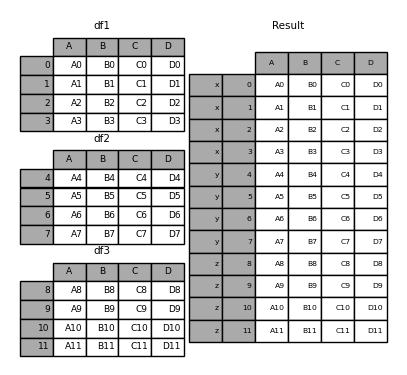
正如您所看到的(如果您已经阅读了文档的其余部分),结果对象的索引有一个 hierarchical index 。这意味着我们现在可以按键选择每个块:
In [7]: result.loc["y"]
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
要知道这是如何非常有用的,并不过分。下面是关于此功能的更多详细信息。
备注
值得注意的是, concat() (因此 append() )创建数据的完整副本,并且不断重复使用此函数可能会对性能造成重大影响。如果需要对多个数据集使用该操作,请使用列表理解。
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames)
备注
在将DataFrame与命名轴连接时,Pandas将尽可能地尝试保留这些索引/列名称。在所有输入共享公共名称的情况下,该名称将被分配给结果。当输入的名称不都一致时,结果将是未命名的。同样的道理也适用于 MultiIndex ,但逻辑是在逐级的基础上单独应用的。
在其他轴上设置逻辑#
当将多个DataFrame粘合在一起时,您可以选择如何处理其他轴(被连接的轴除外)。这可以通过以下两种方式完成:
拿他们所有人的结合来说,
join='outer'。这是默认选项,因为它会导致零信息丢失。走十字路口,
join='inner'。
下面是每种方法的一个示例。第一,缺省 join='outer' 行为:
In [8]: df4 = pd.DataFrame(
...: {
...: "B": ["B2", "B3", "B6", "B7"],
...: "D": ["D2", "D3", "D6", "D7"],
...: "F": ["F2", "F3", "F6", "F7"],
...: },
...: index=[2, 3, 6, 7],
...: )
...:
In [9]: result = pd.concat([df1, df4], axis=1)
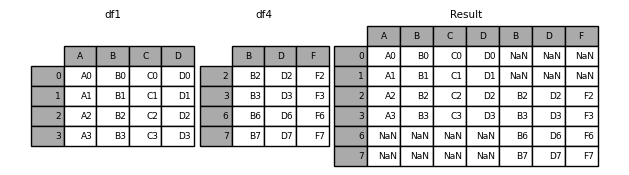
下面是同样的情况 join='inner' :
In [10]: result = pd.concat([df1, df4], axis=1, join="inner")

最后,假设我们只想重用 精确指数 从原始的DataFrame:
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
同样,我们可以在连接之前编制索引:
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

忽略级联轴上的索引#
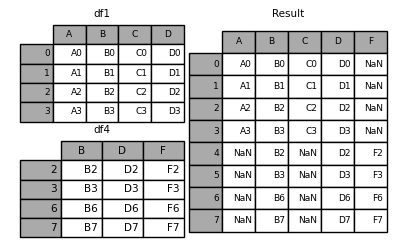
为 DataFrame 对象没有有意义的索引,您可能希望追加它们,并忽略它们可能具有重叠索引的事实。为此,请使用 ignore_index 论点:
In [13]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
使用混合ndim进行连接#
您可以串联混合的 Series 和 DataFrame 物体。这个 Series 将被转换为 DataFrame 使用列名作为 Series 。
In [14]: s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
In [15]: result = pd.concat([df1, s1], axis=1)
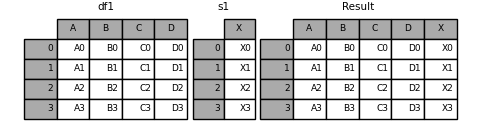
备注
因为我们要串联一个 Series 发送到 DataFrame ,我们本可以达到同样的结果 DataFrame.assign() 。串联任意数量的Pandas对象 (DataFrame 或 Series ),使用 concat 。
如果未命名 Series 如果通过,它们将被连续编号。
In [16]: s2 = pd.Series(["_0", "_1", "_2", "_3"])
In [17]: result = pd.concat([df1, s2, s2, s2], axis=1)
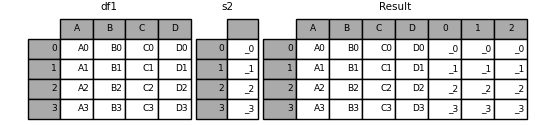
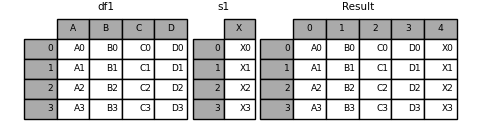
通过 ignore_index=True 将删除所有名称引用。
In [18]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
使用组密钥进行更多连接#
的一个相当常见的用法 keys 参数是在创建新的 DataFrame 基于现有的 Series 。请注意,默认行为是如何让产生的 DataFrame 继承父级 Series ‘名称,如果它们存在的话。
In [19]: s3 = pd.Series([0, 1, 2, 3], name="foo")
In [20]: s4 = pd.Series([0, 1, 2, 3])
In [21]: s5 = pd.Series([0, 1, 4, 5])
In [22]: pd.concat([s3, s4, s5], axis=1)
Out[22]:
foo 0 1
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
通过 keys 参数,则可以覆盖现有的列名。
In [23]: pd.concat([s3, s4, s5], axis=1, keys=["red", "blue", "yellow"])
Out[23]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
让我们考虑一下第一个示例的变体:
In [24]: result = pd.concat(frames, keys=["x", "y", "z"])
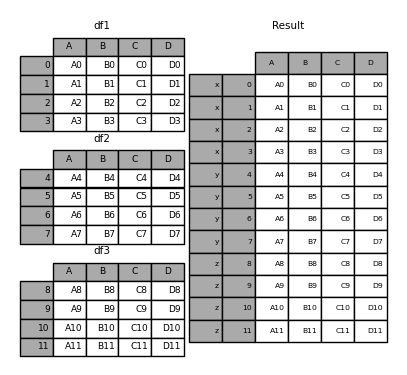
您还可以将判决传递给 concat 在这种情况下,Dict键将用于 keys 参数(除非指定了其他键):
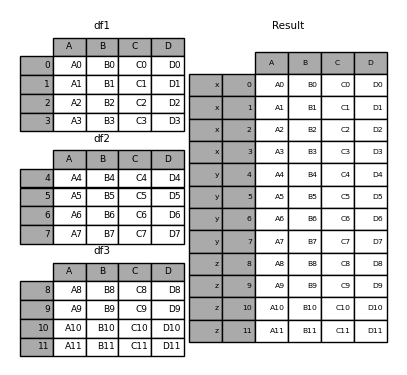
In [25]: pieces = {"x": df1, "y": df2, "z": df3}
In [26]: result = pd.concat(pieces)
In [27]: result = pd.concat(pieces, keys=["z", "y"])
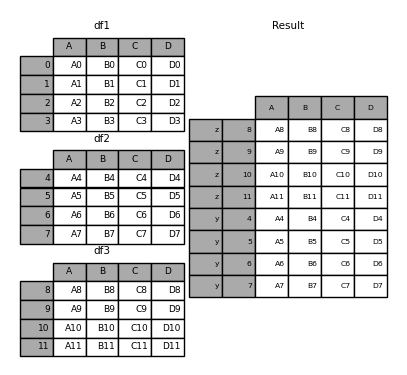
创建的多重索引具有由传递的键和 DataFrame 片断:
In [28]: result.index.levels
Out[28]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
如果希望指定其他级别(有时会出现这种情况),可以使用 levels 论点:
In [29]: result = pd.concat(
....: pieces, keys=["x", "y", "z"], levels=[["z", "y", "x", "w"]], names=["group_key"]
....: )
....:
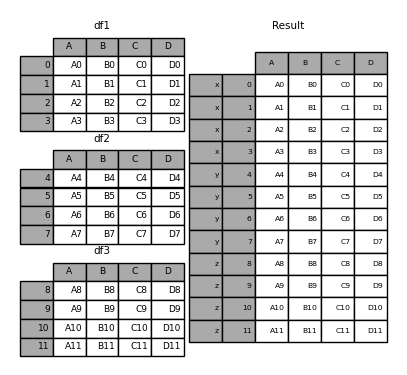
In [30]: result.index.levels
Out[30]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
这相当深奥,但它实际上对于实现GroupBy之类的东西是必要的,在这种情况下,类别变量的顺序是有意义的。
将行追加到DataFrame#
如果您希望将一个序列作为单行追加到 DataFrame ,则可以将该行转换为 DataFrame 并使用 concat
In [31]: s2 = pd.Series(["X0", "X1", "X2", "X3"], index=["A", "B", "C", "D"])
In [32]: result = pd.concat([df1, s2.to_frame().T], ignore_index=True)
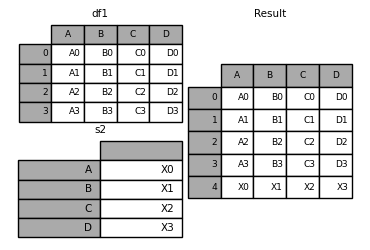
您应该使用 ignore_index 使用此方法指示DataFrame丢弃其索引。如果希望保留索引,则应构造一个适当索引的DataFrame,并追加或连接这些对象。
数据库风格的DataFrame或命名系列联接/合并#
Pandas拥有功能齐全、 高性能 内存中的连接操作习惯上非常类似于关系数据库,如SQL。这些方法的性能明显好于其他开源实现(例如 base::merge.data.frame 在R)中。其原因是仔细的算法设计和数据的内部布局 DataFrame 。
请参阅 cookbook 一些先进的策略。
熟悉SQL但不熟悉Pandas的用户可能会对 comparison with SQL 。
Pandas只有一种功能, merge() 之间的所有标准数据库连接操作的入口点 DataFrame 或命名为 Series 对象:
pd.merge(
left,
right,
how="inner",
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=True,
suffixes=("_x", "_y"),
copy=True,
indicator=False,
validate=None,
)
left:DataFrame或命名系列对象。right:另一个DataFrame或命名系列对象。on:要联接的列或索引级名称。必须在左侧和右侧的DataFrame和/或Series对象中找到。如果未通过,则left_index和right_index是False,DataFrames和/或Series中的列的交集将被推断为联接键。left_on:左侧DataFrame或Series中用作键的列或索引级。可以是列名、索引级名称,也可以是长度等于DataFrame或Series长度的数组。right_on:要用作键的正确DataFrame或Series中的列或索引级。可以是列名、索引级名称,也可以是长度等于DataFrame或Series长度的数组。left_index:如果True,则使用左侧DataFrame或Series中的索引(行标签)作为其联接键。在具有多索引(分层)的DataFrame或Series的情况下,层数必须与来自正确DataFrame或Series的联接键的数目匹配。right_index:用法与left_index适用于合适的DataFrame或系列how:其中之一'left','right','outer','inner','cross'。默认为inner。有关每种方法的更详细说明,请参见下文。sort:根据连接键按词典顺序对结果DataFrame进行排序。默认为True,设置为False在许多情况下将显著提高性能。suffixes:要应用于重叠列的字符串后缀元组。默认为('_x', '_y')。copy:始终复制数据(默认True从传递的DataFrame或命名系列对象中),即使不需要重新索引也是如此。在许多情况下无法避免,但可能会提高性能/内存使用率。可以避免复制的情况在某种程度上是病态的,但仍然提供了这种选择。indicator:将名为的列添加到输出DataFrame_merge包含有关每行来源的信息。_merge是类别类型的,并具有值left_only对于其合并键仅出现在'left'DataFrame或系列,right_only对于其合并键仅出现在'right'DataFrame或系列,以及both如果在两者中都找到了观察的合并键。validate:字符串,默认为无。如果指定,则检查合并是否为指定类型。“one_to_one”或“1:1”:检查合并项在左侧和右侧数据集中是否唯一。
“one_to_any”或“1:m”:检查合并项在左侧数据集中是否唯一。
“any_to_one”或“m:1”:检查合并项在正确的数据集中是否唯一。
“MANY_TO_MANY”或“m:m”:允许,但不会导致检查。
备注
支持将索引级别指定为 on , left_on ,以及 right_on 在版本0.23.0中添加了参数。支持合并命名的 Series 在版本0.24.0中添加了对象。
返回类型将与 left 。如果 left 是一种 DataFrame 或命名为 Series 和 right 是的子类 DataFrame ,则返回类型仍将为 DataFrame 。
merge 是Pandas命名空间中的一个函数,它还可以作为 DataFrame 实例方法 merge() ,伴随着呼唤 DataFrame 被隐式视为联接中的左对象。
相关的 join() 方法,使用 merge 在内部用于索引时索引(默认情况下)和索引时列联接。如果您仅在索引上连接,则可能希望使用 DataFrame.join 省去了打字的麻烦。
合并方法入门简介(关系代数)#
有经验的关系数据库(如SQL)用户将熟悉用于描述两个SQL表结构之间的连接操作的术语 (DataFrame 对象)。有几种情况需要考虑,了解这些情况非常重要:
one-to-one 联接:例如,在联接两个
DataFrame对象的索引(必须包含唯一值)。many-to-one 联接:例如,将索引(唯一)联接到不同
DataFrame。many-to-many 联接:联接柱上的柱。
备注
当联接列上的列时(可能是多对多联接), DataFrame 对象 将被丢弃 。
有必要花一些时间来了解 many-to-many 加入案例。在SQL/标准关系代数中,如果一个键组合在两个表中出现多次,则结果表将具有 笛卡尔乘积 关联数据的。以下是一个具有唯一组合键的非常基本的示例:
In [33]: left = pd.DataFrame(
....: {
....: "key": ["K0", "K1", "K2", "K3"],
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: }
....: )
....:
In [34]: right = pd.DataFrame(
....: {
....: "key": ["K0", "K1", "K2", "K3"],
....: "C": ["C0", "C1", "C2", "C3"],
....: "D": ["D0", "D1", "D2", "D3"],
....: }
....: )
....:
In [35]: result = pd.merge(left, right, on="key")
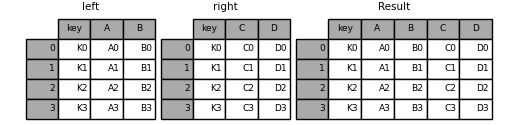
下面是一个具有多个连接键的更复杂的示例。只有出现在 left 和 right 都存在(交叉口),因为 how='inner' 默认情况下。
In [36]: left = pd.DataFrame(
....: {
....: "key1": ["K0", "K0", "K1", "K2"],
....: "key2": ["K0", "K1", "K0", "K1"],
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: }
....: )
....:
In [37]: right = pd.DataFrame(
....: {
....: "key1": ["K0", "K1", "K1", "K2"],
....: "key2": ["K0", "K0", "K0", "K0"],
....: "C": ["C0", "C1", "C2", "C3"],
....: "D": ["D0", "D1", "D2", "D3"],
....: }
....: )
....:
In [38]: result = pd.merge(left, right, on=["key1", "key2"])

这个 how 参数为 merge 指定如何确定要包括在结果表中的键。如果是组合键 不会出现 在左侧或右侧的表中,连接表中的值将为 NA 。以下是以下内容的摘要 how 选项及其SQL等效名称:
合并方法 |
SQL联接名称 |
描述 |
|---|---|---|
|
|
仅从左帧使用关键点 |
|
|
仅使用来自右帧的关键点 |
|
|
使用来自两个帧的关键点的并集 |
|
|
使用来自两个帧的关键点的交集 |
|
|
创建两个帧的行的笛卡尔乘积 |
In [39]: result = pd.merge(left, right, how="left", on=["key1", "key2"])
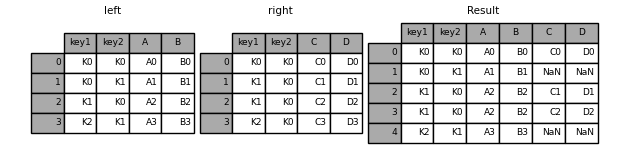
In [40]: result = pd.merge(left, right, how="right", on=["key1", "key2"])

In [41]: result = pd.merge(left, right, how="outer", on=["key1", "key2"])
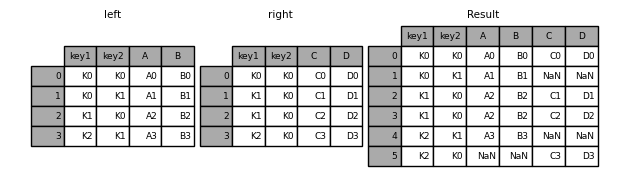
In [42]: result = pd.merge(left, right, how="inner", on=["key1", "key2"])

In [43]: result = pd.merge(left, right, how="cross")
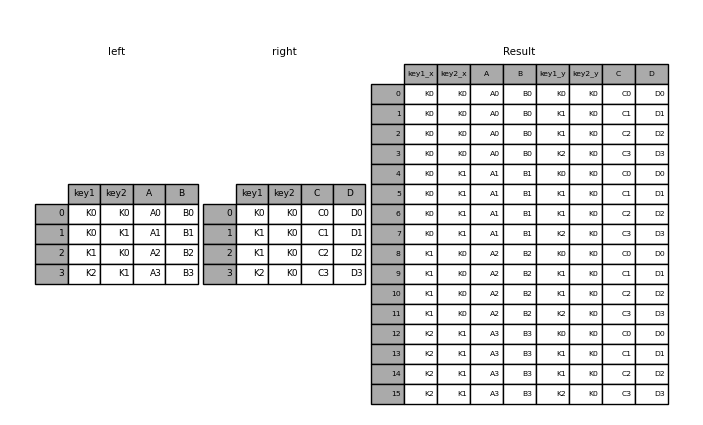
如果多索引的名称与DataFrame中的列相对应,则可以合并多索引序列和DataFrame。使用将系列转换为DataFrame Series.reset_index() 在合并之前,如下例所示。
In [44]: df = pd.DataFrame({"Let": ["A", "B", "C"], "Num": [1, 2, 3]})
In [45]: df
Out[45]:
Let Num
0 A 1
1 B 2
2 C 3
In [46]: ser = pd.Series(
....: ["a", "b", "c", "d", "e", "f"],
....: index=pd.MultiIndex.from_arrays(
....: [["A", "B", "C"] * 2, [1, 2, 3, 4, 5, 6]], names=["Let", "Num"]
....: ),
....: )
....:
In [47]: ser
Out[47]:
Let Num
A 1 a
B 2 b
C 3 c
A 4 d
B 5 e
C 6 f
dtype: object
In [48]: pd.merge(df, ser.reset_index(), on=["Let", "Num"])
Out[48]:
Let Num 0
0 A 1 a
1 B 2 b
2 C 3 c
以下是DataFrames中具有重复联接键的另一个示例:
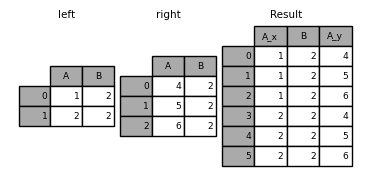
In [49]: left = pd.DataFrame({"A": [1, 2], "B": [2, 2]})
In [50]: right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
In [51]: result = pd.merge(left, right, on="B", how="outer")
警告
在重复关键点上联接/合并可能会导致返回的帧是行维度的乘积,这可能会导致内存溢出。用户有责任在加入大型DataFrame之前管理键中的重复值。
正在检查重复的密钥#
用户可以使用 validate 参数自动检查它们的合并项中是否有意外的重复项。键唯一性在合并操作之前检查,因此应防止内存溢出。检查键的唯一性也是确保用户数据结构符合预期的好方法。
在下面的示例中,存在重复的 B 在右边 DataFrame 。因为这不是一对一的合并--如 validate 参数--将引发异常。
In [52]: left = pd.DataFrame({"A": [1, 2], "B": [1, 2]})
In [53]: right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
In [53]: result = pd.merge(left, right, on="B", how="outer", validate="one_to_one")
...
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
如果用户知道右侧的重复项 DataFrame 但要确保左侧DataFrame中没有重复项,则可以使用 validate='one_to_many' 参数,这不会引发异常。
In [54]: pd.merge(left, right, on="B", how="outer", validate="one_to_many")
Out[54]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
合并指示器#
merge() 接受参数 indicator 。如果 True ,一个类别类型的列,名为 _merge 将被添加到具有以下值的输出对象:
观测原点
_merge价值仅在中合并关键字
'left'框架
left_only仅在中合并关键字
'right'框架
right_only合并两个帧中的关键点
both
In [55]: df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]})
In [56]: df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]})
In [57]: pd.merge(df1, df2, on="col1", how="outer", indicator=True)
Out[57]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
这个 indicator 参数还将接受字符串参数,在这种情况下,指示器函数将使用传递的字符串的值作为指示符列的名称。
In [58]: pd.merge(df1, df2, on="col1", how="outer", indicator="indicator_column")
Out[58]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
合并数据类型#
合并将保留连接键的数据类型。
In [59]: left = pd.DataFrame({"key": [1], "v1": [10]})
In [60]: left
Out[60]:
key v1
0 1 10
In [61]: right = pd.DataFrame({"key": [1, 2], "v1": [20, 30]})
In [62]: right
Out[62]:
key v1
0 1 20
1 2 30
我们能够保留联接密钥:
In [63]: pd.merge(left, right, how="outer")
Out[63]:
key v1
0 1 10
1 1 20
2 2 30
In [64]: pd.merge(left, right, how="outer").dtypes
Out[64]:
key int64
v1 int64
dtype: object
当然,如果引入了缺少的值,那么结果数据类型将被向上转换。
In [65]: pd.merge(left, right, how="outer", on="key")
Out[65]:
key v1_x v1_y
0 1 10.0 20
1 2 NaN 30
In [66]: pd.merge(left, right, how="outer", on="key").dtypes
Out[66]:
key int64
v1_x float64
v1_y int64
dtype: object
合并将保留 category Mergands的dtype。另请参阅 categoricals 。
左边的画框。
In [67]: from pandas.api.types import CategoricalDtype
In [68]: X = pd.Series(np.random.choice(["foo", "bar"], size=(10,)))
In [69]: X = X.astype(CategoricalDtype(categories=["foo", "bar"]))
In [70]: left = pd.DataFrame(
....: {"X": X, "Y": np.random.choice(["one", "two", "three"], size=(10,))}
....: )
....:
In [71]: left
Out[71]:
X Y
0 bar one
1 foo one
2 foo three
3 bar three
4 foo one
5 bar one
6 bar three
7 bar three
8 bar three
9 foo three
In [72]: left.dtypes
Out[72]:
X category
Y object
dtype: object
正确的画面。
In [73]: right = pd.DataFrame(
....: {
....: "X": pd.Series(["foo", "bar"], dtype=CategoricalDtype(["foo", "bar"])),
....: "Z": [1, 2],
....: }
....: )
....:
In [74]: right
Out[74]:
X Z
0 foo 1
1 bar 2
In [75]: right.dtypes
Out[75]:
X category
Z int64
dtype: object
合并后的结果:
In [76]: result = pd.merge(left, right, how="outer")
In [77]: result
Out[77]:
X Y Z
0 bar one 2
1 bar three 2
2 bar one 2
3 bar three 2
4 bar three 2
5 bar three 2
6 foo one 1
7 foo three 1
8 foo one 1
9 foo three 1
In [78]: result.dtypes
Out[78]:
X category
Y object
Z int64
dtype: object
备注
类别数据类型必须为 一点儿没错 相同,表示相同的类别和有序属性。否则,结果将强制为类别的dtype。
备注
合并在一起 category 与相同的数据类型相比,相同的数据类型的性能可能相当高 object 数据类型合并。
对索引进行联接#
DataFrame.join() 是组合两个索引可能不同的列的便捷方法 DataFrames 整合到一个结果中 DataFrame 。下面是一个非常基本的例子:
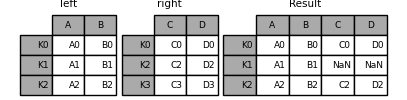
In [79]: left = pd.DataFrame(
....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
....: )
....:
In [80]: right = pd.DataFrame(
....: {"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
....: )
....:
In [81]: result = left.join(right)
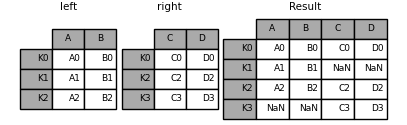
In [82]: result = left.join(right, how="outer")
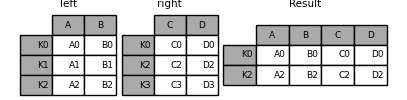
与上面相同,但使用 how='inner' 。
In [83]: result = left.join(right, how="inner")
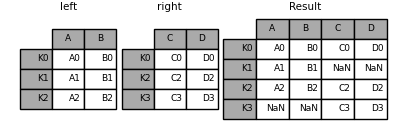
这里的数据对齐在索引(行标签)上。使用以下命令可以实现相同的行为 merge 外加指示它使用索引的其他参数:
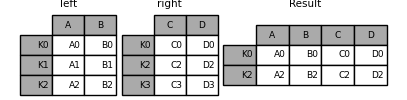
In [84]: result = pd.merge(left, right, left_index=True, right_index=True, how="outer")
In [85]: result = pd.merge(left, right, left_index=True, right_index=True, how="inner")
联接索引上的键列#
join() 采用可选的 on 参数,该参数可以是一列或多个列名,该参数指定传递的 DataFrame 中该列对齐 DataFrame 。这两个函数调用完全等价:
left.join(right, on=key_or_keys)
pd.merge(
left, right, left_on=key_or_keys, right_index=True, how="left", sort=False
)
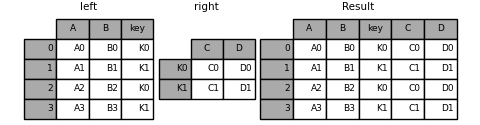
显然,您可以选择您认为更方便的任何形式。对于多对一连接(其中一个 DataFrame 的已由连接键索引),使用 join 可能会更方便。下面是一个简单的例子:
In [86]: left = pd.DataFrame(
....: {
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: "key": ["K0", "K1", "K0", "K1"],
....: }
....: )
....:
In [87]: right = pd.DataFrame({"C": ["C0", "C1"], "D": ["D0", "D1"]}, index=["K0", "K1"])
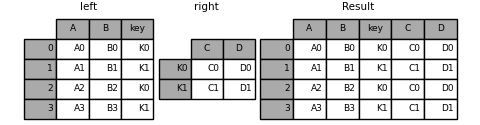
In [88]: result = left.join(right, on="key")
In [89]: result = pd.merge(
....: left, right, left_on="key", right_index=True, how="left", sort=False
....: )
....:
若要联接多个键,传递的DataFrame必须具有 MultiIndex :
In [90]: left = pd.DataFrame(
....: {
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: "key1": ["K0", "K0", "K1", "K2"],
....: "key2": ["K0", "K1", "K0", "K1"],
....: }
....: )
....:
In [91]: index = pd.MultiIndex.from_tuples(
....: [("K0", "K0"), ("K1", "K0"), ("K2", "K0"), ("K2", "K1")]
....: )
....:
In [92]: right = pd.DataFrame(
....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=index
....: )
....:
现在,可以通过传递两个键列名称将其连接起来:
In [93]: result = left.join(right, on=["key1", "key2"])
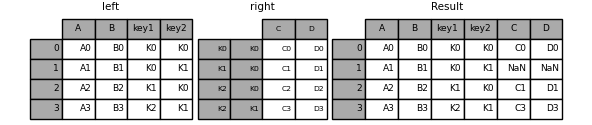
的默认设置 DataFrame.join 是执行左联接(对于Excel用户,本质上是“VLOOKUP”操作),它只使用在调用DataFrame中找到的键。可以同样轻松地执行其他联接类型,例如内部联接:
In [94]: result = left.join(right, on=["key1", "key2"], how="inner")
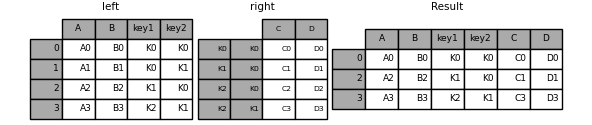
如您所见,这将删除所有不匹配的行。
将单个索引连接到多个索引#
您可以联接单个索引的 DataFrame 具有多索引级别的 DataFrame 。该级别将根据单索引框架的索引名称与多索引框架的级别名称进行匹配。
In [95]: left = pd.DataFrame(
....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]},
....: index=pd.Index(["K0", "K1", "K2"], name="key"),
....: )
....:
In [96]: index = pd.MultiIndex.from_tuples(
....: [("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")],
....: names=["key", "Y"],
....: )
....:
In [97]: right = pd.DataFrame(
....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]},
....: index=index,
....: )
....:
In [98]: result = left.join(right, how="inner")
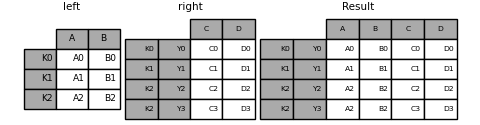
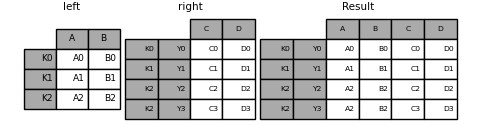
这是等价的,但不那么冗长,并且比这更高效/更快。
In [99]: result = pd.merge(
....: left.reset_index(), right.reset_index(), on=["key"], how="inner"
....: ).set_index(["key","Y"])
....:
使用两个多指标进行连接#
如果在联接中完全使用了右参数的索引,并且是左参数中索引的子集,则这种支持是有限的,如下例所示:
In [100]: leftindex = pd.MultiIndex.from_product(
.....: [list("abc"), list("xy"), [1, 2]], names=["abc", "xy", "num"]
.....: )
.....:
In [101]: left = pd.DataFrame({"v1": range(12)}, index=leftindex)
In [102]: left
Out[102]:
v1
abc xy num
a x 1 0
2 1
y 1 2
2 3
b x 1 4
2 5
y 1 6
2 7
c x 1 8
2 9
y 1 10
2 11
In [103]: rightindex = pd.MultiIndex.from_product(
.....: [list("abc"), list("xy")], names=["abc", "xy"]
.....: )
.....:
In [104]: right = pd.DataFrame({"v2": [100 * i for i in range(1, 7)]}, index=rightindex)
In [105]: right
Out[105]:
v2
abc xy
a x 100
y 200
b x 300
y 400
c x 500
y 600
In [106]: left.join(right, on=["abc", "xy"], how="inner")
Out[106]:
v1 v2
abc xy num
a x 1 0 100
2 1 100
y 1 2 200
2 3 200
b x 1 4 300
2 5 300
y 1 6 400
2 7 400
c x 1 8 500
2 9 500
y 1 10 600
2 11 600
如果不满足该条件,则可以使用以下代码完成与两个多索引的连接。
In [107]: leftindex = pd.MultiIndex.from_tuples(
.....: [("K0", "X0"), ("K0", "X1"), ("K1", "X2")], names=["key", "X"]
.....: )
.....:
In [108]: left = pd.DataFrame(
.....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=leftindex
.....: )
.....:
In [109]: rightindex = pd.MultiIndex.from_tuples(
.....: [("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")], names=["key", "Y"]
.....: )
.....:
In [110]: right = pd.DataFrame(
.....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=rightindex
.....: )
.....:
In [111]: result = pd.merge(
.....: left.reset_index(), right.reset_index(), on=["key"], how="inner"
.....: ).set_index(["key", "X", "Y"])
.....:
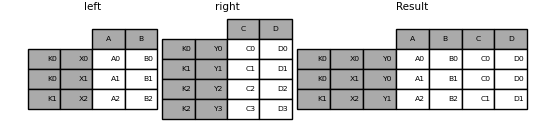
在列和索引级的组合上合并#
字符串作为 on , left_on ,以及 right_on 参数可以引用列名或索引级名称。这使合并成为可能 DataFrame 实例的索引级别和列的组合而不重置索引。
In [112]: left_index = pd.Index(["K0", "K0", "K1", "K2"], name="key1")
In [113]: left = pd.DataFrame(
.....: {
.....: "A": ["A0", "A1", "A2", "A3"],
.....: "B": ["B0", "B1", "B2", "B3"],
.....: "key2": ["K0", "K1", "K0", "K1"],
.....: },
.....: index=left_index,
.....: )
.....:
In [114]: right_index = pd.Index(["K0", "K1", "K2", "K2"], name="key1")
In [115]: right = pd.DataFrame(
.....: {
.....: "C": ["C0", "C1", "C2", "C3"],
.....: "D": ["D0", "D1", "D2", "D3"],
.....: "key2": ["K0", "K0", "K0", "K1"],
.....: },
.....: index=right_index,
.....: )
.....:
In [116]: result = left.merge(right, on=["key1", "key2"])
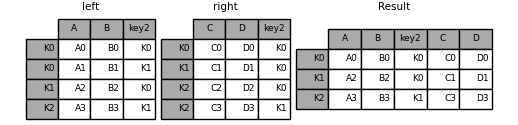
备注
当在与两个帧中的索引级别匹配的字符串上合并DataFrame时,该索引级别将作为索引级别保留在生成的DataFrame中。
备注
仅使用数据帧的某些级别合并数据帧时 MultiIndex ,额外的级别将从产生的合并中删除。为了保持这些级别,请使用 reset_index 在执行合并之前,在这些标高名称上将这些标高移动到列。
备注
如果字符串同时匹配列名和索引级名称,则会发出警告,并且该列优先。这将在将来的版本中导致歧义错误。
重叠的值列#
合并 suffixes 参数接受字符串列表的元组,以追加到输入中重叠的列名 DataFrame 要消除结果列的歧义,请执行以下操作:
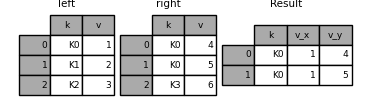
In [117]: left = pd.DataFrame({"k": ["K0", "K1", "K2"], "v": [1, 2, 3]})
In [118]: right = pd.DataFrame({"k": ["K0", "K0", "K3"], "v": [4, 5, 6]})
In [119]: result = pd.merge(left, right, on="k")
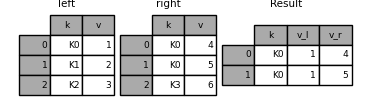
In [120]: result = pd.merge(left, right, on="k", suffixes=("_l", "_r"))
DataFrame.join() 有 lsuffix 和 rsuffix 行为相似的论据。
In [121]: left = left.set_index("k")
In [122]: right = right.set_index("k")
In [123]: result = left.join(right, lsuffix="_l", rsuffix="_r")
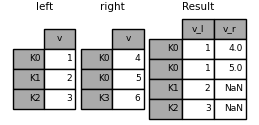
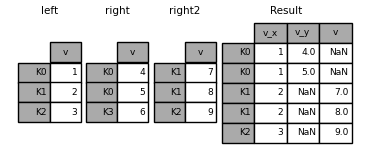
加入多个DataFrame#
的列表或元组 DataFrames 也可以传递给 join() 在索引上将它们连接在一起。
In [124]: right2 = pd.DataFrame({"v": [7, 8, 9]}, index=["K1", "K1", "K2"])
In [125]: result = left.join([right, right2])
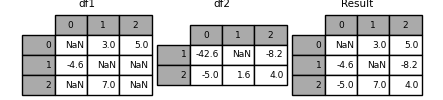
将Series或DataFrame列中的值合并在一起#
另一种相当常见的情况是有两个相似的索引(或类似的索引) Series 或 DataFrame 对象,并希望从一个对象中的值“修补”另一个对象中的值以匹配索引。下面是一个例子:
In [126]: df1 = pd.DataFrame(
.....: [[np.nan, 3.0, 5.0], [-4.6, np.nan, np.nan], [np.nan, 7.0, np.nan]]
.....: )
.....:
In [127]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5.0, 1.6, 4]], index=[1, 2])
为此,请使用 combine_first() 方法:
In [128]: result = df1.combine_first(df2)
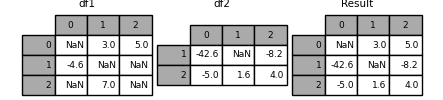
请注意,此方法只接受右侧的值 DataFrame 如果他们在左边不见了 DataFrame 。一种相关的方法, update() ,更改非NA值:
In [129]: df1.update(df2)
TimeSeries友好合并#
合并有序数据#
A merge_ordered() 功能允许组合时间序列和其他有序数据。特别是,它有一个可选的 fill_method 用于填充/插入缺失数据的关键字:
In [130]: left = pd.DataFrame(
.....: {"k": ["K0", "K1", "K1", "K2"], "lv": [1, 2, 3, 4], "s": ["a", "b", "c", "d"]}
.....: )
.....:
In [131]: right = pd.DataFrame({"k": ["K1", "K2", "K4"], "rv": [1, 2, 3]})
In [132]: pd.merge_ordered(left, right, fill_method="ffill", left_by="s")
Out[132]:
k lv s rv
0 K0 1.0 a NaN
1 K1 1.0 a 1.0
2 K2 1.0 a 2.0
3 K4 1.0 a 3.0
4 K1 2.0 b 1.0
5 K2 2.0 b 2.0
6 K4 2.0 b 3.0
7 K1 3.0 c 1.0
8 K2 3.0 c 2.0
9 K4 3.0 c 3.0
10 K1 NaN d 1.0
11 K2 4.0 d 2.0
12 K4 4.0 d 3.0
合并截止日期#
A merge_asof() 类似于有序的左连接,不同之处在于我们匹配的是最近的键而不是相等的键。中的每一行 left DataFrame 中的最后一行 right DataFrame 谁的 on 钥匙比左边的钥匙小。两个DataFrame都必须按键排序。
可选地,ASOF合并可以执行分组合并。这与 by 上最接近的匹配项之外, on 钥匙。
例如,我们可能有 trades 和 quotes 我们想要 asof 把它们合并。
In [133]: trades = pd.DataFrame(
.....: {
.....: "time": pd.to_datetime(
.....: [
.....: "20160525 13:30:00.023",
.....: "20160525 13:30:00.038",
.....: "20160525 13:30:00.048",
.....: "20160525 13:30:00.048",
.....: "20160525 13:30:00.048",
.....: ]
.....: ),
.....: "ticker": ["MSFT", "MSFT", "GOOG", "GOOG", "AAPL"],
.....: "price": [51.95, 51.95, 720.77, 720.92, 98.00],
.....: "quantity": [75, 155, 100, 100, 100],
.....: },
.....: columns=["time", "ticker", "price", "quantity"],
.....: )
.....:
In [134]: quotes = pd.DataFrame(
.....: {
.....: "time": pd.to_datetime(
.....: [
.....: "20160525 13:30:00.023",
.....: "20160525 13:30:00.023",
.....: "20160525 13:30:00.030",
.....: "20160525 13:30:00.041",
.....: "20160525 13:30:00.048",
.....: "20160525 13:30:00.049",
.....: "20160525 13:30:00.072",
.....: "20160525 13:30:00.075",
.....: ]
.....: ),
.....: "ticker": ["GOOG", "MSFT", "MSFT", "MSFT", "GOOG", "AAPL", "GOOG", "MSFT"],
.....: "bid": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],
.....: "ask": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03],
.....: },
.....: columns=["time", "ticker", "bid", "ask"],
.....: )
.....:
In [135]: trades
Out[135]:
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
In [136]: quotes
Out[136]:
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
默认情况下,我们采用报价的截止日期。
In [137]: pd.merge_asof(trades, quotes, on="time", by="ticker")
Out[137]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
我们只是在内心深处 2ms 在报价时间和交易时间之间。
In [138]: pd.merge_asof(trades, quotes, on="time", by="ticker", tolerance=pd.Timedelta("2ms"))
Out[138]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
我们只是在内心深处 10ms 在报价时间和交易时间之间,我们排除了准确匹配的时间。请注意,虽然我们排除了(引号的)完全匹配,但前面的引号 do 传播到那个时间点。
In [139]: pd.merge_asof(
.....: trades,
.....: quotes,
.....: on="time",
.....: by="ticker",
.....: tolerance=pd.Timedelta("10ms"),
.....: allow_exact_matches=False,
.....: )
.....:
Out[139]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
比较对象#
这个 compare() 和 compare() 方法使您可以分别比较两个DataFrame或Series,并总结它们的差异。
此功能是在 V1.1.0 。
例如,您可能想要比较两个 DataFrame 并将他们的分歧并排堆积在一起。
In [140]: df = pd.DataFrame(
.....: {
.....: "col1": ["a", "a", "b", "b", "a"],
.....: "col2": [1.0, 2.0, 3.0, np.nan, 5.0],
.....: "col3": [1.0, 2.0, 3.0, 4.0, 5.0],
.....: },
.....: columns=["col1", "col2", "col3"],
.....: )
.....:
In [141]: df
Out[141]:
col1 col2 col3
0 a 1.0 1.0
1 a 2.0 2.0
2 b 3.0 3.0
3 b NaN 4.0
4 a 5.0 5.0
In [142]: df2 = df.copy()
In [143]: df2.loc[0, "col1"] = "c"
In [144]: df2.loc[2, "col3"] = 4.0
In [145]: df2
Out[145]:
col1 col2 col3
0 c 1.0 1.0
1 a 2.0 2.0
2 b 3.0 4.0
3 b NaN 4.0
4 a 5.0 5.0
In [146]: df.compare(df2)
Out[146]:
col1 col3
self other self other
0 a c NaN NaN
2 NaN NaN 3.0 4.0
默认情况下,如果两个对应的值相等,则它们将显示为 NaN 。此外,如果整行/整列中的所有值,则该行/列将从结果中省略。其余的差异将在列上对齐。
如果您愿意,您可以选择按行堆叠差异。
In [147]: df.compare(df2, align_axis=0)
Out[147]:
col1 col3
0 self a NaN
other c NaN
2 self NaN 3.0
other NaN 4.0
如果希望保留所有原始行和列,请设置 keep_shape 参数为 True 。
In [148]: df.compare(df2, keep_shape=True)
Out[148]:
col1 col2 col3
self other self other self other
0 a c NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN 3.0 4.0
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
您也可以保留所有原始值,即使它们是相等的。
In [149]: df.compare(df2, keep_shape=True, keep_equal=True)
Out[149]:
col1 col2 col3
self other self other self other
0 a c 1.0 1.0 1.0 1.0
1 a a 2.0 2.0 2.0 2.0
2 b b 3.0 3.0 3.0 4.0
3 b b NaN NaN 4.0 4.0
4 a a 5.0 5.0 5.0 5.0