scipy.stats.nhypergeom¶
- scipy.stats.nhypergeom = <scipy.stats._discrete_distns.nhypergeom_gen object>[源代码]¶
负的超几何离散随机变量。
考虑一个包含以下内容的盒子 \(M\) 球:, \(n\) 红色和 \(M-n\) 蓝色。我们从盒子里随机抽取球,一次一个,然后 没有 替换,直到我们选好 \(r\) 蓝色的球。
nhypergeom是红球数量的分布 \(k\) 我们已经选好了。作为
rv_discrete班级,nhypergeom对象从它继承一组泛型方法(完整列表请参见下面),并用特定于此特定发行版的详细信息来完成它们。注意事项
用于表示形状参数的符号 (M , n ,以及 r )并不是被普遍接受的。有关此处使用的定义的说明,请参阅示例。
概率质量函数被定义为,
\[F(k;M,n,r)=\frac{k+r-1}\choose{k}}{{M-r-k}\choose{n-k} {{M\Choose n}}\]为 \(k \in [0, n]\) , \(n \in [0, M]\) , \(r \in [0, M-n]\) ,二项式系数为:
\[\binom{n}{k}\EQUIV\FRAC{n!}{k!(n-k)}。\]这相当于观察 \(k\) 在以下方面取得的成功 \(k+r-1\) 样本: \(k+r\) 这个样本是失败的。前者可以用超几何分布建模。后者的概率简单地说就是剩余的失败次数。 \(M-n-(r-1)\) 除以剩余人口的数量 \(M-(k+r-1)\) 。此关系可以显示为:
\[NHG(k;M,n,r)=HG(k;M,n,k+r-1)\frac{(M-n-(r-1))}{(M-(k+r-1)}\]哪里 \(NHG\) 是负超几何分布的概率质量函数(PMF),并且 \(HG\) 是超几何分布的PMF。
上面的概率质量函数是以“标准化”形式定义的。若要移动分布,请使用
loc参数。具体地说,nhypergeom.pmf(k, M, n, r, loc)等同于nhypergeom.pmf(k - loc, M, n, r)。参考文献
- 1
维基百科https://en.wikipedia.org/wiki/Negative_hypergeometric_distribution上的负超几何分布
- 2
来自http://www.math.wm.edu/~leemis/chart/UDR/PDFs/Negativehypergeometric.pdf的负超几何分布
示例
>>> from scipy.stats import nhypergeom >>> import matplotlib.pyplot as plt
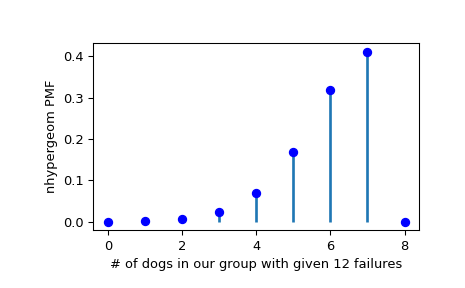
假设我们收集了20只动物,其中7只是狗。然后,如果我们想知道在正好有12只不是狗(失败)的动物的样本中找到给定数量的狗(成功)的概率,我们可以初始化冻结分布并绘制概率质量函数:
>>> M, n, r = [20, 7, 12] >>> rv = nhypergeom(M, n, r) >>> x = np.arange(0, n+2) >>> pmf_dogs = rv.pmf(x)
>>> fig = plt.figure() >>> ax = fig.add_subplot(111) >>> ax.plot(x, pmf_dogs, 'bo') >>> ax.vlines(x, 0, pmf_dogs, lw=2) >>> ax.set_xlabel('# of dogs in our group with given 12 failures') >>> ax.set_ylabel('nhypergeom PMF') >>> plt.show()
除了使用冻结分发之外,我们还可以使用
nhypergeom方法采用直接法。例如,要获得概率质量函数,请使用:>>> prb = nhypergeom.pmf(x, M, n, r)
并生成随机数:
>>> R = nhypergeom.rvs(M, n, r, size=10)
要验证以下各项之间的关系,请执行以下操作
hypergeom和nhypergeom,请使用:>>> from scipy.stats import hypergeom, nhypergeom >>> M, n, r = 45, 13, 8 >>> k = 6 >>> nhypergeom.pmf(k, M, n, r) 0.06180776620271643 >>> hypergeom.pmf(k, M, n, k+r-1) * (M - n - (r-1)) / (M - (k+r-1)) 0.06180776620271644
方法:
rvs(M, n, r, loc=0, size=1, random_state=None)
随机变量。
pmf(k, M, n, r, loc=0)
概率质量函数。
logpmf(k, M, n, r, loc=0)
概率质量函数的对数。
cdf(k, M, n, r, loc=0)
累积分布函数。
logcdf(k, M, n, r, loc=0)
累积分布函数的日志。
sf(k, M, n, r, loc=0)
生存函数(也定义为
1 - cdf,但是 sf 有时更准确)。logsf(k, M, n, r, loc=0)
生存函数的对数。
ppf(q, M, n, r, loc=0)
百分点数函数(与
cdf-百分位数)。isf(q, M, n, r, loc=0)
逆生存函数(逆
sf)。stats(M, n, r, loc=0, moments='mv')
均值(‘m’)、方差(‘v’)、偏斜(‘s’)和/或峰度(‘k’)。
entropy(M, n, r, loc=0)
房车的(微分)熵。
expect(func, args=(M, n, r), loc=0, lb=None, ub=None, conditional=False)
函数相对于分布的期望值(只有一个参数)。
median(M, n, r, loc=0)
分布的中位数。
mean(M, n, r, loc=0)
分布的平均值。
var(M, n, r, loc=0)
分布的方差。
std(M, n, r, loc=0)
分布的标准差。
interval(alpha, M, n, r, loc=0)
包含分数Alpha的范围的端点 [0, 1] 分布的