

读写时间序列#
内置读卡器#
自从 TimeSeries 和 BinnedTimeSeries 是的子类 Table ,他们有 read() 和 write() 方法,这些方法可用于从文件中读取和写入时间序列。我们在中包含一些定义良好的格式的读取器 astropy.timeseries. For instance we have readers for light curves in FITS format from the Kepler 和 TESS 任务。
例子#
在这个使用开普勒拟合时间序列的演示中,我们首先获取一个示例文件:
from astropy.utils.data import get_pkg_data_filename
example_data = get_pkg_data_filename('timeseries/kplr010666592-2009131110544_slc.fits')
备注
此处提供的光曲线是为示例目的而手动选择的。要使用Python获取其他用于科学目的的开普勒光曲线,请参见 astroquery 附属套餐。
这将设置 example_data 下载文件的文件名(这样您就可以用要读入的文件的文件名替换它)。然后我们可以使用以下方法读取时间序列:
from astropy.timeseries import TimeSeries
kepler = TimeSeries.read(example_data, format='kepler.fits', unit_parse_strict='silent')
现在我们可以检查时间序列是否已正确读入:
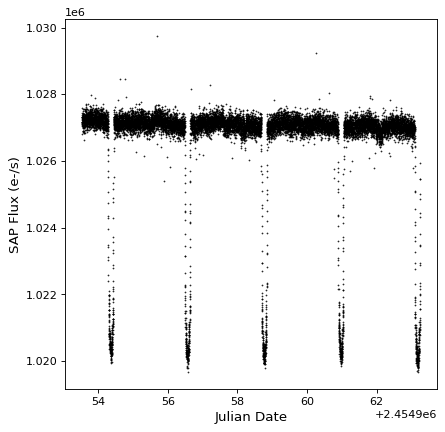
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot(kepler.time.jd, kepler['sap_flux'], 'k.', markersize=1)
ax.set(xlabel='Julian Date', ylabel='SAP Flux (e-/s)')
{kind=link}
{kind=link}
读取常用灯光曲线格式#
目前只有少数格式在中定义 astropy 它本身,部分原因是存储时间序列的文档格式不多。因此,在许多情况下,您可能必须首先使用更通用的 Table 类(见) 表格数据 ). 事实上 TimeSeries.read 和 BinnedTimeSeries.read 方法可以在幕后完成此操作。如果任何时间序列读取器都无法读取该表,则这些方法将尝试使用某些默认值 Table 然后要求用户指定重要列的名称。
实例#
如果你正在读取一个名为 sampled.csv 调用时间列的位置 Date 是一个ISO字符串,您可以:
>>> from astropy.timeseries import TimeSeries
>>> from astropy.utils.data import get_pkg_data_filename
>>> sampled_filename = get_pkg_data_filename('data/sampled.csv',
... package='astropy.timeseries.tests')
>>> ts = TimeSeries.read(sampled_filename, format='ascii.csv',
... time_column='Date')
>>> ts[:3]
<TimeSeries length=3>
time A B C D E F G
Time float64 float64 float64 float64 float64 float64 float64
----------------------- ------- ------- ------- ------- ------- ------- -------
2008-03-18 00:00:00.000 24.68 164.93 114.73 26.27 19.21 28.87 63.44
2008-03-19 00:00:00.000 24.18 164.89 114.75 26.22 19.07 27.76 59.98
2008-03-20 00:00:00.000 23.99 164.63 115.04 25.78 19.01 27.04 59.61
如果您正在从一个名为 binned.csv 还有一根柱子 time_start 给出开始时间和 bin_size 给出每个垃圾箱的大小,你可以:
>>> from astropy import units as u
>>> from astropy.timeseries import BinnedTimeSeries
>>> binned_filename = get_pkg_data_filename('data/binned.csv',
... package='astropy.timeseries.tests')
>>> ts = BinnedTimeSeries.read(binned_filename, format='ascii.csv',
... time_bin_start_column='time_start',
... time_bin_size_column='bin_size',
... time_bin_size_unit=u.s)
>>> ts[:3]
<BinnedTimeSeries length=3>
time_bin_start time_bin_size ... E F
s ...
Time float64 ... float64 float64
----------------------- ------------- ... ------- -------
2016-03-22T12:30:31.000 3.0 ... 28.87 63.44
2016-03-22T12:30:34.000 3.0 ... 27.76 59.98
2016-03-22T12:30:37.000 3.0 ... 27.04 59.61
参见文档 TimeSeries.read 和 BinnedTimeSeries.read 了解更多详细信息。
或者,可以使用自己的代码读入表,然后构造 TimeSeries 对象,如中所述 创建时间序列 ,但你不能用同样的格式写出另一个时间序列。
如果你写了一个常用格式的读者/作者,请随时投稿给 astropy 你说什么?