

数据表 (astropy.table )#
介绍#
astropy.table 提供了一套灵活且易于使用的工具,用于使用基于 numpy .除了基本的表创建、访问和修改操作外,主要功能还包括:
支持占星术柱 time , coordinates ,而且 quantities .
支持多层面和 structured array columns .
维护列的单位、描述和格式。
为表和各个列提供灵活的元数据结构。
表演 表操作 比如数据库连接、连接和binning。
维护表索引以快速检索表项或范围。
支持将军 mixin protocol 表中的灵活数据容器。
来回转换
pandas.DataFrame.
的 天体表和数据框架 页面提供了维护和使用专用 astropy.table 而不是依赖于 pandas .
入门#
创建表、访问表元素和修改表的基本工作流如下所示。这些例子展示了一个简洁的案例,而 astropy.table 文档可从 使用 table 部分。
首先创建一个简单的表,其中包含名为 a , b , c 和 d . 这些列有integer、float、string和 Quantity 数值分别为:
>>> from astropy.table import QTable
>>> import astropy.units as u
>>> import numpy as np
>>> a = np.array([1, 4, 5], dtype=np.int32)
>>> b = [2.0, 5.0, 8.5]
>>> c = ['x', 'y', 'z']
>>> d = [10, 20, 30] * u.m / u.s
>>> t = QTable([a, b, c, d],
... names=('a', 'b', 'c', 'd'),
... meta={'name': 'first table'})
评论:
列
a是一种numpy.ndarray具有指定的dtype的int32。如果未提供数据类型,则整数的默认类型为int64在Mac和Linux上int32在Windows上。柱
b是一个列表float值,表示为float64.柱
c是一个列表str值,以unicode表示。看到了吗 Bytestring列 更多信息。柱
d是一个Quantity数组。自从我们用过QTable,这将存储一个本机Quantity在桌子里,带来了 单位和数量 (astropy.units ) 到表中的此列。
备注
如果表数据没有单位或您不想使用 Quantity ,然后您可以使用 Table 类来创建表。这个 only 两者之间的区别 QTable 和 Table 添加具有单位的列时的行为。看到了吗 数量和数量 和 带单位的列 有关差异和用例的详细信息。
还有许多其他方法可以 构造表 ,包括来自行列表(元组或字典)、 numpy 结构化或2D数组,通过递增添加列或行,甚至从 SkyCoord 或者是 pandas.DataFrame 。
有几种方法 访问表 . 您可以获得有关表值和列定义的详细信息,如下所示:
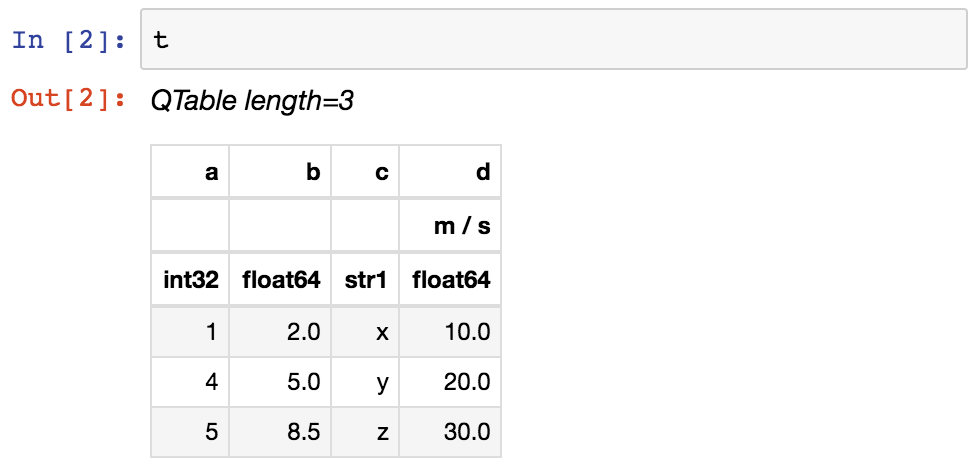
>>> t
<QTable length=3>
a b c d
m / s
int32 float64 str1 float64
----- ------- ---- -------
1 2.0 x 10.0
4 5.0 y 20.0
5 8.5 z 30.0
您可以按如下方式获取有关表的摘要信息:
>>> t.info
<QTable length=3>
name dtype unit class
---- ------- ----- --------
a int32 Column
b float64 Column
c str1 Column
d float64 m / s Quantity
从一个 Jupyter notebook ,该表将显示为格式化的HTML表(其详细信息可以通过更改 astropy.table.conf.default_notebook_table_class 项目中的 配置系统 (astropy.config ) :
或者您可以获得更精美的笔记本电脑界面 show_in_notebook() ,例如,当用于 backend="ipydatagrid" ,它带有浏览器内过滤和排序:
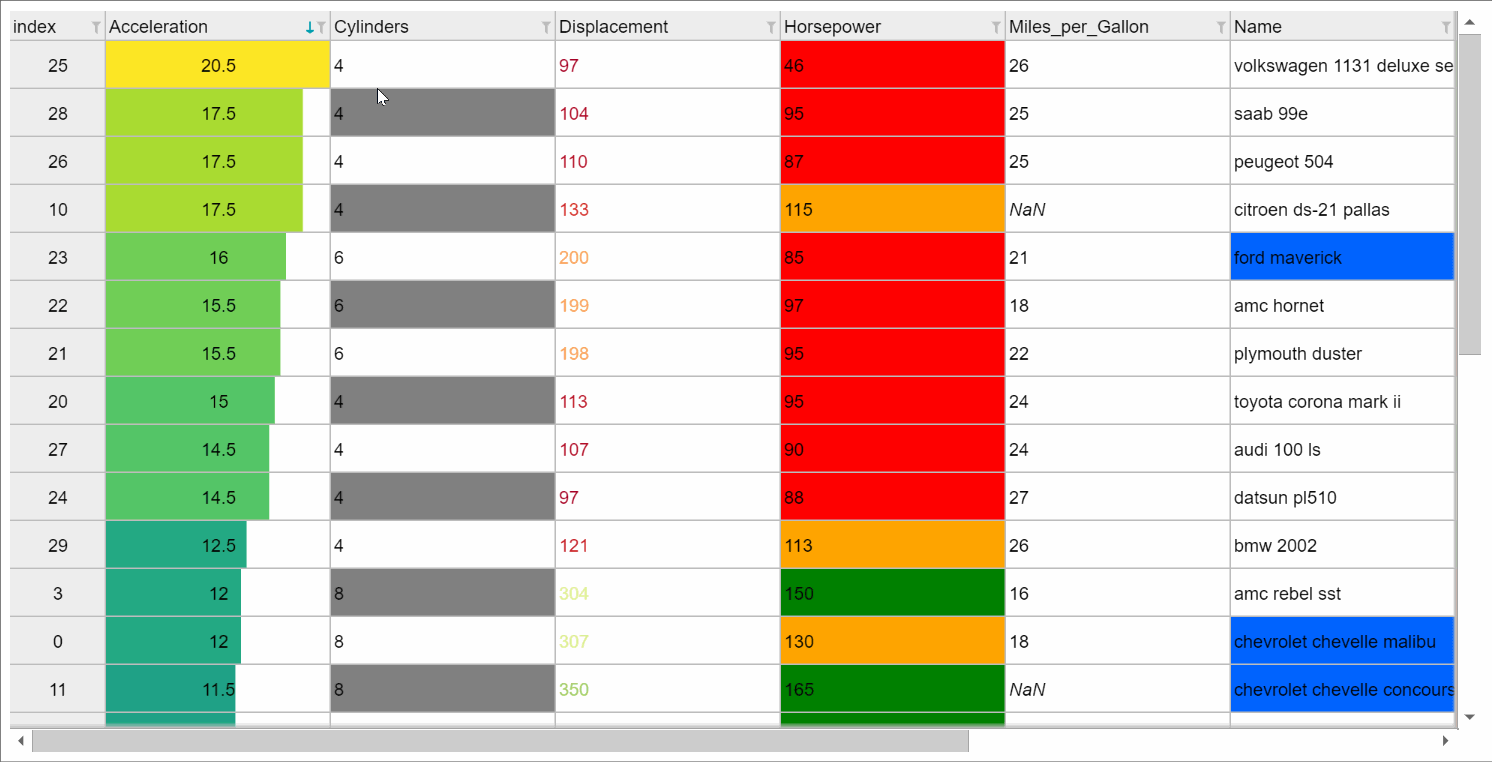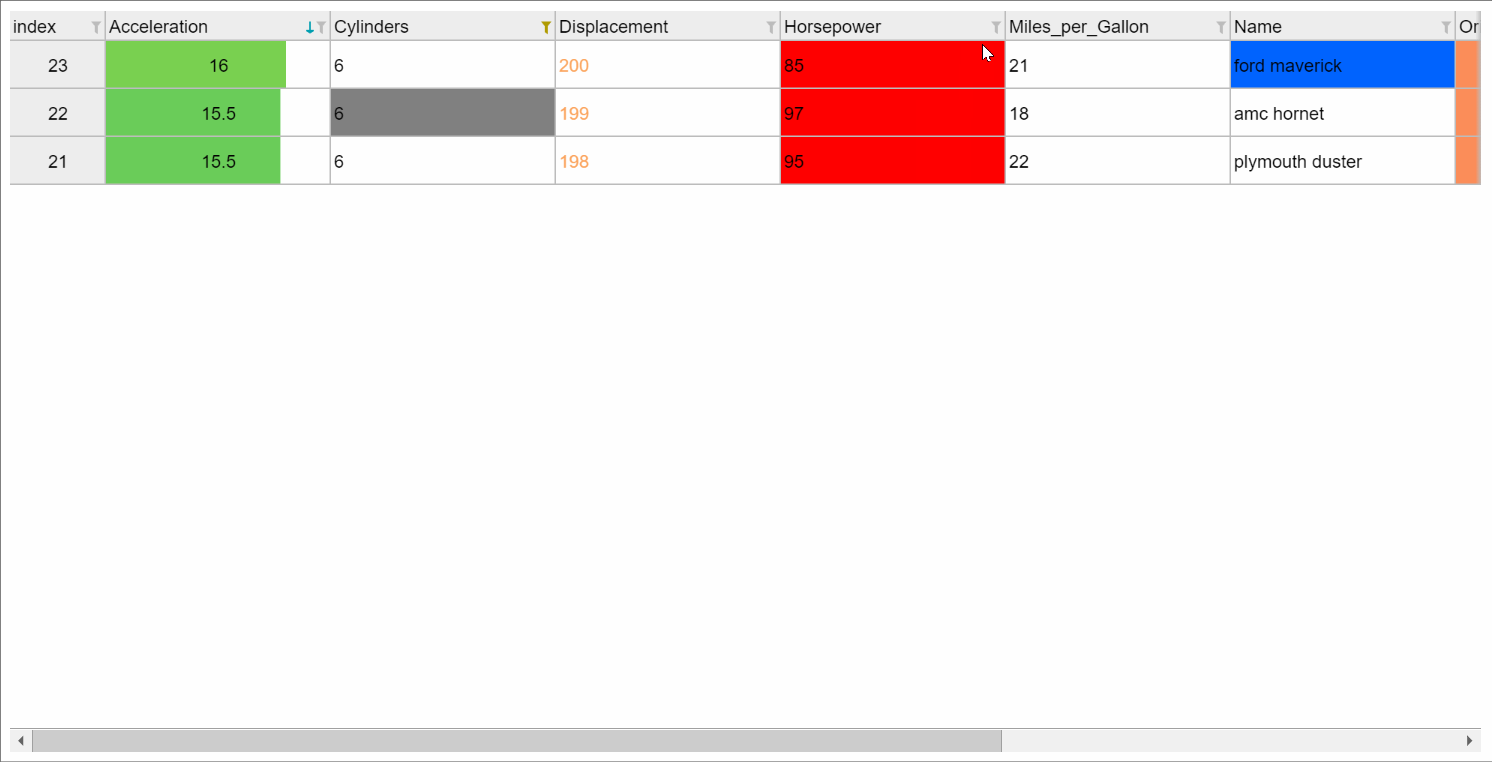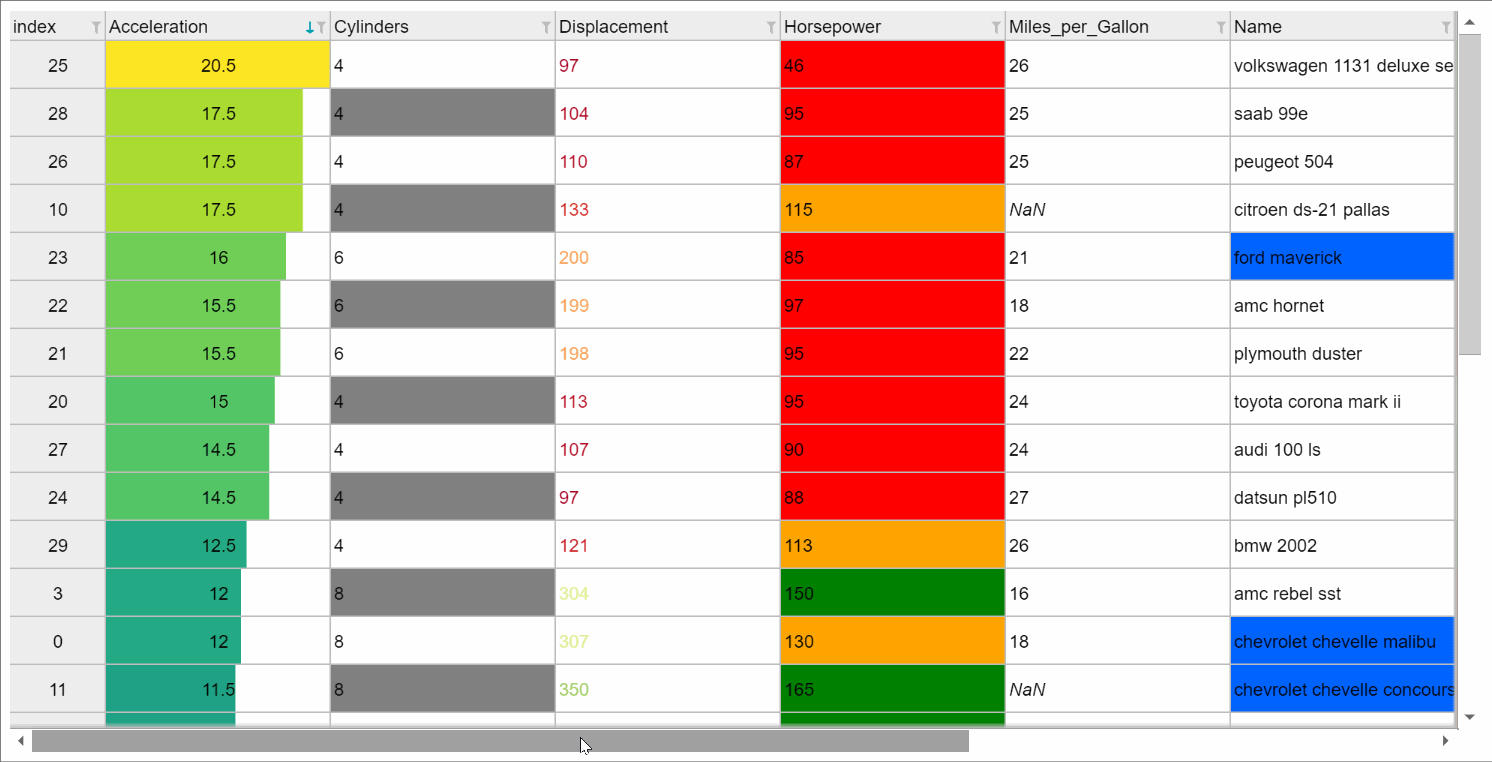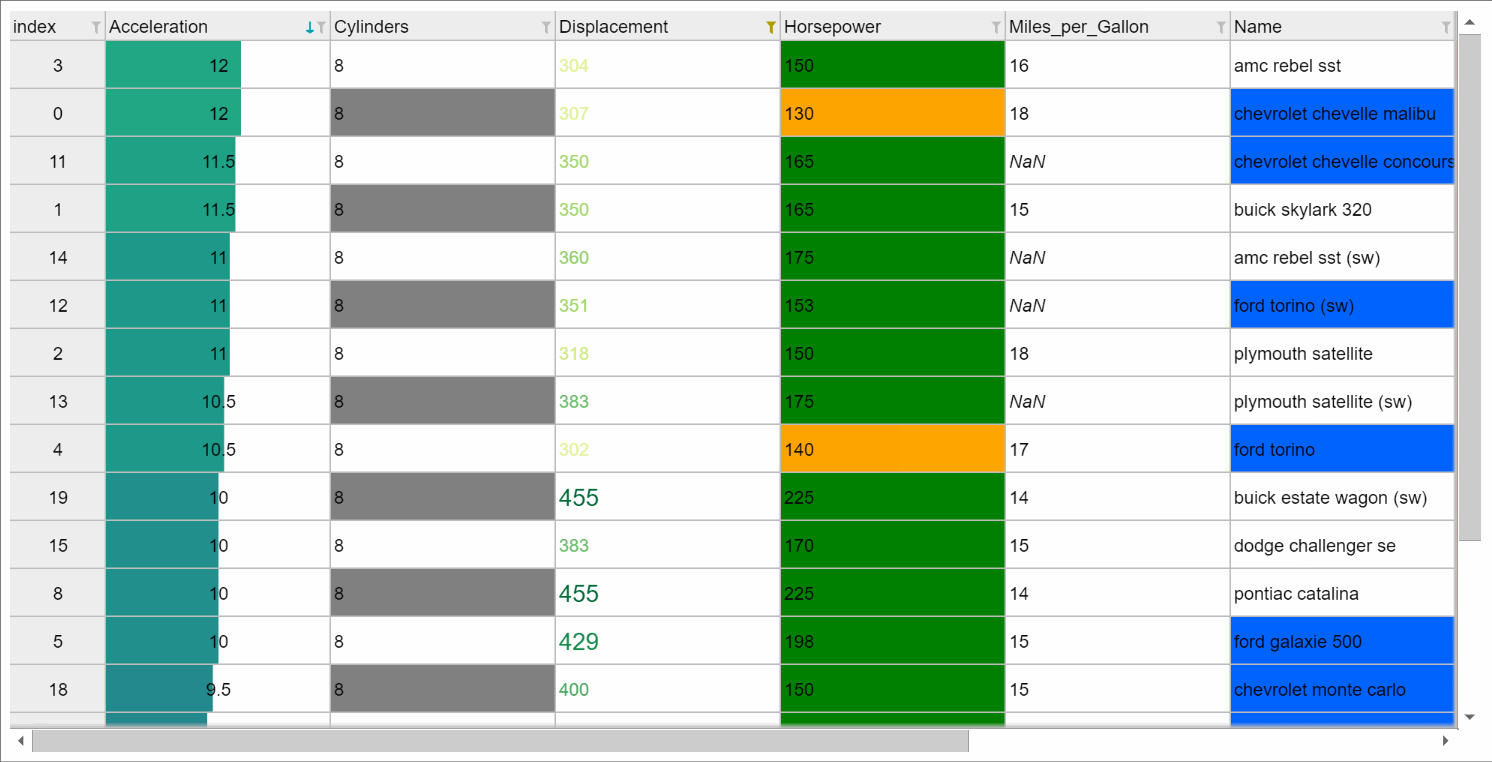
如果打印表格(从笔记本或在文本控制台会话中),则会显示格式化版本:
>>> print(t)
a b c d
m / s
--- --- --- -----
1 2.0 x 10.0
4 5.0 y 20.0
5 8.5 z 30.0
如果您不喜欢特定列的格式,可以通过 the 'info' property **
>>> t['b'].info.format = '7.3f'
>>> print(t)
a b c d
m / s
--- ------- --- -----
1 2.000 x 10.0
4 5.000 y 20.0
5 8.500 z 30.0
对于长表格,您可以在表格中上下滚动一页:
>>> t.more()
也可以在浏览器中将其显示为HTML格式的表:
>>> t.show_in_browser()
或作为交互式(可搜索和可排序)javascript表:
>>> t.show_in_browser(jsviewer=True)
现在检查有关表的一些高级信息:
>>> t.colnames
['a', 'b', 'c', 'd']
>>> len(t)
3
>>> t.meta
{'name': 'first table'}
使用“熟悉”按列或行访问数据 numpy 结构化数组语法:
>>> t['a'] # Column 'a'
<Column name='a' dtype='int32' length=3>
1
4
5
>>> t['a'][1] # Row 1 of column 'a'
np.int32(4)
>>> t[1] # Row 1 of the table
<Row index=1>
a b c d
m / s
int32 float64 str1 float64
----- ------- ---- -------
4 5.000 y 20.0
>>> t[1]['a'] # Column 'a' of row 1
np.int32(4)
您可以按行检索表的子集(使用 slice )或按列(使用列名),其中子集作为新表返回::
>>> print(t[0:2]) # Table object with rows 0 and 1
a b c d
m / s
--- ------- --- -----
1 2.000 x 10.0
4 5.000 y 20.0
>>> print(t['a', 'c']) # Table with cols 'a' and 'c'
a c
--- ---
1 x
4 y
5 z
修改表 “就位”非常灵活,可以像您预期的那样工作:
>>> t['a'][:] = [-1, -2, -3] # Set all column values in place
>>> t['a'][2] = 30 # Set row 2 of column 'a'
>>> t[1] = (8, 9.0, "W", 4 * u.m / u.s) # Set all values of row 1
>>> t[1]['b'] = -9 # Set column 'b' of row 1
>>> t[0:2]['b'] = 100.0 # Set column 'b' of rows 0 and 1
>>> print(t)
a b c d
m / s
--- ------- --- -----
-1 100.000 x 10.0
8 100.000 W 4.0
30 8.500 z 30.0
使用以下内容替换、添加、删除和重命名列:
>>> t['b'] = ['a', 'new', 'dtype'] # Replace column 'b' (different from in-place)
>>> t['e'] = [1, 2, 3] # Add column 'e'
>>> del t['c'] # Delete column 'c'
>>> t.rename_column('a', 'A') # Rename column 'a' to 'A'
>>> t.colnames
['A', 'b', 'd', 'e']
将新数据行添加到表中如下所示。请注意,单位值在中给出 cm / s 但将作为 0.1 m / s 与现有单位一致。
>>> t.add_row([-8, 'string', 10 * u.cm / u.s, 10])
>>> t['d']
<Quantity [10. , 4. , 30. , 0.1] m / s>
表可用于以下缺少值的数据:
>>> from astropy.table import MaskedColumn
>>> a_masked = MaskedColumn(a, mask=[True, True, False])
>>> t = QTable([a_masked, b, c], names=('a', 'b', 'c'),
... dtype=('i4', 'f8', 'U1'))
>>> t
<QTable length=3>
a b c
int32 float64 str1
----- ------- ----
-- 2.0 x
-- 5.0 y
5 8.5 z
除了 Quantity ,可以包括某些对象类型,例如 Time , SkyCoord 和 NdarrayMixin 在你的桌子上。这些“mixin”列的行为类似于常规 Column 以及本机对象类型(请参见 混合柱 )例如::
>>> from astropy.time import Time
>>> from astropy.coordinates import SkyCoord
>>> tm = Time(['2000:002', '2002:345'])
>>> sc = SkyCoord([10, 20], [-45, +40], unit='deg')
>>> t = QTable([tm, sc], names=['time', 'skycoord'])
>>> t
<QTable length=2>
time skycoord
deg,deg
Time SkyCoord
--------------------- ----------
2000:002:00:00:00.000 10.0,-45.0
2002:345:00:00:00.000 20.0,40.0
现在让我们计算一下 Chandra X-ray Observatory 在船上 STS-93 把这个作为一个 Quantity 天数:
>>> dt = t['time'] - Time('1999-07-23 04:30:59.984')
>>> t['dt_cxo'] = dt.to(u.d)
>>> t['dt_cxo'].info.format = '.3f'
>>> print(t)
time skycoord dt_cxo
deg,deg d
--------------------- ---------- --------
2000:002:00:00:00.000 10.0,-45.0 162.812
2002:345:00:00:00.000 20.0,40.0 1236.812
使用 table#
使用细节 astropy.table 在以下章节中提供:
构造表#
存取表#
修改表#
表操作#
索引#
掩蔽#
混合柱#
天体表和数据框架#
实施#
性能提示#
>>> from astropy.table import Table
>>> t = Table(names=['a', 'b'])
>>> for i in range(100):
... t.add_row((1, 2))
如果确实需要在代码中循环以创建行,一种更快的方法是构造一个行列表,然后创建 Table 最后的对象:
>>> rows = []
>>> for i in range(100):
... rows.append((1, 2))
>>> t = Table(rows=rows, names=['a', 'b'])
写一篇 Table 具有 MaskedColumn 到 .ecsv 使用 write() 可能很慢:
>>> from astropy.table import Table
>>> import numpy as np
>>> x = np.arange(10000, dtype=float)
>>> tm = Table([x], masked=True)
>>> tm.write('tm.ecsv', overwrite=True)
如果你想写 .ecsv 使用 write() 然后使用 serialize_method='data_mask' . 这将使用非屏蔽版本的数据,而且速度更快:
>>> tm.write('tm.ecsv', overwrite=True, serialize_method='data_mask')
Read FITS with memmap=True#
默认情况下 read() 将整个表读入内存,这可能会占用大量内存,也可能会占用大量时间,具体取决于表大小和文件格式。在某些情况下,通过选择选项,可以只读取表的一个子集 memmap=True .
对于FITS二进制表,数据是逐行存储的,并且可以只读取行的子集,但读取整列会将整个表数据加载到内存中:
>>> import numpy as np
>>> from astropy.table import Table
>>> tbl = Table({'a': np.arange(1e7),
... 'b': np.arange(1e7, dtype=float),
... 'c': np.arange(1e7, dtype=float)})
>>> tbl.write('test.fits', overwrite=True)
>>> table = Table.read('test.fits', memmap=True) # Very fast, doesn't actually load data
>>> table2 = tbl[:100] # Fast, will read only first 100 rows
>>> print(table2) # Accessing column data triggers the read
a b c
---- ---- ----
0.0 0.0 0.0
1.0 1.0 1.0
2.0 2.0 2.0
... ... ...
98.0 98.0 98.0
99.0 99.0 99.0
Length = 100 rows
>>> col = table['my_column'] # Will load all table into memory
read() 不支持 memmap=True 适用于HDF5和文本文件格式。