scipy.signal.welch¶
- scipy.signal.welch(x, fs=1.0, window='hann', nperseg=None, noverlap=None, nfft=None, detrend='constant', return_onesided=True, scaling='density', axis=- 1, average='mean')[源代码]¶
用韦尔奇方法估计功率谱密度。
韦尔奇法 [1] 通过将数据分成重叠段、计算每个段的修正周期图并平均周期图来计算功率谱密度的估计。
- 参数
- xarray_like
测量值的时间序列
- fs浮动,可选
的采样频率 x 时间序列。默认为1.0。
- window字符串或元组或array_like,可选
要使用的所需窗口。如果 window 是字符串或元组,则将其传递给
get_window以生成窗口值,该窗口值是DFT-即使在默认情况下也是如此。看见get_window有关窗口和所需参数的列表,请执行以下操作。如果 window is array_like它将直接用作窗口,其长度必须为nperseg。默认为Hann窗口。- nperseg整型,可选
每个线段的长度。默认值为None,但如果Window为字符串或元组,则设置为256,如果Window为array_like,则设置为窗口长度。
- noverlap整型,可选
线段之间要重叠的点数。如果 None ,
noverlap = nperseg // 2。默认为 None 。- nfft整型,可选
如果需要填充零的FFT,则使用的FFT长度。如果 None ,FFT长度为 nperseg 。默认为 None 。
- 下降趋势 :字符串或函数或 False ,可选字符串或函数或
指定如何对每段数据段进行趋势调整。如果
detrend是字符串,则将其作为 type 参数设置为detrend功能。如果它是一个函数,它接受一个段并返回一个去势的段。如果detrend是 False ,没有进行去趋势性操作。默认值为“Constant”。- return_onesided布尔值,可选
如果 True ,返回真实数据的单边频谱。如果 False 返回双面光谱。默认为 True ,但是对于复杂的数据,总是返回双面频谱。
- scaling{‘密度’,‘光谱’},可选
在计算功率谱密度(‘密度’)之间进行选择,其中 Pxx 单位为V 2/Hz and computing the power spectrum ('spectrum') where `Pxx` has units of V 2,如果 x 是以V为单位测量的,并且 fs 是以赫兹为单位测量的。默认为“密度”
- axis整型,可选
沿其计算周期图的轴;默认值在最后一个轴上(即
axis=-1)。- average{‘均值’,‘中位数’},可选
平均周期图时使用的方法。默认为“Mean”。
1.2.0 新版功能.
- 退货
- fndarray
采样频率数组。
- Pxxndarray
功率谱密度或x的功率谱。
参见
periodogram简单的、可选修改的周期图
lombscargle非均匀采样数据的Lomb-Scarger周期图
注意事项
适当的重叠量将取决于窗口的选择和您的要求。对于默认的汉恩窗口,50%的重叠是准确估计信号功率,同时不过度计算任何数据之间的合理折衷。较窄的窗口可能需要较大的重叠。
如果 noverlap 为0,则此方法等效于Bartlett方法 [2].
0.12.0 新版功能.
参考文献
- 1
P.Welch,“快速傅立叶变换在功率谱估计中的应用:一种基于短周期图时间平均的方法”,IEEE Transans。音频电声。卷。15年,第70-73页,1967年。
- 2
M.S.Bartlett,“周期图分析和连续谱”,Bitomka,Vol.37页,第1-16页,1950年。
示例
>>> from scipy import signal >>> import matplotlib.pyplot as plt >>> rng = np.random.default_rng()
产生一个测试信号,一个1234Hz处的2 Vrms正弦波,被以10 KHz采样的0.001 V**2/Hz白噪声破坏。
>>> fs = 10e3 >>> N = 1e5 >>> amp = 2*np.sqrt(2) >>> freq = 1234.0 >>> noise_power = 0.001 * fs / 2 >>> time = np.arange(N) / fs >>> x = amp*np.sin(2*np.pi*freq*time) >>> x += rng.normal(scale=np.sqrt(noise_power), size=time.shape)
计算并绘制功率谱密度。
>>> f, Pxx_den = signal.welch(x, fs, nperseg=1024) >>> plt.semilogy(f, Pxx_den) >>> plt.ylim([0.5e-3, 1]) >>> plt.xlabel('frequency [Hz]') >>> plt.ylabel('PSD [V**2/Hz]') >>> plt.show()
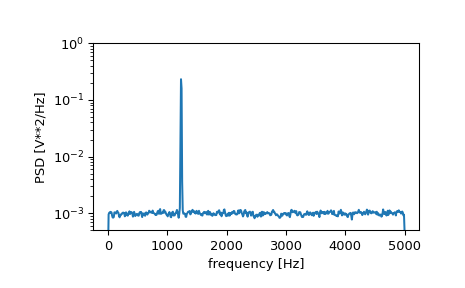
如果我们平均频谱密度的后半部分,以排除峰值,我们可以恢复信号上的噪声功率。
>>> np.mean(Pxx_den[256:]) 0.0009924865443739191
现在计算并绘制功率谱。
>>> f, Pxx_spec = signal.welch(x, fs, 'flattop', 1024, scaling='spectrum') >>> plt.figure() >>> plt.semilogy(f, np.sqrt(Pxx_spec)) >>> plt.xlabel('frequency [Hz]') >>> plt.ylabel('Linear spectrum [V RMS]') >>> plt.show()
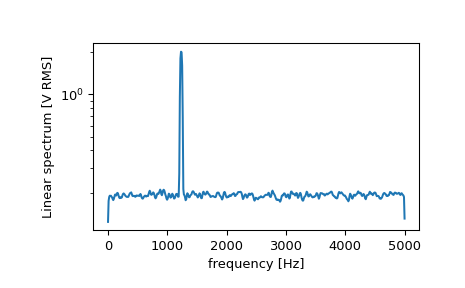
功率谱中的峰值高度是均方根幅度的估计值。
>>> np.sqrt(Pxx_spec.max()) 2.0077340678640727
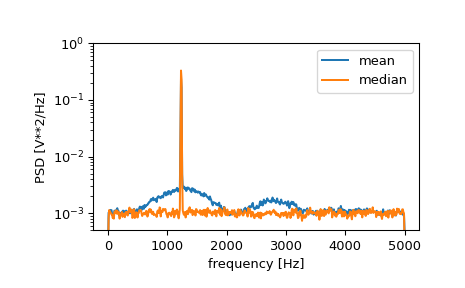
如果我们现在在信号中引入不连续,通过将一小部分信号的幅度增加50%,我们可以看到平均功率谱密度的破坏,但使用中值平均更好地估计正常行为。
>>> x[int(N//2):int(N//2)+10] *= 50. >>> f, Pxx_den = signal.welch(x, fs, nperseg=1024) >>> f_med, Pxx_den_med = signal.welch(x, fs, nperseg=1024, average='median') >>> plt.semilogy(f, Pxx_den, label='mean') >>> plt.semilogy(f_med, Pxx_den_med, label='median') >>> plt.ylim([0.5e-3, 1]) >>> plt.xlabel('frequency [Hz]') >>> plt.ylabel('PSD [V**2/Hz]') >>> plt.legend() >>> plt.show()