0.20.1版(2017-05-05)#
这是从0.19.2开始的一个主要版本,包括许多API更改、弃用、新功能、增强功能和性能改进,以及大量的错误修复。我们建议所有用户升级到此版本。
亮点包括:
新的
.agg()类似Groupby-Rolling-Resample接口的Series/DataFrame接口,请参见 here与
feather-format,包括一个新的顶层pd.read_feather()和DataFrame.to_feather()方法,请参见 here 。这个
.ix索引器已弃用,请参见 herePanelhas been deprecated, see here增加了一个
IntervalIndex和Interval标量类型,请参见 here改进了按索引级别分组时的用户API
.groupby(),请参见 here改进了对
UInt64数据类型,请参见 hereJSON序列化的新方向,
orient='table',它使用表模式规范,这为Jupyter笔记本中更具互动性的REPR提供了可能性,请参见 here对导出样式化DataFrame的实验性支持 (
DataFrame.style)到Excel,请参阅 here窗口二进制相关/覆盖操作现在返回一个多索引
DataFrame而不是Panel作为Panel现在已弃用,请参见 here现在使用对S3处理的支持
s3fs,请参见 hereGoogle BigQuery支持现在使用
pandas-gbq库,请参见 here
警告
Pandas改变了代码库的内部结构和布局。这可能会影响非来自顶层的导入 pandas.* 命名空间,请查看更改 here 。
检查 API Changes 和 deprecations 在更新之前。
备注
这是0.20.0和0.20.1的合并版本。版本0.20.1包含一个额外的向后更改--与使用Pandas的下游项目兼容 utils 例行公事。 (GH16250 )
V0.20.0中的新特性
新功能#
方法 agg 用于DataFrame/系列的API#
Series & DataFrame have been enhanced to support the aggregation API. This is a familiar API
from groupby, window operations, and resampling. This allows aggregation operations in a concise way
by using agg() and transform(). The full documentation
is here (GH1623).
这是一个样品
In [1]: df = pd.DataFrame(np.random.randn(10, 3), columns=['A', 'B', 'C'],
...: index=pd.date_range('1/1/2000', periods=10))
...:
In [2]: df.iloc[3:7] = np.nan
In [3]: df
Out[3]:
A B C
2000-01-01 0.469112 -0.282863 -1.509059
2000-01-02 -1.135632 1.212112 -0.173215
2000-01-03 0.119209 -1.044236 -0.861849
2000-01-04 NaN NaN NaN
2000-01-05 NaN NaN NaN
2000-01-06 NaN NaN NaN
2000-01-07 NaN NaN NaN
2000-01-08 0.113648 -1.478427 0.524988
2000-01-09 0.404705 0.577046 -1.715002
2000-01-10 -1.039268 -0.370647 -1.157892
[10 rows x 3 columns]
可以使用字符串函数名、可调用函数、列表或它们的字典进行操作。
使用单个函数相当于 .apply 。
In [4]: df.agg('sum')
Out[4]:
A -1.068226
B -1.387015
C -4.892029
Length: 3, dtype: float64
具有函数列表的多个聚合。
In [5]: df.agg(['sum', 'min'])
Out[5]:
A B C
sum -1.068226 -1.387015 -4.892029
min -1.135632 -1.478427 -1.715002
[2 rows x 3 columns]
使用DICT提供了按列应用特定聚合的能力。您将获得所有聚合器的类似于矩阵的输出。输出中的每个唯一函数都有一列。应用于特定列的那些函数将是 NaN :
In [6]: df.agg({'A': ['sum', 'min'], 'B': ['min', 'max']})
Out[6]:
A B
sum -1.068226 NaN
min -1.135632 -1.478427
max NaN 1.212112
[3 rows x 2 columns]
该API还支持 .transform() 用于播放结果的功能。
In [7]: df.transform(['abs', lambda x: x - x.min()])
Out[7]:
A B C
abs <lambda> abs <lambda> abs <lambda>
2000-01-01 0.469112 1.604745 0.282863 1.195563 1.509059 0.205944
2000-01-02 1.135632 0.000000 1.212112 2.690539 0.173215 1.541787
2000-01-03 0.119209 1.254841 1.044236 0.434191 0.861849 0.853153
2000-01-04 NaN NaN NaN NaN NaN NaN
2000-01-05 NaN NaN NaN NaN NaN NaN
2000-01-06 NaN NaN NaN NaN NaN NaN
2000-01-07 NaN NaN NaN NaN NaN NaN
2000-01-08 0.113648 1.249281 1.478427 0.000000 0.524988 2.239990
2000-01-09 0.404705 1.540338 0.577046 2.055473 1.715002 0.000000
2000-01-10 1.039268 0.096364 0.370647 1.107780 1.157892 0.557110
[10 rows x 6 columns]
当呈现不能聚集的混合数据类型时, .agg() 将只接受有效的聚合。这类似于Groupby如何 .agg() 行得通。 (GH15015 )
In [8]: df = pd.DataFrame({'A': [1, 2, 3],
...: 'B': [1., 2., 3.],
...: 'C': ['foo', 'bar', 'baz'],
...: 'D': pd.date_range('20130101', periods=3)})
...:
In [9]: df.dtypes
Out[9]:
A int64
B float64
C object
D datetime64[ns]
Length: 4, dtype: object
In [10]: df.agg(['min', 'sum'])
Out[10]:
A B C D
min 1 1.0 bar 2013-01-01
sum 6 6.0 foobarbaz NaT
[2 rows x 4 columns]
关键字参数 dtype 对于数据IO#
这个 'python' 引擎用于 read_csv() ,以及 read_fwf() 用于解析固定宽度文本文件的函数和 read_excel() 对于解析Excel文件,现在接受 dtype 用于指定特定列类型的关键字参数 (GH14295 )。请参阅 io docs 了解更多信息。
In [11]: data = "a b\n1 2\n3 4"
In [12]: pd.read_fwf(StringIO(data)).dtypes
Out[12]:
a int64
b int64
Length: 2, dtype: object
In [13]: pd.read_fwf(StringIO(data), dtype={'a': 'float64', 'b': 'object'}).dtypes
Out[13]:
a float64
b object
Length: 2, dtype: object
方法 .to_datetime() 已经获得了一个 origin 参数#
to_datetime() 获得了一个新的参数, origin 属性分析数值时,定义计算结果时间戳的引用日期 unit 指定的。 (GH11276 , GH11745 )
例如,以1960-01-01作为开始日期:
In [14]: pd.to_datetime([1, 2, 3], unit='D', origin=pd.Timestamp('1960-01-01'))
Out[14]: DatetimeIndex(['1960-01-02', '1960-01-03', '1960-01-04'], dtype='datetime64[ns]', freq=None)
缺省值设置为 origin='unix' ,它缺省为 1970-01-01 00:00:00 ,这通常被称为‘Unix纪元’或POSIX时间。这是以前的默认设置,因此这是一个向后兼容的更改。
In [15]: pd.to_datetime([1, 2, 3], unit='D')
Out[15]: DatetimeIndex(['1970-01-02', '1970-01-03', '1970-01-04'], dtype='datetime64[ns]', freq=None)
GroupBy增强功能#
传递到的字符串 DataFrame.groupby() 作为 by 参数现在可以引用列名或索引级名称。以前,只能引用列名。这使您可以轻松地同时按列和索引级别分组。 (GH5677 )
In [16]: arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],
....: ['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
....:
In [17]: index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
In [18]: df = pd.DataFrame({'A': [1, 1, 1, 1, 2, 2, 3, 3],
....: 'B': np.arange(8)},
....: index=index)
....:
In [19]: df
Out[19]:
A B
first second
bar one 1 0
two 1 1
baz one 1 2
two 1 3
foo one 2 4
two 2 5
qux one 3 6
two 3 7
[8 rows x 2 columns]
In [20]: df.groupby(['second', 'A']).sum()
Out[20]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
[6 rows x 1 columns]
中对压缩URL的更好支持 read_csv#
The compression code was refactored (GH12688). As a result, reading
dataframes from URLs in read_csv() or read_table() now supports
additional compression methods: xz, bz2, and zip (GH14570).
Previously, only gzip compression was supported. By default, compression of
URLs and paths are now inferred using their file extensions. Additionally,
support for bz2 compression in the python 2 C-engine improved (GH14874).
In [21]: url = ('https://github.com/{repo}/raw/{branch}/{path}'
....: .format(repo='pandas-dev/pandas',
....: branch='main',
....: path='pandas/tests/io/parser/data/salaries.csv.bz2'))
....:
# default, infer compression
In [22]: df = pd.read_csv(url, sep='\t', compression='infer')
# explicitly specify compression
In [23]: df = pd.read_csv(url, sep='\t', compression='bz2')
In [24]: df.head(2)
Out[24]:
S X E M
0 13876 1 1 1
1 11608 1 3 0
[2 rows x 4 columns]
Pickle文件IO现在支持压缩#
read_pickle(), DataFrame.to_pickle() and Series.to_pickle()
can now read from and write to compressed pickle files. Compression methods
can be an explicit parameter or be inferred from the file extension.
See the docs here.
In [25]: df = pd.DataFrame({'A': np.random.randn(1000),
....: 'B': 'foo',
....: 'C': pd.date_range('20130101', periods=1000, freq='s')})
....:
使用显式压缩类型
In [26]: df.to_pickle("data.pkl.compress", compression="gzip")
In [27]: rt = pd.read_pickle("data.pkl.compress", compression="gzip")
In [28]: rt.head()
Out[28]:
A B C
0 -1.344312 foo 2013-01-01 00:00:00
1 0.844885 foo 2013-01-01 00:00:01
2 1.075770 foo 2013-01-01 00:00:02
3 -0.109050 foo 2013-01-01 00:00:03
4 1.643563 foo 2013-01-01 00:00:04
[5 rows x 3 columns]
默认情况下,从扩展名推断压缩类型 (compression='infer' ):
In [29]: df.to_pickle("data.pkl.gz")
In [30]: rt = pd.read_pickle("data.pkl.gz")
In [31]: rt.head()
Out[31]:
A B C
0 -1.344312 foo 2013-01-01 00:00:00
1 0.844885 foo 2013-01-01 00:00:01
2 1.075770 foo 2013-01-01 00:00:02
3 -0.109050 foo 2013-01-01 00:00:03
4 1.643563 foo 2013-01-01 00:00:04
[5 rows x 3 columns]
In [32]: df["A"].to_pickle("s1.pkl.bz2")
In [33]: rt = pd.read_pickle("s1.pkl.bz2")
In [34]: rt.head()
Out[34]:
0 -1.344312
1 0.844885
2 1.075770
3 -0.109050
4 1.643563
Name: A, Length: 5, dtype: float64
改进了对UInt64的支持#
Pandas极大地改进了对涉及无符号或纯非负整数运算的支持。以前,处理这些整数会导致不正确的舍入或数据类型转换,从而导致不正确的结果。值得注意的是,一个新的数字指数, UInt64Index ,已创建 (GH14937 )
In [1]: idx = pd.UInt64Index([1, 2, 3])
In [2]: df = pd.DataFrame({'A': ['a', 'b', 'c']}, index=idx)
In [3]: df.index
Out[3]: UInt64Index([1, 2, 3], dtype='uint64')
关于范畴的GroupBy#
在以前的版本中, .groupby(..., sort=False) 将失败,并显示 ValueError 在数据中未出现某些类别的分类系列上进行分组时。 (GH13179 )
In [35]: chromosomes = np.r_[np.arange(1, 23).astype(str), ['X', 'Y']]
In [36]: df = pd.DataFrame({
....: 'A': np.random.randint(100),
....: 'B': np.random.randint(100),
....: 'C': np.random.randint(100),
....: 'chromosomes': pd.Categorical(np.random.choice(chromosomes, 100),
....: categories=chromosomes,
....: ordered=True)})
....:
In [37]: df
Out[37]:
A B C chromosomes
0 87 22 81 4
1 87 22 81 13
2 87 22 81 22
3 87 22 81 2
4 87 22 81 6
.. .. .. .. ...
95 87 22 81 8
96 87 22 81 11
97 87 22 81 X
98 87 22 81 1
99 87 22 81 19
[100 rows x 4 columns]
以前的行为 :
In [3]: df[df.chromosomes != '1'].groupby('chromosomes', sort=False).sum()
---------------------------------------------------------------------------
ValueError: items in new_categories are not the same as in old categories
新行为 :
In [38]: df[df.chromosomes != '1'].groupby('chromosomes', sort=False).sum()
Out[38]:
A B C
chromosomes
2 348 88 324
3 348 88 324
4 348 88 324
5 261 66 243
6 174 44 162
... ... ... ...
22 348 88 324
X 348 88 324
Y 435 110 405
1 0 0 0
21 0 0 0
[24 rows x 3 columns]
表模式输出#
新东方 'table' 为 DataFrame.to_json() 将生成一个 Table Schema 数据的兼容字符串表示形式。
In [39]: df = pd.DataFrame(
....: {'A': [1, 2, 3],
....: 'B': ['a', 'b', 'c'],
....: 'C': pd.date_range('2016-01-01', freq='d', periods=3)},
....: index=pd.Index(range(3), name='idx'))
....:
In [40]: df
Out[40]:
A B C
idx
0 1 a 2016-01-01
1 2 b 2016-01-02
2 3 c 2016-01-03
[3 rows x 3 columns]
In [41]: df.to_json(orient='table')
Out[41]: '{"schema":{"fields":[{"name":"idx","type":"integer"},{"name":"A","type":"integer"},{"name":"B","type":"string"},{"name":"C","type":"datetime"}],"primaryKey":["idx"],"pandas_version":"1.4.0"},"data":[{"idx":0,"A":1,"B":"a","C":"2016-01-01T00:00:00.000Z"},{"idx":1,"A":2,"B":"b","C":"2016-01-02T00:00:00.000Z"},{"idx":2,"A":3,"B":"c","C":"2016-01-03T00:00:00.000Z"}]}'
看见 IO: Table Schema for more information 。
此外,Repr for DataFrame 和 Series 现在可以发布Series或DataFrame的此JSON表架构表示,如果您使用的是IPython(或其他前端,如 nteract 使用Jupyter消息收发协议)。这给了Jupyter笔记本和Jupyter这样的前端 nteract 显示Pandas对象的方式更加灵活,因为它们拥有更多关于数据的信息。您必须通过设置 display.html.table_schema 选项以执行以下操作 True 。
从SparseDataFrame到SparseDataFrame的SciPy稀疏矩阵#
Pandas现在支持直接从 scipy.sparse.spmatrix 实例。请参阅 documentation 了解更多信息。 (GH4343 )
支持所有稀疏格式,但不支持 COOrdinate 将转换格式,根据需要复制数据。
from scipy.sparse import csr_matrix
arr = np.random.random(size=(1000, 5))
arr[arr < .9] = 0
sp_arr = csr_matrix(arr)
sp_arr
sdf = pd.SparseDataFrame(sp_arr)
sdf
要转换为 SparseDataFrame 回到COO格式的稀疏SciPy矩阵,您可以使用:
sdf.to_coo()
带样式的DataFrame的Excel输出#
为出口增加了试验性支持 DataFrame.style 将格式设置为Excel openpyxl 引擎。 (GH15530 )
例如,在运行以下命令后, styled.xlsx 渲染如下:
In [42]: np.random.seed(24)
In [43]: df = pd.DataFrame({'A': np.linspace(1, 10, 10)})
In [44]: df = pd.concat([df, pd.DataFrame(np.random.RandomState(24).randn(10, 4),
....: columns=list('BCDE'))],
....: axis=1)
....:
In [45]: df.iloc[0, 2] = np.nan
In [46]: df
Out[46]:
A B C D E
0 1.0 1.329212 NaN -0.316280 -0.990810
1 2.0 -1.070816 -1.438713 0.564417 0.295722
2 3.0 -1.626404 0.219565 0.678805 1.889273
3 4.0 0.961538 0.104011 -0.481165 0.850229
4 5.0 1.453425 1.057737 0.165562 0.515018
5 6.0 -1.336936 0.562861 1.392855 -0.063328
6 7.0 0.121668 1.207603 -0.002040 1.627796
7 8.0 0.354493 1.037528 -0.385684 0.519818
8 9.0 1.686583 -1.325963 1.428984 -2.089354
9 10.0 -0.129820 0.631523 -0.586538 0.290720
[10 rows x 5 columns]
In [47]: styled = (df.style
....: .applymap(lambda val: 'color:red;' if val < 0 else 'color:black;')
....: .highlight_max())
....:
In [48]: styled.to_excel('styled.xlsx', engine='openpyxl')
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Input In [48], in <cell line: 1>()
----> 1 styled.to_excel('styled.xlsx', engine='openpyxl')
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/formats/style.py:584, in Styler.to_excel(self, excel_writer, sheet_name, na_rep, float_format, columns, header, index, index_label, startrow, startcol, engine, merge_cells, encoding, inf_rep, verbose, freeze_panes)
571 from pandas.io.formats.excel import ExcelFormatter
573 formatter = ExcelFormatter(
574 self,
575 na_rep=na_rep,
(...)
582 inf_rep=inf_rep,
583 )
--> 584 formatter.write(
585 excel_writer,
586 sheet_name=sheet_name,
587 startrow=startrow,
588 startcol=startcol,
589 freeze_panes=freeze_panes,
590 engine=engine,
591 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/formats/excel.py:896, in ExcelFormatter.write(self, writer, sheet_name, startrow, startcol, freeze_panes, engine, storage_options)
892 need_save = False
893 else:
894 # error: Cannot instantiate abstract class 'ExcelWriter' with abstract
895 # attributes 'engine', 'save', 'supported_extensions' and 'write_cells'
--> 896 writer = ExcelWriter( # type: ignore[abstract]
897 writer, engine=engine, storage_options=storage_options
898 )
899 need_save = True
901 try:
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/excel/_openpyxl.py:55, in OpenpyxlWriter.__init__(self, path, engine, date_format, datetime_format, mode, storage_options, if_sheet_exists, engine_kwargs, **kwargs)
42 def __init__(
43 self,
44 path: FilePath | WriteExcelBuffer | ExcelWriter,
(...)
53 ) -> None:
54 # Use the openpyxl module as the Excel writer.
---> 55 from openpyxl.workbook import Workbook
57 engine_kwargs = combine_kwargs(engine_kwargs, kwargs)
59 super().__init__(
60 path,
61 mode=mode,
(...)
64 engine_kwargs=engine_kwargs,
65 )
ModuleNotFoundError: No module named 'openpyxl'
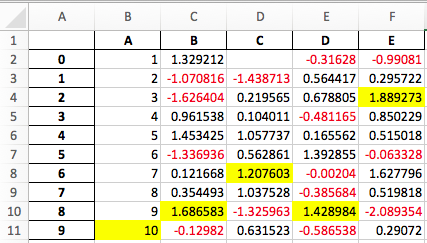
请参阅 Style documentation 了解更多详细信息。
IntervalIndex#
Pandas获得了一种 IntervalIndex 具有自己的数据类型, interval 以及 Interval 标量类型。它们允许对间隔表示法提供一流的支持,特别是将其作为 cut() 和 qcut() 。这个 IntervalIndex 允许建立一些唯一索引,请参阅 docs 。 (GH7640 , GH8625 )
警告
IntervalIndex的这些索引行为是暂时的,在未来的Pandas版本中可能会发生变化。欢迎对使用情况进行反馈。
以前的行为:
返回的类别是代表时间间隔的字符串
In [1]: c = pd.cut(range(4), bins=2)
In [2]: c
Out[2]:
[(-0.003, 1.5], (-0.003, 1.5], (1.5, 3], (1.5, 3]]
Categories (2, object): [(-0.003, 1.5] < (1.5, 3]]
In [3]: c.categories
Out[3]: Index(['(-0.003, 1.5]', '(1.5, 3]'], dtype='object')
新行为:
In [49]: c = pd.cut(range(4), bins=2)
In [50]: c
Out[50]:
[(-0.003, 1.5], (-0.003, 1.5], (1.5, 3.0], (1.5, 3.0]]
Categories (2, interval[float64, right]): [(-0.003, 1.5] < (1.5, 3.0]]
In [51]: c.categories
Out[51]: IntervalIndex([(-0.003, 1.5], (1.5, 3.0]], dtype='interval[float64, right]')
此外,这还允许一个人 其他 用这些相同的存储箱存储数据, NaN 表示类似于其它数据类型的缺失值。
In [52]: pd.cut([0, 3, 5, 1], bins=c.categories)
Out[52]:
[(-0.003, 1.5], (1.5, 3.0], NaN, (-0.003, 1.5]]
Categories (2, interval[float64, right]): [(-0.003, 1.5] < (1.5, 3.0]]
一个 IntervalIndex 也可用于 Series 和 DataFrame 作为索引。
In [53]: df = pd.DataFrame({'A': range(4),
....: 'B': pd.cut([0, 3, 1, 1], bins=c.categories)
....: }).set_index('B')
....:
In [54]: df
Out[54]:
A
B
(-0.003, 1.5] 0
(1.5, 3.0] 1
(-0.003, 1.5] 2
(-0.003, 1.5] 3
[4 rows x 1 columns]
通过特定间隔进行选择:
In [55]: df.loc[pd.Interval(1.5, 3.0)]
Out[55]:
A 1
Name: (1.5, 3.0], Length: 1, dtype: int64
通过包含的标量值进行选择 in 间歇期。
In [56]: df.loc[0]
Out[56]:
A
B
(-0.003, 1.5] 0
(-0.003, 1.5] 2
(-0.003, 1.5] 3
[3 rows x 1 columns]
其他增强功能#
DataFrame.rolling()now accepts the parameterclosed='right'|'left'|'both'|'neither'to choose the rolling window-endpoint closedness. See the documentation (GH13965)与
feather-format,包括一个新的顶层pd.read_feather()和DataFrame.to_feather()方法,请参见 here 。Series.str.replace()now accepts a callable, as replacement, which is passed tore.sub(GH15055)Series.str.replace()现在接受已编译的正则表达式作为模式 (GH15446 )Series.sort_indexaccepts parameterskindandna_position(GH13589, GH14444)DataFrame和DataFrame.groupby()已经获得了一个nunique()方法对轴上的不同值进行计数 (GH14336 , GH15197 )。DataFrame已经获得了melt()方法,等效于pd.melt(),用于从宽到长格式的取消枢轴 (GH12640 )。pd.read_excel()now preserves sheet order when usingsheetname=None(GH9930)现在支持多个带小数点的偏移别名(例如
0.5min被解析为30s) (GH8419 ).isnull()和.notnull()已添加到Index对象以使它们与SeriesAPI (GH15300 )新的
UnsortedIndexError(子类KeyError)在索引/切片到未排序的多索引时引发 (GH11897 )。这允许区分由于缺少排序或键不正确而导致的错误。看见 hereMultiIndexhas gained a.to_frame()method to convert to aDataFrame(GH12397)pd.cut和pd.qcut现在支持DateTime64和timedelta64数据类型 (GH14714 , GH14798 )pd.qcut已经获得了duplicates='raise'|'drop'用于控制是否在重复边上升高的选项 (GH7751 )Series提供一个to_excel一种输出Excel文件的方法 (GH8825 )这个
usecols中的参数pd.read_csv()现在接受可调用函数作为值 (GH14154 )这个
skiprows中的参数pd.read_csv()现在接受可调用函数作为值 (GH10882 )这个
nrows和chunksize中的参数pd.read_csv()如果两者都通过,则支持 (GH6774 , GH15755 )DataFrame.plot如果出现以下情况,则会在每个子图上方打印标题suplots=True和title是一个字符串列表 (GH14753 )DataFrame.plotcan pass the matplotlib 2.0 default color cycle as a single string as color parameter, see here 。 (GH15516 )Series.interpolate()now supports timedelta as an index type withmethod='time'(GH6424)增加了一个
level关键字至DataFrame/Series.rename重命名多重索引指定级别中的标签的步骤 (GH4160 )。DataFrame.reset_index()will now interpret a tupleindex.nameas a key spanning across levels ofcolumns, if this is aMultiIndex(GH16164)Timedelta.isoformatmethod added for formatting Timedeltas as an ISO 8601 duration. See the Timedelta docs (GH15136).select_dtypes()现在允许字符串datetimetz通常使用TZ选择日期时间 (GH14910 )这个
.to_latex()方法现在将接受multicolumn和multirow参数以使用随附的LaTeX增强功能pd.merge_asof()gained the optiondirection='backward'|'forward'|'nearest'(GH14887)Series/DataFrame.asfreq()已经获得了一个fill_value参数,以填充缺失的值 (GH3715 )。Series/DataFrame.resample.asfreq已经获得了一个fill_value参数,以填充重采样过程中缺失的值 (GH3715 )。pandas.util.hash_pandas_object()has gained the ability to hash aMultiIndex(GH15224)Series/DataFrame.squeeze()已经获得了axis参数。 (GH15339 )DataFrame.to_excel()有一个新的freeze_panes用于在导出到Excel时打开冻结窗格的参数 (GH15160 )pd.read_html()将分析多个标题行,从而创建一个多索引标题。 (GH13434 )。HTML表输出跳过
colspan或rowspan属性,如果等于1。 (GH15403 )pandas.io.formats.style.Stylertemplate now has blocks for easier extension, see the example notebook (GH15649)Styler.render()现在接受**kwargs允许在模板中使用用户定义的变量 (GH15649 )与Jupyter Notebook 5.0兼容;多索引列标签左对齐,多索引行标签顶部对齐 (GH15379 )
TimedeltaIndex现在有一个专门为纳秒级精度设计的定制日期刻度格式化程序 (GH8711 )pd.api.types.union_categoricals获得了ignore_ordered参数以允许忽略联合范畴词的有序属性 (GH13410 )。请参阅 categorical union docs 了解更多信息。DataFrame.to_latex()和DataFrame.to_string()现在允许使用可选的标头别名。 (GH15536 )重新启用
parse_dates的关键字pd.read_excel()将字符串列解析为日期 (GH14326 )已添加
.empty属性设置为Index。 (GH15270 )Enabled floor division for
TimedeltaandTimedeltaIndex(GH15828)pandas.io.json.json_normalize()获得了选项errors='ignore'|'raise';默认为errors='raise'它是向后兼容的。 (GH14583 )pandas.io.json.json_normalize()with an emptylistwill return an emptyDataFrame(GH15534)pandas.io.json.json_normalize()已经获得了sep接受的选项str分隔联接的字段;默认为“.”,这是向后兼容的。 (GH14883 )MultiIndex.remove_unused_levels()已添加,以方便 removing unused levels 。 (GH15694 )pd.read_csv()现在将引发一个ParserError当出现任何解析错误时出错 (GH15913 , GH15925 )pd.read_csv()现在支持error_bad_lines和warn_bad_lines用于Python解析器的参数 (GH15925 )这个
display.show_dimensions选项现在还可以用来指定Series应显示在其epr中 (GH7117 )。parallel_coordinates()已经获得了sort_labels对类标签和分配给它们的颜色进行排序的关键字参数 (GH15908 )Options added to allow one to turn on/off using
bottleneckandnumexpr, see here (GH16157)DataFrame.style.bar()现在接受另外两个选项以进一步自定义条形图。条形对齐设置为align='left'|'mid'|'zero',缺省值为“Left”,这是向后兼容的;现在可以传递color=[color_negative, color_positive]。 (GH14757 )
向后不兼容的API更改#
使用PANAS<0.13.0创建的HDF5格式可能不兼容#
pd.TimeSeries 在0.17.0中正式弃用,但从0.13.0开始就一直是别名。它已被放弃,取而代之的是 pd.Series 。 (GH15098 )。
这 may 如果出现以下情况,将导致在以前版本中创建的HDF5文件变得不可读 pd.TimeSeries 被利用了。这很可能是针对小于0.13.0的Pandas。如果你发现自己处于这种情况。您可以使用最新的早期版本的PANDA来读取您的HDF5文件,然后在应用下面的程序后再次将其写出。
In [2]: s = pd.TimeSeries([1, 2, 3], index=pd.date_range('20130101', periods=3))
In [3]: s
Out[3]:
2013-01-01 1
2013-01-02 2
2013-01-03 3
Freq: D, dtype: int64
In [4]: type(s)
Out[4]: pandas.core.series.TimeSeries
In [5]: s = pd.Series(s)
In [6]: s
Out[6]:
2013-01-01 1
2013-01-02 2
2013-01-03 3
Freq: D, dtype: int64
In [7]: type(s)
Out[7]: pandas.core.series.Series
索引类型上的地图现在返回其他索引类型#
map 在An上 Index 现在返回一个 Index ,而不是一个无名数组 (GH12766 )
In [57]: idx = pd.Index([1, 2])
In [58]: idx
Out[58]: Int64Index([1, 2], dtype='int64')
In [59]: mi = pd.MultiIndex.from_tuples([(1, 2), (2, 4)])
In [60]: mi
Out[60]:
MultiIndex([(1, 2),
(2, 4)],
)
以前的行为:
In [5]: idx.map(lambda x: x * 2)
Out[5]: array([2, 4])
In [6]: idx.map(lambda x: (x, x * 2))
Out[6]: array([(1, 2), (2, 4)], dtype=object)
In [7]: mi.map(lambda x: x)
Out[7]: array([(1, 2), (2, 4)], dtype=object)
In [8]: mi.map(lambda x: x[0])
Out[8]: array([1, 2])
新行为:
In [61]: idx.map(lambda x: x * 2)
Out[61]: Int64Index([2, 4], dtype='int64')
In [62]: idx.map(lambda x: (x, x * 2))
Out[62]:
MultiIndex([(1, 2),
(2, 4)],
)
In [63]: mi.map(lambda x: x)
Out[63]:
MultiIndex([(1, 2),
(2, 4)],
)
In [64]: mi.map(lambda x: x[0])
Out[64]: Int64Index([1, 2], dtype='int64')
map on a Series with datetime64 values may return int64 dtypes rather than int32
In [65]: s = pd.Series(pd.date_range('2011-01-02T00:00', '2011-01-02T02:00', freq='H')
....: .tz_localize('Asia/Tokyo'))
....:
In [66]: s
Out[66]:
0 2011-01-02 00:00:00+09:00
1 2011-01-02 01:00:00+09:00
2 2011-01-02 02:00:00+09:00
Length: 3, dtype: datetime64[ns, Asia/Tokyo]
以前的行为:
In [9]: s.map(lambda x: x.hour)
Out[9]:
0 0
1 1
2 2
dtype: int32
新行为:
In [67]: s.map(lambda x: x.hour)
Out[67]:
0 0
1 1
2 2
Length: 3, dtype: int64
访问索引的日期时间字段现在返回索引#
与日期时间相关的属性(请参见 here 以获取概述) DatetimeIndex , PeriodIndex 和 TimedeltaIndex 以前返回的NumPy数组。他们现在将返回一个新的 Index 对象,但布尔型字段的情况除外,在这种情况下,结果仍然是布尔型ndarray。 (GH15022 )
既往行为:
In [1]: idx = pd.date_range("2015-01-01", periods=5, freq='10H')
In [2]: idx.hour
Out[2]: array([ 0, 10, 20, 6, 16], dtype=int32)
新行为:
In [68]: idx = pd.date_range("2015-01-01", periods=5, freq='10H')
In [69]: idx.hour
Out[69]: Int64Index([0, 10, 20, 6, 16], dtype='int64')
这具有特定的优势,即 Index 结果上的方法仍然可用。另一方面,这可能具有向后不兼容性:例如与NumPy阵列相比, Index 对象不是可变的。要获得原始ndarray,您始终可以使用 np.asarray(idx.hour) 。
Pd.Unique现在将与扩展类型保持一致#
在以前的版本中,使用 Series.unique() 和 pandas.unique() 在……上面 Categorical 并且TZ感知的数据类型将产生不同的返回类型。现在,这些都是一致的。 (GH15903 )
DateTime Tz感知
既往行为:
# Series In [5]: pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]).unique() Out[5]: array([Timestamp('2016-01-01 00:00:00-0500', tz='US/Eastern')], dtype=object) In [6]: pd.unique(pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')])) Out[6]: array(['2016-01-01T05:00:00.000000000'], dtype='datetime64[ns]') # Index In [7]: pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]).unique() Out[7]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) In [8]: pd.unique([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]) Out[8]: array(['2016-01-01T05:00:00.000000000'], dtype='datetime64[ns]')
新行为:
# Series, returns an array of Timestamp tz-aware In [70]: pd.Series([pd.Timestamp(r'20160101', tz=r'US/Eastern'), ....: pd.Timestamp(r'20160101', tz=r'US/Eastern')]).unique() ....: Out[70]: <DatetimeArray> ['2016-01-01 00:00:00-05:00'] Length: 1, dtype: datetime64[ns, US/Eastern] In [71]: pd.unique(pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')])) ....: Out[71]: <DatetimeArray> ['2016-01-01 00:00:00-05:00'] Length: 1, dtype: datetime64[ns, US/Eastern] # Index, returns a DatetimeIndex In [72]: pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')]).unique() ....: Out[72]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) In [73]: pd.unique(pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')])) ....: Out[73]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None)
类别词
既往行为:
In [1]: pd.Series(list('baabc'), dtype='category').unique() Out[1]: [b, a, c] Categories (3, object): [b, a, c] In [2]: pd.unique(pd.Series(list('baabc'), dtype='category')) Out[2]: array(['b', 'a', 'c'], dtype=object)
新行为:
# returns a Categorical In [74]: pd.Series(list('baabc'), dtype='category').unique() Out[74]: ['b', 'a', 'c'] Categories (3, object): ['a', 'b', 'c'] In [75]: pd.unique(pd.Series(list('baabc'), dtype='category')) Out[75]: ['b', 'a', 'c'] Categories (3, object): ['a', 'b', 'c']
S3文件处理#
Pandas现在使用 s3fs 用于处理S3连接。这应该不会违反任何代码。然而,由于 s3fs 不是必需的依赖项,则需要单独安装它,如 boto 在之前的Pandas版本中。 (GH11915 )。
部分字符串索引更改#
DatetimeIndex Partial String Indexing 现在完全匹配,只要字符串解析与索引解析一致,包括两者都是秒的情况 (GH14826 )。看见 Slice vs. Exact Match 有关详细信息,请参阅。
In [76]: df = pd.DataFrame({'a': [1, 2, 3]}, pd.DatetimeIndex(['2011-12-31 23:59:59',
....: '2012-01-01 00:00:00',
....: '2012-01-01 00:00:01']))
....:
以前的行为:
In [4]: df['2011-12-31 23:59:59']
Out[4]:
a
2011-12-31 23:59:59 1
In [5]: df['a']['2011-12-31 23:59:59']
Out[5]:
2011-12-31 23:59:59 1
Name: a, dtype: int64
新行为:
In [4]: df['2011-12-31 23:59:59']
KeyError: '2011-12-31 23:59:59'
In [5]: df['a']['2011-12-31 23:59:59']
Out[5]: 1
不同浮点数据类型的连接不会自动向上转换#
在此之前, concat 多个对象的不同 float 数据类型会自动将结果向上转换为 float64 。现在将使用可接受的最小数据类型 (GH13247 )
In [77]: df1 = pd.DataFrame(np.array([1.0], dtype=np.float32, ndmin=2))
In [78]: df1.dtypes
Out[78]:
0 float32
Length: 1, dtype: object
In [79]: df2 = pd.DataFrame(np.array([np.nan], dtype=np.float32, ndmin=2))
In [80]: df2.dtypes
Out[80]:
0 float32
Length: 1, dtype: object
以前的行为:
In [7]: pd.concat([df1, df2]).dtypes
Out[7]:
0 float64
dtype: object
新行为:
In [81]: pd.concat([df1, df2]).dtypes
Out[81]:
0 float32
Length: 1, dtype: object
Pandas谷歌BigQuery支持已转移#
pandas has split off Google BigQuery support into a separate package pandas-gbq. You can conda install pandas-gbq -c conda-forge or
pip install pandas-gbq to get it. The functionality of read_gbq() and DataFrame.to_gbq() remain the same with the
currently released version of pandas-gbq=0.1.4. Documentation is now hosted here (GH15347)
索引的内存使用更准确#
在以前的版本中,显示 .memory_usage() 在具有索引的Pandas结构上,将仅包括实际索引值,而不包括促进快速索引的结构。这通常不同于 Index 和 MultiIndex 而对于其他指数类型,情况则不是如此。 (GH15237 )
以前的行为:
In [8]: index = pd.Index(['foo', 'bar', 'baz'])
In [9]: index.memory_usage(deep=True)
Out[9]: 180
In [10]: index.get_loc('foo')
Out[10]: 0
In [11]: index.memory_usage(deep=True)
Out[11]: 180
新行为:
In [8]: index = pd.Index(['foo', 'bar', 'baz'])
In [9]: index.memory_usage(deep=True)
Out[9]: 180
In [10]: index.get_loc('foo')
Out[10]: 0
In [11]: index.memory_usage(deep=True)
Out[11]: 260
DataFrame.sorte_index更改#
在某些情况下,调用 .sort_index() 在多索引DataFrame上将返回 same 似乎没有排序的DataFrame。这将发生在一个 lexsorted ,但非单调水平。 (GH15622 , GH15687 , GH14015 , GH13431 , GH15797 )
这是 保持不变 来自以前的版本,但出于说明目的而显示:
In [82]: df = pd.DataFrame(np.arange(6), columns=['value'],
....: index=pd.MultiIndex.from_product([list('BA'), range(3)]))
....:
In [83]: df
Out[83]:
value
B 0 0
1 1
2 2
A 0 3
1 4
2 5
[6 rows x 1 columns]
In [87]: df.index.is_lexsorted()
Out[87]: False
In [88]: df.index.is_monotonic
Out[88]: False
排序工作按预期进行
In [84]: df.sort_index()
Out[84]:
value
A 0 3
1 4
2 5
B 0 0
1 1
2 2
[6 rows x 1 columns]
In [90]: df.sort_index().index.is_lexsorted()
Out[90]: True
In [91]: df.sort_index().index.is_monotonic
Out[91]: True
然而,这个例子,它有一个非单调的第二级,行为并不像预期的那样。
In [85]: df = pd.DataFrame({'value': [1, 2, 3, 4]},
....: index=pd.MultiIndex([['a', 'b'], ['bb', 'aa']],
....: [[0, 0, 1, 1], [0, 1, 0, 1]]))
....:
In [86]: df
Out[86]:
value
a bb 1
aa 2
b bb 3
aa 4
[4 rows x 1 columns]
以前的行为:
In [11]: df.sort_index()
Out[11]:
value
a bb 1
aa 2
b bb 3
aa 4
In [14]: df.sort_index().index.is_lexsorted()
Out[14]: True
In [15]: df.sort_index().index.is_monotonic
Out[15]: False
新行为:
In [94]: df.sort_index()
Out[94]:
value
a aa 2
bb 1
b aa 4
bb 3
[4 rows x 1 columns]
In [95]: df.sort_index().index.is_lexsorted()
Out[95]: True
In [96]: df.sort_index().index.is_monotonic
Out[96]: True
组按描述格式化#
的输出格式 groupby.describe() 现在标记为 describe() 列中而不是索引中的指标。此格式与 groupby.agg() 一次应用多个功能时。 (GH4792 )
以前的行为:
In [1]: df = pd.DataFrame({'A': [1, 1, 2, 2], 'B': [1, 2, 3, 4]})
In [2]: df.groupby('A').describe()
Out[2]:
B
A
1 count 2.000000
mean 1.500000
std 0.707107
min 1.000000
25% 1.250000
50% 1.500000
75% 1.750000
max 2.000000
2 count 2.000000
mean 3.500000
std 0.707107
min 3.000000
25% 3.250000
50% 3.500000
75% 3.750000
max 4.000000
In [3]: df.groupby('A').agg([np.mean, np.std, np.min, np.max])
Out[3]:
B
mean std amin amax
A
1 1.5 0.707107 1 2
2 3.5 0.707107 3 4
新行为:
In [87]: df = pd.DataFrame({'A': [1, 1, 2, 2], 'B': [1, 2, 3, 4]})
In [88]: df.groupby('A').describe()
Out[88]:
B
count mean std min 25% 50% 75% max
A
1 2.0 1.5 0.707107 1.0 1.25 1.5 1.75 2.0
2 2.0 3.5 0.707107 3.0 3.25 3.5 3.75 4.0
[2 rows x 8 columns]
In [89]: df.groupby('A').agg([np.mean, np.std, np.min, np.max])
Out[89]:
B
mean std amin amax
A
1 1.5 0.707107 1 2
2 3.5 0.707107 3 4
[2 rows x 4 columns]
窗口二进制相关/覆盖操作返回多索引数据帧#
二进制窗口操作,如 .corr() 或 .cov() ,当在一个 .rolling(..) , .expanding(..) ,或 .ewm(..) 对象,现在将返回一个2级 MultiIndexed DataFrame 而不是 Panel 作为 Panel 现在已弃用,请参见 here 。它们在功能上是等效的,但多索引 DataFrame 在Pandas身上得到更多的支持。请参阅 Windowed Binary Operations 了解更多信息。 (GH15677 )
In [90]: np.random.seed(1234)
In [91]: df = pd.DataFrame(np.random.rand(100, 2),
....: columns=pd.Index(['A', 'B'], name='bar'),
....: index=pd.date_range('20160101',
....: periods=100, freq='D', name='foo'))
....:
In [92]: df.tail()
Out[92]:
bar A B
foo
2016-04-05 0.640880 0.126205
2016-04-06 0.171465 0.737086
2016-04-07 0.127029 0.369650
2016-04-08 0.604334 0.103104
2016-04-09 0.802374 0.945553
[5 rows x 2 columns]
以前的行为:
In [2]: df.rolling(12).corr()
Out[2]:
<class 'pandas.core.panel.Panel'>
Dimensions: 100 (items) x 2 (major_axis) x 2 (minor_axis)
Items axis: 2016-01-01 00:00:00 to 2016-04-09 00:00:00
Major_axis axis: A to B
Minor_axis axis: A to B
新行为:
In [93]: res = df.rolling(12).corr()
In [94]: res.tail()
Out[94]:
bar A B
foo bar
2016-04-07 B -0.132090 1.000000
2016-04-08 A 1.000000 -0.145775
B -0.145775 1.000000
2016-04-09 A 1.000000 0.119645
B 0.119645 1.000000
[5 rows x 2 columns]
检索横截面的相关矩阵
In [95]: df.rolling(12).corr().loc['2016-04-07']
Out[95]:
bar A B
bar
A 1.00000 -0.13209
B -0.13209 1.00000
[2 rows x 2 columns]
HDFStore Where字符串比较#
In previous versions most types could be compared to string column in a HDFStore
usually resulting in an invalid comparison, returning an empty result frame. These comparisons will now raise a
TypeError (GH15492)
In [96]: df = pd.DataFrame({'unparsed_date': ['2014-01-01', '2014-01-01']})
In [97]: df.to_hdf('store.h5', 'key', format='table', data_columns=True)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/compat/_optional.py:139, in import_optional_dependency(name, extra, errors, min_version)
138 try:
--> 139 module = importlib.import_module(name)
140 except ImportError:
File /usr/lib/python3.10/importlib/__init__.py:126, in import_module(name, package)
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
File <frozen importlib._bootstrap>:1050, in _gcd_import(name, package, level)
File <frozen importlib._bootstrap>:1027, in _find_and_load(name, import_)
File <frozen importlib._bootstrap>:1004, in _find_and_load_unlocked(name, import_)
ModuleNotFoundError: No module named 'tables'
During handling of the above exception, another exception occurred:
ImportError Traceback (most recent call last)
Input In [97], in <cell line: 1>()
----> 1 df.to_hdf('store.h5', 'key', format='table', data_columns=True)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/core/generic.py:2655, in NDFrame.to_hdf(self, path_or_buf, key, mode, complevel, complib, append, format, index, min_itemsize, nan_rep, dropna, data_columns, errors, encoding)
2651 from pandas.io import pytables
2653 # Argument 3 to "to_hdf" has incompatible type "NDFrame"; expected
2654 # "Union[DataFrame, Series]" [arg-type]
-> 2655 pytables.to_hdf(
2656 path_or_buf,
2657 key,
2658 self, # type: ignore[arg-type]
2659 mode=mode,
2660 complevel=complevel,
2661 complib=complib,
2662 append=append,
2663 format=format,
2664 index=index,
2665 min_itemsize=min_itemsize,
2666 nan_rep=nan_rep,
2667 dropna=dropna,
2668 data_columns=data_columns,
2669 errors=errors,
2670 encoding=encoding,
2671 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/pytables.py:312, in to_hdf(path_or_buf, key, value, mode, complevel, complib, append, format, index, min_itemsize, nan_rep, dropna, data_columns, errors, encoding)
310 path_or_buf = stringify_path(path_or_buf)
311 if isinstance(path_or_buf, str):
--> 312 with HDFStore(
313 path_or_buf, mode=mode, complevel=complevel, complib=complib
314 ) as store:
315 f(store)
316 else:
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/pytables.py:573, in HDFStore.__init__(self, path, mode, complevel, complib, fletcher32, **kwargs)
570 if "format" in kwargs:
571 raise ValueError("format is not a defined argument for HDFStore")
--> 573 tables = import_optional_dependency("tables")
575 if complib is not None and complib not in tables.filters.all_complibs:
576 raise ValueError(
577 f"complib only supports {tables.filters.all_complibs} compression."
578 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/compat/_optional.py:142, in import_optional_dependency(name, extra, errors, min_version)
140 except ImportError:
141 if errors == "raise":
--> 142 raise ImportError(msg)
143 else:
144 return None
ImportError: Missing optional dependency 'pytables'. Use pip or conda to install pytables.
In [98]: df.dtypes
Out[98]:
unparsed_date object
Length: 1, dtype: object
以前的行为:
In [4]: pd.read_hdf('store.h5', 'key', where='unparsed_date > ts')
File "<string>", line 1
(unparsed_date > 1970-01-01 00:00:01.388552400)
^
SyntaxError: invalid token
新行为:
In [18]: ts = pd.Timestamp('2014-01-01')
In [19]: pd.read_hdf('store.h5', 'key', where='unparsed_date > ts')
TypeError: Cannot compare 2014-01-01 00:00:00 of
type <class 'pandas.tslib.Timestamp'> to string column
Index.cross和内连接现在保持左索引的顺序#
Index.intersection() 现在保留调用的顺序 Index (左)而不是另一个 Index (右) (GH15582 )。这会影响内部联接, DataFrame.join() 和 merge() ,以及 .align 方法。
Index.intersectionIn [99]: left = pd.Index([2, 1, 0]) In [100]: left Out[100]: Int64Index([2, 1, 0], dtype='int64') In [101]: right = pd.Index([1, 2, 3]) In [102]: right Out[102]: Int64Index([1, 2, 3], dtype='int64')
以前的行为:
In [4]: left.intersection(right) Out[4]: Int64Index([1, 2], dtype='int64')
新行为:
In [103]: left.intersection(right) Out[103]: Int64Index([2, 1], dtype='int64')
DataFrame.joinandpd.mergeIn [104]: left = pd.DataFrame({'a': [20, 10, 0]}, index=[2, 1, 0]) In [105]: left Out[105]: a 2 20 1 10 0 0 [3 rows x 1 columns] In [106]: right = pd.DataFrame({'b': [100, 200, 300]}, index=[1, 2, 3]) In [107]: right Out[107]: b 1 100 2 200 3 300 [3 rows x 1 columns]
以前的行为:
In [4]: left.join(right, how='inner') Out[4]: a b 1 10 100 2 20 200
新行为:
In [108]: left.join(right, how='inner') Out[108]: a b 2 20 200 1 10 100 [2 rows x 2 columns]
数据透视表始终返回DataFrame#
的文档 pivot_table() 声明一项 DataFrame 是 始终 回来了。这里修复了一个错误,该错误允许它返回一个 Series 在某些情况下。 (GH4386 )
In [109]: df = pd.DataFrame({'col1': [3, 4, 5],
.....: 'col2': ['C', 'D', 'E'],
.....: 'col3': [1, 3, 9]})
.....:
In [110]: df
Out[110]:
col1 col2 col3
0 3 C 1
1 4 D 3
2 5 E 9
[3 rows x 3 columns]
以前的行为:
In [2]: df.pivot_table('col1', index=['col3', 'col2'], aggfunc=np.sum)
Out[2]:
col3 col2
1 C 3
3 D 4
9 E 5
Name: col1, dtype: int64
新行为:
In [111]: df.pivot_table('col1', index=['col3', 'col2'], aggfunc=np.sum)
Out[111]:
col1
col3 col2
1 C 3
3 D 4
9 E 5
[3 rows x 1 columns]
其他API更改#
numexpr现在要求版本大于或等于2.4.6,如果不满足此要求,则根本不会使用该版本 (GH15213 )。CParserError已重命名为ParserError在……里面pd.read_csv()并将在未来被移除 (GH12665 )SparseArray.cumsum()和SparseSeries.cumsum()现在总是会回来SparseArray和SparseSeries分别 (GH12855 )DataFrame.applymap()with an emptyDataFramewill return a copy of the emptyDataFrameinstead of aSeries(GH8222)Series.map()now respects default values of dictionary subclasses with a__missing__method, such ascollections.Counter(GH15999).loc与……相伴.ix用于接受迭代器和命名元组 (GH15120 )interpolate()和fillna()将引发一个ValueError如果limit关键字参数不大于0。 (GH9217 )pd.read_csv()现在将发布一个ParserWarning提供的值冲突时,dialect参数和用户 (GH14898 )pd.read_csv()现在将引发一个ValueError对于C引擎,如果引号字符大于一个字节 (GH11592 )inplace参数现在需要布尔值,否则ValueError被抛出 (GH14189 )pandas.api.types.is_datetime64_ns_dtypewill now reportTrueon a tz-aware dtype, similar topandas.api.types.is_datetime64_any_dtypeDataFrame.asof()将返回一个填充的空值Series相反,标量NaN如果未找到匹配项 (GH15118 )对以下方面的具体支持
copy.copy()和copy.deepcopy()NDFrame对象上的函数 (GH15444 )Series.sort_values()accepts a one element list of bool for consistency with the behavior ofDataFrame.sort_values()(GH15604).merge()和.join()在……上面category如果可能,dtype列现在将保留类别dtype (GH10409 )SparseDataFrame.default_fill_valuewill be 0, previously wasnanin the return frompd.get_dummies(..., sparse=True)(GH15594)的默认行为
Series.str.match已从提取组更改为匹配模式。从Pandas 0.13.0版开始,提取行为就不再受欢迎,可以使用Series.str.extract方法 (GH5224 )。因此,as_indexer关键字被忽略(不再需要指定新行为),并且已弃用。NaTwill now correctly reportFalsefor datetimelike boolean operations such asis_month_start(GH15781)NaTwill now correctly returnnp.nanforTimedeltaandPeriodaccessors such asdaysandquarter(GH15782)NaT现在会回来了NaT为tz_localize和tz_convert方法: (GH15830 )DataFrame和Panel具有无效输入的构造函数现在将引发ValueError而不是PandasError,如果使用标量输入而不是轴调用 (GH15541 )DataFrame和Panel具有无效输入的构造函数现在将引发ValueError而不是pandas.core.common.PandasError,如果使用标量输入而不是轴调用;则异常PandasError也被移除了。 (GH15541 )例外情况是
pandas.core.common.AmbiguousIndexError被删除,因为它未被引用 (GH15541 )
类库的重组:隐私的变化#
模块隐私已更改#
一些以前公开的python/c/c++/cython扩展模块已经被移动和/或重命名。这些都从公共API中移除。此外, pandas.core , pandas.compat ,以及 pandas.util 顶级模块现在被认为是私有的。如果指明,如果引用这些模块,则会发出弃用警告。 (GH12588 )
以前的位置 |
新地点 |
已弃用 |
|---|---|---|
pandas.lib |
pandas._libs.lib |
X |
pandas.tslib |
pandas._libs.tslib |
X |
pandas.computation |
pandas.core.computation |
X |
pandas.msgpack |
pandas.io.msgpack |
|
pandas.index |
pandas._libs.index |
|
pandas.algos |
pandas._libs.algos |
|
pandas.hashtable |
pandas._libs.hashtable |
|
pandas.indexes |
pandas.core.indexes |
|
pandas.json |
Pandas._libs.json/anda as.io.json |
X |
pandas.parser |
pandas._libs.parsers |
X |
pandas.formats |
pandas.io.formats |
|
pandas.sparse |
pandas.core.sparse |
|
pandas.tools |
pandas.core.reshape |
X |
pandas.types |
pandas.core.dtypes |
X |
pandas.io.sas.saslib |
pandas.io.sas._sas |
|
pandas._join |
pandas._libs.join |
|
pandas._hash |
pandas._libs.hashing |
|
pandas._period |
pandas._libs.period |
|
pandas._sparse |
pandas._libs.sparse |
|
pandas._testing |
pandas._libs.testing |
|
pandas._window |
pandas._libs.window |
一些新的子包是使用不直接在顶级命名空间中公开的公共功能创建的: pandas.errors , pandas.plotting 和 pandas.testing (更多细节见下文)。与.一起 pandas.api.types 中的某些函数 pandas.io 和 pandas.tseries 子模块,这些现在是公共子程序包。
进一步的变化:
The function
union_categoricals()is now importable frompandas.api.types, formerly frompandas.types.concat(GH15998)The type import
pandas.tslib.NaTTypeis deprecated and can be replaced by usingtype(pandas.NaT)(GH16146)The public functions in
pandas.tools.hashingdeprecated from that locations, but are now importable frompandas.util(GH16223)中的模块
pandas.util:decorators,print_versions,doctools,validators,depr_module现在都是私人的。中公开的函数pandas.util其本身是公开的 (GH16223 )
pandas.errors#
我们正在为所有Pandas例外和警告添加一个标准公共模块 pandas.errors 。 (GH14800 )。以前,这些异常和警告可以从 pandas.core.common 或 pandas.io.common 。这些异常和警告将从 *.common 未来版本中的位置。 (GH15541 )
以下内容现已包含在此接口中:
['DtypeWarning',
'EmptyDataError',
'OutOfBoundsDatetime',
'ParserError',
'ParserWarning',
'PerformanceWarning',
'UnsortedIndexError',
'UnsupportedFunctionCall']
pandas.testing#
We are adding a standard module that exposes the public testing functions in pandas.testing (GH9895). Those functions can be used when writing tests for functionality using pandas objects.
以下测试函数现已包含在此接口中:
pandas.plotting#
一个新的公众 pandas.plotting 添加了包含绘图功能的模块,该功能以前位于 pandas.tools.plotting 或在顶级命名空间中。请参阅 deprecations sections 了解更多详细信息。
其他发展变化#
不推荐使用#
不推荐使用 .ix#
这个 .ix 不推荐使用索引器,而是使用更严格的 .iloc 和 .loc 索引器。 .ix 在推断用户想要做什么方面提供了很多魔力。更具体地说, .ix 可以决定建立索引 在位置上 或VIA 标签 ,具体取决于索引的数据类型。多年来,这造成了相当多的用户困惑。完整的索引文档如下 here 。 (GH14218 )
推荐的索引方法有:
.loc如果你想 标签 索引.iloc如果你想 在位置上 指数。
使用 .ix will now show a DeprecationWarning with a link to some examples of how to convert code here 。
In [112]: df = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6]},
.....: index=list('abc'))
.....:
In [113]: df
Out[113]:
A B
a 1 4
b 2 5
c 3 6
[3 rows x 2 columns]
之前的行为,其中您希望从‘A’列的索引中获取第0个和第2个元素。
In [3]: df.ix[[0, 2], 'A']
Out[3]:
a 1
c 3
Name: A, dtype: int64
使用 .loc 。在这里,我们将从索引中选择适当的索引,然后使用 标签 正在编制索引。
In [114]: df.loc[df.index[[0, 2]], 'A']
Out[114]:
a 1
c 3
Name: A, Length: 2, dtype: int64
使用 .iloc 。这里我们将获取‘A’列的位置,然后使用 位置 编入索引以选择事物。
In [115]: df.iloc[[0, 2], df.columns.get_loc('A')]
Out[115]:
a 1
c 3
Name: A, Length: 2, dtype: int64
弃用面板#
Panel is deprecated and will be removed in a future version. The recommended way to represent 3-D data are with a MultiIndex on a DataFrame via the to_frame() or with the xarray package 。Pandas提供了一种 to_xarray() 方法自动执行此转换。 (GH13563 )。
In [133]: import pandas._testing as tm
In [134]: p = tm.makePanel()
In [135]: p
Out[135]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
转换为多索引数据帧
In [136]: p.to_frame()
Out[136]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.628776 -1.409432 0.209395
B 0.988138 -1.347533 -0.896581
C -0.938153 1.272395 -0.161137
D -0.223019 -0.591863 -1.051539
2000-01-04 A 0.186494 1.422986 -0.592886
B -0.072608 0.363565 1.104352
C -1.239072 -1.449567 0.889157
D 2.123692 -0.414505 -0.319561
2000-01-05 A 0.952478 -2.147855 -1.473116
B -0.550603 -0.014752 -0.431550
C 0.139683 -1.195524 0.288377
D 0.122273 -1.425795 -0.619993
[12 rows x 3 columns]
转换为XARRAY数据数组
In [137]: p.to_xarray()
Out[137]:
<xarray.DataArray (items: 3, major_axis: 3, minor_axis: 4)>
array([[[ 0.628776, 0.988138, -0.938153, -0.223019],
[ 0.186494, -0.072608, -1.239072, 2.123692],
[ 0.952478, -0.550603, 0.139683, 0.122273]],
[[-1.409432, -1.347533, 1.272395, -0.591863],
[ 1.422986, 0.363565, -1.449567, -0.414505],
[-2.147855, -0.014752, -1.195524, -1.425795]],
[[ 0.209395, -0.896581, -0.161137, -1.051539],
[-0.592886, 1.104352, 0.889157, -0.319561],
[-1.473116, -0.43155 , 0.288377, -0.619993]]])
Coordinates:
* items (items) object 'ItemA' 'ItemB' 'ItemC'
* major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05
* minor_axis (minor_axis) object 'A' 'B' 'C' 'D'
重命名时,不建议使用字典的groupby.agg()#
这个 .groupby(..).agg(..) , .rolling(..).agg(..) ,以及 .resample(..).agg(..) 语法可以接受输入变量,包括标量、列表和标量或列表的列名字典。这为构建多个(可能不同的)聚合提供了有用的语法。
然而, .agg(..) 能 also 接受允许“重命名”结果列的字典。这是一种复杂且令人困惑的语法,而且 Series 和 DataFrame 。我们不推荐使用这种“重命名”功能。
我们不赞成将判决传递给分组/滚动/重新采样的
Series。这使得人们能够rename结果聚合,但这与将词典传递给分组的DataFrame,它接受列到聚合。我们不建议将字典传递给分组/滚动/重新采样的
DataFrame以类似的方式。
这是一个说明性的例子:
In [116]: df = pd.DataFrame({'A': [1, 1, 1, 2, 2],
.....: 'B': range(5),
.....: 'C': range(5)})
.....:
In [117]: df
Out[117]:
A B C
0 1 0 0
1 1 1 1
2 1 2 2
3 2 3 3
4 2 4 4
[5 rows x 3 columns]
以下是计算不同列的不同聚合的典型有用语法。这是一种自然且有用的语法。我们通过获取指定的列并应用函数列表来从DICT-TO-LIST聚合。这将返回一个 MultiIndex 对于列(这是 not 已弃用)。
In [118]: df.groupby('A').agg({'B': 'sum', 'C': 'min'})
Out[118]:
B C
A
1 3 0
2 7 3
[2 rows x 2 columns]
下面是第一个弃用的示例,将一个字典传递给一个分组 Series 。这是聚合和重命名的组合:
In [6]: df.groupby('A').B.agg({'foo': 'count'})
FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version
Out[6]:
foo
A
1 3
2 2
您可以通过以下方式来完成相同的操作,更贴切地说:
In [119]: df.groupby('A').B.agg(['count']).rename(columns={'count': 'foo'})
Out[119]:
foo
A
1 3
2 2
[2 rows x 1 columns]
下面是第二个弃用的示例,将词典传递给分组的 DataFrame :
In [23]: (df.groupby('A')
...: .agg({'B': {'foo': 'sum'}, 'C': {'bar': 'min'}})
...: )
FutureWarning: using a dict with renaming is deprecated and
will be removed in a future version
Out[23]:
B C
foo bar
A
1 3 0
2 7 3
您可以通过以下方式实现几乎相同的目标:
In [120]: (df.groupby('A')
.....: .agg({'B': 'sum', 'C': 'min'})
.....: .rename(columns={'B': 'foo', 'C': 'bar'})
.....: )
.....:
Out[120]:
foo bar
A
1 3 0
2 7 3
[2 rows x 2 columns]
不推荐使用.ploting#
The pandas.tools.plotting module has been deprecated, in favor of the top level pandas.plotting module. All the public plotting functions are now available
from pandas.plotting (GH12548).
此外,最高层 pandas.scatter_matrix 和 pandas.plot_params 都已被弃用。用户可以从以下位置导入 pandas.plotting 也是。
上一个脚本:
pd.tools.plotting.scatter_matrix(df)
pd.scatter_matrix(df)
应更改为:
pd.plotting.scatter_matrix(df)
其他不推荐使用的词#
SparseArray.to_dense()已不推荐使用fill参数,因为该参数未被遵守 (GH14647 )SparseSeries.to_dense()已不推荐使用sparse_only参数 (GH14647 )Series.repeat()has deprecated therepsparameter in favor ofrepeats(GH12662)这个
Series构造函数和.astype方法不推荐接受没有频率的时间戳数据类型(例如np.datetime64),用于dtype参数 (GH15524 )Index.repeat()andMultiIndex.repeat()have deprecated thenparameter in favor ofrepeats(GH12662)Categorical.searchsorted()andSeries.searchsorted()have deprecated thevparameter in favor ofvalue(GH12662)TimedeltaIndex.searchsorted(),DatetimeIndex.searchsorted(), andPeriodIndex.searchsorted()have deprecated thekeyparameter in favor ofvalue(GH12662)DataFrame.astype()has deprecated theraise_on_errorparameter in favor oferrors(GH14878)Series.sortlevelandDataFrame.sortlevelhave been deprecated in favor ofSeries.sort_indexandDataFrame.sort_index(GH15099)正在导入
concat从…pandas.tools.merge已被弃用,而是支持从pandas命名空间。这应该只影响显式导入 (GH15358 )Series/DataFrame/Panel.consolidate()作为公共方法已被弃用。 (GH15483 )这个
as_indexer的关键字Series.str.match()已弃用(忽略关键字) (GH15257 )。以下顶级Pandas函数已弃用,将在未来版本中删除 (GH13790 , GH15940 )
pd.pnow(), replaced byPeriod.now()pd.Term被移除,因为它不适用于用户代码。在HDFStore中进行搜索时,请改用WHERE子句中的内联字符串表达式pd.Expr被移除,因为它不适用于用户代码。pd.match(),则被删除。pd.groupby(), replaced by using the.groupby()method directly on aSeries/DataFramepd.get_store(), replaced by a direct call topd.HDFStore(...)
is_any_int_dtype,is_floating_dtype, andis_sequenceare deprecated frompandas.api.types(GH16042)
删除先前版本的弃用/更改#
这个
pandas.rpymodule is removed. Similar functionality can be accessed through the rpy2 项目。请参阅 R interfacing docs 了解更多详细信息。这个
pandas.io.gamodule with agoogle-analyticsinterface is removed (GH11308). Similar functionality can be found in the Google2Pandas 包裹。pd.to_datetimeandpd.to_timedeltahave dropped thecoerceparameter in favor oferrors(GH13602)pandas.stats.fama_macbeth,pandas.stats.ols,pandas.stats.plmandpandas.stats.var, as well as the top-levelpandas.fama_macbethandpandas.olsroutines are removed. Similar functionality can be found in the statsmodels 包裹。 (GH11898 )这个
TimeSeries和SparseTimeSeries类、别名Series和SparseSeries,将被移除 (GH10890 , GH15098 )。Series.is_time_seriesis dropped in favor ofSeries.index.is_all_dates(GH15098)The deprecated
irow,icol,igetandiget_valuemethods are removed in favor ofilocandiatas explained here (GH10711).The deprecated
DataFrame.iterkv()has been removed in favor ofDataFrame.iteritems()(GH10711)这个
Categorical构造函数已删除name参数 (GH10632 )Categorical已放弃对以下各项的支持NaN范畴 (GH10748 )这个
take_last参数已从duplicated(),drop_duplicates(),nlargest(),以及nsmallest()方法: (GH10236 , GH10792 , GH10920 )Series,Index,以及DataFrame已经丢弃了sort和order方法: (GH10726 )WHERE子句中
pytables仅接受作为字符串和表达式类型,而不接受其他数据类型 (GH12027 )DataFrame已经放弃了combineAdd和combineMult赞成的方法add和mul分别 (GH10735 )
性能改进#
Improved performance of
pd.wide_to_long()(GH14779)改进的性能
pd.factorize()通过释放GILobject当推断为字符串时的数据类型 (GH14859 , GH16057 )改进了使用不规则DatetimeIndex(或使用
compat_x=True) (GH15073 )。Improved performance of
groupby().cummin()andgroupby().cummax()(GH15048, GH15109, GH15561, GH15635)Improved performance and reduced memory when indexing with a
MultiIndex(GH15245)在读取缓冲区对象时
read_sas()方法,则推断文件路径字符串而不是缓冲区对象。 (GH14947 )改进的性能
.rank()对于分类数据 (GH15498 )Improved performance when using
.unstack()(GH15503)改进了合并/联接的性能
category列 (GH10409 )改进的性能
drop_duplicates()在……上面bool列 (GH12963 )提高性能
pd.core.groupby.GroupBy.apply当应用的函数使用.name组DataFrame的属性 (GH15062 )。改进的性能
iloc使用列表或数组进行索引 (GH15504 )。改进的性能
Series.sort_index()具有单调指数 (GH15694 )提高了
pd.read_csv()在某些带有缓冲读取的平台上 (GH16039 )
错误修复#
转换#
Bug in
Timestamp.replacenow raisesTypeErrorwhen incorrect argument names are given; previously this raisedValueError(GH15240)窃听
Timestamp.replace使用COMPAT传递长整数 (GH15030 )窃听
TimedeltaIndex在没有错误的情况下允许溢出的添加 (GH14816 )Bug in
TimedeltaIndexraising aValueErrorwhen boolean indexing withloc(GH14946)捕获溢出中的错误
Timestamp+Timedelta/Offset运营 (GH15126 )窃听
DatetimeIndex.round()和Timestamp.round()舍入毫秒或更小时的浮点精度 (GH14440 , GH15578 )窃听
astype()哪里inf值被错误地转换为整数。现在引发错误,现在使用astype()对于系列和DataFrame (GH14265 )窃听
DataFrame(..).apply(to_numeric)当值的类型为Decimal.Decimal时。 (GH14827 )窃听
describe()将不包含中值的Numy数组传递给percentiles关键字参数 (GH14908 )清理干净了
PeriodIndex构造函数,包括更一致地在浮点数上引发 (GH13277 )在使用中出现错误
__deepcopy__关于空的NDFrame对象 (GH15370 )窃听
Series.replace和DataFrame.replace它在空的替换字典上失败 (GH15289 )窃听
Series.replace它将数字替换为字符串 (GH15743 )窃听
Index使用以下工具进行施工NaN指定的元素和整型数据类型 (GH15187 )窃听
Series有日期的施工 (GH14928 )窃听
Series.dt.round()不一致的行为NaT有不同的论点 (GH14940 )窃听
Series构造函数,当两者都copy=True和dtype提供了参数 (GH15125 )Incorrect dtyped
Serieswas returned by comparison methods (e.g.,lt,gt, ...) against a constant for an emptyDataFrame(GH15077)窃听
Series.ffill()具有包含TZ感知的日期时间的混合数据类型。 (GH14956 )Bug in
DataFrame.fillna()where the argumentdowncastwas ignored when fillna value was of typedict(GH15277)Bug in
.asfreq(), where frequency was not set for emptySeries(GH14320)窃听
DataFrame在类列表中使用空值和日期时间进行构造 (GH15869 )窃听
DataFrame.fillna()使用TZ感知的DateTime (GH15855 )窃听
is_string_dtype,is_timedelta64_ns_dtype,以及is_string_like_dtype当出现以下情况时,会引发错误None是传入的 (GH15941 )Bug in the return type of
pd.uniqueon aCategorical, which was returning an ndarray and not aCategorical(GH15903)窃听
Index.to_series()在索引未被复制的情况下(因此后来的突变将改变原始索引), (GH15949 )使用len-1 DataFrame对部分字符串进行索引时出现错误 (GH16071 )
窃听
Series传递无效数据类型不会引发错误的构造。 (GH15520 )
标引#
窃听
Index操作数反转的幂运算 (GH14973 )Bug in
DataFrame.sort_values()when sorting by multiple columns where one column is of typeint64and containsNaT(GH14922)Bug in
DataFrame.reindex()in whichmethodwas ignored when passingcolumns(GH14992)窃听
DataFrame.loc使用索引将一个MultiIndex使用一个Series索引器 (GH14730 , GH15424 )窃听
DataFrame.loc使用索引将一个MultiIndex使用一个稀疏的数组 (GH15434 )Bug in
Series.asofwhich raised if the series contained allnp.nan(GH15713)窃听
.at当从TZ感知列中进行选择时 (GH15822 )窃听
Series.where()和DataFrame.where()其中类似数组的条件条件被拒绝 (GH15414 )窃听
Series.where()将支持TZ的数据转换为浮点表示形式的位置 (GH15701 )窃听
.loc这不会为DataFrame的标量访问返回正确的数据类型 (GH11617 )窃听
Categorical.searchsorted()其中使用的是字母顺序而不是提供的分类顺序 (GH14522 )窃听
Series.iloc其中一个Categorical对象,其中一个Series是意料之中的。 (GH14580 )窃听
DataFrame.isin将类似日期的帧与空帧进行比较 (GH15473 )窃听
.reset_index()当所有人都NaN级别为MultiIndex会失败的 (GH6322 )窃听
.reset_index()引发索引名称已存在于中的错误时MultiIndex列 (GH16120 )Bug in creating a
MultiIndexwith tuples and not passing a list of names; this will now raiseValueError(GH15110)在HTML显示中出现错误
MultiIndex和截断 (GH14882 )显示中的错误
.info()其中,限定符(+)将始终与MultiIndex只包含非字符串的 (GH15245 )Bug in
pd.concat()where the names ofMultiIndexof resultingDataFrameare not handled correctly whenNoneis presented in the names ofMultiIndexof inputDataFrame(GH15787)Bug in
DataFrame.sort_index()andSeries.sort_index()wherena_positiondoesn't work with aMultiIndex(GH14784, GH16604)Bug in
pd.concat()when combining objects with aCategoricalIndex(GH16111)Bug in indexing with a scalar and a
CategoricalIndex(GH16123)
IO#
窃听
pd.read_fwf()其中,在列宽推断过程中未考虑skiprows参数 (GH11256 )窃听
pd.read_csv()其中dialect参数在处理前未进行验证 (GH14898 )Bug in
pd.read_csv()in which missing data was being improperly handled withusecols(GH6710)窃听
pd.read_csv()如果文件包含具有多列的行,后跟较少列的行,则会导致崩溃 (GH14125 )Bug in
pd.read_csv()for the C engine whereusecolswere being indexed incorrectly withparse_dates(GH14792)窃听
pd.read_csv()使用parse_dates当指定多行页眉时 (GH15376 )窃听
pd.read_csv()使用float_precision='round_trip'在解析文本条目时,这会导致段错误 (GH15140 )窃听
pd.read_csv()当指定了索引且未将任何值指定为空值时 (GH15835 )窃听
pd.read_csv()其中某些无效的文件对象会导致Python解释器崩溃 (GH15337 )窃听
pd.read_csv()其中的无效值nrows和chunksize都被允许 (GH15767 )窃听
pd.read_csv()对于在发生解析错误时引发无用错误消息的Python引擎 (GH15910 )窃听
pd.read_csv()其中skipfooter未正确验证参数 (GH15925 )窃听
pd.to_csv()其中在写入时间戳索引时存在数字溢出 (GH15982 )窃听
pd.util.hashing.hash_pandas_object()其中,分类词的散列依赖于类别的排序,而不仅仅是它们的值。 (GH15143 )窃听
.to_json()哪里lines=True和内容(键或值)包含转义字符 (GH15096 )窃听
.to_json()导致单字节ASCII字符扩展为四个字节的Unicode (GH15344 )窃听
.to_json()对于没有正确处理翻转的C引擎,在frc为奇数且diff恰好为0.5的情况下 (GH15716 , GH15864 )窃听
pd.read_json()对于Python2,其中lines=True和内容包含非ASCII Unicode字符 (GH15132 )窃听
pd.read_msgpack()其中Series分类信息被错误地处理 (GH14901 )Bug in
pd.read_msgpack()which did not allow loading of a dataframe with an index of typeCategoricalIndex(GH15487)Bug in
pd.read_msgpack()when deserializing aCategoricalIndex(GH15487)窃听
DataFrame.to_records()使用转换为DatetimeIndex使用时区 (GH13937 )窃听
DataFrame.to_records()失败,列名中包含Unicode字符 (GH11879 )窃听
.to_sql()使用数字索引名编写DataFrame时 (GH15404 )。Bug in
DataFrame.to_html()withindex=Falseandmax_rowsraising inIndexError(GH14998)窃听
pd.read_hdf()传递一个Timestamp发送到where具有非日期列的参数 (GH15492 )窃听
DataFrame.to_stata()和StataWriter它会为某些区域设置生成格式不正确的文件 (GH13856 )窃听
StataReader和StataWriter,它允许无效编码。 (GH15723 )Bug in the
Series当输出被截断时,REPR不显示长度 (GH15962 )。
标绘#
分组依据/重采样/滚动#
窃听
.groupby(..).resample()当传递给on=科瓦格。 (GH15021 )正确设置
__name__和__qualname__为Groupby.*功能 (GH14620 )窃听
GroupBy.get_group()用绝对的石斑鱼失败 (GH15155 )Bug in
.groupby(...).rolling(...)whenonis specified and using aDatetimeIndex(GH15130, GH13966)Bug in groupby operations with
timedelta64when passingnumeric_only=False(GH5724)窃听
groupby.apply()胁迫object当并非所有值都是数值时,将数据类型转换为数值类型 (GH14423 , GH15421 , GH15670 )窃听
resample,其中非字符串loffset对时间序列进行重新采样时不会应用参数 (GH13218 )窃听
DataFrame.groupby().describe()在分组时Index包含元组 (GH14848 )窃听
groupby().nunique()使用类DateTime-Grouper,其中箱计数不正确 (GH13453 )窃听
groupby.transform()这将强制将结果数据类型恢复为原始数据类型 (GH10972 , GH11444 )Bug in
groupby.agg()incorrectly localizing timezone ondatetime(GH15426, GH10668, GH13046)窃听
.rolling/expanding()函数,其中count()是不算的np.Inf,也不处理object数据类型 (GH12541 )窃听
.rolling()哪里pd.Timedelta或datetime.timedelta未被接受为window论据 (GH15440 )Bug in
Rolling.quantilefunction that caused a segmentation fault when called with a quantile value outside of the range [0, 1] (GH15463)窃听
DataFrame.resample().median()如果存在重复的列名 (GH14233 )
稀疏#
重塑#
窃听
pd.merge_asof()哪里left_index或right_index导致在以下情况下出现故障by被指定为 (GH15676 )窃听
pd.merge_asof()whereleft_index/right_index一起导致了失败,当tolerance被指定为 (GH15135 )窃听
DataFrame.pivot_table()哪里dropna=True在列是时,不会删除全南列category数据类型 (GH15193 )Bug in
pd.melt()where passing a tuple value forvalue_varscaused aTypeError(GH15348)窃听
pd.pivot_table()如果值参数不在列中,则不会引发错误 (GH14938 )窃听
pd.concat()在这种情况下,连接一个空的数据帧join='inner'被不恰当地处理 (GH15328 )BUG与
sort=True在……里面DataFrame.join和pd.merge连接索引时 (GH15582 )窃听
DataFrame.nsmallest和DataFrame.nlargest其中相同的值会产生重复的行 (GH15297 )窃听
pandas.pivot_table()错误地提高UnicodeError将Unicode输入传递给margins关键字 (GH13292 )
数字#
窃听
.rank()它错误地对有序类别进行了排序 (GH15420 )窃听
.corr()和.cov()其中,列和索引是同一对象 (GH14617 )窃听
.mode()哪里mode如果仅为单个值,则不返回 (GH15714 )窃听
pd.cut()在全0阵列上具有单个存储单元 (GH15428 )窃听
pd.qcut()具有单个分位数和具有相同值的数组 (GH15431 )窃听
pandas.tools.utils.cartesian_product()使用大输入可能会导致Windows上的溢出 (GH15265 )窃听
.eval()这会导致多行计算失败,因为局部变量不在第一行 (GH15342 )
其他#
贡献者#
共有204人为此次发布贡献了补丁。名字中带有“+”的人第一次贡献了一个补丁。
Adam J. Stewart +
Adrian +
Ajay Saxena
Akash Tandon +
Albert Villanova del Moral +
Aleksey Bilogur +
Alexis Mignon +
Amol Kahat +
Andreas Winkler +
Andrew Kittredge +
Anthonios Partheniou
Arco Bast +
Ashish Singal +
Baurzhan Muftakhidinov +
Ben Kandel
Ben Thayer +
Ben Welsh +
Bill Chambers +
Brandon M. Burroughs
Brian +
Brian McFee +
Carlos Souza +
Chris
Chris Ham
Chris Warth
Christoph Gohlke
Christoph Paulik +
Christopher C. Aycock
Clemens Brunner +
D.S. McNeil +
DaanVanHauwermeiren +
Daniel Himmelstein
Dave Willmer
David Cook +
David Gwynne +
David Hoffman +
David Krych
Diego Fernandez +
Dimitris Spathis +
Dmitry L +
Dody Suria Wijaya +
Dominik Stanczak +
Dr-Irv
Dr. Irv +
Elliott Sales de Andrade +
Ennemoser Christoph +
Francesc Alted +
Fumito Hamamura +
Giacomo Ferroni
Graham R. Jeffries +
Greg Williams +
Guilherme Beltramini +
Guilherme Samora +
Hao Wu +
Harshit Patni +
Ilya V. Schurov +
Iván Vallés Pérez
Jackie Leng +
Jaehoon Hwang +
James Draper +
James Goppert +
James McBride +
James Santucci +
Jan Schulz
Jeff Carey
Jeff Reback
JennaVergeynst +
Jim +
Jim Crist
Joe Jevnik
Joel Nothman +
John +
John Tucker +
John W. O'Brien
John Zwinck
Jon M. Mease
Jon Mease
Jonathan Whitmore +
Jonathan de Bruin +
Joost Kranendonk +
Joris Van den Bossche
Joshua Bradt +
Julian Santander
Julien Marrec +
Jun Kim +
Justin Solinsky +
Kacawi +
Kamal Kamalaldin +
Kerby Shedden
Kernc
Keshav Ramaswamy
Kevin Sheppard
Kyle Kelley
Larry Ren
Leon Yin +
Line Pedersen +
Lorenzo Cestaro +
Luca Scarabello
Lukasz +
Mahmoud Lababidi
Mark Mandel +
Matt Roeschke
Matthew Brett
Matthew Roeschke +
Matti Picus
Maximilian Roos
Michael Charlton +
Michael Felt
Michael Lamparski +
Michiel Stock +
Mikolaj Chwalisz +
Min RK
Miroslav Šedivý +
Mykola Golubyev
Nate Yoder
Nathalie Rud +
Nicholas Ver Halen
Nick Chmura +
Nolan Nichols +
Pankaj Pandey +
Pawel Kordek
Pete Huang +
Peter +
Peter Csizsek +
Petio Petrov +
Phil Ruffwind +
Pietro Battiston
Piotr Chromiec
Prasanjit Prakash +
Rob Forgione +
Robert Bradshaw
Robin +
Rodolfo Fernandez
Roger Thomas
Rouz Azari +
Sahil Dua
Sam Foo +
Sami Salonen +
Sarah Bird +
Sarma Tangirala +
Scott Sanderson
Sebastian Bank
Sebastian Gsänger +
Shawn Heide
Shyam Saladi +
Sinhrks
Stephen Rauch +
Sébastien de Menten +
Tara Adiseshan
Thiago Serafim
Thoralf Gutierrez +
Thrasibule +
Tobias Gustafsson +
Tom Augspurger
Tong SHEN +
Tong Shen +
TrigonaMinima +
Uwe +
Wes Turner
Wiktor Tomczak +
WillAyd
Yaroslav Halchenko
Yimeng Zhang +
abaldenko +
adrian-stepien +
alexandercbooth +
atbd +
bastewart +
bmagnusson +
carlosdanielcsantos +
chaimdemulder +
chris-b1
dickreuter +
discort +
dr-leo +
dubourg
dwkenefick +
funnycrab +
gfyoung
goldenbull +
hesham.shabana@hotmail.com
jojomdt +
linebp +
manu +
manuels +
mattip +
maxalbert +
mcocdawc +
nuffe +
paul-mannino
pbreach +
sakkemo +
scls19fr
sinhrks
stijnvanhoey +
the-nose-knows +
themrmax +
tomrod +
tzinckgraf
wandersoncferreira
watercrossing +
wcwagner
xgdgsc +
yui-knk