版本0.17.0(2015年10月9日)#
这是从0.16.2发布的一个主要版本,包括少量的API更改、几个新功能、增强功能和性能改进,以及大量的错误修复。我们建议所有用户升级到此版本。
警告
Pandas>=0.17.0将不再支持与Python 3.2版的兼容性 (GH9118 )
警告
The pandas.io.data package is deprecated and will be replaced by the
pandas-datareader package.
This will allow the data modules to be independently updated to your pandas
installation. The API for pandas-datareader v0.1.1 is exactly the same
as in pandas v0.17.0 (GH8961, GH10861).
安装Pandas-DataReader后,您可以轻松更改您的导入:
from pandas.io import data, wb
变成了
from pandas_datareader import data, wb
亮点包括:
在一些Cython操作上释放全局解释器锁(GIL),请参见 here
绘图方法现在可以作为
.plot访问者,请参见 here对排序API进行了修改,删除了一些长期不一致的问题,请参见 here
支持
datetime64[ns]如果将时区作为一级数据类型,请参见 here的默认设置
to_datetime现在将是raise当以无法解析的格式呈现时,以前这将返回原始输入。此外,日期解析函数现在返回一致的结果。看见 here的默认设置
dropna在……里面HDFStore已更改为False,默认情况下存储所有行,即使它们都是NaN,请参见 hereDateTime访问器 (
dt)现在支持Series.dt.strftime为DateTime-Like生成格式化字符串,以及Series.dt.total_seconds生成时间增量的每个持续时间(以秒为单位)。看见 herePeriodandPeriodIndexcan handle multiplied freq like3D, which corresponding to 3 days span. See here开发安装的Pandas版本现在将有
PEP440符合标准的版本字符串 (GH9518 )Development support for benchmarking with the Air Speed Velocity library (GH8361)
支持读取SAS xport文件,请参阅 here
将SA与 Pandas ,请参见 here
删除自0.8.0起不建议使用的自动时间序列广播,请参见 here
纯文本显示格式可以选择与Unicode东亚宽度对齐,请参见 here
与Python3.5的兼容性 (GH11097 )
与matplotlib 1.5.0兼容 (GH11111 )
检查 API Changes 和 deprecations 在更新之前。
V0.17.0中的新特性
新功能#
与TZ的约会时间#
我们正在添加一个本地支持带有时区的DateTime的实现。一个 Series 或者是 DataFrame 之前的专栏 可能 被分配一个带有时区的日期时间,并将作为 object 数据类型。这在行数较多的情况下存在性能问题。请参阅 docs 了解更多详细信息。 (GH8260 , GH10763 , GH11034 )。
新的实现允许跨所有行使用单一时区,并以性能良好的方式进行操作。
In [1]: df = pd.DataFrame(
...: {
...: "A": pd.date_range("20130101", periods=3),
...: "B": pd.date_range("20130101", periods=3, tz="US/Eastern"),
...: "C": pd.date_range("20130101", periods=3, tz="CET"),
...: }
...: )
...:
In [2]: df
Out[2]:
A B C
0 2013-01-01 2013-01-01 00:00:00-05:00 2013-01-01 00:00:00+01:00
1 2013-01-02 2013-01-02 00:00:00-05:00 2013-01-02 00:00:00+01:00
2 2013-01-03 2013-01-03 00:00:00-05:00 2013-01-03 00:00:00+01:00
[3 rows x 3 columns]
In [3]: df.dtypes
Out[3]:
A datetime64[ns]
B datetime64[ns, US/Eastern]
C datetime64[ns, CET]
Length: 3, dtype: object
In [4]: df.B
Out[4]:
0 2013-01-01 00:00:00-05:00
1 2013-01-02 00:00:00-05:00
2 2013-01-03 00:00:00-05:00
Name: B, Length: 3, dtype: datetime64[ns, US/Eastern]
In [5]: df.B.dt.tz_localize(None)
Out[5]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
Name: B, Length: 3, dtype: datetime64[ns]
它还使用了一种新的dtype表示,在外观和感觉上与它的Numty表亲非常相似 datetime64[ns]
In [6]: df["B"].dtype
Out[6]: datetime64[ns, US/Eastern]
In [7]: type(df["B"].dtype)
Out[7]: pandas.core.dtypes.dtypes.DatetimeTZDtype
备注
对于基础的 DatetimeIndex 作为数据类型更改的结果,但在功能上是相同的。
以前的行为:
In [1]: pd.date_range('20130101', periods=3, tz='US/Eastern')
Out[1]: DatetimeIndex(['2013-01-01 00:00:00-05:00', '2013-01-02 00:00:00-05:00',
'2013-01-03 00:00:00-05:00'],
dtype='datetime64[ns]', freq='D', tz='US/Eastern')
In [2]: pd.date_range('20130101', periods=3, tz='US/Eastern').dtype
Out[2]: dtype('<M8[ns]')
新行为:
In [8]: pd.date_range("20130101", periods=3, tz="US/Eastern")
Out[8]:
DatetimeIndex(['2013-01-01 00:00:00-05:00', '2013-01-02 00:00:00-05:00',
'2013-01-03 00:00:00-05:00'],
dtype='datetime64[ns, US/Eastern]', freq='D')
In [9]: pd.date_range("20130101", periods=3, tz="US/Eastern").dtype
Out[9]: datetime64[ns, US/Eastern]
释放Gil#
我们正在发布一些cython操作的全局解释锁(GIL)。这将允许其他线程在计算期间同时运行,从而潜在地允许多线程提高性能。值得注意的是 groupby , nsmallest , value_counts 而一些索引操作也从中受益。 (GH8882 )
例如,以下代码中的Groupby表达式将在因式分解步骤中释放GIL,例如 df.groupby('key') 以及 .sum() 手术开始了。
N = 1000000
ngroups = 10
df = DataFrame(
{"key": np.random.randint(0, ngroups, size=N), "data": np.random.randn(N)}
)
df.groupby("key")["data"].sum()
发布GIL可以使使用线程进行用户交互的应用程序受益(例如 QT) ,或执行多线程计算。可以并行处理这些类型的计算的库的一个很好的例子是 dask 类库。
曲线图的子方法#
系列和DataFrame .plot() 方法允许自定义 plot types 通过提供 kind 关键字参数。不幸的是,许多这类绘图使用不同的必需和可选关键字参数,这使得很难从数十个可能的参数中发现任何给定的绘图类型使用了什么。
为了缓解这个问题,我们添加了一个新的、可选的绘图接口,它将每种绘图公开为 .plot 属性。与其写作,不如 series.plot(kind=<kind>, ...) ,您现在还可以使用 series.plot.<kind>(...) :
In [10]: df = pd.DataFrame(np.random.rand(10, 2), columns=['a', 'b'])
In [11]: df.plot.bar()
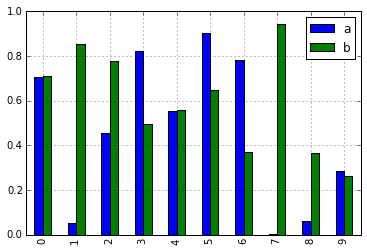
由于这一变化,这些方法现在都可以通过制表符完成来发现:
In [12]: df.plot.<TAB> # noqa: E225, E999
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
每个方法签名仅包括相关参数。目前,这些参数仅限于必需参数,但将来还将包括可选参数。有关概述,请参阅新的 标绘 API文档。
其他方法可用于 dt 访问者#
Series.dt.strftime#
我们现在支持一个 Series.dt.strftime DateTime的方法-喜欢生成格式化字符串 (GH10110 )。例如:
# DatetimeIndex
In [13]: s = pd.Series(pd.date_range("20130101", periods=4))
In [14]: s
Out[14]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
Length: 4, dtype: datetime64[ns]
In [15]: s.dt.strftime("%Y/%m/%d")
Out[15]:
0 2013/01/01
1 2013/01/02
2 2013/01/03
3 2013/01/04
Length: 4, dtype: object
# PeriodIndex
In [16]: s = pd.Series(pd.period_range("20130101", periods=4))
In [17]: s
Out[17]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
Length: 4, dtype: period[D]
In [18]: s.dt.strftime("%Y/%m/%d")
Out[18]:
0 2013/01/01
1 2013/01/02
2 2013/01/03
3 2013/01/04
Length: 4, dtype: object
字符串格式是作为Python标准库的,详细信息可以找到 here
Series.dt.total_seconds#
pd.Series 类型的 timedelta64 有新的方法 .dt.total_seconds() 返回时间增量的持续时间(秒) (GH10817 )
# TimedeltaIndex
In [19]: s = pd.Series(pd.timedelta_range("1 minutes", periods=4))
In [20]: s
Out[20]:
0 0 days 00:01:00
1 1 days 00:01:00
2 2 days 00:01:00
3 3 days 00:01:00
Length: 4, dtype: timedelta64[ns]
In [21]: s.dt.total_seconds()
Out[21]:
0 60.0
1 86460.0
2 172860.0
3 259260.0
Length: 4, dtype: float64
周期频率增强#
Period, PeriodIndex and period_range can now accept multiplied freq. Also, Period.freq and PeriodIndex.freq are now stored as a DateOffset instance like DatetimeIndex, and not as str (GH7811)
乘以的频率Q表示相应长度的跨度。下面的示例创建了一个3天的周期。加法和减法将按跨度移动周期。
In [22]: p = pd.Period("2015-08-01", freq="3D")
In [23]: p
Out[23]: Period('2015-08-01', '3D')
In [24]: p + 1
Out[24]: Period('2015-08-04', '3D')
In [25]: p - 2
Out[25]: Period('2015-07-26', '3D')
In [26]: p.to_timestamp()
Out[26]: Timestamp('2015-08-01 00:00:00')
In [27]: p.to_timestamp(how="E")
Out[27]: Timestamp('2015-08-03 23:59:59.999999999')
您可以使用相乘后的频率 PeriodIndex 和 period_range 。
In [28]: idx = pd.period_range("2015-08-01", periods=4, freq="2D")
In [29]: idx
Out[29]: PeriodIndex(['2015-08-01', '2015-08-03', '2015-08-05', '2015-08-07'], dtype='period[2D]')
In [30]: idx + 1
Out[30]: PeriodIndex(['2015-08-03', '2015-08-05', '2015-08-07', '2015-08-09'], dtype='period[2D]')
支持SAS XPORT文件#
read_sas() 为阅读提供支持 SAS XPORT 格式化文件。 (GH4052 )。
df = pd.read_sas("sas_xport.xpt")
还可以获得迭代器并以增量方式读取XPORT文件。
for df in pd.read_sas("sas_xport.xpt", chunksize=10000):
do_something(df)
请参阅 docs 了解更多详细信息。
支持.val()中的数学函数#
df = pd.DataFrame({"a": np.random.randn(10)})
df.eval("b = sin(a)")
支持的数学函数有 sin , cos , exp , log , expm1 , log1p , sqrt , sinh , cosh , tanh , arcsin , arccos , arctan , arccosh , arcsinh , arctanh , abs 和 arctan2 。
这些函数映射到 NumExpr 引擎。对于Python引擎,它们被映射到 NumPy 电话。
使用对Excel进行的更改 MultiIndex#
在0.16.2a版中 DataFrame 使用 MultiIndex 无法通过以下方式将列写入Excel to_excel 。该功能已添加 (GH10564 ),以及更新 read_excel 这样,通过指定哪些列/行构成 MultiIndex 在 header 和 index_col 参数 (GH4679 )
请参阅 documentation 了解更多详细信息。
In [31]: df = pd.DataFrame(
....: [[1, 2, 3, 4], [5, 6, 7, 8]],
....: columns=pd.MultiIndex.from_product(
....: [["foo", "bar"], ["a", "b"]], names=["col1", "col2"]
....: ),
....: index=pd.MultiIndex.from_product([["j"], ["l", "k"]], names=["i1", "i2"]),
....: )
....:
In [32]: df
Out[32]:
col1 foo bar
col2 a b a b
i1 i2
j l 1 2 3 4
k 5 6 7 8
[2 rows x 4 columns]
In [33]: df.to_excel("test.xlsx")
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Input In [33], in <cell line: 1>()
----> 1 df.to_excel("test.xlsx")
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/core/generic.py:2237, in NDFrame.to_excel(self, excel_writer, sheet_name, na_rep, float_format, columns, header, index, index_label, startrow, startcol, engine, merge_cells, encoding, inf_rep, verbose, freeze_panes, storage_options)
2224 from pandas.io.formats.excel import ExcelFormatter
2226 formatter = ExcelFormatter(
2227 df,
2228 na_rep=na_rep,
(...)
2235 inf_rep=inf_rep,
2236 )
-> 2237 formatter.write(
2238 excel_writer,
2239 sheet_name=sheet_name,
2240 startrow=startrow,
2241 startcol=startcol,
2242 freeze_panes=freeze_panes,
2243 engine=engine,
2244 storage_options=storage_options,
2245 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/formats/excel.py:896, in ExcelFormatter.write(self, writer, sheet_name, startrow, startcol, freeze_panes, engine, storage_options)
892 need_save = False
893 else:
894 # error: Cannot instantiate abstract class 'ExcelWriter' with abstract
895 # attributes 'engine', 'save', 'supported_extensions' and 'write_cells'
--> 896 writer = ExcelWriter( # type: ignore[abstract]
897 writer, engine=engine, storage_options=storage_options
898 )
899 need_save = True
901 try:
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/excel/_openpyxl.py:55, in OpenpyxlWriter.__init__(self, path, engine, date_format, datetime_format, mode, storage_options, if_sheet_exists, engine_kwargs, **kwargs)
42 def __init__(
43 self,
44 path: FilePath | WriteExcelBuffer | ExcelWriter,
(...)
53 ) -> None:
54 # Use the openpyxl module as the Excel writer.
---> 55 from openpyxl.workbook import Workbook
57 engine_kwargs = combine_kwargs(engine_kwargs, kwargs)
59 super().__init__(
60 path,
61 mode=mode,
(...)
64 engine_kwargs=engine_kwargs,
65 )
ModuleNotFoundError: No module named 'openpyxl'
In [34]: df = pd.read_excel("test.xlsx", header=[0, 1], index_col=[0, 1])
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Input In [34], in <cell line: 1>()
----> 1 df = pd.read_excel("test.xlsx", header=[0, 1], index_col=[0, 1])
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/util/_decorators.py:317, in deprecate_nonkeyword_arguments.<locals>.decorate.<locals>.wrapper(*args, **kwargs)
311 if len(args) > num_allow_args:
312 warnings.warn(
313 msg.format(arguments=arguments),
314 FutureWarning,
315 stacklevel=stacklevel,
316 )
--> 317 return func(*args, **kwargs)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/excel/_base.py:458, in read_excel(io, sheet_name, header, names, index_col, usecols, squeeze, dtype, engine, converters, true_values, false_values, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, parse_dates, date_parser, thousands, decimal, comment, skipfooter, convert_float, mangle_dupe_cols, storage_options)
456 if not isinstance(io, ExcelFile):
457 should_close = True
--> 458 io = ExcelFile(io, storage_options=storage_options, engine=engine)
459 elif engine and engine != io.engine:
460 raise ValueError(
461 "Engine should not be specified when passing "
462 "an ExcelFile - ExcelFile already has the engine set"
463 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/excel/_base.py:1482, in ExcelFile.__init__(self, path_or_buffer, engine, storage_options)
1480 ext = "xls"
1481 else:
-> 1482 ext = inspect_excel_format(
1483 content_or_path=path_or_buffer, storage_options=storage_options
1484 )
1485 if ext is None:
1486 raise ValueError(
1487 "Excel file format cannot be determined, you must specify "
1488 "an engine manually."
1489 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/excel/_base.py:1355, in inspect_excel_format(content_or_path, storage_options)
1352 if isinstance(content_or_path, bytes):
1353 content_or_path = BytesIO(content_or_path)
-> 1355 with get_handle(
1356 content_or_path, "rb", storage_options=storage_options, is_text=False
1357 ) as handle:
1358 stream = handle.handle
1359 stream.seek(0)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/common.py:795, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
786 handle = open(
787 handle,
788 ioargs.mode,
(...)
791 newline="",
792 )
793 else:
794 # Binary mode
--> 795 handle = open(handle, ioargs.mode)
796 handles.append(handle)
798 # Convert BytesIO or file objects passed with an encoding
FileNotFoundError: [Errno 2] No such file or directory: 'test.xlsx'
In [35]: df
Out[35]:
col1 foo bar
col2 a b a b
i1 i2
j l 1 2 3 4
k 5 6 7 8
[2 rows x 4 columns]
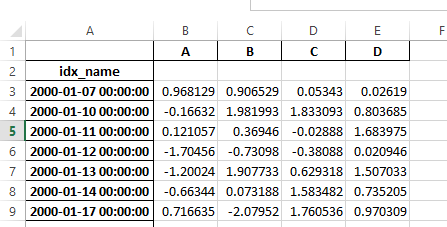
以前,有必要指定 has_index_names 中的参数 read_excel 如果序列化数据具有索引名。对于版本0.17.0,输出格式为 to_excel 已更改为不需要此关键字-更改如下所示。
Old
New
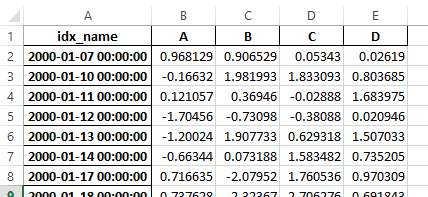
警告
保存在版本0.16.2或更早版本中且具有索引名的Excel文件仍可读入,但 has_index_names 参数必须指定为 True 。
Google BigQuery增强功能#
添加了使用自动创建表/数据集的功能
pandas.io.gbq.to_gbq()如果目标表/数据集不存在,则函数。 (GH8325 , GH11121 )。方法时替换现有表和架构的功能
pandas.io.gbq.to_gbq()函数通过if_existsargument. See the docs 获取更多详细信息 (GH8325 )。InvalidColumnOrder和InvalidPageToken在GBQ模块中将引发ValueError而不是IOError。这个
generate_bq_schema()函数现在已弃用,并将在将来的版本中删除 (GH11121 )GBQ模块现在将支持Python3 (GH11094 )。
显示与Unicode东亚宽度对齐#
警告
启用此选项将影响打印的性能 DataFrame 和 Series (速度大约慢2倍)。仅在实际需要时使用。
一些东亚国家使用Unicode字符,其宽度相当于2个字母。如果一个 DataFrame 或 Series 包含这些字符,则默认输出无法正确对齐。添加以下选项以启用对这些字符的精确处理。
display.unicode.east_asian_width:是否使用Unicode东亚宽度来计算显示文本宽度。 (GH2612 )display.unicode.ambiguous_as_wide:是否处理Unicode字符属于模棱两可的宽泛。 (GH11102 )
In [36]: df = pd.DataFrame({u"国籍": ["UK", u"日本"], u"名前": ["Alice", u"しのぶ"]})
In [37]: df
Out[37]:
国籍 名前
0 UK Alice
1 日本 しのぶ
[2 rows x 2 columns]
In [38]: pd.set_option("display.unicode.east_asian_width", True)
In [39]: df
Out[39]:
国籍 名前
0 UK Alice
1 日本 しのぶ
[2 rows x 2 columns]
有关更多详细信息,请参阅 here
其他增强功能#
支持
openpyxl>=2.2。用于样式支持的API现在是稳定的 (GH10125 )merge现在接受参数indicator它添加了一个分类类型的列(缺省情况下称为_merge)添加到接受这些值的输出对象 (GH8790 )观测原点
_merge价值仅在中合并关键字
'left'框架left_only仅在中合并关键字
'right'框架right_only合并两个帧中的关键点
bothIn [40]: df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]}) In [41]: df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]}) In [42]: pd.merge(df1, df2, on="col1", how="outer", indicator=True) Out[42]: col1 col_left col_right _merge 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only [4 rows x 4 columns]
有关更多信息,请参阅 updated docs
pd.to_numeric是一个将字符串强制转换为数字的新函数(可能带有强制) (GH11133 )pd.merge现在,如果没有合并列名,则允许使用重复的列名 (GH10639 )。pd.pivotwill now allow passing index asNone(GH3962).pd.concat现在将使用现有的系列名称(如果提供 (GH10698 )。In [43]: foo = pd.Series([1, 2], name="foo") In [44]: bar = pd.Series([1, 2]) In [45]: baz = pd.Series([4, 5])
以前的行为:
In [1]: pd.concat([foo, bar, baz], axis=1) Out[1]: 0 1 2 0 1 1 4 1 2 2 5
新行为:
In [46]: pd.concat([foo, bar, baz], axis=1) Out[46]: foo 0 1 0 1 1 4 1 2 2 5 [2 rows x 3 columns]
DataFrame已经获得了nlargest和nsmallest方法: (GH10393 )添加
limit_direction使用的关键字参数limit要启用interpolate填满NaN值向前、向后或同时向前和向后 (GH9218 , GH10420 , GH11115 )In [47]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13]) In [48]: ser.interpolate(limit=1, limit_direction="both") Out[48]: 0 NaN 1 5.0 2 5.0 3 7.0 4 NaN 5 11.0 6 13.0 Length: 7, dtype: float64
添加了一个
DataFrame.round方法将值四舍五入到可变的小数位数 (GH10568 )。In [49]: df = pd.DataFrame( ....: np.random.random([3, 3]), ....: columns=["A", "B", "C"], ....: index=["first", "second", "third"], ....: ) ....: In [50]: df Out[50]: A B C first 0.126970 0.966718 0.260476 second 0.897237 0.376750 0.336222 third 0.451376 0.840255 0.123102 [3 rows x 3 columns] In [51]: df.round(2) Out[51]: A B C first 0.13 0.97 0.26 second 0.90 0.38 0.34 third 0.45 0.84 0.12 [3 rows x 3 columns] In [52]: df.round({"A": 0, "C": 2}) Out[52]: A B C first 0.0 0.966718 0.26 second 1.0 0.376750 0.34 third 0.0 0.840255 0.12 [3 rows x 3 columns]
drop_duplicatesandduplicatednow accept akeepkeyword to target first, last, and all duplicates. Thetake_lastkeyword is deprecated, see here (GH6511, GH8505)In [53]: s = pd.Series(["A", "B", "C", "A", "B", "D"]) In [54]: s.drop_duplicates() Out[54]: 0 A 1 B 2 C 5 D Length: 4, dtype: object In [55]: s.drop_duplicates(keep="last") Out[55]: 2 C 3 A 4 B 5 D Length: 4, dtype: object In [56]: s.drop_duplicates(keep=False) Out[56]: 2 C 5 D Length: 2, dtype: object
Reindex now has a
toleranceargument that allows for finer control of 重建索引时对填充的限制 (GH10411):In [57]: df = pd.DataFrame({"x": range(5), "t": pd.date_range("2000-01-01", periods=5)}) In [58]: df.reindex([0.1, 1.9, 3.5], method="nearest", tolerance=0.2) Out[58]: x t 0.1 0.0 2000-01-01 1.9 2.0 2000-01-03 3.5 NaN NaT [3 rows x 2 columns]
当在
DatetimeIndex,TimedeltaIndex或PeriodIndex,tolerance将被迫成为一名Timedelta如果可能的话。这允许您使用字符串指定公差:In [59]: df = df.set_index("t") In [60]: df.reindex(pd.to_datetime(["1999-12-31"]), method="nearest", tolerance="1 day") Out[60]: x 1999-12-31 0 [1 rows x 1 columns]
tolerance也是被下级曝光的Index.get_indexer和Index.get_loc方法。Added functionality to use the
baseargument when resampling aTimeDeltaIndex(GH10530)DatetimeIndexcan be instantiated using strings containsNaT(GH7599)to_datetime现在可以接受yearfirst关键字 (GH7599 )pandas.tseries.offsets比Day偏移量现在可以与Series用于加/减 (GH10699 )。请参阅 docs 了解更多详细信息。pd.Timedelta.total_seconds()现在将Timedelta持续时间返回到ns精度(以前的微秒精度) (GH10939 )PeriodIndexnow supports arithmetic withnp.ndarray(GH10638)支持酸洗
Period对象 (GH10439 ).as_blocks现在将需要一个copy返回数据副本的可选参数,默认为复制(与以前的版本相比行为没有变化), (GH9607 )regexargument toDataFrame.filternow handles numeric column names instead of raisingValueError(GH10384).通过显式设置压缩参数或通过从响应中是否存在HTTP Content-Ending标头推断来启用通过URL读取gzip压缩文件 (GH8685 )
Enable serialization of lists and dicts to strings in
ExcelWriter(GH8188)SQL io函数现在接受可连接的SQLAlChemy。 (GH7877 )
pd.read_sql和to_sql可以将数据库URI接受为con参数 (GH10214 )read_sql_table现在将允许从视图中读取 (GH10750 )。启用将复数值写入
HDFStores在使用table格式化 (GH10447 )启用
pd.read_hdf当HDF文件包含单个数据集时,在不指定密钥的情况下使用 (GH10443 )pd.read_stata现在将读取Stata 118类型文件。 (GH9882 )msgpack子模块已更新到0.4.6,具有向后兼容性 (GH10581 )DataFrame.to_dict现在接受orient='index'关键字参数 (GH10844 )。DataFrame.applywill return a Series of dicts if the passed function returns a dict andreduce=True(GH8735).允许通过
kwargs到插值法 (GH10378 )。改进了串联空的可迭代对象时的错误消息
Dataframe对象 (GH9157 )pd.read_csv现在可以增量读取bz2压缩文件,C解析器可以从AWS S3读取bz2压缩文件 (GH11070 , GH11072 )。在……里面
pd.read_csv,认出s3n://和s3a://指定S3文件存储的URL (GH11070 , GH11071 )。从AWS S3以增量方式读取CSV文件,而不是先下载整个文件。(在Python2中,压缩文件仍需要下载完整文件。) (GH11070 , GH11073 )
向后不兼容的API更改#
对排序API的更改#
分类API长期以来一直存在一些不一致之处。 (GH9816 , GH8239 )。
以下是该API的摘要 PRIOR 至0.17.0:
Series.sort是 INPLACE 而当DataFrame.sort返回一个新对象。Series.order返回新对象它有可能用来
Series/DataFrame.sort_index按以下条件进行排序 值 通过传递by关键字。Series/DataFrame.sortlevel仅在一台MultiIndex用于按索引排序。
为了解决这些问题,我们修改了API:
我们介绍了一种新的方法,
DataFrame.sort_values(),这是由DataFrame.sort(),Series.sort(),以及Series.order(),以处理排序 值 。现有的方法
Series.sort(),Series.order(),以及DataFrame.sort()已被弃用,并将在未来的版本中删除。这个
by论证DataFrame.sort_index()已被弃用,并将在未来版本中删除。现有的方法
.sort_index()将获得level关键字以启用级别排序。
我们现在有两种截然不同且互不重叠的排序方法。一个 * 标记将显示 FutureWarning 。
要按 值 :
以前的 |
更换 |
|---|---|
* |
|
* |
|
* |
|
要按 索引 :
以前的 |
更换 |
|---|---|
|
|
|
|
|
|
|
|
* |
|
我们还弃用并更改了两个类似Series的类中的类似方法, Index 和 Categorical 。
以前的 |
更换 |
|---|---|
* |
|
* |
|
更改TO_DATETIME和TO_TIME增量#
错误处理#
的默认设置 pd.to_datetime 错误处理已更改为 errors='raise' 。在以前的版本中,它是 errors='ignore' 。此外, coerce 争论已被弃用,而是赞成 errors='coerce' 。这意味着将引发无效的解析,而不是像在以前的版本中那样返回原始输入。 (GH10636 )
以前的行为:
In [2]: pd.to_datetime(['2009-07-31', 'asd'])
Out[2]: array(['2009-07-31', 'asd'], dtype=object)
新行为:
In [3]: pd.to_datetime(['2009-07-31', 'asd'])
ValueError: Unknown string format
当然,你也可以强迫他们这么做。
In [61]: pd.to_datetime(["2009-07-31", "asd"], errors="coerce")
Out[61]: DatetimeIndex(['2009-07-31', 'NaT'], dtype='datetime64[ns]', freq=None)
要保持以前的行为,您可以使用 errors='ignore' :
In [62]: pd.to_datetime(["2009-07-31", "asd"], errors="ignore")
Out[62]: Index(['2009-07-31', 'asd'], dtype='object')
此外, pd.to_timedelta 已经获得了类似的API, errors='raise'|'ignore'|'coerce' ,以及 coerce 关键字已被弃用,转而支持 errors='coerce' 。
一致的解析#
的字符串解析 to_datetime , Timestamp 和 DatetimeIndex 都是一致的。 (GH7599 )
在v0.17.0之前, Timestamp 和 to_datetime 可能会使用今天的日期错误地分析仅限年份的日期时间字符串,否则为 DatetimeIndex 使用年初。 Timestamp 和 to_datetime 可能会提高 ValueError 在某些类型的日期时间字符串中, DatetimeIndex 可以解析,如季度字符串。
以前的行为:
In [1]: pd.Timestamp('2012Q2')
Traceback
...
ValueError: Unable to parse 2012Q2
# Results in today's date.
In [2]: pd.Timestamp('2014')
Out [2]: 2014-08-12 00:00:00
V0.17.0可以按如下方式解析它们。它的工作原理是 DatetimeIndex 还有.。
新行为:
In [63]: pd.Timestamp("2012Q2")
Out[63]: Timestamp('2012-04-01 00:00:00')
In [64]: pd.Timestamp("2014")
Out[64]: Timestamp('2014-01-01 00:00:00')
In [65]: pd.DatetimeIndex(["2012Q2", "2014"])
Out[65]: DatetimeIndex(['2012-04-01', '2014-01-01'], dtype='datetime64[ns]', freq=None)
备注
如果要根据今天的日期执行计算,请使用 Timestamp.now() 和 pandas.tseries.offsets 。
In [66]: import pandas.tseries.offsets as offsets
In [67]: pd.Timestamp.now()
Out[67]: Timestamp('2022-05-08 15:40:50.384965')
In [68]: pd.Timestamp.now() + offsets.DateOffset(years=1)
Out[68]: Timestamp('2023-05-08 15:40:50.385542')
对指数比较的更改#
Operator equal on Index should behavior similarly to Series (GH9947, GH10637)
从v0.17.0开始,比较 Index 不同长度的对象将引发 ValueError 。这与……的行为一致 Series 。
以前的行为:
In [2]: pd.Index([1, 2, 3]) == pd.Index([1, 4, 5])
Out[2]: array([ True, False, False], dtype=bool)
In [3]: pd.Index([1, 2, 3]) == pd.Index([2])
Out[3]: array([False, True, False], dtype=bool)
In [4]: pd.Index([1, 2, 3]) == pd.Index([1, 2])
Out[4]: False
新行为:
In [8]: pd.Index([1, 2, 3]) == pd.Index([1, 4, 5])
Out[8]: array([ True, False, False], dtype=bool)
In [9]: pd.Index([1, 2, 3]) == pd.Index([2])
ValueError: Lengths must match to compare
In [10]: pd.Index([1, 2, 3]) == pd.Index([1, 2])
ValueError: Lengths must match to compare
请注意,这不同于 numpy 可以广播比较的行为:
In [69]: np.array([1, 2, 3]) == np.array([1])
Out[69]: array([ True, False, False])
或者,如果无法播放,则返回FALSE:
In [70]: np.array([1, 2, 3]) == np.array([1, 2])
Out[70]: False
布尔比较与无比较的更改#
的布尔比较 Series VS None 现在将等同于与 np.nan ,而不是提高 TypeError 。 (GH1079 )。
In [71]: s = pd.Series(range(3))
In [72]: s.iloc[1] = None
In [73]: s
Out[73]:
0 0.0
1 NaN
2 2.0
Length: 3, dtype: float64
以前的行为:
In [5]: s == None
TypeError: Could not compare <type 'NoneType'> type with Series
新行为:
In [74]: s == None
Out[74]:
0 False
1 False
2 False
Length: 3, dtype: bool
通常,您只想知道哪些值为空。
In [75]: s.isnull()
Out[75]:
0 False
1 True
2 False
Length: 3, dtype: bool
警告
您通常会想要使用 isnull/notnull 对于这些类型的比较,如 isnull/notnull 告诉您哪些元素为空。人们必须注意到 nan's 不是平等的比较,但是 None's 做。请注意,Pandas/Numpy使用的事实是 np.nan != np.nan ,并招待 None 喜欢 np.nan 。
In [76]: None == None
Out[76]: True
In [77]: np.nan == np.nan
Out[77]: False
HDFStore Dropna行为#
HDFStore写入函数的默认行为为 format='table' 现在是保留所有缺失的行。以前,行为是删除所有缺少SAVE索引的行。之前的行为可以使用 dropna=True 选项。 (GH9382 )
以前的行为:
In [78]: df_with_missing = pd.DataFrame(
....: {"col1": [0, np.nan, 2], "col2": [1, np.nan, np.nan]}
....: )
....:
In [79]: df_with_missing
Out[79]:
col1 col2
0 0.0 1.0
1 NaN NaN
2 2.0 NaN
[3 rows x 2 columns]
In [27]:
df_with_missing.to_hdf('file.h5',
'df_with_missing',
format='table',
mode='w')
In [28]: pd.read_hdf('file.h5', 'df_with_missing')
Out [28]:
col1 col2
0 0 1
2 2 NaN
新行为:
In [80]: df_with_missing.to_hdf("file.h5", "df_with_missing", format="table", mode="w")
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/compat/_optional.py:139, in import_optional_dependency(name, extra, errors, min_version)
138 try:
--> 139 module = importlib.import_module(name)
140 except ImportError:
File /usr/lib/python3.10/importlib/__init__.py:126, in import_module(name, package)
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
File <frozen importlib._bootstrap>:1050, in _gcd_import(name, package, level)
File <frozen importlib._bootstrap>:1027, in _find_and_load(name, import_)
File <frozen importlib._bootstrap>:1004, in _find_and_load_unlocked(name, import_)
ModuleNotFoundError: No module named 'tables'
During handling of the above exception, another exception occurred:
ImportError Traceback (most recent call last)
Input In [80], in <cell line: 1>()
----> 1 df_with_missing.to_hdf("file.h5", "df_with_missing", format="table", mode="w")
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/core/generic.py:2655, in NDFrame.to_hdf(self, path_or_buf, key, mode, complevel, complib, append, format, index, min_itemsize, nan_rep, dropna, data_columns, errors, encoding)
2651 from pandas.io import pytables
2653 # Argument 3 to "to_hdf" has incompatible type "NDFrame"; expected
2654 # "Union[DataFrame, Series]" [arg-type]
-> 2655 pytables.to_hdf(
2656 path_or_buf,
2657 key,
2658 self, # type: ignore[arg-type]
2659 mode=mode,
2660 complevel=complevel,
2661 complib=complib,
2662 append=append,
2663 format=format,
2664 index=index,
2665 min_itemsize=min_itemsize,
2666 nan_rep=nan_rep,
2667 dropna=dropna,
2668 data_columns=data_columns,
2669 errors=errors,
2670 encoding=encoding,
2671 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/pytables.py:312, in to_hdf(path_or_buf, key, value, mode, complevel, complib, append, format, index, min_itemsize, nan_rep, dropna, data_columns, errors, encoding)
310 path_or_buf = stringify_path(path_or_buf)
311 if isinstance(path_or_buf, str):
--> 312 with HDFStore(
313 path_or_buf, mode=mode, complevel=complevel, complib=complib
314 ) as store:
315 f(store)
316 else:
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/pytables.py:573, in HDFStore.__init__(self, path, mode, complevel, complib, fletcher32, **kwargs)
570 if "format" in kwargs:
571 raise ValueError("format is not a defined argument for HDFStore")
--> 573 tables = import_optional_dependency("tables")
575 if complib is not None and complib not in tables.filters.all_complibs:
576 raise ValueError(
577 f"complib only supports {tables.filters.all_complibs} compression."
578 )
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/compat/_optional.py:142, in import_optional_dependency(name, extra, errors, min_version)
140 except ImportError:
141 if errors == "raise":
--> 142 raise ImportError(msg)
143 else:
144 return None
ImportError: Missing optional dependency 'pytables'. Use pip or conda to install pytables.
In [81]: pd.read_hdf("file.h5", "df_with_missing")
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Input In [81], in <cell line: 1>()
----> 1 pd.read_hdf("file.h5", "df_with_missing")
File /usr/local/lib/python3.10/dist-packages/pandas-1.5.0.dev0+697.gf9762d8f52-py3.10-linux-x86_64.egg/pandas/io/pytables.py:428, in read_hdf(path_or_buf, key, mode, errors, where, start, stop, columns, iterator, chunksize, **kwargs)
425 exists = False
427 if not exists:
--> 428 raise FileNotFoundError(f"File {path_or_buf} does not exist")
430 store = HDFStore(path_or_buf, mode=mode, errors=errors, **kwargs)
431 # can't auto open/close if we are using an iterator
432 # so delegate to the iterator
FileNotFoundError: File file.h5 does not exist
请参阅 docs 了解更多详细信息。
更改为 display.precision 选项#
这个 display.precision 选项已澄清为引用小数位 (GH10451 )。
早期版本的Pandas会将浮点数的格式设置为比中的值少一个小数位 display.precision 。
In [1]: pd.set_option('display.precision', 2)
In [2]: pd.DataFrame({'x': [123.456789]})
Out[2]:
x
0 123.5
如果将精度解释为“有意义的数字”,这对科学记数法确实有效,但同样的解释不适用于标准格式的值。它与NumPy处理格式的方式也不同步。
展望未来, display.precision 将直接控制小数点后的位数,用于常规格式以及科学记数法,类似于Numpy的 precision 打印选项起作用。
In [82]: pd.set_option("display.precision", 2)
In [83]: pd.DataFrame({"x": [123.456789]})
Out[83]:
x
0 123.46
[1 rows x 1 columns]
要保留与以前版本的输出行为,请使用 display.precision 已经减少到 6 从… 7 。
更改为 Categorical.unique#
Categorical.unique now returns new Categoricals with categories and codes that are unique, rather than returning np.array (GH10508)
无序类别:值和类别按外观顺序排序。
有序类别:值按外观顺序排序,类别保持现有顺序。
In [84]: cat = pd.Categorical(["C", "A", "B", "C"], categories=["A", "B", "C"], ordered=True)
In [85]: cat
Out[85]:
['C', 'A', 'B', 'C']
Categories (3, object): ['A' < 'B' < 'C']
In [86]: cat.unique()
Out[86]:
['C', 'A', 'B']
Categories (3, object): ['A' < 'B' < 'C']
In [87]: cat = pd.Categorical(["C", "A", "B", "C"], categories=["A", "B", "C"])
In [88]: cat
Out[88]:
['C', 'A', 'B', 'C']
Categories (3, object): ['A', 'B', 'C']
In [89]: cat.unique()
Out[89]:
['C', 'A', 'B']
Categories (3, object): ['A', 'B', 'C']
更改为 bool 被认为是 header 在解析器中#
In earlier versions of pandas, if a bool was passed the header argument of
read_csv, read_excel, or read_html it was implicitly converted to
an integer, resulting in header=0 for False and header=1 for True
(GH6113)
A bool 输入到 header 现在将引发一个 TypeError
In [29]: df = pd.read_csv('data.csv', header=False)
TypeError: Passing a bool to header is invalid. Use header=None for no header or
header=int or list-like of ints to specify the row(s) making up the column names
其他API更改#
线条和KDE图与
subplots=True现在使用默认颜色,不是全部为黑色。指定color='k'用黑色绘制所有线条的步骤 (GH9894 )Calling the
.value_counts()method on a Series with acategoricaldtype now returns a Series with aCategoricalIndex(GH10704)现在将序列化Pandas对象的子类的元数据属性 (GH10553 )。
groupby使用Categorical遵循与以下相同的规则Categorical.unique上文所述 (GH10508 )在施工时
DataFrame具有一组complex64DTYPE以前表示相应的列自动升级到complex128数据类型。Pandas现在将保留复杂数据的输入项大小 (GH10952 )某些数值约简运算符将返回
ValueError,而不是TypeError关于包括字符串和数字的对象类型 (GH11131 )Passing currently unsupported
chunksizeargument toread_excelorExcelFile.parsewill now raiseNotImplementedError(GH8011)Allow an
ExcelFileobject to be passed intoread_excel(GH11198)DatetimeIndex.uniondoes not inferfreqifselfand the input haveNoneasfreq(GH11086)NaT's methods now either raiseValueError, or returnnp.nanorNaT(GH9513)行为
方法:
返回
np.nanweekday,isoweekday返回
NaTdate,now,replace,to_datetime,today返回
np.datetime64('NaT')to_datetime64(不变)加薪
ValueError所有其他公共方法(名称不以下划线开头)
不推荐使用#
为
Series以下索引函数已弃用 (GH10177 )。不推荐使用的函数
更换
.irow(i).iloc[i]or.iat[i].iget(i).iloc[i]or.iat[i].iget_value(i).iloc[i]or.iat[i]为
DataFrame以下索引函数已弃用 (GH10177 )。不推荐使用的函数
更换
.irow(i).iloc[i].iget_value(i, j).iloc[i, j]or.iat[i, j].icol(j).iloc[:, j]
备注
自0.11.0起,文档中已弃用这些索引函数。
Categorical.name已被弃用来制作Categorical更多numpy.ndarray喜欢。使用Series(cat, name="whatever")取而代之的是 (GH10482 )。中设置缺失值(NaN)
Categorical%scategories将发出警告 (GH10748 )。中仍然可以有缺失值。values。drop_duplicates和duplicated%stake_last关键字已弃用,取而代之keep。 (GH6511 , GH8505 )Series.nsmallest和nlargest%stake_last关键字已弃用,取而代之keep。 (GH10792 )DataFrame.combineAddandDataFrame.combineMultare deprecated. They can easily be replaced by using theaddandmulmethods:DataFrame.add(other, fill_value=0)andDataFrame.mul(other, fill_value=1.)(GH10735).TimeSeries不赞成,赞成Series(请注意,这是自0.13.0以来的别名), (GH10890 )SparsePanel已弃用,并将在未来版本中删除 (GH11157 )。Series.is_time_seriesdeprecated in favor ofSeries.index.is_all_dates(GH11135)传统偏移量(如
'A@JAN')已弃用(请注意,从0.8.0起这一直是别名) (GH10878 )WidePanel不赞成,赞成Panel,LongPanel赞成DataFrame(请注意,这些是从<0.11.0开始的别名), (GH10892 )DataFrame.convert_objects已被弃用,取而代之的是特定于类型的函数pd.to_datetime,pd.to_timestamp和pd.to_numeric(0.17.0中的新功能) (GH11133 )。
删除先前版本的弃用/更改#
删除
na_last参数来自Series.order()和Series.sort(),支持na_position。 (GH5231 )删除
percentile_width从….describe(),支持percentiles。 (GH7088 )删除
colSpace参数来自DataFrame.to_string(),支持col_space,约为0.8.0版。取消自动时间序列广播 (GH2304 )
In [90]: np.random.seed(1234) In [91]: df = pd.DataFrame( ....: np.random.randn(5, 2), ....: columns=list("AB"), ....: index=pd.date_range("2013-01-01", periods=5), ....: ) ....: In [92]: df Out[92]: A B 2013-01-01 0.471435 -1.190976 2013-01-02 1.432707 -0.312652 2013-01-03 -0.720589 0.887163 2013-01-04 0.859588 -0.636524 2013-01-05 0.015696 -2.242685 [5 rows x 2 columns]
先前
In [3]: df + df.A FutureWarning: TimeSeries broadcasting along DataFrame index by default is deprecated. Please use DataFrame.<op> to explicitly broadcast arithmetic operations along the index Out[3]: A B 2013-01-01 0.942870 -0.719541 2013-01-02 2.865414 1.120055 2013-01-03 -1.441177 0.166574 2013-01-04 1.719177 0.223065 2013-01-05 0.031393 -2.226989
当前
In [93]: df.add(df.A, axis="index") Out[93]: A B 2013-01-01 0.942870 -0.719541 2013-01-02 2.865414 1.120055 2013-01-03 -1.441177 0.166574 2013-01-04 1.719177 0.223065 2013-01-05 0.031393 -2.226989 [5 rows x 2 columns]
Remove
tablekeyword inHDFStore.put/append, in favor of usingformat=(GH4645)删除
kind在……里面read_excel/ExcelFile因为它没有被使用过 (GH4712 )删除
infer_type关键字来源pd.read_html因为它没有被使用过 (GH4770 , GH7032 )Remove
offsetandtimeRulekeywords fromSeries.tshift/shift, in favor offreq(GH4853, GH4864)Remove
pd.load/pd.savealiases in favor ofpd.to_pickle/pd.read_pickle(GH3787)
性能改进#
Development support for benchmarking with the Air Speed Velocity library (GH8361)
添加了用于替代ExcelWriter引擎和读取Excel文件的vbench基准测试 (GH7171 )
Performance improvements in
Categorical.value_counts(GH10804)Performance improvements in
SeriesGroupBy.nuniqueandSeriesGroupBy.value_countsandSeriesGroupby.transform(GH10820, GH11077)在以下方面的性能改进
DataFrame.drop_duplicates使用整型数据类型 (GH10917 )在以下方面的性能改进
DataFrame.duplicated有着宽大的框架。 (GH10161 , GH11180 )性能提高8倍
timedelta64和datetime64奥普斯 (GH6755 )显著提高了索引性能
MultiIndex使用切片机 (GH10287 )性能提高8倍
iloc使用类似列表的输入 (GH10791 )改进的性能
Series.isin对于类日期时间/整数系列 (GH10287 )性能提高20倍
concat当类别相同时的范畴 (GH10587 )改进的性能
to_datetime指定的格式字符串为ISO8601时 (GH10178 )将性能提高2倍
Series.value_counts对于浮点数据类型 (GH10821 )启用
infer_datetime_format在……里面to_datetime当日期组件没有0填充时 (GH11142 )在构建过程中从0.16.1回归
DataFrame来自嵌套词典 (GH11084 )Performance improvements in addition/subtraction operations for
DateOffsetwithSeriesorDatetimeIndex(GH10744, GH11205)
错误修复#
错误计算中的错误
.mean()在……上面timedelta64[ns]由于溢流 (GH9442 )窃听
.isin上了年纪的麻瓜 (GH11232 )窃听
DataFrame.to_html(index=False)使之成为不必要的name划 (GH10344 )窃听
DataFrame.to_latex()这个column_format无法传递参数 (GH9402 )Bug in
DatetimeIndexwhen localizing withNaT(GH10477)窃听
Series.dt保存元数据的操作 (GH10477 )保存中的错误
NaT当传入一个否则无效的to_datetime施工 (GH10477 )窃听
DataFrame.apply当函数返回分类序列时。 (GH9573 )窃听
to_datetime提供的日期和格式无效 (GH10154 )窃听
Index.drop_duplicates正在删除名称 (GH10115 )窃听
Series.quantile正在删除名称 (GH10881 )窃听
pd.Series当在空的Series它的指数是有频率的。 (GH10193 )窃听
pd.Series.interpolate带有无效的order关键字值。 (GH10633 )窃听
DataFrame.plot加薪ValueError当颜色名称由多个字符指定时 (GH10387 )窃听
Index使用混合元组列表进行构造 (GH10697 )窃听
DataFrame.reset_index当索引包含NaT。 (GH10388 )窃听
ExcelReader当工作表为空时 (GH6403 )窃听
BinGrouper.group_info其中返回值与基类不兼容 (GH10914 )清除上的缓存时出现错误
DataFrame.pop以及随后的原地行动 (GH10912 )Bug in indexing with a mixed-integer
Indexcausing anImportError(GH10610)窃听
Series.count当索引有空值时 (GH10946 )Bug in pickling of a non-regular freq
DatetimeIndex(GH11002)错误导致
DataFrame.where不尊重axis当框架具有对称形状时,使用。 (GH9736 )窃听
Table.select_column未保留名称的位置 (GH10392 )Bug in
offsets.generate_rangewherestartandendhave finer precision thanoffset(GH9907)窃听
pd.rolling_*哪里Series.name将在输出中丢失 (GH10565 )窃听
stack当索引或列不唯一时。 (GH10417 )设置中的错误
Panel当轴具有多重索引时 (GH10360 )窃听
USFederalHolidayCalendar哪里USMemorialDay和USMartinLutherKingJr是不正确的 (GH10278 和 GH9760 )Bug in
.sample()where returned object, if set, gives unnecessarySettingWithCopyWarning(GH10738)窃听
.sample()其中权重传递为Series在位置处理之前没有沿轴对齐,如果权重指数与采样对象不对齐,可能会导致问题。 (GH10738 )回归已修复 (GH9311 , GH6620 , GH9345 ),其中使用类似DateTime的Groupby转换为带有某些聚合器的浮点型 (GH10979 )
Bug in
DataFrame.interpolatewithaxis=1andinplace=True(GH10395)窃听
io.sql.get_schema将多列指定为主键时 (GH10385 )。Bug in
groupby(sort=False)with datetime-likeCategoricalraisesValueError(GH10505)Bug in
groupby(axis=1)withfilter()throwsIndexError(GH11041)窃听
test_categorical关于大端构建 (GH10425 )窃听
Series.shift和DataFrame.shift不支持分类数据 (GH9416 )Bug in
Series.mapusing categoricalSeriesraisesAttributeError(GH10324)Bug in
MultiIndex.get_level_valuesincludingCategoricalraisesAttributeError(GH10460)Bug in
pd.get_dummieswithsparse=Truenot returningSparseDataFrame(GH10531)窃听
Index子类型(如PeriodIndex)不返回其自己的类型.drop和.insert方法: (GH10620 )窃听
algos.outer_join_indexer什么时候right数组为空 (GH10618 )窃听
filter(从0.16.0回归)和transform在对多个键进行分组时,其中一个类似DateTime (GH10114 )窃听
to_datetime和to_timedelta引起Index将丢失的名称 (GH10875 )窃听
len(DataFrame.groupby)引起IndexError当有一列只包含NaN时 (GH11016 )重新采样空系列时导致段错误的错误 (GH10228 )
窃听
DatetimeIndex和PeriodIndex.value_counts重置其结果中的名称,但保留在结果中Index。 (GH10150 )窃听
pd.eval使用numexpr引擎将1个元素的数值数组强制为标量 (GH10546 )Bug in
pd.concatwithaxis=0when column is of dtypecategory(GH10177)Bug in
pd.read_csvwith kwargsindex_col=False,index_col=['a', 'b']ordtype(GH10413, GH10467, GH10577)Bug in
Series.from_csvwithheaderkwarg not setting theSeries.nameor theSeries.index.name(GH10483)窃听
groupby.var这导致对于较小的浮点值,方差不准确 (GH10448 )窃听
Series.plot(kind='hist')Y标签不提供信息 (GH10485 )窃听
read_csv当使用生成uint8类型 (GH9266 )BUG导致时间序列直线和面积图中的内存泄漏 (GH9003 )
Bug when setting a
Panelsliced along the major or minor axes when the right-hand side is aDataFrame(GH11014)返回的错误
None并且不会引发NotImplementedError当操作员功能(例如.add)的Panel都没有实现 (GH7692 )Bug in line and kde plot cannot accept multiple colors when
subplots=True(GH9894)窃听
DataFrame.plot加薪ValueError当颜色名称由多个字符指定时 (GH10387 )左侧和右侧的错误
align的Series使用MultiIndex可能是倒置的 (GH10665 )左侧和右侧的错误
join具有的MultiIndex可能是倒置的 (GH10741 )Bug in
read_statawhen reading a file with a different order set incolumns(GH10757)Bug in
Categoricalmay not representing properly when category containstzorPeriod(GH10713)Bug in
Categorical.__iter__may not returning correctdatetimeandPeriod(GH10713)Bug in indexing with a
PeriodIndexon an object with aPeriodIndex(GH4125)窃听
read_csv使用engine='c':未正确处理前面有注释、空行等的EOF (GH10728 , GH10548 )通过读取“Famafrch”数据
DataReader由于网站URL已更改而导致HTTP404错误 (GH10591 )。窃听
read_msgpack其中要解码的DataFrame具有重复的列名 (GH9618 )窃听
io.common.get_filepath_or_buffer如果存储桶还包含用户没有读取权限的密钥,这会导致读取有效的S3文件失败 (GH10604 )Bug in vectorised setting of timestamp columns with python
datetime.dateand numpydatetime64(GH10408, GH10412)窃听
Index.take可能会添加不必要的内容freq属性 (GH10791 )Bug in
mergewith emptyDataFramemay raiseIndexError(GH10824)窃听
to_latex某些文档参数的WHERE意外关键字参数 (GH10888 )索引大型数据库时出错
DataFrame哪里IndexError没有被抓住 (GH10645 和 GH10692 )窃听
read_csv在使用nrows或chunksize如果文件仅包含标题行,则为参数 (GH9535 )序列化中的错误
category在存在替代编码的情况下使用HDF5中的类型。 (GH10366 )窃听
pd.DataFrame使用字符串dtype构造空DataFrame时 (GH9428 )窃听
pd.DataFrame.diff当DataFrame未整合时 (GH10907 )窃听
pd.unique对于具有datetime64或timedelta64Dtype,表示返回具有对象dtype的数组,而不是返回原始dtype (GH9431 )窃听
Timedelta从0开始切片时引发错误 (GH10583 )窃听
DatetimeIndex.take和TimedeltaIndex.take不能举起IndexError针对无效索引 (GH10295 )Bug in
Series([np.nan]).astype('M8[ms]'), which now returnsSeries([pd.NaT])(GH10747)窃听
PeriodIndex.order重置频率 (GH10295 )窃听
date_range什么时候freq分割end作为Nanos (GH10885 )窃听
iloc允许使用负整数访问超出系列界限的内存 (GH10779 )窃听
read_msgpack不尊重编码的情况下 (GH10581 )Bug in
TimedeltaIndexformatter causing error while trying to saveDataFramewithTimedeltaIndexusingto_csv(GH10833)BUG在哪里
pd.read_gbq投掷ValueError当BigQuery返回零行时 (GH10273 )窃听
to_json在序列化0级ndarray时导致分段错误 (GH9576 )Bug in plotting functions may raise
IndexErrorwhen plotted onGridSpec(GH10819)绘图结果中的错误可能会显示不必要的次要标记标签 (GH10657 )
窃听
groupby上的聚合计算不正确DataFrame使用NaT(例如first,last,min)。 (GH10590 , GH11010 )构造时出现BUG
DataFrame其中,传递仅具有标量值的字典并指定列不会引发错误 (GH10856 )窃听
.var()导致高度相似值的舍入误差 (GH10242 )窃听
DataFrame.plot(subplots=True)具有重复列的输出结果不正确 (GH10962 )窃听
Index算术可能会导致错误的类 (GH10638 )窃听
date_range如果年度、季度和每月频率为负值,则结果为空 (GH11018 )窃听
DatetimeIndex无法推断负频率 (GH11018 )删除一些不推荐使用的比较操作,主要是在测试中。 (GH10569 )
窃听
Index数据类型可能未正确应用 (GH11017 )窃听
io.gbq测试最低Google API客户端版本时 (GH10652 )窃听
DataFrame从嵌套构造dict使用timedelta钥匙 (GH11129 )窃听
.fillna反对阿美募集TypeError当数据包含DateTime数据类型时 (GH7095 , GH11153 )窃听
.groupby当分组依据的键数与索引长度相同时 (GH11185 )Bug in
convert_objectswhere converted values might not be returned if all null andcoerce(GH9589)窃听
convert_objects哪里copy未遵守关键字 (GH9589 )
贡献者#
共有112人为此次发布贡献了补丁。名字中带有“+”的人第一次贡献了一个补丁。
Alex Rothberg
Andrea Bedini +
Andrew Rosenfeld
Andy Hayden
Andy Li +
Anthonios Partheniou +
Artemy Kolchinsky
Bernard Willers
Charlie Clark +
Chris +
Chris Whelan
Christoph Gohlke +
Christopher Whelan
Clark Fitzgerald
Clearfield Christopher +
Dan Ringwalt +
Daniel Ni +
Data & Code Expert Experimenting with Code on Data +
David Cottrell
David John Gagne +
David Kelly +
ETF +
Eduardo Schettino +
Egor +
Egor Panfilov +
Evan Wright
Frank Pinter +
Gabriel Araujo +
Garrett-R
Gianluca Rossi +
Guillaume Gay
Guillaume Poulin
Harsh Nisar +
Ian Henriksen +
Ian Hoegen +
Jaidev Deshpande +
Jan Rudolph +
Jan Schulz
Jason Swails +
Jeff Reback
Jonas Buyl +
Joris Van den Bossche
Joris Vankerschaver +
Josh Levy-Kramer +
Julien Danjou
Ka Wo Chen
Karrie Kehoe +
Kelsey Jordahl
Kerby Shedden
Kevin Sheppard
Lars Buitinck
Leif Johnson +
Luis Ortiz +
Mac +
Matt Gambogi +
Matt Savoie +
Matthew Gilbert +
Maximilian Roos +
Michelangelo D'Agostino +
Mortada Mehyar
Nick Eubank
Nipun Batra
Ondřej Čertík
Phillip Cloud
Pratap Vardhan +
Rafal Skolasinski +
Richard Lewis +
Rinoc Johnson +
Rob Levy
Robert Gieseke
Safia Abdalla +
Samuel Denny +
Saumitra Shahapure +
Sebastian Pölsterl +
Sebastian Rubbert +
Sheppard, Kevin +
Sinhrks
Siu Kwan Lam +
Skipper Seabold
Spencer Carrucciu +
Stephan Hoyer
Stephen Hoover +
Stephen Pascoe +
Terry Santegoeds +
Thomas Grainger
Tjerk Santegoeds +
Tom Augspurger
Vincent Davis +
Winterflower +
Yaroslav Halchenko
Yuan Tang (Terry) +
agijsberts
ajcr +
behzad nouri
cel4
chris-b1 +
cyrusmaher +
davidovitch +
ganego +
jreback
juricast +
larvian +
maximilianr +
msund +
rekcahpassyla
robertzk +
scls19fr
seth-p
sinhrks
springcoil +
terrytangyuan +
tzinckgraf +