使用融合进行聚集#
空间数据通常比我们需要的更细粒度。例如,我们可能有关于国家以下单位的数据,但我们实际上对研究国家一级的模式感兴趣。
在非空间环境中,当我们只需要数据的汇总统计信息时,我们使用 groupby() 功能。但对于空间数据,有时还需要聚合几何特征。在 地貌熊猫 库中,我们可以使用 dissolve() 功能。
dissolve() can be thought of as doing three things:
它将给定组内的所有几何融合到单个几何要素中(使用
unary_union方法),以及它使用以下命令聚合组中的所有数据行 groupby.aggregate ,以及
它结合了这两个结果。
dissolve() 示例#
假设我们对研究大陆感兴趣,但我们只有国家级别的数据,如 地貌熊猫 。我们可以很容易地将其转换为大陆级别的数据集。
首先,让我们看看最简单的情况,我们只需要大陆的形状和名称。默认情况下, dissolve() 会过去的 'first' 至 groupby.aggregate 。
In [1]: world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
In [2]: world = world[['continent', 'geometry']]
In [3]: continents = world.dissolve(by='continent')
In [4]: continents.plot();
In [5]: continents.head()
Out[5]:
geometry
continent
Africa MULTIPOLYGON (((-11.43878 6.78592, -11.70819 6...
Antarctica MULTIPOLYGON (((-61.13898 -79.98137, -60.61012...
Asia MULTIPOLYGON (((48.67923 14.00320, 48.23895 13...
Europe MULTIPOLYGON (((-53.55484 2.33490, -53.77852 2...
North America MULTIPOLYGON (((-155.22217 19.23972, -155.5421...
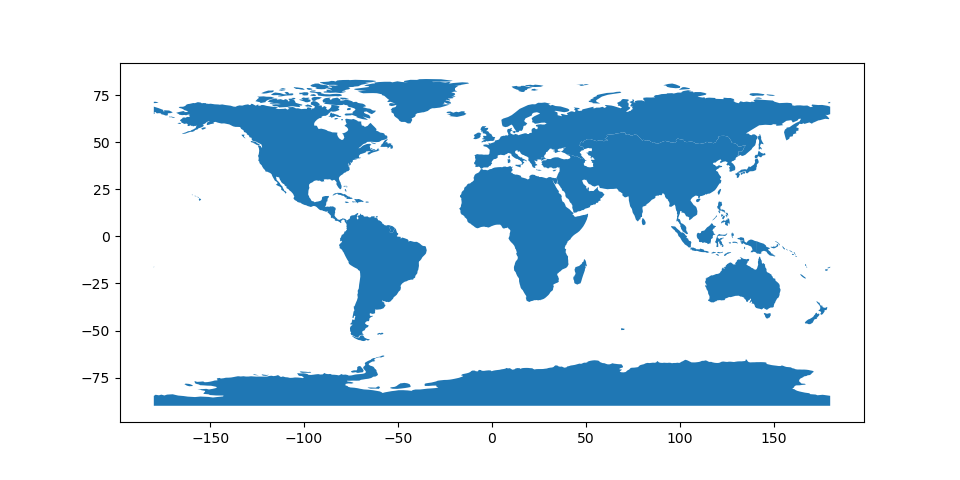
但是,如果我们对总人口感兴趣,我们可以将不同的函数传递给 dissolve() 方法来聚合种群。 aggfunc = 论点:
In [6]: world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
In [7]: world = world[['continent', 'geometry', 'pop_est']]
In [8]: continents = world.dissolve(by='continent', aggfunc='sum')
In [9]: continents.plot(column = 'pop_est', scheme='quantiles', cmap='YlOrRd');
In [10]: continents.head()
Out[10]:
geometry pop_est
continent
Africa MULTIPOLYGON (((-11.43878 6.78592, -11.70819 6... 1219176238
Antarctica MULTIPOLYGON (((-61.13898 -79.98137, -60.61012... 4050
Asia MULTIPOLYGON (((48.67923 14.00320, 48.23895 13... 4389144868
Europe MULTIPOLYGON (((-53.55484 2.33490, -53.77852 2... 746398461
North America MULTIPOLYGON (((-155.22217 19.23972, -155.5421... 573042112
化解争论#
这个 aggfunc = 参数默认为‘First’,这意味着在Dissolve例程中找到的第一行属性值将被分配给结果已分解的Geodataframe。但是,它还接受允许的其他汇总统计信息选项 pandas.groupby 包括:
“第一名”
“最后一名”
“分钟”
“最大”
“总和”
“卑鄙”
“中位数”
功能
字符串函数名
函数和/或函数名称列表,例如 [Np.sum,“Mean”]
轴标签的字典->函数、函数名称或此类列表。
例如,要获得每个大陆上的城市数量,以及每个大陆最大和最小国家的人口,我们可以将 'name' 列使用 'count' ,以及 'pop_est' 列使用 'min' 和 'max' :
In [11]: world = geopandas.read_file(geopandas.datasets.get_path("naturalearth_lowres"))
In [12]: continents = world.dissolve(
....: by="continent",
....: aggfunc={
....: "name": "count",
....: "pop_est": ["min", "max"],
....: },
....: )
....: