27.1.21. 向量表
27.1.21.1. 添加自动增量字段
向矢量图层添加一个新的整型字段,每个要素都有一个顺序值。
此字段可用作图层中要素的唯一ID。新属性不会添加到输入层,而是会生成一个新层。
可以指定增量序列的初始起始值。或者,增量序列可以基于分组字段,也可以指定要素的排序顺序。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层。 |
Field name |
|
[string] 默认值:‘AUTO’ |
具有自动增量值的字段的名称 |
Start values at 任选 |
|
[number] 默认:0 |
选择增量计数的初始数量 |
Modulus value 任选 |
|
[number] 默认:0 |
指定一个可选的模数值将在该字段值达到模数值时重新开始计数。 |
Group values by 任选 |
|
[tablefield: any] [list] |
选择分组字段(S):对这些字段组合返回的每个值进行单独计数,而不是对整个层执行一次计数。 |
Sort expression 任选 |
|
[expression] |
使用表达式对图层中的要素进行全局排序或基于编组字段(如果设置)进行排序。 |
Sort ascending |
|
[boolean] 默认值:True |
当一个 |
Sort nulls first |
|
[boolean] 默认:FALSE |
当一个 |
Incremented |
|
[same as input] 默认: |
使用自动增量字段指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Incremented |
|
[same as input] |
具有自动增量场的矢量层 |
Python代码
Algorithm ID : native:addautoincrementalfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.2. 向属性表添加字段
将新场添加到矢量层。
属性的名称和特征被定义为参数。
新属性不会添加到输入层,而是会生成一个新层。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入层 |
Field name |
|
[string] |
新字段的名称 |
Field type |
|
[enumeration] 默认:0 |
新字段的类型。您可以在以下选项之间进行选择:
|
Field length |
|
[number] 默认:10 |
该字段的长度 |
Field precision |
|
[number] 默认:0 |
字段的精度。适用于浮点型字段类型。 |
Field alias
任选 |
|
[string] |
设置用作字段别名的名称。并非所有格式类型都支持。 |
Field comment
任选 |
|
[string] |
存储描述该字段的注释。并非所有格式类型都支持。 |
Added |
|
[same as input] 默认: |
指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Added |
|
[same as input] |
添加了新字段的矢量层 |
Python代码
Algorithm ID : native:addfieldtoattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.3. 添加唯一值索引字段
获取一个矢量层和一个属性,并添加一个新的数值字段。
此字段中的值对应于指定属性中的值,因此该属性值相同的要素将在新的数值字段中具有相同的值。
这将创建定义相同类的指定属性的数字等效项。
新属性不会添加到输入层,而是会生成一个新层。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入层。 |
Class field |
|
[tablefield: any] |
此字段具有相同值的要素将获得相同的索引。 |
Output field name |
|
[string] 默认值:‘num_field’ |
包含索引的新字段的名称。 |
Layer with index field |
|
[vector: any] 默认: |
具有包含索引的数值字段的矢量层。以下选项之一:
还可以在此处更改文件编码。 |
Class summary |
|
[table] 默认: |
指定该表以包含映射到相应唯一值的类字段的摘要。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Layer with index field |
|
[same as input] |
具有包含索引的数值字段的矢量层。 |
Class summary |
|
[table] |
具有映射到相应唯一值的类字段摘要的表。 |
Python代码
Algorithm ID : native:adduniquevalueindexfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.4. 将X/Y字段添加到层
将X和Y(或纬度/经度)字段添加到点图层。可以在与层不同的CRS中计算X/Y场(例如,为投影CRS中的层创建纬度/经度场)。
 允许 features in-place modification 点要素的数量
允许 features in-place modification 点要素的数量
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: point] |
输入层。 |
Coordinate system |
|
[crs] 默认:“EPSG:4326” |
用于生成的x和y字段的坐标参考系。 |
Field prefix 任选 |
|
[string] |
添加到新字段名以避免名称与输入层中的字段冲突的前缀。 |
Added fields |
|
[vector: point] 默认: |
指定输出层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Added fields |
|
[vector: point] |
输出层-与输入层相同,但具有两个新的双字段, |
Python代码
Algorithm ID : native:addxyfieldstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.5. 高级Python域计算器
将新属性添加到矢量层,其值是通过将表达式应用于每个要素而产生的。
该表达式被定义为一个Python函数。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层 |
Result field name |
|
[string] 默认:‘Newfield’ |
新字段的名称 |
Field type |
|
[enumeration] 默认:0 |
新字段的类型。以下选项之一:
|
Field length |
|
[number] 默认:10 |
该字段的长度 |
Field precision |
|
[number] 默认:3 |
字段的精度。适用于浮点型字段类型。 |
Global expression 任选 |
|
[string] |
在计算器开始迭代输入层的所有要素之前,全局表达式部分中的代码将只执行一次。因此,这是导入必要的模块或计算将在后续计算中使用的变量的正确位置。 |
Formula |
|
[string] |
要计算的Python公式。示例:要计算输入多边形层的面积,可以添加: value = $geom.area()
|
Calculated |
|
[same as input] 默认: |
使用新的计算字段指定矢量图层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Calculated |
|
[same as input] |
具有新计算字段的矢量图层 |
Python代码
Algorithm ID : qgis:advancedpythonfieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.6. 空投场(S)
获取一个矢量层并生成一个新的层,该层具有相同的功能,但没有选定的列。
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
要从中删除字段(S)的输入矢量图层 |
Fields to drop |
|
[tablefield: any] [list] |
场上(S)要降下来 |
Remaining fields |
|
[same as input] 默认: |
使用其余字段指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Remaining fields |
|
[same as input] |
包含剩余字段的矢量图层 |
Python代码
Algorithm ID : native:deletecolumn
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.7. 分解HStore字段
创建输入层的副本,并为HStore字段中的每个唯一键添加一个新字段。
预期字段列表是可选的逗号分隔列表。如果指定此列表,则仅添加这些字段,并更新HStore字段。默认情况下,将添加所有唯一密钥。
The PostgreSQL HStore 是在PostgreSQL和GDAL中使用的简单键值存储(在读取 OSM file 与 other_tags 菲尔德。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层 |
HStore field |
|
[tablefield: any] |
场上(S)要降下来 |
Expected list of fields separated by a comma 任选 |
|
[string] 默认:‘’ |
要提取的字段的逗号分隔列表。将通过删除这些密钥来更新HStore字段。 |
Exploded |
|
[same as input] 默认: |
指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Exploded |
|
[same as input] |
输出向量层 |
Python代码
Algorithm ID : native:explodehstorefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.8. 提取二进制域
从二进制字段中提取内容,并将其保存到各个文件中。可以使用从源表中的属性获取的值或基于更复杂的表达式来生成文件名。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
包含二进制数据的输入矢量图层 |
Binary field |
|
[tablefield: any] |
包含二进制数据的字段 |
File name |
|
[expression] |
用于命名每个输出文件的基于字段或表达式的文本 |
Destination folder |
|
[folder] 默认: |
用于存储输出文件的文件夹。以下选项之一:
|
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Folder |
|
[folder] |
包含输出文件的文件夹。 |
Python代码
Algorithm ID : native:extractbinary
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.9. 现场计算器
打开字段计算器(请参见 表达式 )。您可以使用所有支持的表达式和函数。
将使用表达式的结果创建一个新层。
字段计算器在以下方面使用时非常有用 模型设计师 。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
要计算的层 |
Output field name |
|
[string] |
结果的字段的名称 |
Output field type |
|
[enumeration] 默认:0 |
该字段的类型。以下选项之一:
|
Output field width |
|
[number] 默认:10 |
结果字段的长度(最小为0) |
Field precision |
|
[number] 默认:3 |
结果字段的精度(最小0,最大15) |
Create new field |
|
[boolean] 默认值:True |
结果字段是否应为新字段 |
Formula |
|
[expression] |
用于计算结果的公式 |
Output file |
|
[vector: any] 默认: |
输出层的规范。
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Calculated |
|
[vector: any] |
包含计算出的字段值的输出图层 |
Python代码
Algorithm ID : native:fieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.10. 重构字段
允许编辑矢量层的属性表的结构。
可以使用字段映射修改字段的类型和名称。
不会修改原始层。根据提供的字段映射,生成包含修改后的属性表的新层。
备注
将模板层与一起使用时 constraints 在字段中,信息以彩色背景和工具提示显示在小部件中。在配置期间将此信息视为提示。不会在输出层上添加任何约束,算法也不会检查或强制执行这些约束。
重构字段算法允许:
更改字段名称和类型
添加和删除字段
重新排序字段
根据表达式计算新字段
从另一图层加载字段列表
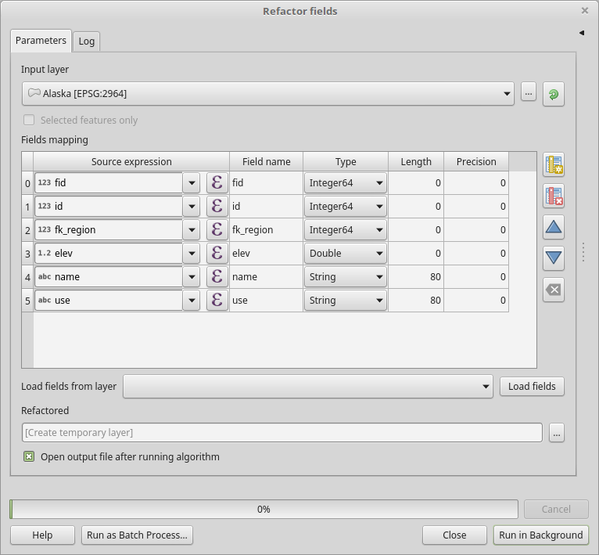
图 27.126 重构字段对话框
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
要修改的层 |
Fields mapping |
|
[list] |
输出字段及其定义的列表。嵌入表列出了源图层的所有字段,并允许您编辑它们:
对于要重复使用的每个字段,您需要填写以下选项:
|
Refactored |
|
[vector: any] 默认: |
输出层的规范。以下选项之一:
还可以在此处更改文件编码。 |





产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Refactored |
|
[vector: any] |
包含重构字段的输出图层 |
Python代码
Algorithm ID : native:refactorfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.11. 重命名字段
重命名矢量层中的现有场。
不会修改原始层。将在属性表中包含重命名的字段的位置生成新的层。
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层 |
Field to rename |
|
[tablefield: any] |
要更改的字段 |
New field name |
|
[string] |
新的字段名称 |
Renamed |
|
[vector: same as input] 默认: |
输出层的规范。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Renamed |
|
[vector: same as input] |
具有重命名的字段的输出图层 |
Python代码
Algorithm ID : qgis:renametablefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.12. 保留字段
获取一个矢量层并生成一个仅保留选定字段的新层。所有其他字段都将被删除。
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层 |
Fields to retain |
|
[tablefield: any] [list] |
要保留在图层中的字段列表 |
Retained fields |
|
[vector: same as input] 默认: |
输出层的规范。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Retained fields |
|
[vector: same as input] |
包含保留字段的输出图层 |
Python代码
Algorithm ID : native:retainfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.21.13. 要浮动的文本
修改向量层中给定属性的类型,将包含数字字符串的文本属性转换为数字属性(例如 1.0 )。
该算法创建了一个新的矢量层,因此源矢量层不会被修改。
如果无法进行转换,则选定的列将具有 NULL 价值观。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层。 |
Text attribute to convert to float |
|
[tablefield: string] |
要转换为浮点型字段的输入层的字符串字段。 |
Float from text |
|
[same as input] 默认: |
指定输出层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Float from text |
|
[same as input] |
将字符串域转换为浮点域的输出向量图层 |
Python代码
Algorithm ID : qgis:texttofloat
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。