27.1.15. 向量分析
27.1.15.1. 字段的基本统计信息
为矢量图层的属性表中的字段生成基本统计信息。
支持数字、日期、时间和字符串字段。
返回的统计信息将取决于字段类型。
统计数据以HTML文件的形式生成,并可在 。
Default menu :
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input vector |
|
[vector: any] |
要计算其统计数据的矢量图层 |
Field to calculate statistics on |
|
[tablefield: any] |
用于计算统计数据的任何受支持的表字段 |
Statistics 任选 |
|
[html] 默认: |
用于计算的统计信息的文件的规范。以下选项之一:
|
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Statistics |
|
[html] |
包含计算出的统计数据的HTML文件 |
Count |
|
[number] |
|
Number of unique values |
|
[number] |
|
Number of empty (null) values |
|
[number] |
|
Number of non-empty values |
|
[number] |
|
Minimum value |
|
[same as input] |
|
Maximum value |
|
[same as input] |
|
Minimum length |
|
[number] |
|
Maximum length |
|
[number] |
|
Mean length |
|
[number] |
|
Coefficient of Variation |
|
[number] |
|
Sum |
|
[number] |
|
Mean value |
|
[number] |
|
Standard deviation |
|
[number] |
|
Range |
|
[number] |
|
Median |
|
[number] |
|
Minority (rarest occurring value) |
|
[same as input] |
|
Majority (most frequently occurring value) |
|
[same as input] |
|
First quartile |
|
[number] |
|
Third quartile |
|
[number] |
|
Interquartile Range (IQR) |
|
[number] |
Python代码
Algorithm ID : qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.2. 沿着这条线攀登
计算沿线几何图形的总爬升和下降。输入层必须具有Z值。如果Z值不可用,则 覆盖(从栅格设置Z值) 算法可用于添加来自DEM图层的Z值。
输出图层是输入图层的副本,其中包含包含总爬升的其他字段 (climb ),完全下降 (descent )、最小高程 (minelev )和最大标高 (maxelev )用于每个线几何图形。如果输入层包含与这些添加的字段同名的字段,则它们将被重命名(字段名称将更改为“NAME_2”、“NAME_3”等,以查找第一个非重复名称)。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Line layer |
|
[vector: line] |
要计算其爬升的线层。必须具有Z值 |
Climb layer |
|
[vector: line] 默认: |
输出(行)层的规范。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Climb layer |
|
[vector: line] |
包含带有攀登计算结果的新属性的线层。 |
Total climb |
|
[number] |
输入图层中所有线几何的爬升总和 |
Total descent |
|
[number] |
输入图层中所有线几何的下降值之和 |
Minimum elevation |
|
[number] |
层中几何图形的最小高程 |
Maximum elevation |
|
[number] |
层中几何图形的最大高程 |
Python代码
Algorithm ID : qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.3. 对多边形中的点进行计数
获取一个点和一个多边形层,并计算多边形层的每个多边形中来自该点层的点数。
将生成一个新的多边形层,其内容与输入多边形层的内容完全相同,但包含一个附加字段,该字段的点数与每个多边形对应。
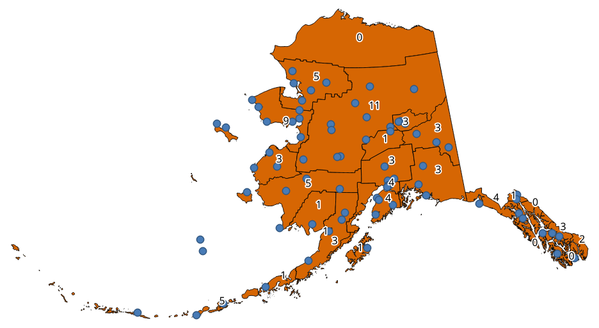
图 27.31 面中的标注显示点数
可选的权重字段可用于为每个点分配权重。或者,可以指定唯一的类字段。如果这两个选项都使用,则权重字段将优先,唯一类字段将被忽略。
 允许 features in-place modification 面要素的
允许 features in-place modification 面要素的
Default menu:
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Polygons |
|
[vector: polygon] |
其要素与其包含的点数相关联的面图层 |
Points |
|
[vector: point] |
包含要计数的要素的点图层 |
Weight field 任选 |
|
[tablefield: any] |
点图层中的字段。生成的计数将是该多边形包含的点的权重场的总和。如果权重字段不是数值,则计数将为 |
Class field 任选 |
|
[tablefield: any] |
根据选定的属性对点进行分类,如果具有相同属性值的多个点位于多边形内,则只计算其中一个点。因此,多边形中的点的最终计数是在其中发现的不同类的计数。 |
Count field name |
|
[string] 默认值:‘NUMPOINTS’ |
用于存储点数的字段的名称 |
Count |
|
[vector: polygon] 默认: |
输出层的规范。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Count |
|
[vector: polygon] |
属性表中包含带有点数的新列的结果图层 |
Python代码
Algorithm ID : native:countpointsinpolygon
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.4. DBSCAN集群
基于二维聚类点要素的基于密度的带噪声空间聚类(DBSCAN)算法。
该算法需要两个参数,最小聚类大小和聚类点之间允许的最大距离。
参见
参数
基本参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: point] |
要分析的层 |
Minimum cluster size |
|
[number] 默认:5 |
生成聚类所需的最小要素数 |
Maximum distance between clustered points |
|
[number] 默认:1.0 |
两个要素不能属于同一聚类的距离(EPS) |
Clusters |
|
[vector: point] 默认: |
指定聚类结果的矢量层。以下选项之一:
还可以在此处更改文件编码。 |
高级参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Treat border points as noise (DBSCAN*) 任选 |
|
[boolean] 默认:FALSE |
如果选中,簇边界上的点本身将被视为未聚簇的点,并且只有簇内部的点被标记为簇。 |
Cluster field name |
|
[string] 默认值:‘CLUSTER_ID’ |
存储相关群集号的字段的名称 |
Cluster size field name |
|
[string] 默认值:‘CLUSTER_SIZE’ |
包含同一聚类中的要素计数的字段名称 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Clusters |
|
[vector: point] |
包含原始要素的矢量图层,其中包含用于设置要素所属聚类的字段 |
Number of clusters |
|
[number] |
已发现的簇数 |
Python代码
Algorithm ID : native:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.5. 距离矩阵
计算点要素到其在同一图层或另一图层中最近要素的距离。
Default menu :
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input point layer |
|
[vector: point] |
为其计算距离矩阵的点图层( from 积分) |
Input unique ID field |
|
[tablefield: any] |
用于唯一标识输入图层要素的字段。在输出属性表中使用。 |
Target point layer |
|
[vector: point] |
包含要搜索的最近点(S)的点图层( to 积分) |
Target unique ID field |
|
[tablefield: any] |
用于唯一标识目标图层要素的字段。在输出属性表中使用。 |
Output matrix type |
|
[enumeration] 默认:0 |
有不同类型的计算可用:
|
Use only the nearest (k) target points |
|
[number] 默认:0 |
您可以选择计算到目标图层中所有点的距离( 0 )或限制为一个数字( k )最接近的要素。 |
Distance matrix |
|
[vector: point] 默认: |
输出向量层的规范。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Distance matrix |
|
[vector: point] |
点(或多点表示“线性(N * * K*x 3)“Case)包含每个输入要素的距离计算的矢量层。其要素和属性表取决于所选的输出矩阵类型。 |
Python代码
Algorithm ID : qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.6. 到最近枢纽的距离(线到枢纽)
创建将输入矢量的每个要素连接到目标图层中最近的要素的直线。距离是根据 center 每一项功能。
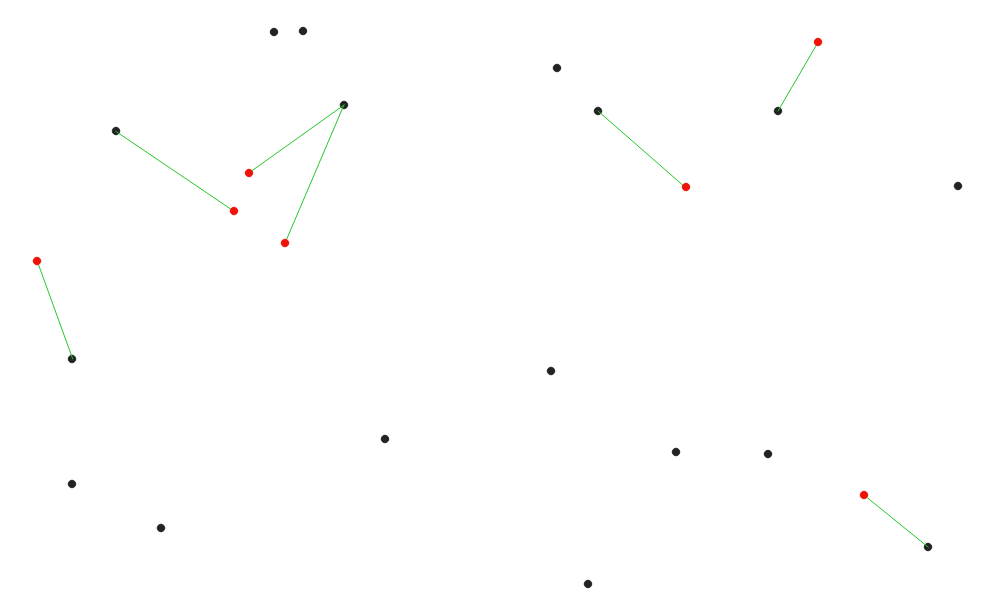
图 27.32 显示红色输入要素的最近中心
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Source points layer |
|
[vector: any] |
搜索最近要素的矢量图层 |
Destination hubs layer |
|
[vector: any] |
包含要搜索的要素的矢量图层 |
Hub layer name attribute |
|
[tablefield: any] |
用于唯一标识目标图层要素的字段。在输出属性表中使用 |
Measurement unit |
|
[enumeration] 默认:0 |
报告到最近要素的距离的单位:
|
Hub distance |
|
[vector: line] 默认: |
指定连接匹配点的输出线向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Hub distance |
|
[vector: line] |
具有输入要素的属性、其最近要素的标识符和计算的距离的线矢量图层。 |
Python代码
Algorithm ID : qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.7. 到最近枢纽的距离(点)
创建一个点图层,表示 center 添加了两个字段,其中包含最近要素的标识符(基于其中心点)和点之间的距离。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Source points layer |
|
[vector: any] |
搜索最近要素的矢量图层 |
Destination hubs layer |
|
[vector: any] |
包含要搜索的要素的矢量图层 |
Hub layer name attribute |
|
[tablefield: any] |
用于唯一标识目标图层要素的字段。在输出属性表中使用 |
Measurement unit |
|
[enumeration] 默认:0 |
报告到最近要素的距离的单位:
|
Hub distance |
|
[vector: point] 默认: |
指定具有最近集线器的输出点向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Hub distance |
|
[vector: point] |
点向量层,表示源要素的中心及其属性、最近要素的标识符和计算的距离。 |
Python代码
Algorithm ID : qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.8. 通过线连接(枢纽线)
通过将轮辐层上的点连接到中心层中匹配点的线来创建轮辐图和轮辐图。
根据中心点上的集线器ID字段与辐条点上的辐条ID字段之间的匹配来确定每个点对应的集线器。
如果输入层不是点层,则几何图形表面上的一个点将被视为连接位置。
此外,还可以创建测地线,这些测地线表示椭球体表面上的最短路径。使用测地线模式时,可以在反偏线(±180度经度)处拆分创建的线,这可以改善线的渲染。此外,还可以指定顶点之间的距离。距离越小,线条越密集、越精确。
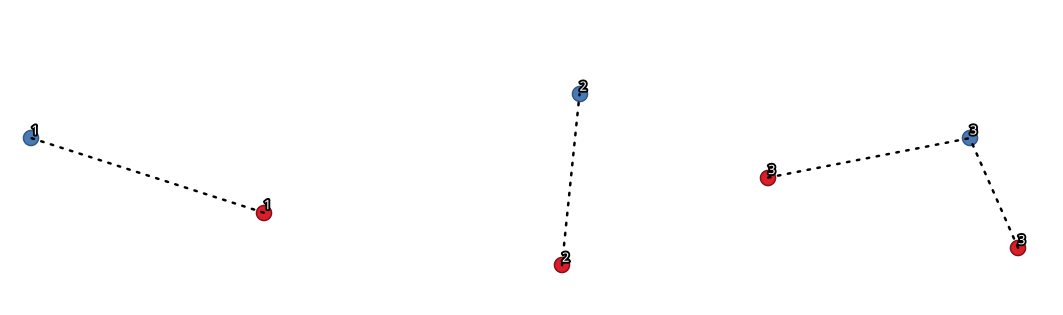
图 27.33 基于公共字段/属性的连接点
参数
基本参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Hub layer |
|
[vector: any] |
输入层 |
Hub ID field |
|
[tablefield: any] |
具有要连接的ID的Hub图层字段 |
Hub layer fields to copy (leave empty to copy all fields) 任选 |
|
[tablefield: any] [list] |
要复制的HUB层的字段(S)。如果没有选择任何字段(S),则采用所有字段。 |
Spoke layer |
|
[vector: any] |
其他轮辐点图层 |
Spoke ID field |
|
[tablefield: any] |
ID为要加入的辐条图层的字段 |
Spoke layer fields to copy (leave empty to copy all fields) 任选 |
|
[tablefield: any] [list] |
要复制的轮辐层的字段(S)。如果未选择任何字段,则采用所有字段。 |
Create geodesic lines |
|
[boolean] 默认:FALSE |
创建测地线(椭球体曲面上的最短路径) |
Hub lines |
|
[vector: line] 默认: |
指定输出轮毂线向量层。以下选项之一:
还可以在此处更改文件编码。 |
高级参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Distance between vertices (geodesic lines only) |
|
[number] 默认:1000.0(公里) |
连续顶点之间的距离(以公里为单位)。距离越小,线条越密集、越精确 |
Split lines at antimeridian (±180 degrees longitude) |
|
[boolean] 默认:FALSE |
以±180度经度拆分线条(以改善线条的渲染) |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Hub lines |
|
[vector: line] |
连接输入图层中匹配点的结果线图层 |
Python代码
Algorithm ID : native:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.9. K-均值聚类
为每个输入要素计算基于2D距离的k均值聚类数。
K-均值聚类的目的是将特征划分成k个簇,每个特征属于均值最接近的簇。均值点由聚类特征的重心表示。
如果输入几何图形是直线或多边形,则聚类会基于要素的质心。
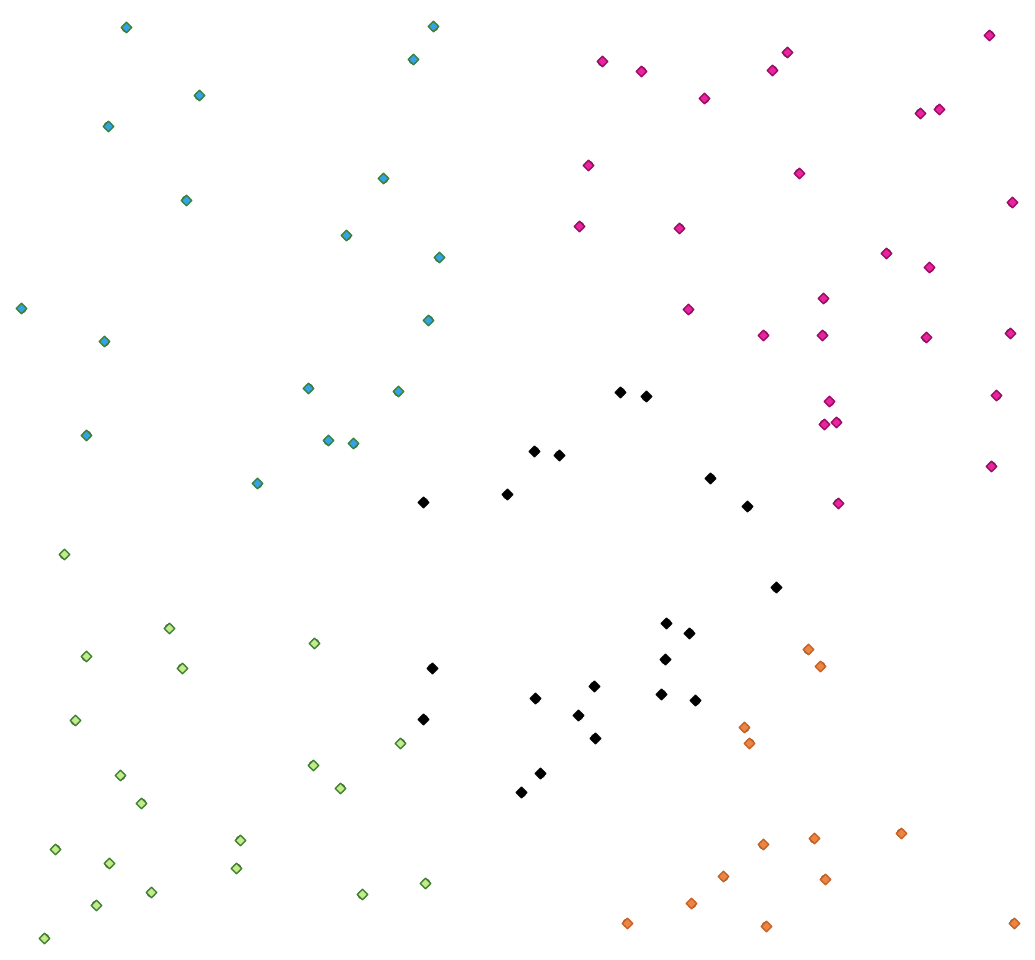
图 27.34 A类五类点群
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
要分析的层 |
Number of clusters |
|
[number] 默认:5 |
要使用要素创建的聚类数 |
Clusters |
|
[vector: any] 默认:`` [Create temporary layer] `` |
为生成的簇指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
高级参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Cluster field name |
|
[string] 默认值:‘CLUSTER_ID’ |
存储相关群集号的字段的名称 |
Cluster size field name |
|
[string] 默认值:‘CLUSTER_SIZE’ |
包含同一聚类中的要素计数的字段名称 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Clusters |
|
[vector: any] |
包含原始要素的矢量图层,其中的字段指定了这些要素所属的聚类及其编号 |
Python代码
Algorithm ID : native:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.10. 列出唯一值
列出属性表字段的唯一值并计算其数量。
Default menu :
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
要分析的层 |
Target field(s) |
|
[tablefield: any] |
要分析的字段 |
Unique values 任选 |
|
[table] 默认:`` [Create temporary layer] `` |
使用唯一值指定摘要表层。以下选项之一:
还可以在此处更改文件编码。 |
HTML report 任选 |
|
[html] 默认:`` [Save to temporary file] `` |
中的唯一值的HTML报告 。以下选项之一:
|
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Unique values |
|
[table] |
具有唯一值的汇总表图层 |
HTML report |
|
[html] |
唯一值的HTML报告。可以从 |
Total unique values |
|
[number] |
输入字段中唯一值的数量 |
Unique values concatenated |
|
[string] |
输入字段中包含以逗号分隔的唯一值列表的字符串 |
Python代码
Algorithm ID : qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.11. 平均坐标(S)
使用输入图层中几何图形的质心计算点图层。
可以将属性指定为包含要在计算质心时应用于每个特征的权重。
如果在参数中选择了属性,则将根据此字段中的值对要素进行分组。输出图层将包含每个类别中要素的质心,而不是具有整个图层质心的单个点。
Default menu :
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入向量层 |
Weight field 任选 |
|
[tablefield: numeric] |
如果要执行加权平均值,则使用的字段 |
Unique ID field |
|
[tablefield: numeric] |
将计算平均值的唯一字段 |
Mean coordinates |
|
[vector: point] 默认:`` [Create temporary layer] `` |
指定结果的(点矢量)层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Mean coordinates |
|
[vector: point] |
结果点(S)图层 |
Python代码
Algorithm ID : native:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.12. 最近邻分析
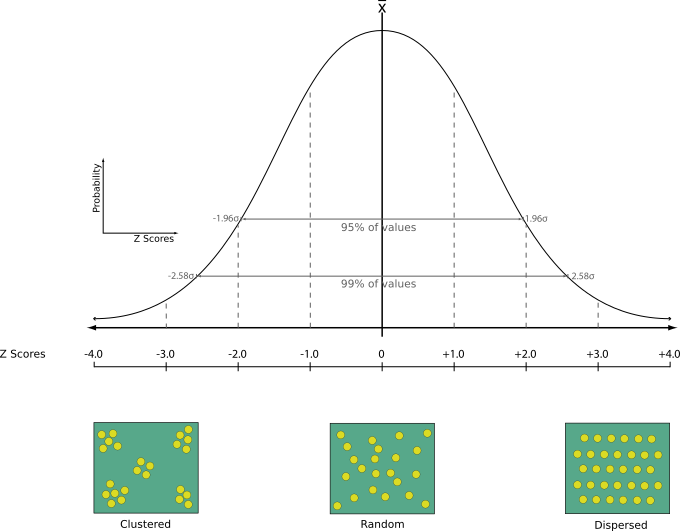
对点图层执行最近邻分析。输出告诉您数据是如何分布的(集群、随机或分布)。
输出以包含计算的统计值的HTML文件的形式生成:
观测平均距离
期望平均距离
最近邻指数
点数
Z-Score:将Z-Score与正态分布进行比较,可以知道数据是如何分布的。低Z分数意味着数据不太可能是空间随机过程的结果,而高Z分数意味着数据很可能是空间随机过程的结果。
Default menu :
参见
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: point] |
要计算其统计数据的点矢量图层 |
Nearest neighbour 任选 |
|
[html] 默认:`` [Save to temporary file] `` |
计算的统计信息的HTML文件的规范。以下选项之一:
|
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Nearest neighbour |
|
[html] |
包含计算出的统计数据的HTML文件 |
Observed mean distance |
|
[number] |
观测平均距离 |
Expected mean distance |
|
[number] |
期望平均距离 |
Nearest neighbour index |
|
[number] |
最近邻指数 |
Number of points |
|
[number] |
点数 |
Z-Score |
|
[number] |
Z-得分 |
Python代码
Algorithm ID : native:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.13. 重叠分析
计算输入图层中的要素与所选覆盖图层中的要素重叠的面积和覆盖百分比。
新属性将添加到输出图层,报告由每个选定覆盖图层重叠的输入要素的总重叠面积和百分比。
参数
基本参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: any] |
输入层。 |
Overlap layers |
|
[vector: any] [list] |
覆盖层。 |
Overlap |
|
[same as input] 默认: |
指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
高级参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Grid size 任选 |
|
[number] 默认:未设置 |
如果提供,输入几何图形将捕捉到给定大小的栅格,并在该栅格上计算结果顶点。需要GEOS 3.9.0或更高版本。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Overlap |
|
[same as input] |
具有报告每个选定图层重叠的输入要素的重叠(以地图单位和百分比表示)的附加字段的输出图层。 |
Python代码
Algorithm ID : native:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.14. 要素之间的最短线
创建一条直线图层作为源和目标图层之间的最短直线。默认情况下,仅考虑目标层的第一个最近要素。可以指定n个最近的相邻要素数。如果指定了最大距离,则只会考虑比此距离更近的要素。
输出要素将包含所有源层属性、来自n最近要素的所有属性以及距离的附加字段。
重要
此算法使用纯粹的笛卡尔距离计算,在确定要素邻近度时不考虑大地测量或椭球体特性。测量和输出坐标系基于源层的坐标系。
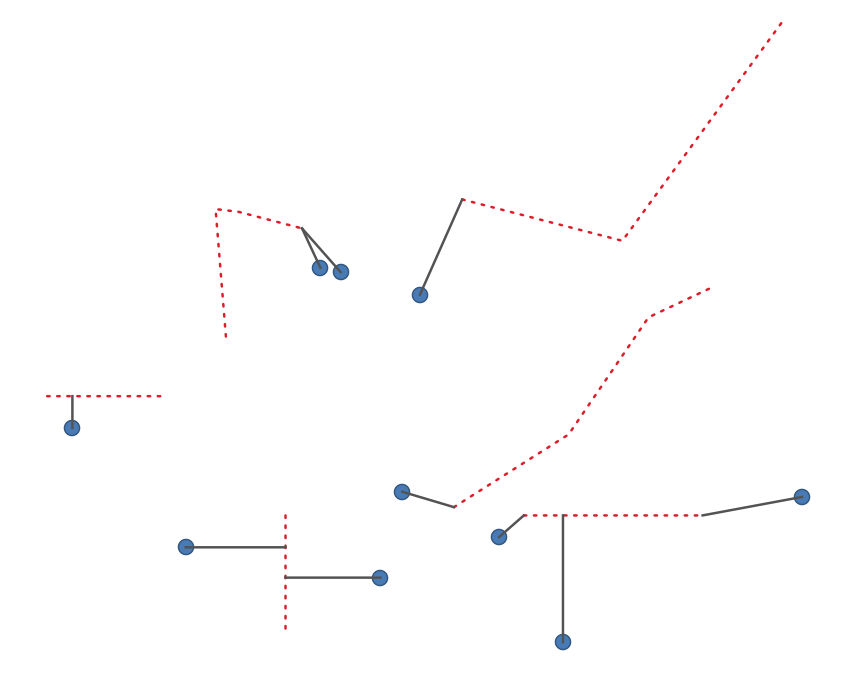
图 27.35 从点要素到线的最短线
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Source layer |
|
[vector: any] |
要搜索最近邻的原始图层 |
Destination layer |
|
[vector: any] |
要在其中搜索最近邻域的目标图层 |
Method |
|
[enumeration] 默认:0 |
最短距离计算方法可能的值为:
|
Maximum number of neighbors |
|
[number] 默认:1 |
要查找的最大邻居数 |
Maximum distance 任选 |
|
[number] |
只有比此距离更近的目的地要素将被考虑。 |
Shortest lines |
|
[vector: line] 默认: |
指定输出向量层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Output layer |
|
[vector: line] |
线向量图层将源要素连接到其在目标图层中的最近邻居(S)。包含源要素和目标要素的所有属性以及计算的距离。 |
Python代码
Algorithm ID : native:shortestline
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.15. ST-DBSCAN聚类
基于2D实现的基于时空密度的带噪声应用程序聚类(ST-DBSCAN)算法。
参数
基本参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input layer |
|
[vector: point] |
要分析的层 |
Date/time field |
|
[tablefield: date] |
包含时间信息的字段 |
Minimum cluster size |
|
[number] 默认:5 |
生成聚类所需的最小要素数 |
Maximum distance between clustered points |
|
[number] 默认:1.0 |
两个要素不能属于同一聚类的距离(EPS) |
Maximum time duration between clustered points |
|
[number] 默认值:0.0(天数) |
持续时间,超过该持续时间,两个特征不能属于同一簇(Eps2)。可用的时间单位为毫秒、秒、分钟、小时、天和周。 |
Clusters |
|
[vector: point] 默认: |
指定聚类结果的矢量层。以下选项之一:
还可以在此处更改文件编码。 |
高级参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Treat border points as noise (DBSCAN*) 任选 |
|
[boolean] 默认:FALSE |
如果选中,簇边界上的点本身将被视为未聚簇的点,并且只有簇内部的点被标记为簇。 |
Cluster field name |
|
[string] 默认值:‘CLUSTER_ID’ |
存储相关群集号的字段的名称 |
Cluster size field name |
|
[string] 默认值:‘CLUSTER_SIZE’ |
包含同一聚类中的要素计数的字段名称 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Clusters |
|
[vector: point] |
包含原始要素的矢量图层,其中包含用于设置要素所属聚类的字段 |
Number of clusters |
|
[number] |
已发现的簇数 |
Python代码
Algorithm ID : native:stdbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.16. 按类别统计
根据父类计算字段的统计信息。父类是来自其他字段的值的组合。
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Input vector layer |
|
[vector: any] |
具有唯一类和值的输入矢量图层 |
Field to calculate statistics on (if empty, only count is calculated) 任选 |
|
[tablefield: any] |
如果为空,则仅计算计数 |
Field(s) with categories |
|
[vector: any] [list] |
定义类别的(组合)字段 |
Statistics by category |
|
[table] 默认: |
为生成的统计信息指定输出表。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Statistics by category |
|
[table] |
包含统计数据的表 |
根据要分析的字段的类型,将为每个分组的值返回以下统计信息:
统计数据 |
细绳 |
数字 |
日期 |
|---|---|---|---|
数数 ( |
|
|
|
唯一值 ( |
|
|
|
空(NULL)值 ( |
|
|
|
非空值 ( |
|
|
|
极小值 ( |
|
|
|
最大值 ( |
|
|
|
射程 ( |
|
||
求和 ( |
|
||
平均值 ( |
|
||
中位数 ( |
|
||
标准差 ( |
|
||
变异系数 ( |
|
||
少数(最稀有的出现值- |
|
||
多数(出现频率最高的值- |
|
||
第一个四分位数 ( |
|
||
第三个四分位数 ( |
|
||
四分位数区间 ( |
|
||
最小长度 ( |
|
||
平均长度 ( |
|
||
最大长度 ( |
|
Python代码
Algorithm ID : qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。
27.1.15.17. 总和线条长度
获取多边形层和线层,并测量线的总长度和与每个多边形相交的线的总数。
生成的层具有与输入多边形层相同的功能,但具有两个附加属性,其中包含跨越每个多边形线的长度和计数。
允许 features in-place modification 面要素的
Default menu :
参数
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Lines |
|
[vector: line] |
输入矢量线图层 |
Polygons |
|
[vector: polygon] |
多边形矢量层 |
Lines length field name |
|
[string] 缺省值:‘长度’ |
线长度的字段名称 |
Lines count field name |
|
[string] 默认:‘计数’ |
用于行计数的字段的名称 |
Line length |
|
[vector: polygon] 默认: |
使用生成的统计信息指定输出多边形层。以下选项之一:
还可以在此处更改文件编码。 |
产出
标签 |
名字 |
类型 |
描述 |
|---|---|---|---|
Line length |
|
[vector: polygon] |
具有线长度和线计数字段的面输出图层 |
Python代码
Algorithm ID : native:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 algorithm id 当您将鼠标悬停在处理工具箱中的算法上时,将显示。这个 parameter dictionary 提供参数名称和值。看见 从控制台使用处理算法 有关如何从Python控制台运行处理算法的详细信息。