scipy.stats.tukey_hsd¶
- scipy.stats.tukey_hsd(*args)[源代码]¶
执行Tukey‘s HSD测试,以确定多种治疗方法的均数相等。
图基的诚实显着差异(HSD)检验对一组样本的均值进行成对比较。而方差分析(例如
f_oneway)评估每个样本背后的真实均值是否相同,Tukey的HSD是用于比较每个样本的平均值与每个其他样本的平均值的事后检验。零假设是样本下面的分布都具有相同的均值。测试统计量是针对每个可能的样本配对计算的,它只是样本均值之间的差异。对于每一对,考虑到正在执行许多成对比较,p值是在零假设(和其他假设;请参见注释)下观察到统计的这种极值的概率。每对均值之间的差异的置信区间也是可用的。
- 参数
- 样本1,样本2,.array_like
每组的样本测量。必须至少有两个论点。
- 退货
- 结果 :
TukeyHSDResult实例TukeyHSDResult实例 返回值是具有以下属性的对象:
- 统计数据浮动ndarray
每次比较的测试的计算统计信息。索引处的元素
(i, j)是用于组间比较的统计数据i和j。- p值浮动ndarray
每次比较的测试计算的p值。索引处的元素
(i, j)是用于组之间比较的p值。i和j。
该对象具有以下方法:
- 置信度_间隔(置信度_级别=0.95):
计算指定置信级别的置信区间。
- 结果 :
注意事项
这项测试的使用依赖于几个假设。
观察结果在组内和组间都是独立的。
每组内的观测值呈正态分布。
从中抽取样本的分布具有相同的有限方差。
测试的原始配方是针对相同大小的样品。 [6]. 在样本大小不相等的情况下,测试使用Tukey-Kramer方法 [4].
参考文献
- 1
NIST/SEMATECH统计方法电子手册,“7.4.7.1,图基方法”。https://www.itl.nist.gov/div898/handbook/prc/section4/prc471.htm,于2020年11月28日。
- 2
作者声明:[by]Abdi,Herve&Williams,Lynne.(2021年)。“图基的诚实显著差异(HSD)测试。”https://personal.utdallas.edu/~herve/abdi-HSD2010-pretty.pdf
- 3
“使用SAS过程方差分析和过程GLM的单向方差分析。”sas教程,2007年,www.stattutorials.com/SAS/TUTORIAL-PROC-GLM.htm.
- 4
克莱默,克莱德·杨。“将多个范围测试扩展到组意味着重复次数不相等。”生物特征学,第一卷。12,第3期,1956年,第307-310页。JSTOR,www.jstor.org/STRATE/3001469。2021年5月25日访问。
- 5
NIST/SEMATECH统计方法电子手册,“7.4.3.3.关于均值的假设的方差分析表和检验”,https://www.itl.nist.gov/div898/handbook/prc/section4/prc433.htm,,2021年6月2日。
- 6
作者:John W.“比较方差分析中的个体均值。”生物特征学,第一卷。第5期,第2期,1949年,第99-114页。JSTOR,www.jstor.org/STRATE/3001913。2021年6月14日访问。
示例
以下是几分钟内报告的三种品牌头痛药物缓解时间的一些数据。数据改编自 [3].
>>> from scipy.stats import tukey_hsd >>> group0 = [24.5, 23.5, 26.4, 27.1, 29.9] >>> group1 = [28.4, 34.2, 29.5, 32.2, 30.1] >>> group2 = [26.1, 28.3, 24.3, 26.2, 27.8]
我们想看看这些团体之间的手段是否有显著的不同。首先,目测一个盒子和胡须情节。
>>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(1, 1) >>> ax.boxplot([group0, group1, group2]) >>> ax.set_xticklabels(["group0", "group1", "group2"]) >>> ax.set_ylabel("mean") >>> plt.show()
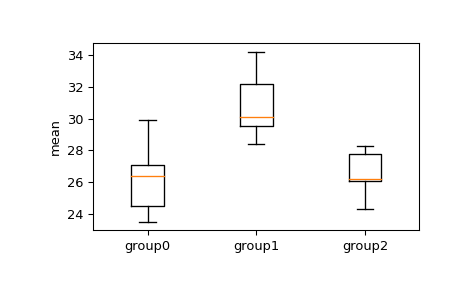
从盒子和胡须图中,我们可以看到四分位数范围组1到组2和组3之间的重叠,但是我们可以应用
tukey_hsd测试以确定平均数之间的差异是否显著。我们将显著性水平设置为0.05以拒绝零假设。>>> res = tukey_hsd(group0, group1, group2) >>> print(res) Tukey's HSD Pairwise Group Comparisons (95.0% Confidence Interval) Comparison Statistic p-value Lower CI Upper CI (0 - 1) -4.600 0.014 -8.249 -0.951 (0 - 2) -0.260 0.980 -3.909 3.389 (1 - 0) 4.600 0.014 0.951 8.249 (1 - 2) 4.340 0.020 0.691 7.989 (2 - 0) 0.260 0.980 -3.389 3.909 (2 - 1) -4.340 0.020 -7.989 -0.691
零假设是,每组人的平均数都是一样的。用于比较的p值
group0和group1以及group1和group2不超过0.05,因此我们拒绝接受它们具有相同均值的零假设。之间比较的p值group0和group2超过0.05,所以我们接受零假设,即它们的平均值之间没有显著差异。我们还可以计算与我们选择的置信水平相关联的置信区间。
>>> group0 = [24.5, 23.5, 26.4, 27.1, 29.9] >>> group1 = [28.4, 34.2, 29.5, 32.2, 30.1] >>> group2 = [26.1, 28.3, 24.3, 26.2, 27.8] >>> result = tukey_hsd(group0, group1, group2) >>> conf = res.confidence_interval(confidence_level=.99) >>> for ((i, j), l) in np.ndenumerate(conf.low): ... # filter out self comparisons ... if i != j: ... h = conf.high[i,j] ... print(f"({i} - {j}) {l:>6.3f} {h:>6.3f}") (0 - 1) -9.480 0.280 (0 - 2) -5.140 4.620 (1 - 0) -0.280 9.480 (1 - 2) -0.540 9.220 (2 - 0) -4.620 5.140 (2 - 1) -9.220 0.540