>>> from env_helper import info; info()
页面更新时间: 2024-01-06 20:46:22
运行环境:
Linux发行版本: Debian GNU/Linux 12 (bookworm)
操作系统内核: Linux-6.1.0-16-amd64-x86_64-with-glibc2.36
Python版本: 3.11.2
5.9. 统计估计和误差线¶
数据可视化有时涉及聚合或估计步骤,其中多个数据点被简化为汇总统计量,例如平均值或中位数。显示汇总统计数据时,通常适合添加误差线,这些误差线提供了有关汇总表示基础数据点的程度的视觉提示。
当给定一个完整的数据集时,几个 seaborn 函数将自动计算汇总统计数据和误差线。本章解释了如何控制误差线显示的内容,以及为什么您可以选择 seaborn 提供的每个选项。
围绕集中趋势估计值的误差线可以显示以下两个一般情况之一:估计值的不确定性范围或基础数据围绕它的分布。这些措施是相关的:在样本量相同的情况下,当数据具有更广泛的分布时,估计值将更加不确定。但随着样本量的增加,不确定性会降低,而传播不会。
在 seaborn 中,有两种方法可以构造每种误差线。一种方法是参数化,使用依赖于分布形状假设的公式。另一种方法是非参数化的,仅使用您提供的数据。
您的选择是使用参数进行的,errorbar参数存在于作为绘图的一部分进行估计的每个函数中。此参数接受要使用的方法的名称,以及控制间隔大小的参数(可选)。这些选择可以在
2D 分类法中定义,该分类法取决于显示的内容及其构造方式:

您会注意到,对于参数化和非参数化方法,size 参数的定义不同。对于参数误差线,它是一个标量因子,乘以定义误差(标准误差或标准差)的统计量。对于非参数误差线,它是一个百分位数宽度。下面将针对每种特定方法进一步解释这一点。
注意
这里描述的errorbar API是在seaborn
v0.12中引入的。在以前的版本中,唯一的选项是显示引导置信区间或标准偏差,其选择由ci参数控制(即ci=<size>或ci="sd")。
为了比较不同的参数化,我们将使用以下帮助程序函数:
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> import seaborn as sns
>>>
>>> sns.set_theme()
>>>
>>> def plot_errorbars(arg, **kws):
>>> np.random.seed(sum(map(ord, "error_bars")))
>>> x = np.random.normal(0, 1, 100)
>>> f, axs = plt.subplots(2, figsize=(7, 2), sharex=True, layout="tight")
>>> sns.pointplot(x=x, errorbar=arg, **kws, capsize=.3, ax=axs[0])
>>> sns.stripplot(x=x, jitter=.3, ax=axs[1])
5.9.1. 数据传播的度量¶
表示数据分布的误差条使用三个数字紧凑地显示分布,其中boxplot()将使用5或更多,violinplot()将使用复杂的算法。
标准偏差误差线¶
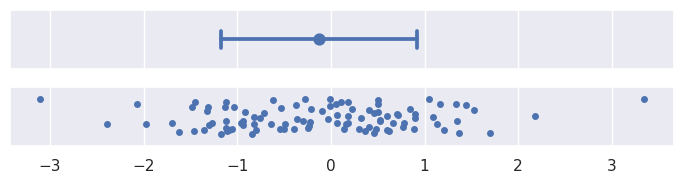
标准偏差误差条是最容易解释的,因为标准偏差是一个熟悉的统计量。它是每个数据点到样本均值的平均距离。默认情况下,errorbar="sd"将在估计值周围以+/-
1
sd绘制误差条,但可以通过传递缩放大小参数来增加该范围。请注意,假设数据正态分布,68%的数据将在一个标准差内,95%将在两个标准差内,~99.7%将在三个标准差内:
>>> plot_errorbars("sd")
百分位数区间误差线¶
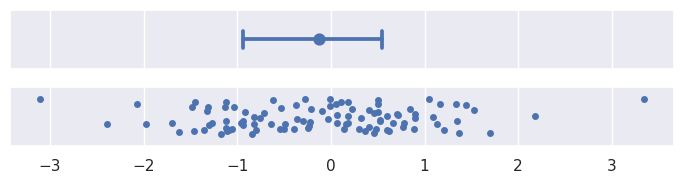
百分位数区间也表示某些数据量的范围,但它们是通过直接从样本中计算这些百分位数来实现的。默认情况下,errorbar="pi"将显示95%的区间,范围从2.5到97.5个百分点。你可以通过传递一个大小参数来选择一个不同的范围,例如,显示四分位数间的范围:
>>> plot_errorbars(("pi", 50))
标准差误差线将始终围绕估计值对称。当数据偏斜时,这可能是一个问题,尤其是在存在自然边界的情况下(例如,如果数据表示只能为正的量)。在某些情况下,标准偏差误差线可能会扩展到“不可能”的值。非参数方法没有这个问题,因为它可以解释不对称扩散,并且永远不会超出数据范围。
5.9.2. 估计不确定性的度量¶
如果数据是来自较大总体的随机样本,则均值(或其他估计值)将是真实总体平均值的不完美度量。显示估计不确定性的误差线尝试表示真实参数的可能值范围。
标准误差线¶
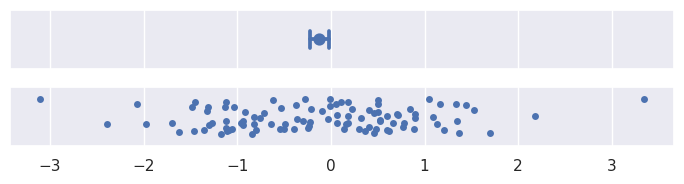
标准误差统计量与标准差有关:实际上,它只是标准差除以样本数量的平方根。默认值
errorbar="se" ,从平均值中得出区间 +/-1 标准误差:
>>> plot_errorbars("se")
置信区间误差线¶
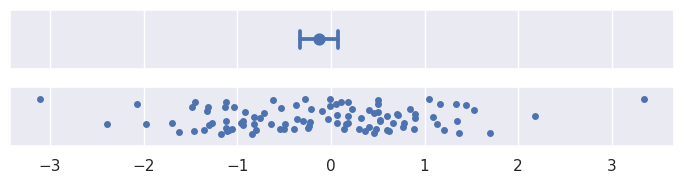
表示不确定性的非参数方法使用自举:在该过程中,数据集被随机重新采样并替换多次,并且根据每次重新采样重新计算估计值。此过程将创建一个统计数据的分布,该分布近似于在具有不同样本的情况下可以为估计值获得的值的分布。
置信区间是通过取自举分布的一个百分位数区间来构造的。默认情况下errorbar="ci"绘制95%置信区间:
>>> plot_errorbars("ci")
seaborn 术语有些具体,因为统计中的置信区间可以是参数的,也可以是非参数的。要绘制参数置信区间,请使用与上述公式类似的公式缩放标准误差。例如,可以通过取平均值 +/- 两个标准误差来构建近似 95% 的置信区间:
>>> plot_errorbars(("se", 2))
非参数自举程序具有与百分位数区间相似的优点:它将自然地适应偏斜和有界数据,这是标准误差区间无法做到的。它也更笼统。虽然标准误差公式特定于平均值,但可以使用任何估计器的引导程序来计算误差线:
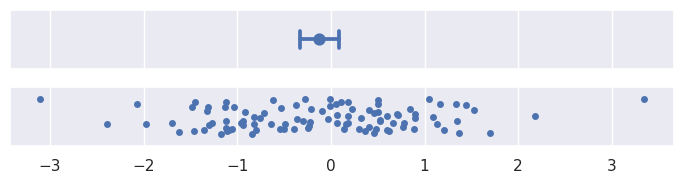
>>> plot_errorbars("ci", estimator="median")
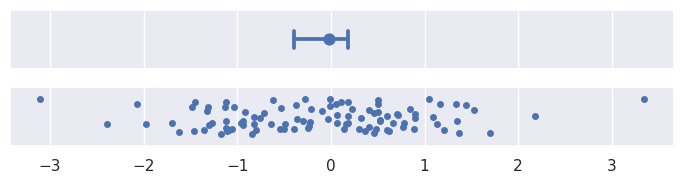
引导涉及随机性,每次运行创建错误条的代码时,错误条都会略有不同。有几个参数可以控制这一点。其中一个设置迭代次数(n_boot):迭代次数越多,生成的时间间隔就越稳定。另一个为随机数生成器设置seed,这将确保相同的结果:
>>> plot_errorbars("ci", n_boot=5000, seed=10)
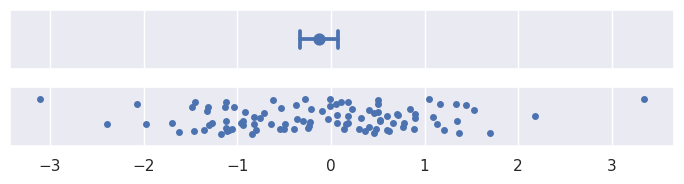
由于其迭代过程,引导间隔的计算成本可能很高,尤其是对于大型数据集。但是,由于不确定性随着样本量的增加而降低,因此在这种情况下,使用表示数据分布的误差线可能更具信息性。
自定义误差线¶
如果这些配方还不够,也可以将泛型函数传递给参数。此函数应采用一个向量并生成一对值,表示区间的最小点和最大点:errorbar
>>> plot_errorbars(lambda x: (x.min(), x.max()))
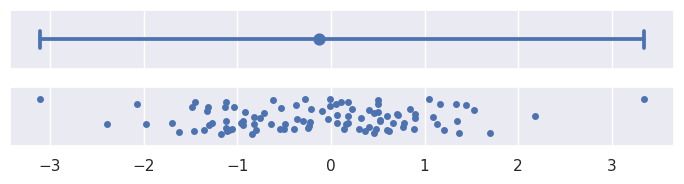
目前,回归估计的误差条不太灵活,仅显示通过ci=设置的大小的置信区间。这在未来可能会改变。
5.9.3. 误差线够用吗?¶
您应该始终问自己,是否最好使用仅显示汇总统计数据和误差线的绘图。在许多情况下,事实并非如此。
如果您对有关汇总的问题感兴趣(例如,各组之间的平均值是否不同或是否随时间增加),聚合可以降低绘图的复杂性并使这些推断更容易。但这样做会掩盖有关基础数据点的宝贵信息,例如分布的形状和异常值的存在。
在分析自己的数据时,不要满足于汇总统计数据。也要始终查看基础分布。有时,将两种观点结合到同一个图形中可能会有所帮助。许多 seaborn 函数可以帮助完成此任务,尤其是分类教程中讨论的函数。