23.4.3. 流网络分析¶
23.4.3.1. 向下连接¶
对于输入的栅格中的每个分区(例如,HUC转换为栅格),它标识具有最大区域8的点。这就是出口。将创建一个OGR文件。使用流向,每个出口向下移动指定数量的网格单元,这些网格单元由用户控制(默认值为1)。将点移动到的位置的ID作为iddown。创建了两个OGR文件,一个带有初始点,另一个带有移动点。两者都包含id、iddown和AreaD8。
23.4.3.1.1. 参数¶
标签 |
名字 |
类型 |
描述 |
D8流向 |
[栅格] |
一种用D8方法编码的流动方向网格,其中从一个单元格流出的所有流动都以最陡下降的方向流向一个相邻的单元格 |
|
D8贡献区 |
[栅格] |
给出贡献面积值的网格,表示每个单元的网格单元数(或权重之和),每个单元作为其自身贡献加上使用D8算法从上坡邻居流入的贡献。这通常是 “D8贡献区” 工具。 |
|
Watershed |
[栅格] |
流域网格由标准流域函数或河流汇流函数划定。其他流域(如HUC)栅格也可用作流域栅格。 |
|
网格单元向下游移动 |
[数] |
根据流向向下游移动的网格单元数。 |
23.4.3.1.2. 输出¶
标签 |
名字 |
类型 |
描述 |
Outlets |
[向量:点] |
一个点OGR文件,其中每个点都是从流域栅格创建的,每个分区的贡献面积最大。 |
|
移动的插座 |
[向量:点] |
一个点OGR文件,定义移动的感兴趣的出口。其中,每个出口使用流向向下移动指定数量的网格单元。 |
23.4.3.1.3. Python代码¶
算法ID : taudem:connectdown
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.2. D8极限上坡值¶
根据D8流模型从输入网格计算极端(最大或最小)上坡值。这最初是用于流栅格生成,以确定斜坡时间区域产品的阈值,从而产生最佳(根据下降分析)流网络。
如果使用可选出口点形状文件,则只有出口单元和它们的上坡单元(通过D8流模型)在要评估的域中。
默认情况下,工具检查边缘污染。这被定义为由于不计算域外的网格单元,可能低估结果的可能性。当排水系统从边界或高程值为“无数据”的区域向内时,就会发生这种情况。算法识别这一点,并为这些网格单元的结果报告“无数据”。常见的情况是,“无数据”值的条纹沿着在边界处进入域的流路径从边界向内延伸。这是期望的效果,表明这些网格单元的结果未知,因为它依赖于可用数据域之外的地形。如果您知道这不是问题或希望忽略这些问题,则可以关闭边缘污染检查,例如,如果DEM已沿流域轮廓裁剪。
23.4.3.2.1. 参数¶
标签 |
名字 |
类型 |
描述 |
D8流向网格 |
[栅格] |
一种由D8流向组成的网格,对于每个单元,该网格被定义为其八个相邻或对角线邻接的方向之一,具有最陡的向下坡度。此网格可以作为**“D8流向”工具的输出获得。 |
|
上坡值栅格 |
[栅格] |
这是选择最大或最小上坡值的值网格。最常用的值是根据跌落分析生成流纹时所需的坡度乘以面积积。 |
|
出口形状文件 可选的 |
[向量:点] |
定义感兴趣的出口的点形状文件。如果使用此输入文件,则工具将仅评估这些出口的上坡区域。 |
|
检查边缘污染 |
[布尔] 默认值:True |
指示工具是否应检查边缘污染的标志。 |
|
使用最大上坡值 |
[布尔] 默认值:True |
指示是否要计算最大或最小上坡值的标志。 |
23.4.3.2.2. 输出¶
标签 |
名字 |
类型 |
描述 |
极端上坡值栅格 |
[栅格] |
最大/最小上坡值的网格。 |
23.4.3.2.3. Python代码¶
算法ID : taudem:d8flowpathextremeup
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.3. 轨距分水岭¶
计算水位计流域网格。每个网格单元都用标识符(从列 id )直接排放而不通过任何其他计量器的计量器。
23.4.3.3.1. 参数¶
标签 |
名字 |
类型 |
描述 |
补充 D-infinity flow directions |
|
[栅格] |
基于D无穷大流方法的流向网格 |
D8流向网格 |
[栅格] |
一种由D8流向组成的网格,对于每个单元,该网格被定义为其八个相邻或对角线邻接的方向之一,具有最陡的向下坡度。此网格可以作为**“D8流向”工具的输出获得。 |
|
量规形状文件 |
[向量:点] |
一个点形状文件,用于定义将划分流域的仪表。此形状文件应具有一个列 |
23.4.3.3.2. 输出¶
标签 |
名字 |
类型 |
描述 |
标准流域网格 |
[栅格] |
网格标识每个计量分水岭。每个网格单元都用标识符(从列 |
|
下游标识符文件 |
[文件] |
提供流域下坡连接的文本文件 |
23.4.3.3.3. Python代码¶
算法ID : taudem:gagewatershed
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.4. 长度区域流源¶
创建一个指标网格(1,0),用于计算 A >= (M)(Ly) 基于上坡路径长度、D8贡献区域网格输入和参数 M 和 y . 此网格表示可能的流源网格单元。这是哈克定律中的一种实验方法,具有理论基础,该定律规定了流 L ~ A 0.6 . 但对于平行流的山坡 L ~ A . 所以从山坡到溪流的过渡可以用 L ~ A 0.8 建议将网格单元识别为流单元,如果 A > M (L (1/0.8)) .
23.4.3.4.1. 参数¶
标签 |
名字 |
类型 |
描述 |
长度网格 |
[栅格] |
每个单元格最大上坡长度的网格。这是根据从最远的单元流向每个单元的流动路径长度计算的。测量单元中心之间的长度时,要考虑单元大小以及方向是相邻的还是对角线的。是这个长度( |
|
贡献区域网格 |
[栅格] |
使用D8算法计算的每个单元的贡献面积值网格。一个单元的贡献面积是它自己的贡献加上所有向上倾斜的邻居对它的贡献的总和,用若干单元来衡量。此网格通常作为**“D8贡献区域”**工具的输出获得。在这个工具中,它是贡献区域( |
|
Threshold |
[数] 默认值:0.03 |
乘数阈值( |
|
Exponent |
[数] 默认值:1.3 |
指数(指数) |
23.4.3.4.2. 输出¶
标签 |
名字 |
类型 |
描述 |
流源网格 |
[栅格] |
一种指标网格(1,0),根据最大上坡路径长度、D8贡献区域网格输入和参数计算a>=(m)(l^y)。 |
23.4.3.4.3. Python代码¶
算法ID : taudem:lengtharea
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.5. 将出口移至溪流¶
从流栅格网格中移动不与流单元对齐的出口点,沿D8流方向向下移动,直到遇到流栅格单元,检查网格单元的“最大距离”数量,或流路径退出域(即D8流方向遇到“无数据”值)。输出文件是一个新的出口形状文件,如果可能,每个点都已移动到与流栅格网格一致的位置。“dist_moved”字段将添加到新的出口形状文件中,以指示对每个点所做的更改。流单元上已经存在的点不会被移动,它们的“dist_moved”字段被分配一个值0。最初不在流单元上的点通过沿D8流方向向下滑动来移动,直到出现以下情况之一:a)在遍历网格单元的“最大距离”数之前遇到流栅格网格单元。在这种情况下,移动点,并为“dist_moved”字段分配一个值,指示移动点的网格单元数。b)超过网格单元的“最大值”,或c)遍历结束后离开域(即遇到“无数据”D8流方向值)。在这种情况下,点不会移动,“dist_moved”字段的值为-1。
23.4.3.5.1. 参数¶
标签 |
名字 |
类型 |
描述 |
D8流向网格 |
[栅格] |
一种由D8流向组成的网格,对于每个单元,该网格被定义为其八个相邻或对角线邻接的方向之一,具有最陡的向下坡度。此网格可以作为**“D8流向”工具的输出获得。 |
|
流栅格 |
[栅格] |
此输出是指示流位置的指示器网格(1,0),每个流单元的值为1,其余单元的值为0。此文件由**“流网络分析”**工具集中的几个不同工具生成。 |
|
出口形状文件 |
[向量:点] |
定义兴趣点或出口的点形状文件,理想情况下应位于流上,但可能不完全位于流上,因为形状文件点位置可能没有相对于流栅格网格准确注册。 |
|
要遍历的最大网格单元数 |
[数] 默认值:50 |
此输入参数是输入出口形状文件中的点在保存到输出出口形状文件之前将移动的最大网格单元数。 |
23.4.3.5.2. 输出¶
标签 |
名字 |
类型 |
描述 |
输出出口形状文件 |
[向量:点] |
定义感兴趣点或出口的点形状文件。对于输入输出形状文件中的每个点,此文件中都有一个点。如果原点位于流上,则不会移动该点。如果原点不在溪流上,则根据D8流向向下移动该点,直到到达溪流或达到最大距离。此文件中添加了一个附加字段“distu moved”,即移动点的单元格数。如果单元格最初位于流上,则此字段为0;如果由于在最大距离内没有流而没有移动单元格,则此字段为1;如果移动单元格,则此字段为正值。 |
23.4.3.5.3. Python代码¶
算法ID : taudem:moveoutletstostreams
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.6. 普鲁道格拉斯¶
根据Peuker和Douglas算法创建向上弯曲网格单元的指示网格(1,0)。
使用此工具,DEM首先由一个中心、边和对角线处具有权重的内核平滑。Peuker和Douglas(1975)方法(同样在Band,1986中解释)随后用于识别向上弯曲的网格单元。此技术标记整个网格,然后在4个网格单元的每个象限中检查一次,并取消标记最高的网格。其余标记的单元格被视为“向上弯曲”,并且在查看时类似于一个通道网络。这种原信道网络通常缺乏连通性,需要细化,这一问题已由Band(1986)详细讨论。
23.4.3.6.1. 参数¶
标签 |
名字 |
类型 |
描述 |
高程网格 |
[栅格] |
高程值网格。这通常是**“PIT REMOVE”**工具的输出,在这种情况下,它是删除PIT后的高程。 |
|
中心平滑权重 |
[数] 默认值:0.4 |
在工具识别向上弯曲的网格单元之前,内核用来平滑DEM的中心权重参数。 |
|
侧平滑权重 |
[数] 默认值:0.1 |
在工具识别向上弯曲的网格单元之前,内核用来平滑DEM的边权参数。 |
|
对角线平滑权重 |
[数] 默认值:0.05 |
在工具识别向上弯曲的网格单元之前,内核用来平滑DEM的对角权重参数。 |
23.4.3.6.2. 输出¶
标签 |
名字 |
类型 |
描述 |
流源网格 |
[栅格] |
根据Peuker和Douglas算法,向上弯曲网格单元的指示网格(1,0),如果查看,类似于通道网络。这种原信道网络通常缺乏连通性,需要细化,这一问题已由Band(1986)详细讨论。 |
23.4.3.6.3. Python代码¶
算法ID : taudem:peukerdouglas
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.6.4. 另见¶
Band,L.E.,(1986),“数字高程模型流域地形划分”,水资源研究,22(1):15-24.
Peuker,T.K.和D.H.Douglas,(1975),“通过离散地形高程数据的局部并行处理检测表面特定点”,计算机。图形图像处理,4:375-387。
23.4.3.7. 佩克道格拉斯河¶
结合“Peuker-Douglas”、“D8贡献区域”、“河流落差分析”和“河流阈值定义”工具的功能,以便使用基于DEM曲率的方法生成河流所在的河流指示网格(1,0)。该方法首先对DEM进行核平滑处理,核的中心、边和对角线上各有权重。然后使用Peuker和Douglas(1975)方法(也在Band,1986中解释)来识别向上弯曲的网格单元。该技术标记整个网格,然后在一次通过中检查4个网格单元的每个象限,并取消对最高网格单元的标记。剩下的标记细胞被认为是“向上弯曲的”,当观察时,类似于一个通道网络。这种原始信道网络有时缺乏连通性,和/或需要细化,Band(1986)对此进行了详细讨论。这些网格单元的细化和连接是通过仅使用这些向上弯曲的单元来计算D8贡献面积来实现的。然后使用这些单元数量的累积阈值来映射信道网络,其中该阈值可由用户选择性地设置,或通过跌落分析来确定。
如果使用跌落分析,则不提供累积阈值的值,而是通过使用参数“number”中的步数搜索跌落分析参数“Lowest”和“Highest”之间的范围来确定累积阈值。关于液滴分析背后的科学,参见Tarboton等人(1991、1992)和Tarboton和Ames(2001)。选择的累积阈值是t统计量的绝对值小于2时的最小值。这将写入drop analysis table文本文件。只有在指定了出口的情况下,才能进行跌落分析,因为如果分析整个网格域,随着阈值的变化,从边缘排出的较短流可能不符合阈值标准,并且被排除在分析之外。这使得定义排水密度成了问题,而且比较不同领域的统计数据有点不一致。
23.4.3.7.1. 参数¶
23.4.3.7.2. 输出¶
标签 |
名字 |
类型 |
描述 |
流源 |
[栅格] |
根据Peuker和Douglas算法,向上弯曲网格单元的指示网格(1,0),如果查看,类似于通道网络。这种原信道网络通常缺乏连通性,需要细化,这一问题已由Band(1986)详细讨论。 |
23.4.3.7.3. Python代码¶
算法ID : taudem:peukerdouglasstreamdef
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.8. 斜坡区组合¶
创建坡度区域值网格= (Sm) (An) 基于坡度和特定集水区的网格输入和参数 m 和 n . 此工具旨在用作斜坡区域流栅格描绘方法的一部分。
23.4.3.8.1. 参数¶
标签 |
名字 |
类型 |
描述 |
坡度网格 |
[栅格] |
此输入是一个坡度值网格。此网格可从**“D-无限流向”**工具获得。 |
|
贡献区域网格 |
[栅格] |
一个网格,给出每个单元的特定集水区面积,作为其自身的贡献(网格单元长度或权重的总和),加上从上坡邻居向其排水的比例贡献。此网格通常从**“D-无限贡献区域”**工具中获得。 |
|
斜率指数 |
[数] 默认值:2 |
坡度指数( |
|
面积指数 |
[数] 默认值:1 |
面积指数( |
23.4.3.8.2. 输出¶
标签 |
名字 |
类型 |
描述 |
坡地网格 |
[栅格] |
坡度面积值网格= |
23.4.3.8.3. Python代码¶
算法ID : taudem:slopearea
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.9. 坡面流定义¶
创建坡度区域值网格= (Sm) (An) 基于坡度和特定集水区的网格输入和参数 m 和 n . 此工具旨在用作斜坡区域流栅格描绘方法的一部分。
23.4.3.9.1. 参数¶
标签 |
名字 |
类型 |
描述 |
D8流向 |
[栅格] |
||
D-infinity Contributing Area |
[栅格] |
一个网格,给出每个单元的特定集水区面积,作为其自身的贡献(网格单元长度或权重的总和),加上从上坡邻居向其排水的比例贡献。此网格通常从**“D-无限贡献区域”**工具中获得。 |
|
Slope |
[栅格] |
此输入是一个坡度值网格。此网格可从**“D-无限流向”**工具获得。 |
|
遮罩网格 |
[栅格] |
||
Outlets |
[向量:点] |
||
Pit-filled grid for drop analysis |
[栅格] |
||
D8跌落分析的贡献区域 |
[栅格] |
||
斜率指数 |
[数] 默认值:2 |
坡度指数( |
|
面积指数 |
[数] 默认值:1 |
面积指数( |
|
累积阈值 |
[数] |
||
最小阈值 |
[数] |
||
最大阈值 |
[数] |
||
丢弃阈值数 |
[数] |
||
阈值步长类型 |
[枚举] 默认值:0 |
选项:
|
|
检查边缘污染 |
[布尔] |
||
通过下拉分析选择阈值 |
[布尔] |
23.4.3.9.2. 输出¶
标签 |
名字 |
类型 |
描述 |
流栅格 |
[栅格] |
||
斜坡区 |
[栅格] |
坡度面积值网格= |
|
最大上坡 |
[栅格] |
||
跌落分析 |
[文件] |
23.4.3.9.3. Python代码¶
算法ID : taudem:slopeareastreamdef
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.10. 按阈值的流定义¶
在任何网格上操作并输出一个指示器(1,0)网格,标识输入值>=阈值的单元格。标准用法是使用累积源区域栅格作为输入栅格,生成流栅格栅格作为输出。如果使用可选的输入掩码网格,它会将要计算的域限制为掩码值大于等于0的单元格。当您使用D无穷大面积栅格时 (*sca )作为遮罩网格,它起到边缘污染遮罩的作用。阈值逻辑是:
src = ((ssa >= thresh) & (mask >= s0)) ? 1:0
23.4.3.10.1. 参数¶
标签 |
名字 |
类型 |
描述 |
累积流源网格 |
[栅格] |
这个网格名义上积累了流域的一些特征或特征组合。具体特征因使用的流网络栅格算法而异。该网格需要具有网格单元值沿d8流向单调增加下坡的特性,以便生成连续的流网络。虽然此网格通常来自于累积,但其他来源(如最大上坡函数)也会生成合适的网格。 |
|
Threshold |
[数] 默认值:100 |
将此参数与累积流源网格中的值进行比较( |
|
遮罩网格 可选的 |
[栅格] |
此可选输入是用于屏蔽感兴趣域的网格,只有当此网格大于等于0时才提供输出。此输入的一个常见用途是使用D-Infinity贡献区域网格作为遮罩,以便将所描绘的流网络限制到D-Infinity贡献区域可用的区域,从而复制边缘污染遮罩的功能。 |
23.4.3.10.2. 输出¶
标签 |
名字 |
类型 |
描述 |
流栅格 |
[栅格] |
这是一个指示网格(1,0),用于指示流的位置,每个流单元的值为1,其余单元的值为0。 |
23.4.3.10.3. Python代码¶
算法ID : taudem:threshold
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.11. 流定义与落差分析¶
结合了“流滴分析”工具和“阈值流定义”工具的功能。它将一系列阈值(由输入参数确定)应用于输入累积流源网格 (ssa )并将结果输出到stream drop statistics表中 (drp.txt ). 然后它输出一个流栅格网格,它是流单元的指示符(1,0)网格。流单元被定义为累积流源值大于等于根据流丢弃统计确定的最佳阈值的那些单元。有一个包含掩码输入的选项,用于复制使用 *sca 文件作为边缘污染遮罩。阈值逻辑应为: src = ((ssa >= thresh) & (mask >=0)) ? 1:0
23.4.3.11.1. 参数¶
23.4.3.11.2. 输出¶
23.4.3.11.3. Python代码¶
算法ID : taudem:streamdefdropanalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.12. 流滴分析¶
将一系列阈值(根据输入参数确定)应用于输入累计流源网格( *ssa )并将结果输出到 *drp.txt 将流删除统计信息表归档。该功能旨在帮助确定用于描述河流的地貌客观阈值。Drop Analysis尝试通过评估流网络的阈值范围并检查生成的Strahler流的常量Drop属性来自动选择正确的阈值。基本上,它提出了一个问题:使用t检验,一阶流的平均流降与高阶流的平均流降在统计上是否不同?流落差是从流的开始到结束的高度差,定义为具有相同流顺序的链接序列。如果t检验显示有显著差异,则流网络不遵守此“定律”,因此需要选择更大的阈值。t检验未显示显著差异的最小阈值给出了符合地貌学中恒定流降“定律”的最高分辨率流网络,并且是为DEM中的流的“目标”或自动映射选择的阈值。该功能可用于河网栅格的开发,其中累积的河网源网格中的准确流域特征根据用于确定河网栅格的方法而变化。
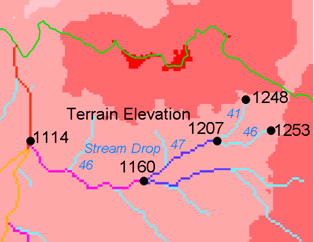
Broscoe(1959)确定了恒定流降“定律”。有关使用此方法确定河流描述阈值的背后的科学,请参见Tarboton等人。(1991年、1992年)、塔波顿和埃姆斯(2001年)。
23.4.3.12.1. 参数¶
标签 |
名字 |
类型 |
描述 |
D8贡献区域网格 |
[栅格] |
使用D8算法计算的每个单元的贡献面积值网格。一个单元的贡献面积是它自己贡献的总和,加上所有向上倾斜的相邻单元对它的贡献,测量为若干单元或重量负荷的总和。此网格可以作为**“D8贡献区域”**工具的输出获得。该网格用于评估水滴表中报告的排水密度。 |
|
D8流向网格 |
[栅格] |
一种由D8流向组成的网格,对于每个单元,该网格被定义为其八个相邻或对角线邻接的方向之一,具有最陡的向下坡度。此网格可以作为**“D8流向”工具的输出获得。 |
|
坑填高程网格 |
[栅格] |
高程值网格。这通常是**“PIT REMOVE”**工具的输出,在这种情况下,它是删除PIT后的高程。 |
|
累积流源网格 |
[栅格] |
该网格必须沿下坡d8流向单调增加。它与一系列阈值进行比较,以确定流的开始。它通常是通过使用**“D8贡献区”工具或使用“D8极端流径”**工具的最大选项,积累流域的某些特征或特征组合而产生的。具体的方法取决于所使用的算法。 |
|
出口形状文件 |
[向量:点] |
一个点形状文件,定义在其上游执行下降分析的出口。 |
|
最小阈值 |
[数] 默认值:5 |
此参数是使用放置分析搜索可能阈值的范围的最低端。该方法寻找t统计量绝对值小于2的范围内的最小阈值。关于液滴分析背后的科学,见Tarboton等人。(1991年、1992年)、塔波顿和埃姆斯(2001年)。 |
|
最大阈值 |
[数] 默认值:500 |
此参数是使用放置分析搜索可能阈值的范围的最高端。该方法寻找t统计量绝对值小于2的范围内的最小阈值。关于液滴分析背后的科学,见Tarboton等人。(1991年、1992年)、塔波顿和埃姆斯(2001年)。 |
|
阈值数目 |
[数] 默认值:10 |
该参数是使用Drop Analysis查找可能的阈值时,将搜索范围划分为的步骤数。该方法寻找t统计量绝对值小于2的范围内的最小阈值。关于液滴分析背后的科学,见Tarboton等人。(1991年、1992年)、塔波顿和埃姆斯(2001年)。 |
|
阈值间距 |
[枚举] 默认值:0 |
此参数指示在使用压降分析查找可能的阈值时应使用对数间距还是线性间距。 选项:
|
23.4.3.12.2. 输出¶
标签 |
名字 |
类型 |
描述 |
D-Infinity Drop to Stream Grid |
[文件] |
这是一个逗号分隔的文本文件,具有以下标题行: Threshold,DrainDen,NoFirstOrd,NoHighOrd,MeanDFirstOrd,MeanDHighOrd,StdDevFirstOrd,StdDevHighOrd,T
然后,该文件包含所检查的每个阈值的一行数据,然后包含指示最佳阈值的摘要行。该方法寻找t统计量绝对值小于2的范围内的最小阈值。关于液滴分析背后的科学,见Tarboton等人。(1991年、1992年)、塔波顿和埃姆斯(2001年)。 |
23.4.3.12.3. Python代码¶
算法ID : taudem:dropanalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。
23.4.3.12.4. 另见¶
Broscoe,A.J.,(1959年),“小流域纵向河流剖面的定量分析”,海军研究办公室,项目编号389-042,技术报告编号18,纽约哥伦比亚大学地质系。
Tarboton,D.G.,R.L.Bras和I.Rodriguez Iturbe,(1991),“从数字高程数据中提取河道网络”,水文过程,5(1):81-100.
Tarboton,D.G.,R.L.Bras和I.Rodriguez Iturbe,(1992),“排水密度的物理基础”,地貌学,5(1/2):59-76.
Tarboton,D.G.和D.P.Ames,(2001年),“利用数字高程数据绘制水流网络的进展”,世界水和环境资源大会,佛罗里达州奥兰多,5月20日至24日,ASCE,https://www.researchgate.net/publication/2329568根据数字高程数据推进流量网络的映射。
23.4.3.13. 河段和流域¶
此工具从流栅格网格生成矢量网络和形状文件。流方向网格用于沿流栅格连接流路径。计算每个流段的Strahler顺序。向每个河流段(河段)排水的子流域也用与河段形状文件中的wsno(流域编号)属性相对应的值标识符进行了描述和标记。
该工具根据Strahler排序系统对流网络进行排序。没有任何其他流流入它们的流是顺序1。当两条不同顺序的河段汇合时,下游河段的顺序为最大汇入河段的顺序。当两条等长的河段连接时,下游河段的连接顺序增加1。当两个以上的到达连接时,下游到达顺序计算为最高到达顺序或第二最高到达顺序+1的最大值。这将通用定义归纳为两个以上在一个点上达到连接的情况。网络拓扑连通性存储在流网络树文件中,网络中每个网格单元的坐标和属性存储在网络坐标文件中。
流栅格网格用作流网络的源,流方向网格用于跟踪流网络内的连接。高程和贡献面积用于确定网络坐标文件中的高程和贡献面积属性。出口形状文件中的点用于对河段进行逻辑分割,以便于代表监测点上游和下游的流域。程序使用outlets shapefile中的属性字段“id”作为网络树文件中的标识符。然后,该工具将网络树中的文本文件矢量网络表示转换为形状文件,并将文件坐标转换为形状文件。还评估了其他属性。该程序有一个选项,通过将流向河网的整个区域表示为输出流域网格中的单个值,来描绘单个流域。
23.4.3.13.1. 参数¶
标签 |
名字 |
类型 |
描述 |
坑填高程网格 |
[栅格] |
高程值网格。这通常是**“PIT REMOVE”**工具的输出,在这种情况下,它是删除PIT后的高程。 |
|
D8流向网格 |
[栅格] |
一种由D8流向组成的网格,对于每个单元,该网格被定义为其八个相邻或对角线邻接的方向之一,具有最陡的向下坡度。此网格可以作为**“D8流向”工具的输出获得。 |
|
D8排水区 |
[栅格] |
根据每个单元的网格单元数(或权重总和)给出贡献面积值的网格,该值被视为自己的贡献,加上使用d8算法从上坡邻居那里吸干的贡献。这通常是**“D8贡献区域”**工具的输出,用于确定网络坐标文件中的贡献区域属性。 |
|
流栅格 |
[栅格] |
一种指示流的网格,通过在流上使用1的网格单元值和在流上使用0的网格单元值来指示流。一些**“流网络分析”**工具产生了这种类型的网格。流栅格网格用作流网络的源。 |
|
将Shapefile作为网络节点 可选的 |
[向量:点] |
定义感兴趣点的点形状文件。如果使用此文件,该工具将仅解除这些出口上游的流网络。此外,Outlets Shapefile中的点用于逻辑分割河流河段,以便于表示监测点上游和下游的流域。此工具要求Outlets Shapefile中有一个整数属性字段“id”,因为“id”值在网络树文件中用作标识符。 |
|
划定单一流域 |
[布尔] 默认值:True |
此选项使工具通过将流向河网的整个区域表示为输出流域网格中的单个值来描绘单个流域。否则,将为每个河段划定单独的流域。默认是 False (单独的分水岭)。 |
23.4.3.13.2. 输出¶
标签 |
名字 |
类型 |
描述 |
流序网格 |
[栅格] |
流顺序网格具有根据Strahler顺序系统排序的流的单元格值。Strahler排序系统将order 1流定义为流到达时没有任何其他的流排入它们。当两条不同顺序的河段汇合时,下游河段的顺序为最大汇入河段的顺序。当两条等长的河段连接时,下游河段的连接顺序增加1。当两个以上的到达连接时,下游到达顺序计算为最高到达顺序或第二最高到达顺序+1的最大值。这将通用定义归纳为两个以上的流路径在一个点上到达连接的情况。 |
|
流域网格 |
[栅格] |
该输出网格用唯一的ID号标识每个河段流域,或者在勾选了“描绘单个流域”选项的情况下,用单个ID标识流向河网的整个区域。 |
|
河段形状文件 |
[向量:线] |
此输出是一个折线形状文件,提供流网络中的链接。属性表中的列有:
|
|
网络连接树 |
[文件] |
此输出是一个文本文件,详细说明网络拓扑连接存储在流网络树文件中。列如下:
|
|
网络坐标 |
[文件] |
此输出是一个文本文件,包含流网络上点的坐标和属性。列如下:
|
23.4.3.13.3. Python代码¶
算法ID : taudem:streamnet
import processing
processing.run("algorithm_id", {parameter_dictionary})
这个 算法id 将鼠标悬停在处理工具箱中的算法上时显示。这个 参数字典 提供参数名称和值。看到了吗 使用控制台中的处理算法 有关如何从Python控制台运行处理算法的详细信息。