In [1]: import pandas as pd
- Titanic data
本教程使用存储为CSV的泰坦尼克号数据集。数据由以下数据列组成:
PassengerID:每个乘客的ID。
生还:表示乘客是否生还。
0是的而且1不是的。Pclass:3个票类中的一个:类
1,班级2和班级3。姓名:乘客姓名。
性别:乘客性别。
年龄:乘客的年龄,以年为单位。
SibSp:船上兄弟姐妹或配偶的数量。
Parch:船上父母或孩子的人数。
车票:旅客车票号码。
票价:标明票价。
客舱:客舱人数。
已装船:装船港。
In [2]: titanic = pd.read_csv("data/titanic.csv") In [3]: titanic.head() Out[3]: PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
-
Air quality data
本教程使用的空气质量数据 \(NO_2\) 和小于2.5微米的颗粒物,由 OpenAQ 并使用 py-openaq 包裹。这个
air_quality_long.csv数据集提供 \(NO_2\) 和 \(PM_{{25}}\) 测量站的值 FR04014 , BETR801 和 伦敦威斯敏斯特 分别在巴黎、安特卫普和伦敦。空气质量数据集包含以下列:
城市:使用传感器的城市,巴黎、安特卫普或伦敦
国家/地区:使用传感器的国家/地区,FR、BE或GB
位置:传感器的ID,或者 FR04014 , BETR801 或 伦敦威斯敏斯特
参数:传感器测量的参数,可以是 \(NO_2\) 或颗粒物
值:测量值
单位:测量参数的单位,在本例中为“微克/米”。
和索引中的
DataFrame是datetime,度量的日期时间。To raw data备注
空气质量数据是在所谓的 长格式 数据表示法,每个观察值位于数据表的单独行中,每个变量位于数据表的单独列中。长/窄格式也称为 tidy data format 。
In [4]: air_quality = pd.read_csv( ...: "data/air_quality_long.csv", index_col="date.utc", parse_dates=True ...: ) ...: In [5]: air_quality.head() Out[5]: city country location parameter value unit date.utc 2019-06-18 06:00:00+00:00 Antwerpen BE BETR801 pm25 18.0 µg/m³ 2019-06-17 08:00:00+00:00 Antwerpen BE BETR801 pm25 6.5 µg/m³ 2019-06-17 07:00:00+00:00 Antwerpen BE BETR801 pm25 18.5 µg/m³ 2019-06-17 06:00:00+00:00 Antwerpen BE BETR801 pm25 16.0 µg/m³ 2019-06-17 05:00:00+00:00 Antwerpen BE BETR801 pm25 7.5 µg/m³
如何重塑表格布局?#
对表行进行排序#
我想根据乘客的年龄对泰坦尼克号的数据进行分类。
In [6]: titanic.sort_values(by="Age").head() Out[6]: PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 803 804 1 3 Thomas, Master. Assad Alexander male 0.42 0 1 2625 8.5167 NaN C 755 756 1 2 Hamalainen, Master. Viljo male 0.67 1 1 250649 14.5000 NaN S 644 645 1 3 Baclini, Miss. Eugenie female 0.75 2 1 2666 19.2583 NaN C 469 470 1 3 Baclini, Miss. Helene Barbara female 0.75 2 1 2666 19.2583 NaN C 78 79 1 2 Caldwell, Master. Alden Gates male 0.83 0 2 248738 29.0000 NaN S
我想把泰坦尼克号的数据按照船舱等级和年龄降序排列。
In [7]: titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head() Out[7]: PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 851 852 0 3 Svensson, Mr. Johan male 74.0 0 0 347060 7.7750 NaN S 116 117 0 3 Connors, Mr. Patrick male 70.5 0 0 370369 7.7500 NaN Q 280 281 0 3 Duane, Mr. Frank male 65.0 0 0 336439 7.7500 NaN Q 483 484 1 3 Turkula, Mrs. (Hedwig) female 63.0 0 0 4134 9.5875 NaN S 326 327 0 3 Nysveen, Mr. Johan Hansen male 61.0 0 0 345364 6.2375 NaN S
使用
DataFrame.sort_values()表中的行将根据定义的列进行排序。索引将遵循行顺序。
上的用户指南部分提供了有关表排序的更多详细信息 sorting data 。
长到宽的表格格式#
让我们使用空气质量数据集的一小部分。我们专注于 \(NO_2\) 数据,并且只使用每个位置的前两个测量值(即,每个组的头部)。该数据子集将被称为 no2_subset 。
# filter for no2 data only
In [8]: no2 = air_quality[air_quality["parameter"] == "no2"]
# use 2 measurements (head) for each location (groupby)
In [9]: no2_subset = no2.sort_index().groupby(["location"]).head(2)
In [10]: no2_subset
Out[10]:
city country location parameter value unit
date.utc
2019-04-09 01:00:00+00:00 Antwerpen BE BETR801 no2 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR FR04014 no2 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB London Westminster no2 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE BETR801 no2 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR FR04014 no2 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB London Westminster no2 67.0 µg/m³

我想要三个站点的值作为彼此相邻的单独列。
In [11]: no2_subset.pivot(columns="location", values="value") Out[11]: location BETR801 FR04014 London Westminster date.utc 2019-04-09 01:00:00+00:00 22.5 24.4 NaN 2019-04-09 02:00:00+00:00 53.5 27.4 67.0 2019-04-09 03:00:00+00:00 NaN NaN 67.0
这个
pivot()函数纯粹是对数据进行整形:每个索引/列组合都需要一个值。
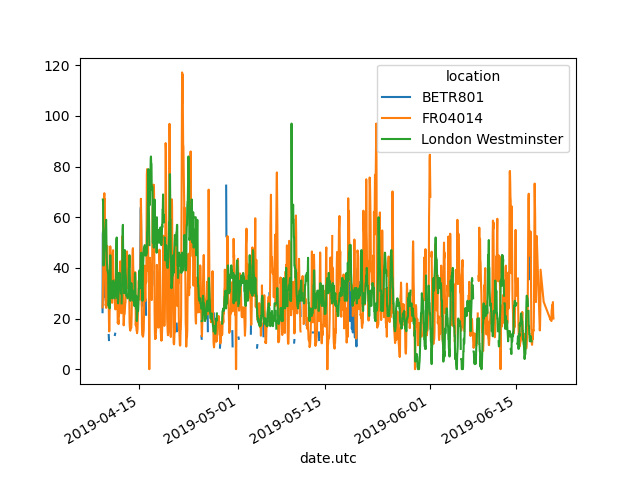
由于Pandas支持绘制多个列(请参见 plotting tutorial )开箱即用,从 long 至 wide 表格格式允许同时绘制不同的时间序列:
In [12]: no2.head()
Out[12]:
city country location parameter value unit
date.utc
2019-06-21 00:00:00+00:00 Paris FR FR04014 no2 20.0 µg/m³
2019-06-20 23:00:00+00:00 Paris FR FR04014 no2 21.8 µg/m³
2019-06-20 22:00:00+00:00 Paris FR FR04014 no2 26.5 µg/m³
2019-06-20 21:00:00+00:00 Paris FR FR04014 no2 24.9 µg/m³
2019-06-20 20:00:00+00:00 Paris FR FR04014 no2 21.4 µg/m³
In [13]: no2.pivot(columns="location", values="value").plot()
Out[13]: <AxesSubplot:xlabel='date.utc'>
备注
当 index 参数,则使用现有索引(行标签)。
有关以下内容的更多信息 pivot() ,请参阅上的用户指南部分 pivoting DataFrame objects 。
数据透视表#

我想要平均浓度 \(NO_2\) 和 \(PM_{{2.5}}\) 以表格的形式显示在每个站点中。
In [14]: air_quality.pivot_table( ....: values="value", index="location", columns="parameter", aggfunc="mean" ....: ) ....: Out[14]: parameter no2 pm25 location BETR801 26.950920 23.169492 FR04014 29.374284 NaN London Westminster 29.740050 13.443568
在.的情况下
pivot(),数据只是重新排列。当需要聚集多个值(在该特定情况下,不同时间步长上的值)时,pivot_table()可以使用,提供关于如何组合这些值的聚合函数(例如,均值)。
透视表是电子表格软件中的一个众所周知的概念。如果对每个变量的行/列边距(小计)感兴趣,请设置 margins 参数设置为 True :
In [15]: air_quality.pivot_table(
....: values="value",
....: index="location",
....: columns="parameter",
....: aggfunc="mean",
....: margins=True,
....: )
....:
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743
有关以下内容的更多信息 pivot_table() ,请参阅上的用户指南部分 pivot tables 。
备注
如果你想知道的话, pivot_table() 确实直接与 groupby() 。通过对两者进行分组可以得出相同的结果 parameter 和 location :
air_quality.groupby(["parameter", "location"]).mean()
看一看 groupby() 结合使用 unstack() 在上的用户指南部分 combining stats and groupby 。
从宽到长格式#
再次从上一节中创建的宽格式表开始,我们向 DataFrame 使用 reset_index() 。
In [16]: no2_pivoted = no2.pivot(columns="location", values="value").reset_index()
In [17]: no2_pivoted.head()
Out[17]:
location date.utc BETR801 FR04014 London Westminster
0 2019-04-09 01:00:00+00:00 22.5 24.4 NaN
1 2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2 2019-04-09 03:00:00+00:00 54.5 34.2 67.0
3 2019-04-09 04:00:00+00:00 34.5 48.5 41.0
4 2019-04-09 05:00:00+00:00 46.5 59.5 41.0

我想收集所有的空气质量 \(NO_2\) 单列测量(长格式)。
In [18]: no_2 = no2_pivoted.melt(id_vars="date.utc") In [19]: no_2.head() Out[19]: date.utc location value 0 2019-04-09 01:00:00+00:00 BETR801 22.5 1 2019-04-09 02:00:00+00:00 BETR801 53.5 2 2019-04-09 03:00:00+00:00 BETR801 54.5 3 2019-04-09 04:00:00+00:00 BETR801 34.5 4 2019-04-09 05:00:00+00:00 BETR801 46.5
这个
pandas.melt()对象上的方法DataFrame将数据表从宽格式转换为长格式。列标题将成为新创建的列中的变量名。
解决方案是关于如何应用的简短版本 pandas.melt() 。该方法将 melt 中未提及的所有列 id_vars 一起放到两列中:一列包含列标题名称,另一列包含值本身。后一列缺省情况下获取名称 value 。
传递给 pandas.melt() 可以更详细地定义:
In [20]: no_2 = no2_pivoted.melt(
....: id_vars="date.utc",
....: value_vars=["BETR801", "FR04014", "London Westminster"],
....: value_name="NO_2",
....: var_name="id_location",
....: )
....:
In [21]: no_2.head()
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
其他参数具有以下效果:
value_vars定义要将哪些列 melt 同舟共济value_nameprovides a custom column name for the values column instead of the default column namevaluevar_nameprovides a custom column name for the column collecting the column header names. Otherwise it takes the index name or a defaultvariable
因此,这些争论 value_name 和 var_name 只是用户为两个生成的列定义的名称。要融化的柱由 id_vars 和 value_vars 。
使用将宽格式转换为长格式 pandas.melt() 上的用户指南部分对此进行了说明 reshaping by melt 。
REMEMBER
支持按一列或多列排序
sort_values。这个
pivot功能是纯粹的数据重组,pivot_table支持聚合。的反面
pivot(长至宽格式)是melt(宽到长格式)。
有关以下页面的用户指南中提供了完整的概述 reshaping and pivoting 。