滤器¶
本章的目的是帮助开发人员创建他们自己的过滤器(进程对象)。本章分为四大部分。术语的初始定义之后是筛选器创建过程的概述。接下来,我们将讨论数据流。为了编写正确的过滤器,必须了解在ITK中传输数据的方式。最后,关于多线程的一节描述了要利用共享内存并行处理必须做些什么。
术语¶
以下是下面讨论的一些基本术语。第二章 系统概述 提供了更多背景信息。
- 这个 data processing pipeline 是一个有向图 process 和 data objects 。管道输入、运算和输出数据。
- A filter ,或 process object 具有一个或多个输入以及一个或多个输出。
- A source 或源进程对象,启动数据处理流水线,并具有一个或多个输出。
- A mapper 或映射器进程对象终止数据处理管道。映射器具有一个或多个输出,并且可以将数据写入磁盘、与显示系统接口或与任何其他系统接口。
- A data object 表示并提供对数据的访问。在ITK中,数据对象(ITK类 itk::DataObject )的类型通常是 otb::Image 或 itk::Mesh 。
- A region (ITK类 itk::Region )表示整个数据集的一部分或子集。
- 一个 image region (ITK类 itk::ImageRegion )表示数据的结构化部分。ImageRegion是使用 itk::Index 和 itk::Size 班级
- A mesh region (ITK类 itk::MeshRegion )表示数据的非结构化部分。
- 这个 LargestPossibleRegion 是理论上可以代表整个数据集的单个、最大的部分(区域)。LargestPossibleRegion在系统中用作可能的最大数据大小的度量值。
- 这个 BufferedRegion 是一个连续的内存块,其大小小于或等于LargestPossibleRegion。缓冲区是过滤器为保存其输出而实际分配的区域。
- 这个 RequestedRegion 是需要筛选器生成的数据集的一部分。RequestedRegion的大小小于或等于BufferedRegion。由于性能原因,RequestedRegion的大小可能不同于BufferedRegion。RequestedRegion可以由用户设置,也可以由只需要部分数据的应用程序设置。
- 这个 modified time (由ITK类表示 itk::TimeStamp )是一个单调递增的整数值,用于描述上次修改对象时的时间点。
- Downstream 是数据流的方向,从源到映射器。
- Upstream 是下游的对立面,从映射者到源头。
- 这个 pipeline modified time 对于特定数据对象是所有上游数据对象和过程对象的最大修改时间。
- 这一术语 information 指的是表征数据的元数据。例如,索引和维度是表征图像区域的信息。
过滤器创建概述¶
过滤器是根据它们输入的数据类型(如果有)和输出的数据类型(如果有)来定义的。编写ITK过滤器的关键是识别输入和输出的数量和类型。这样做之后,通常会有超类通过类派生来简化这项任务。例如,ITK中的大多数滤镜将单个图像作为输入,并在输出时生成单个图像。超级阶级 itk::ImageToImageFilter 是一个方便的类,它提供了此类筛选器所需的大部分功能。
新滤镜的一些常见基类包括:
ImageToImageFilter:分割算法最常用的滤波器基。获取图像并生成新图像,默认情况下,新图像的尺寸相同。超覆GenerateOutputInformation生产不同大小的产品。UnaryFunctorImageFilter:定义将函数应用于图像的滤镜时使用。BinaryFunctorImageFilter:定义对两个图像应用操作的滤镜时使用。ImageFunction:可以应用于图像的函数器,计算 f(x) 在图像中的每个点。MeshToMeshFilter:变换网格的滤镜,例如细分、减少多边形等。LightObject:不适合类层次结构中其他位置的筛选器的抽象基。对于“计算器”过滤器也很有用;接收器筛选器,该筛选器接受输入并计算使用Get()方法。
一旦确定了适当的超类,筛选器编写器就会实现定义大多数ITK对象所需方法的类: New() , PrintSelf() ,以及受保护的构造函数、复制构造函数、删除和运算符=等。另外,不要忘记标准的typedef,比如 Self , Superclass , Pointer ,以及 ConstPointer 。然后,筛选器编写器可以专注于实现的最重要部分:定义API、数据成员和算法的其他实现细节。特别是,筛选器编写器将必须实现 GenerateData() (非线程)或 ThreadedGenerateData() 方法。(见第节 [sec:MultiThreading] 有关ITK中的多线程的概述。)
一个重要的注意事项:需要使用GenerateData()方法为输出分配内存。ThreadedGenerateData()方法不是。在默认实施中(请参见 itk::ImageSource ,是的超类 itk::ImageToImageFilter ) GenerateData() 分配内存,然后调用 ThreadedGenerateData() 。
开发人员必须做出的最重要决策之一是筛选器是否可以流式传输数据;也就是说,只处理输入的一部分以产生输出的一部分。超类行为通常工作得很好:如果滤镜使用单像素访问处理输入,那么默认行为就足够了。如果不是,则用户可能必须a)找到更专用的超类以从中派生,或者b)重写控制过滤器在流水线执行期间如何操作的一个或多个方法。下一节将介绍这些方法。
大数据流传输¶
与多维图像相关联的数据很大,并且正在变得更大。这一趋势是由于扫描分辨率的进步以及计算能力的增加。任何实用的分割和配准软件系统都必须解决这一事实,以便在应用中有用。ITK通过其数据流设施解决了这个问题。
在ITK中,流是将数据分成多个片段或区域,然后通过数据管道处理这些数据的过程。回想一下,管道由流程对象组成,这些流程对象生成连接到管道拓扑中的数据对象。流程对象的输入是数据对象(除非流程启动管道,然后它是源流程对象)。这些数据对象依次由其他过程对象使用,依此类推,直到数据流的有向图被构造出来。最终,流水线由一个或多个映射器终止,该映射器可以将数据写入存储,或者与图形或其他系统接口。这一点如图所示。 [fig:DataPipeLineOneConnection] 和 [fig:DataPipeLine] 。
这种体系结构的一个重要好处是,管理流水线执行的相对复杂的过程被设计到系统中。这意味着使流水线保持最新、仅执行流水线中已更改的部分、多线程执行、管理内存分配和流都内置于体系结构中。然而,这些特性确实给系统带来了复杂性,类开发人员可以看到大部分复杂性。本章的目的是详细描述流水线执行过程,重点是数据流。
流水线执行概述¶
流水线执行进程执行几个重要功能。
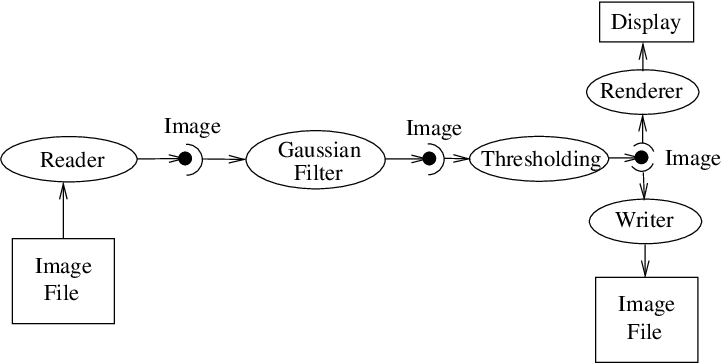
Fig. 16 数据管道
- 它确定需要执行过滤器管道中的哪些过滤器。这可以防止重复执行,并最大限度地减少总体执行时间。
- 它初始化(筛选器的)输出数据对象,为新数据做好准备。此外,它还确定每个过滤器必须为其输出分配多少内存,并对其进行分配。
- 执行过程确定过滤器必须处理多少数据才能为下游过滤器生成足够大的输出;它还会考虑对内存的任何限制或特殊的过滤器要求。其他因素包括数据处理内核的大小,这会影响需要多少数据输入数据(额外填充)。
- 它将数据细分为多个子段以进行多线程处理。(请注意,将数据分成子块与将数据分成块以进行流处理的问题完全相同;因此,多线程作为流体系结构的一部分是免费的。)
- 如果过滤器不再需要计算输出数据,并且用户请求释放数据,则它可以释放(或释放)输出数据。(注意:过滤器的输出数据对象可以被视为“缓存”。如果允许缓存保留 (
ReleaseDataFlagOff())在流水线执行和筛选器之间,筛选器或筛选器的输入永远不会改变,然后筛选器下游的处理对象只会重用筛选器的缓存来重新执行。)
要执行这些功能,执行过程需要与定义管道的过滤器协商。只有每个过滤器才能知道需要多少输入数据才能产生特定的输出。例如,收缩系数为2的收缩滤镜需要输入图像大两倍(就其x-y维度而言),才能生成特定大小的输出。根据卷积核的大小,图像卷积滤波将需要额外的输入(边界填充)。某些过滤器需要整个输入来生成输出(例如,直方图),并且可以选择请求整个输入。(在这种情况下,除非开发人员创建一个可以请求多个片段的过滤器,缓存每个片段之间的状态以组合最终输出,否则流不起作用。)
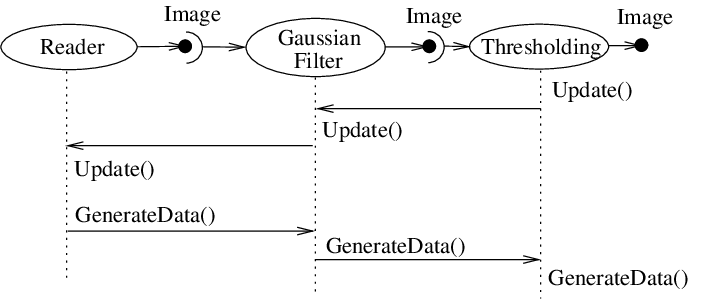
Fig. 17 数据管道更新机制的顺序
最终,协商过程由对特定大小(即,区域)的数据的请求控制。可能是用户要求处理大图像中的感兴趣区域,或者内存限制导致将数据分成几个部分处理。例如,应用程序可以计算管道所需的内存,然后使用 itk::StreamingImageFilter 将数据处理分成几个部分。数据请求在上游方向通过管道传播,协商过程配置每个过滤器以产生特定大小的输出数据。
创建流筛选器的秘诀在于了解此协商过程的工作原理,以及如何使用 itk::ProcessObject 。下一节描述这些方法的细节,以及何时覆盖它们。在此过程中提供了一些示例来说明概念。
管道执行的详细信息¶
通常,当进程对象收到 ProcessObject::Update() 方法调用。此方法只是被委托给筛选器的输出,调用 DataObject::Update() 方法。请注意,此行为是ProcessObject和DataObject之间交互的典型行为:在一个对象上调用的方法最终被委托给另一个对象。通过这种方式,来自管道的数据请求被向上传播,从而启动返回到下游的数据流。
这个 DataObject::Update() 方法依次调用其他三个方法:
DataObject::UpdateOutputInformation()DataObject::PropagateRequestedRegion()DataObject::UpdateOutputData()
更新输出信息()¶
这个 UpdateOutputInformation() 方法确定管道修改时间。它可以根据筛选器的配置方式设置RequestedRegion和LargestPossibleRegion。(RequestedRegion被设置为处理所有数据,即LargestPossibleRegion,如果尚未设置的话。)UpdateOutputInformation()通过整个管道向上游传播,并在源处终止。
在.期间 UpdateOutputInformation() ,筛选器有机会重写 ProcessObject::GenerateOutputInformation() 方法 (GenerateOutputInformation() 由以下人员调用 UpdateOutputInformation() )。默认行为是针对 GenerateOutputInformation() 将描述输入的元数据复制到输出(通过 DataObject::CopyInformation() )。请记住,信息是描述输出的元数据,例如图像的原点、间距和LargestPossibleRegion(即可能的最大大小)。
这种行为的一个很好的例子是 itk::ShrinkImageFilter 。此过滤器获取输入图像,并将其缩小某个整数值。结果是输出的间距和LargestPossibleRegion将与输入的不同。因此, GenerateOutputInformation() 超载了。
PropagateRequestedRegion()¶
这个 PropagateRequestedRegion() 调用向上游传播以满足数据请求。在典型应用中,该数据请求通常是LargestPossibleRegion,但是如果流是必要的,或者用户只对更新数据的一部分感兴趣,则RequestedRegion可以是LargestPossibleRegion内的任何有效区域。
的功能 PropagateRequestedRegion() 在给定对数据的请求(数量由RequestedRegion指定)的情况下,将筛选器的输入和输出处理对象的配置为正确的大小向上传播。最终,这意味着配置BufferedRegion,即实际分配的数据量。
缓冲区域的原因是:一个滤波器的输出可能被一个以上的下游滤波器消耗。如果这些消费者各自请求不同数量的输入(例如,由于内核要求或其他填充需求),则上游生成的筛选器生成满足两个消费者的数据,这可能意味着它生成的数据多于其中一个消费者所需的数据。
这个 ProcessObject::PropagateRequestedRegion() 方法调用筛选器开发人员可以选择重载的三个方法。
EnlargeOutputRequestedRegion(DataObject *output)使(Filter)子类有机会指示它将提供比输出所需更多的数据。例如,当源只能产生整个输出(即LargestPossibleRegion)时,就会发生这种情况。GenerateOutputRequestedRegion(DataObject *output)使子类有机会定义如何在给定输出的请求区域的情况下为其每个输出设置请求区域。默认实现是使所有请求输出的区域都相同。如果每个输出的分辨率不同,则子类可能需要重写此方法。此方法仅在筛选器有多个输出时才被重写。GenerateInputRequestedRegion()使子类有机会在输入上请求更大的请求区域。例如,当过滤器由于内核操作或其他区域边界影响而需要在“内部”边界处获得更多数据以产生边界值时,这是必要的。
itk::RGBGibbsPriorFilter 是需要调用的筛选器示例 EnlargeOutputRequestedRegion() 。此筛选器的设计者决定筛选器应该对所有数据进行操作。请注意,此方法和 GenerateInputRequestedRegion() 正在这里发生。的默认行为 GenerateInputRequestedRegion() (至少对于 itk::ImageToImageFilter )是将输入RequestedRegion设置为输出的RequestedRegion。因此,通过重写该方法 EnlargeOutputRequestedRegion() 要将输出设置为LargestPossibleRegion,需要有效地将此筛选器的输入设置为LargestPossibleRegion(并且可能会导致所有上游筛选器也处理它们的LargestPossibleRegion。这意味着过滤器不会流,因此管道不会流。这可以通过使用算法中内置的流概念重新实现过滤器来修复。)
itk::GradientMagnitudeImageFilter 是需要调用的筛选器示例 GenerateInputRequestedRegion() 。它需要更大的输入请求区域,因为需要一个内核来计算像素处的梯度。因此,需要对输入进行“填充”,以便过滤器有足够的数据来计算每个输出像素的梯度。
更新输出数据()¶
UpdateOutputData() 是第三个也是最后一个方法,因为 Update() 方法。此方法的目的是确定是否需要执行特定筛选器以使其输出保持最新。(筛选器在其 GenerateData() 方法被调用。)当a)由于修改实例变量而修改了筛选器;b)筛选器的输入发生更改;c)输入数据已被释放;或d)先前设置了无效的RequestedRegion并且筛选器没有生成数据时,就会发生筛选器执行。过滤器在下游方向上按顺序执行。一旦筛选器执行,其下游的所有筛选器也必须执行。
DataObject::UpdateOutputData() 仅当需要更新DataObject时才委托给DataObject的源(即,生成它的ProcessObject)。比较修改时间、流水线时间、释放数据标志和有效请求区域。如果这些条件中的任何一个指示数据需要重新生成,则源的 ProcessObject::UpdateOutputData() 被调用。这些调用沿管道递归进行,直到遇到源筛选器对象,或者管道被确定为最新且有效。此时,递归展开,过滤器的执行继续进行。(这意味着输出数据被初始化,StartEvent被调用,筛选器 GenerateData() 调用EndEvent,则可以释放此筛选器的输入数据(如果请求)。此外,此筛选器的InformationTime更新为当前时间。)
开发人员永远不会重写 UpdateOutputData() 。开发人员只需编写 GenerateData() 方法(非线程)或 ThreadedGenerateData() 方法。下一节将讨论线程化。
线程筛选器执行¶
可以分段处理数据的过滤器通常可以使用管道执行进程中内置的数据并行、共享内存实现进行多进程处理。要创建多线程筛选器,只需定义并实现 ThreadedGenerateData() 方法。例如,一个 itk::ImageToImageFilter 将创建以下方法:
void ThreadedGenerateData(const OutputImageRegionType& outputRegionForThread, itk::ThreadIdType threadId)
线程化的关键是为给定的输出区域生成输出(作为上面参数列表中的第一个参数)。在ITK中,这很容易做到,因为可以使用提供的区域创建输出迭代器。因此,可以迭代输出,根据需要访问相应的输入像素以计算输出像素的值。
多线程在执行I/O时需要谨慎(包括使用 cout 或 cerr )或调用事件。安全的做法是只允许线程id为零来执行I/O或生成事件。(线程ID作为参数传递到 ThreadedGenerateData() )。如果多个线程试图同时写入同一位置,程序可能会表现得很糟糕,甚至可能死锁或崩溃。
过滤器约定¶
为了充分参与ITK管道,过滤器应遵循某些约定,并提供某些接口。本节介绍将过滤器集成到ITK框架中的最低要求。
筛选器的类声明应包括宏 ITK_EXPORT ,以便在某些平台上可以包括出口申报。
筛选器应该为类本身定义公共类型 (Self )和其 Superclass ,以及 const 和非 const 智能指针,因此:
typedef ExampleImageFilter Self;
typedef ImageToImageFilter<TImage,TImage> Superclass;
typedef SmartPointer<Self> Pointer;
typedef SmartPointer<const Self> ConstPointer;
这个 Pointer 类型特别有用,因为它是一种智能指针,所有客户端代码都将使用它来保存筛选器的引用计数的实例化。
一旦定义了上述类型,您就可以使用以下方便的宏,这些宏允许您的筛选器参与对象工厂机制,并使用规范 ::New() :
/** Method for creation through the object factory. */
itkNewMacro(Self);
/** Run-time type information (and related methods). */
itkTypeMacro(ExampleImageFilter, ImageToImageFilter);
默认构造函数应为 protected ,并为所有参数提供合理的默认值(通常为零)。应声明复制构造函数和赋值运算符 private 并且未实现,以防止在没有工厂方法的情况下实例化筛选器(如上)。
最后,模板实现代码(在 .hxx 文件)应包括在内,并由手动实例化测试括起来,因此:
#ifndef ITK_MANUAL_INSTANTIATION
#include "itkExampleFilter.hxx"
#endif
任选¶
筛选器可以打印到 std::ostream (例如 std::cout )通过实现以下方法:
void PrintSelf(std::ostream& os, Indent indent) const;
并将筛选器参数的名称-值对写入所提供的输出流。这对于调试特别有用。
有用的宏¶
ITK提供了许多方便的宏来简化筛选器编码。下面将介绍其中的一些内容:
- ItkStaticConstMacro
- 声明具有指定初始值的给定类型的静态变量。
- ItkGetMacro
- 定义指定标量数据成员的访问器方法。约定是数据成员的前缀为
m_。 - ItkSetMacro
- 为所提供类型的指定标量数据成员定义赋值函数方法。这将自动设置
Modified标志,因此筛选阶段将在下一个Update()。 - ItkBoolanMacro
- 定义一对
OnFlag和OffFlag布尔变量的方法m_Flag。 - ItkGetObjectMacro、itkSetObjectMacro
- 定义ITK对象的访问器和赋值函数。Get窗体返回指向该对象的智能指针。
中的源代码可以了解更多有用的信息 Code/Common/itkMacro.h 而对于 itk::Object 和 itk::LightObject 上课。
复合滤光片¶
通常,大多数ITK/OTB过滤器实现一种特定的算法,无论它是图像过滤、信息度量还是分割算法。在上一节中,我们了解了如何从头开始编写新的过滤器。然而,能够通过组合两个或更多现有的过滤器来制造新的过滤器通常是非常有用的,然后这些过滤器可以用作复杂管道中的构建块。此方法遵循复合模式,根据该模式,复合筛选器本身的行为就像常规筛选器一样,为实现提供自己的(可能更高级别的)接口并使用其他筛选器(其详细信息对类的用户隐藏)。这种复合结构如图所示 [fig:CompositeFilterStages] ,其中不同的 Stage-n 过滤器被合并为一个过滤器,由 Composite 过滤。这个 Source 和 Sink 筛选器只能看到由 Composite 。使用复合模式,复合过滤器可以封装任意复杂性的管道。这些管道又可以嵌套在其他管道中。

Fig. 18 复合滤镜封装了许多其他滤镜。
在实施复合过滤器时,有几个需要考虑的事项。过滤器的所有常见要求均适用(如上所述),但应考虑以下准则:
- 它采用的模板参数必须足以实例化所有组件筛选器。每个组件筛选器都需要由实现者或包含的类提供的类型。例如,一个
ImageToImageFilter通常接受输入和输出图像类型(可能相同)。但如果复合滤镜的输出是分类图像,则需要决定复合滤镜内部的输出类型,或者在实例化滤镜时限制用户的选择。 - 组件筛选器的类型应在标头中声明,最好使用
protected可见性。这是因为内部结构通常不应该对类的用户可见,而应该对可能需要修改或自定义行为的后代类可见。 - 组件筛选器应该是复合类的私有数据成员,如
FilterType::Pointer。 - 默认构造函数应该通过创建阶段来构建管道,并根据需要将它们以及任何默认参数设置连接在一起。
- 复合过滤器的输入和输出需要分别嫁接到组件过滤器的头部和尾部。
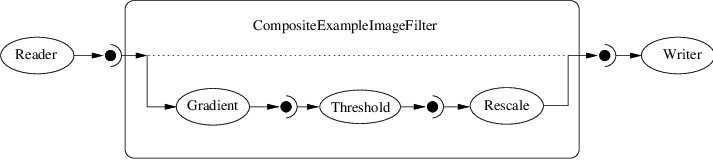
Fig. 19 典型的复合滤镜示例。请注意,内部流水线中最后一个过滤器的输出必须嫁接到复合过滤器的输出中。
请参见示例 CompositeFilterExample.cxx