分类¶
特征分类和训练¶
Orfeo工具箱提供了用于训练来自不同集合的监督或非监督分类器的应用程序 features 并将生成的分类器用于矢量数据分类。那些 features 可以是从图像提取的信息(请参见 feature extraction 部分),也可以是不同类型的 features 例如存在于OGR兼容格式的矢量数据文件中的曲面的周长、宽度或面积。
用特征训练分类器¶
这个 TrainVectorClassifier 应用程序提供了一种使用一组已标记的几何图形和一个 features 考虑进行分类。
otbcli_TrainVectorClassifier -io.vd samples.sqlite
-cfield CODE
-io.out model.rf
-classifier rf
-feat perimeter area width
这个 -classifier 参数允许选择要训练的机器学习模型算法。你有可能做非监督分类,为此,你必须选择Shark KMeans分类器。请参阅 TrainVectorClassifier 应用程序参考文档。
如果有多个示例文件,可以将它们添加到 -io.vd 参数。
要用于培训的功能必须使用 -feat 参数。名单的顺序很重要。
如果要使用统计文件进行要素归一化,可以使用 -io.stats 参数。确保统计文件中要素统计的顺序与传递给的要素顺序匹配 -feat 选择。
矢量数据中允许指定每个样本的标签的字段可以使用 -cfield 选择。
默认情况下,应用程序将在用于训练的同一组样本上估计已训练的分类器性能。这个 -io.vd 参数允许为此指定不同的样本文件,以便更公平地估计性能。请注意,此评估性能的方案也可以在之后执行(请参见 Validating the classification model 节)。
特征分类¶
一旦训练了分类器,就可以使用模型对新的矢量数据文件上的一组要素进行分类 VectorClassifier 应用程序:
otbcli_VectorClassifier -in vectorData.shp
-model model.rf
-feat perimeter area width
-cfield predicted
-out classifiedData.shp
此应用程序输出存储样本值和分类标签的矢量数据文件。输出向量文件是可选的。如果没有输出给应用程序,则更新输入矢量数据分类标签字段。如果在培训过程中使用统计文件对特征进行归一化,则在分类过程中也应在此使用统计文件。
请注意,使用此应用程序,机器学习模型可能来自图像或矢量数据的训练,这并不重要。唯一的要求是选择要使用的功能应与培训期间使用的功能相同。
正在验证分类¶
生成的模型的性能 TrainVectorClassifier 或 TrainImagesClassifier 应用程序本身直接评估应用程序,显示每个类别的查准率、召回率和F-Score,并可以生成监督算法的全局混淆矩阵。对于无监督算法,生成列联表。这些结果以*.CSV文件的形式输出。
基于像素的分类¶
Orfeo工具箱附带了一组应用程序,用于执行监督或非监督的基于像素的图像分类。此框架允许从多个图像学习,并使用几种机器学习方法,如支持向量机、贝叶斯、KNN、随机森林、人工神经网络等...(请参阅应用程序帮助 TrainImagesClassifier 和 TrainVectorClassifier 有关所有可用分类器的更多详细信息)。以下是整个工作流程的概述:
- 计算每个图像的样本统计信息
- 计算每个图像的采样率(仅当有多个输入图像时)
- 为每个图像选择样本位置
- 提取每个图像的样本测量结果
- 计算图像统计信息
- 从样本训练机器学习模型
样本统计估计¶
该框架的第一步是知道您的图像中的每个类有多少样本可用。这个 PolygonClassStatistics 会帮你完成这项工作。此应用程序处理一组训练几何图形和图像,并以XML文件的形式输出有关可用样本(即,图像覆盖的像素和无数据掩码之外的像素)的统计数据:
- 每班样本数
- 每个几何体的采样数
支持的几何图形包括多边形、直线和点。根据几何体类型的不同,此应用程序的行为也会有所不同:
- 多边形:选择中心落在多边形内的像素
- 直线:选择与直线相交的像素
- 点:选择距离提供的点最近的像素
该应用程序将需要输入图像,但它仅用于定义将在其中选择样本的占地面积。用户还可以使用参数提供用于丢弃像素位置的栅格掩膜 -mask 。
应用程序的简单使用 PolygonClassStatistics 可能如下所示:
otbcli_PolygonClassStatistics -in LANDSAT_MultiTempIm_clip_GapF_20140309.tif
-vec training.shp
-field CODE
-out classes.xml
这个 -field 参数是与输入几何图形中的类标签对应的字段的名称。
输出的XML文件如下所示::
<?xml version="1.0" ?>
<GeneralStatistics>
<Statistic name="samplesPerClass">
<StatisticMap key="11" value="56774" />
<StatisticMap key="12" value="59347" />
<StatisticMap key="211" value="25317" />
<StatisticMap key="221" value="2087" />
<StatisticMap key="222" value="2080" />
<StatisticMap key="31" value="8149" />
<StatisticMap key="32" value="1029" />
<StatisticMap key="34" value="3770" />
<StatisticMap key="36" value="941" />
<StatisticMap key="41" value="2630" />
<StatisticMap key="51" value="11221" />
</Statistic>
<Statistic name="samplesPerVector">
<StatisticMap key="0" value="3" />
<StatisticMap key="1" value="2" />
<StatisticMap key="10" value="86" />
<StatisticMap key="100" value="21" />
<StatisticMap key="1000" value="3" />
<StatisticMap key="1001" value="27" />
<StatisticMap key="1002" value="7" />
...
样本选择¶
现在,我们确切地知道对于训练集中的每个类和每个几何图形,图像中有多少样本可用。根据这些统计数据,我们现在可以计算适用于每个类别的采样率,并执行样本选择。这将由 SampleSelection 申请。
有几种策略可以计算这些采样率:
- Constant strategy: 所有类别都将使用相同数量的样本进行采样,这是用户定义的。
- Smallest class strategy: 样本数量最少的类将被完全采样。所有其他类别将使用相同数量的样本进行采样。
- Percent strategy: 每个类别都将使用用户定义的百分比(所有类别的相同值)对此类中的可用样本进行采样。
- Total strategy: 要选择的样本的全局数量在每个类别中按比例分配(强制实施类别比例)。
- Take all strategy: 带上所有可用的样品。
- By class strategy: 为每个类设置目标样本数。从CSV文件中读取每个类的样本数。
要实际选择采样位置,有两种可用的采样技术:
- Random: 随机选择样本,同时尊重采样率。
- Periodic: 使用采样率定期采样。
该应用程序将通过调整采样率来确保样本跨越整个训练集范围。根据确定采样率的策略,可能不对训练集的某些几何形状进行采样。
应用程序将接受输入图像和训练几何图形,以及在上一步中计算的类统计数据XML文件。它将输出一个矢量文件,其中包含指示样本位置的点几何图形。
otbcli_SampleSelection -in LANDSAT_MultiTempIm_clip_GapF_20140309.tif
-vec training.shp
-instats classes.xml
-field CODE
-strategy smallest
-outrates rates.csv
-out samples.sqlite
可选的写入的CSV文件 -outrates 参数汇总样本选择过程中所做的工作:
#className requiredSamples totalSamples rate
11 941 56774 0.0165745
12 941 59347 0.0158559
211 941 25317 0.0371687
221 941 2087 0.450886
222 941 2080 0.452404
31 941 8149 0.115474
32 941 1029 0.91448
34 941 3770 0.249602
36 941 941 1
41 941 2630 0.357795
51 941 11221 0.0838606

Fig. 1 此图像显示了训练的多边形,其颜色与其类别相对应。红点表示已选择的样本。
样品提取¶
既然已经选择了样本的位置,我们将为它们附加测量结果。这就是 SampleExtraction 申请。它将遍历样本列表并提取底层像素值。如果没有 -out 参数,则 SampleExtraction 应用程序可以在更新模式下工作,从而允许从同一位置的多个图像中提取特征。
要素将存储在附加到每个样本的字段中。字段名可以从前缀数字序列生成(即,如果前缀为 feature_ 然后将要素命名为 feature_0 , feature_1 、...)。这可以通过使用 -outfield prefix 选择。也可以使用为所有功能设置显式名称 -outfield list 选择。
otbcli_SampleExtraction -in LANDSAT_MultiTempIm_clip_GapF_20140309.tif
-vec samples.sqlite
-outfield prefix
-outfield.prefix.name band_
-field CODE
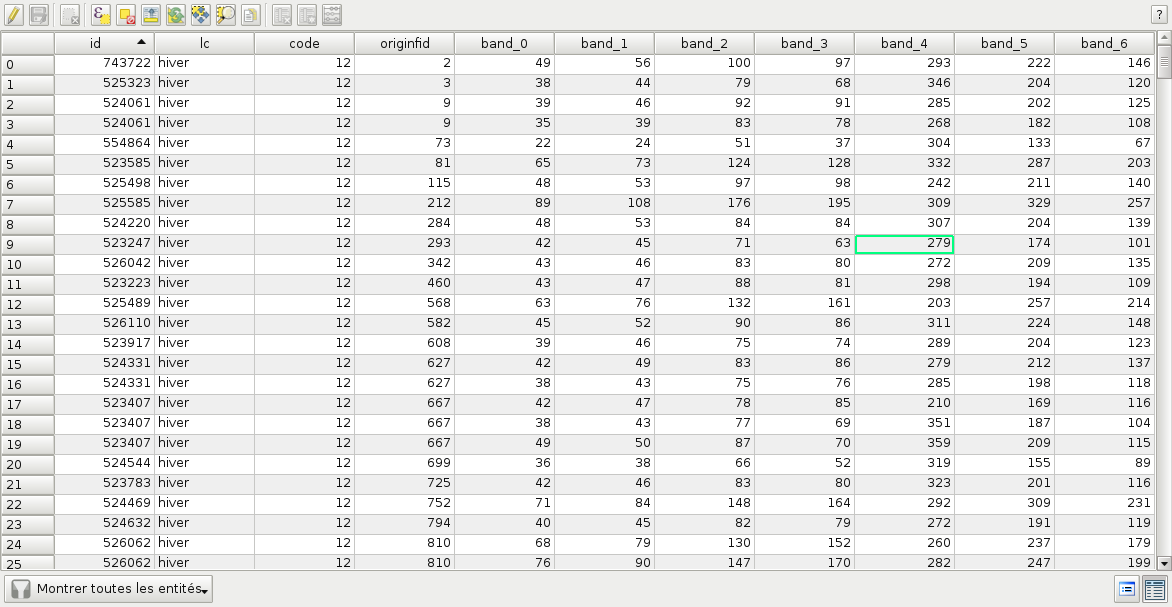
Fig. 2 更新的示例文件的属性表。
处理多个图像¶
如果训练集跨越多个图像,则 MultiImageSamplingRate 应用程序允许计算每个图像和每个类的适当采样率,以便获得覆盖整个图像范围的样本。
它首先需要运行 PolygonClassStatistics 分别在每一组图像上应用。这个 MultiImageSamplingRate 然后,应用程序将读取所有生成的统计数据XML文件,并根据采样策略得出采样率。有关更多信息,请参阅 Samples statistics estimation 一节。
多幅图像的采样率估计有3种模式:
- Proportional mode: 对于每个类别,所请求的样本数在图像中按比例分配。
- Equal mode: 对于每个类别,所请求的样本数在图像中平均分配。
- Custom mode: 用户指示每个图像的目标样本数。
每种模式和策略的不同行为如下所述。
T_i( c ) 和 N_i( c ) 分别参考到图像中的总样本数和所需样本数 i 上课用的 c 。我们打个电话吧 L 图像的总数。
- Strategy = all
- 所有模式的相同行为成比例、相等、自定义:采集所有样本
- Strategy = constant )让我们打个电话 M 每类所需的全局样本数)
- Mode = proportional: 对于每个图像 i 以及每一节课 c , N_i( c ) = \frac{M * T_i(c)}{sum_k(T_k(c))}
- Mode = equal: 对于每个图像 i 以及每一节课 c , N_i( c ) = \frac{M}{L}
- Mode = custom: 对于每个图像 i 以及每一节课 c , N_i( c ) = M_i 哪里 M_i 是图像i的自定义请求样本数
- Strategy = byClass )让我们打个电话 M(c) C)类的全局样本数
- Mode = proportional: 对于每个图像 i 以及每一节课 c , N_i( c ) = M(c) * \frac{T_i( c )}{sum_k( T_k(c))}
- Mode = equal: 对于每个图像 i 以及每一节课 c , N_i( c ) = \frac{M(c)}{L}
- Mode = custom: 对于每个图像 i 以及每一节课 c , Ni( c ) = M_i(c) 哪里 M_i(c) 是每个图像的自定义请求样本数 i 以及每一节课 c
- Strategy = percent
- Mode = proportional: 对于每个图像 i 以及每一节课 c , N_i( c ) = p * T_i(c) 哪里 p 是用户定义的百分比
- Mode = equal: 对于每个图像 i 以及每一节课 c , N_i( c ) = p * \frac{sum_k(Tk(c))}{L} 哪里 p 是用户定义的百分比
- Mode = custom: 对于每个图像 i 以及每一节课 c , Ni( c ) = p(i) * T_i(c) 哪里 p(i) 是用户定义的图像百分比 i
- Strategy = total
- Mode = proportional: 对于每个图像 i 以及每一节课 c , N_i( c ) = total * (\frac{sum_k(Ti(k))}{sum_kl(Tl(k))}) * (\frac{Ti(c)}{sum_k(Ti(k))}) 哪里 total 是指定的样本总数
- Mode = equal: 对于每个图像 i 以及每一节课 c , N_i( c ) = (total / L) * (\frac{Ti(c)}{sum_k(Ti(k))}) 哪里 total 是指定的样本总数
- Mode = custom: 对于每个图像 i 以及每一节课 c , Ni( c ) = total(i) * (\frac{Ti(c)}{sum_k(Ti(k))}) 哪里 total(i) 是为图像指定的样本总数 i
- Strategy = smallest class
- Mode = proportional: 全局计算最小类,然后将该最小类用于策略常量+比例
- Mode = equal: 全局计算最小类,然后将此最小大小用于策略常数+EQUAL
- Mode = custom: 对每个图像分别计算和使用最小类
这个 MultiImageSamplingRate 应用程序可按如下方式使用:
otbcli_MultiImageSamplingRate -il stats1.xml stats2.xml stats3.xml
-out rates.csv
-strategy smallest
-mim proportional
来自的输出文件名 -out 参数将用于根据需要生成任意数量的文件名(例如,每个输入文件名一个),名为 rates_1.csv , rates_2.csv ..。
一旦为每个图像计算了比率,就可以使用按类别策略对每个相应的图像执行样本选择:
otbcli_SampleSelection -in img1.tif
-vec training.shp
-instats stats1.xml
-field CODE
-strategy byclass
-strategy.byclass.in rates_1.csv
-out samples1.sqlite
然后,可以通过遵循以下步骤对每个图像执行样本提取 Samples extraction 一步。学习应用程序可以处理多个样例文件。
图像统计估计¶
某些机器学习算法在特征范围为 [-1,1] 或 [0,1] 。另一些则对特征之间的相对范围敏感,例如,范围较大的特征在最终决策中可能具有更大的权重。例如,机器学习算法在某一时刻使用欧几里德距离来比较特征就是这种情况。在这些情况下,建议将所有要素归一化到该范围 [-1,1] 在执行学习之前。为此, ComputeImageStatistics 应用程序允许计算基于一个或多个图像的每个波段的集合方差的平均值和标准差,并将其输出到XML文件。
otbcli_ComputeImagesStatistics -il im1.tif im2.tif im3.tif
-out images_statistics.xml
然后,可以将输出统计文件提供给培训和分类应用程序。
训练模型¶
现在训练样本已经准备好了,我们可以使用 TrainVectorClassifier 申请。
otbcli_TrainVectorClassifier -io.vd samples.sqlite
-cfield CODE
-io.out model.rf
-classifier rf
-feat band_0 band_1 band_2 band_3 band_4 band_5 band_6
如果有多个示例文件,可以将它们添加到 -io.vd 参数(请参见 Working with several images 节)。
有关功能培训流程的更多信息,请参阅 Train a classifier with features 一节。
使用分类模型¶
一旦训练了分类器,就可以应用该模型来使用新图像上定义的类别内的像素进行分类 ImageClassifier 应用程序:
otbcli_ImageClassifier -in image.tif
-model model.rf
-out labeled_image.tif
您可以设置输入蒙版,以将分类限制在值>0的蒙版区域。
-imstat图像_他国统计.xml
验证分类模型¶
Orfeo工具箱培训应用程序提供有关所生成模型的性能的信息(请参阅 Validating classification )。
与 ConputeConfusionMatrix 应用程序,还可以从使用 ImageClassifier 申请。将该标记图像与正参考样本(或者表示为栅格标记图像,或者表示为包含参考类别的矢量数据)进行比较。它还将计算每个类别的混淆矩阵和查准率、召回率和F-分数 ConfusionMatrixCalculator 班级。
如果您已进行非监督分类,则必须将其指定给 ConputeConfusionMatrix 申请。在这种情况下,必须创建列联表而不是混淆矩阵。有关更多详细信息,请参阅 format 应用程序帮助中的参数 ConputeConfusionMatrix 。
otbcli_ComputeConfusionMatrix -in labeled_image.tif
-ref vector
-ref.vector.in vectordata.shp
-ref.vector.field Class (name_of_label_field)
-out confusion_matrix.csv
花式分类结果¶
颜色映射可用于在最终的灰度级标签图像上应用颜色变换。它允许通过重新映射图像值以适合显示目的来获得RGB分类图。用户可以使用 ColorMapping 申请。此工具将用映射文件中指定的8位RGB颜色替换每个标签。映射文件应如下所示:
# Lines beginning with a # are ignored
1 255 0 0
在上一个示例中,1是标签,255 0 0是RGB颜色(此颜色将渲染为红色)。要使用映射工具,请输入以下内容:
otbcli_ColorMapping -in labeled_image.tif
-method custom
-method.custom.lut lut_mapping_file.txt
-out RGB_color_image.tif
还可以使用其他查找表(LUT):标准连续LUT、最佳LUT和基于支持映像计算的LUT。
示例¶
我们考虑4个类别:水、道路、植被和红色屋顶建筑。数据在OTB-Data中可用 repository 。
 |
 |
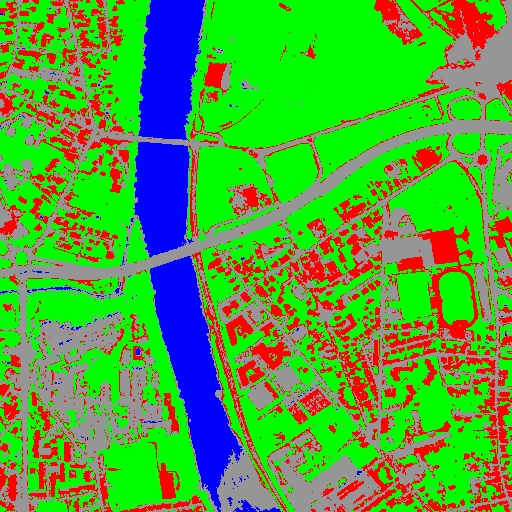 |
图2:从左到右:原始图像、原始图像与奇特分类融合后的结果图像和标签图像中奇特颜色分类的输入图像。
无监督学习¶
使用相同的机器学习框架,也可以执行无监督分类。在这种情况下,主要区别在于训练样本不需要真正的类标签。然而,为了使用相同的 TrainImagesClassifier 应用程序,您仍然需要提供一个带有标签字段的矢量数据文件。该向量文件将用于提取用于训练的样本。每个标签值可以被认为是样本的源区域,应用与监督学习中相同的逻辑来计算每个区域的提取样本。因此,对于非监督分类,基于在训练期间实际不使用的类别来选择样本。目前,在这个框架中只提出了KMeans算法。
otbcli_TrainImageClassifier
-io.il image.tif
-io.vd training_areas.shp
-io.out model.txt
-sample.vfn Class
-classifier sharkkm
-classifier.sharkkm.k 4
如果训练样本位于矢量数据文件中,则可以使用该应用程序 TrainVectorClassifier 。在这种情况下,您不需要假标签字段。您只需指定应使用哪些字段进行培训。
otbcli_TrainVectorClassifier
-io.vd training_samples.shp
-io.out model.txt
-feat perimeter area width red nir
-classifier sharkkm
-classifier.sharkkm.k 4
一旦有了模型文件,实际的分类步骤就与受监督的案例相同。该模型将预测您输入数据上的标签。
otbcli_ImageClassifier
-in input_image.tif
-model model.txt
-out kmeans_labels.tif
分类地图的融合¶
在处理了同一输入图像的不同模型或方法(支持向量机、KNN、随机森林等)的几种分类之后,可以将这些分类地图与 FusionOfClassifications 使用多数表决或Dempster-Shafer框架来处理这种融合的应用程序。分类融合生成单个更稳健和更精确的分类图,该分类图结合了从标签图像的输入列表中提取的信息。
这个 FusionOfClassifications 应用程序具有以下输入参数:
-il要融合的已标记分类图像的输入列表-out由输入分类图像的融合得到的输出标记图像-method融合方法(多数票或邓普斯特·谢弗)-nodatalabel无数据类的标签(默认值=0)-undecidedlabel待定类别的标签(默认值=0)
具有无数据类别标签的输入像素被融合过程简单地忽略。此外,将融合过程没有产生唯一类别标签的输出像素设置为未定值。
多数票赞成分类融合¶
在实施的多数表决方法中, FusionOfClassifications 应用程序中,每个输出像素的值等于输入分类图中相同像素的更频繁的类别标签。然而,更频繁的类别标签在单个像素中可能不是唯一的。在这种情况下,未决定的标签被归因于输出像素。
该应用程序可按如下方式使用:
otbcli_FusionOfClassifications -il cmap1.tif cmap2.tif cmap3.tif
-method majorityvoting
-nodatalabel 0
-undecidedlabel 10
-out MVFusedClassificationMap.tif
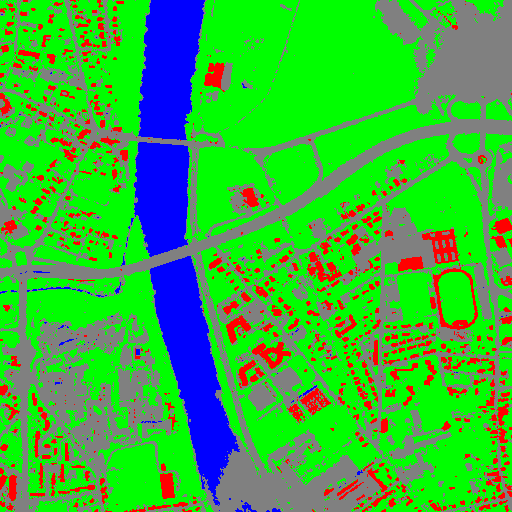
让我们考虑同一输入图像的6个独立分类图(参见。中的左侧图像 Figure2) 由6个不同的支持向量机模型生成。这个 Figure3 表示由同一LUT进行颜色映射后的对象。因此,在每一个上面都可以观察到4个等级(水:蓝色、道路:灰色、植被:绿色、红色屋顶的建筑:红色)。
 |
 |
 |
 |
 |
 |
图3:由6个不同的支持向量机模型生成的6幅待融合的彩色分类图像。
作为一个例子, FusionOfClassifications 申请者: majority voting 中表示的六个输入分类图的融合 Figure3 中右侧所示的分类图。 Figure4. 因此,这种融合似乎突出了六个不同输入分类中更相关的类别。融合图像的白色部分对应于未确定的类别标签,即对应于不存在唯一多数投票的像素。
|
 |
图4:从左至右:原始图像,由图4.13所示的6个分类图(水:蓝色,道路:灰色,植被:绿色,红色屋顶:红色,待定:白色)经多数表决融合得到的彩色分类图像
用于分类融合的Dempster Shafer框架¶
这个 FusionOfClassifications 应用程序处理另一种计算融合的方法:Dempster Shafer框架。在 Dempster-Shafer theory 在分类图融合的基础上,对每个分类器的性能进行了评估 belief function 来衡量相应的标签被正确地分配给像素的置信度。对于每个分类器和每个类标签,这些信任函数是从另一个称为 mass of belief 其测量用户根据所得到的标签在每个分类器中可以具有的置信度。
在分类地图融合的Dempster Shafer框架中,每个像素的融合类别标签是具有最大置信度函数的类别标签。在多类标签最大化置信度函数的情况下,将输出融合像素设置为待定值。
为了估计每个分类图中的置信度,每个分类图都应该面对一个基本事实。为此,由分类器产生的类标签的置信度是从其混淆矩阵估计的,该混淆矩阵本身被输出为*.CSV file with the help of the * ComputeConfusionMatrix * application. Thus, using the Dempster-Shafer method to fuse classification maps needs an additional input list of such * 与其各自的混淆矩阵相对应的.csv文件。
该应用程序可按如下方式使用:
otbcli_FusionOfClassifications -il cmap1.tif cmap2.tif cmap3.tif
-method dempstershafer
-method.dempstershafer.cmfl
cmat1.csv cmat2.csv cmat3.csv
-nodatalabel 0
-undecidedlabel 10
-out DSFusedClassificationMap.tif
作为一个例子, FusionOfClassifications 申请者: Dempster Shafer 中表示的六个输入分类图的融合 Figure3 中右侧所示的分类图。 Figure5. 因此,这种融合似乎提供了基于每个分类器中的置信度的更精确和更健壮的分类图。
|
 |
图5:从左到右:原始图像和通过Dempster-Shafer融合获得的彩色分类图像 Figure3 (水:蓝色,道路:灰色,植被:绿色,红色屋顶的建筑:红色,待定:白色)。
正确使用分类地图融合的建议¶
为了正确使用 FusionOfClassifications 申请时,应考虑以下几点。首先, list_of_input_images 和 OutputFusedClassificationImage 都是单波段标记的图像,这意味着每个像素的值对应于它所属的类别标签,并且每个分类地图中的标签必须代表相同的类别。其次,未确定的标签值必须与输入图像中的现有标签不同,以避免在解释 OutputFusedClassificationImage 。
基于多数投票的分类地图正则化¶
生成的分类图可以正则化,以平滑不规则类。这样的正则化过程通过使更均匀的区域更容易处理来改进分类结果。
多数票支持分类图正则化¶
这个 ClassificationMapRegularization 应用程序基于指定球状邻域中的多数投票方法对标记的输入图像执行正则化。对于每个中心像素,多数投票采用结构化元素标识的所有像素中更具代表性的值,然后将输出的中心像素设置为该多数标签值。球状邻域由其以像素表示的半径标识。
基于多数投票的正则化中模糊和未分类像素的处理¶
由于多数投票正则化可能导致邻域中的多数标签不是唯一的,因此重要的是定义在这种情况下过滤器必须具有哪些行为。为此,布尔参数(称为ip.suvbool)用于 ClassificationMapRegularization 应用程序选择是否将具有多个多数类的像素设置为未决定(TRUE)或设置为其原始标签(FALSE=默认值)。
此外,输入图像中的像素可能不属于所考虑的任何类别。假设这样的像素属于NoData类,其标签被指定为正则化的输入参数。因此,这些NoData输入像素是不变的,并在输出正则化图像中保留其NoData标签。
这个 ClassificationMapRegularization 应用程序具有以下输入参数:
-io.in由先前分类过程产生的带标签的输入图像-io.out输出对应于输入图像的正则化的标记图像-ip.radius与球状结构元素半径对应的整数(默认值=1像素)-ip.suvbool用于选择将具有多个多数类的像素设置为未决定(TRUE)还是设置为其原始标签(FALSE=默认值)的布尔参数。请注意,未确定的值必须与输入图像中的现有标注不同-ip.nodatalabelNoData类的标签。此类输入像素在输出图像中保留其NoData标签(默认值=0)-ip.undecidedlabel待定类别的标签(默认值=0)。
该应用程序可按如下方式使用:
otbcli_ClassificationMapRegularization -io.in labeled_image.tif
-ip.radius 3
-ip.suvbool true
-ip.nodatalabel 10
-ip.undecidedlabel 7
-io.out regularized.tif
正确使用基于多数表决的正规化的建议¶
为了正确使用 ClassificationMapRegularization 申请时,应考虑以下几点。首先,两者都是 InputLabeledImage 和 OutputLabeledImage 是单波段标记的图像,这意味着每个像素的值对应于它所属的类别标签。这个 InputLabeledImage 通常是使用诸如支持向量机分类之类的分类算法生成的图像。备注:两者皆有 InputLabeledImage 和 OutputLabeledImage 不一定是同一类型的。其次,如果ip.suvbool==TRUE,则未确定的标签值必须不同于输入标记图像中的现有标签,以避免在解释正则化的 OutputLabeledImage 。最后,结构元素半径的最小值必须等于1像素,这是其缺省值。NoData和未决定标签的默认值都等于0。

回归¶
OpenCV、LibSVM和SharkML中的机器学习模型也支持回归模式:它们可以用于从输入预测器预测数值(即不是类别索引)。工作流程与分类相同。首先,对回归模型进行训练,然后用它来预测输出值。
有两个应用程序可供培训:
TrainVectorRegression 可用于使用包含特征(预测值)列表和相应输出值的一组几何图形来训练分类器:
otbcli_TrainVectorRegression -io.vd samples.sqlite -cfield predicted -io.out model.rf -classifier rf -feat perimeter area width
验证集 io.valid 用于计算原始输出值与计算模型预测值之间的均方误差。如果没有提供验证集,则使用输入训练样本来计算均方误差。
TrainImagesRegression 可用于从多对预测器图像和标签图像训练分类器。使用此应用程序有两种方式:
可以为每个输入图像提供具有对应于将用于训练的输入位置的几何的矢量数据文件。这是通过使用 io.vd 参数。这个 sample.nt 和 sample.nv 可用于指定从图像中提取的样本数量,分别用于训练和验证。
otbcli_TrainImagesRegression -io.il inputPredictorImage.tif -io.ip inputLabelImage.tif -io.vd trainingData.shp -classifier rf -io.out model.txt -sample.nt 1000 -sample.nv 500
或者,如果没有提供输入矢量数据,则将从全图像范围中提取训练样本。
还有两个应用程序可用于预测:
- VectorRegression 使用回归机器学习模型根据一系列功能预测输出值:
otbcli_VectorRegression
-in input_vector_data.shp
-feat perimeter area width
-model model.txt
-out predicted_vector_data.shp
- 同样, ImageRegression 将预测器的图像作为输入,并使用回归模型计算输出图像:
otbcli_ImageRegression
-in input_image.tif
-model model.txt
-out predicted_image.tif